Python深度学习 基于Pytorch
PyTorch基础
Numpy与Tensor
最大的区别就是Numpy会把ndarray放在CPU中进行加速运算,而由Torch产生的Tensor会放在GPU中进行加速运算(假设当前环境有GPU)。
Tensor概述
对Tensor的操作很多,从接口的角度来划分,可以分为两类:
- torch.function,如torch.sum、torch.add等;
- torch.function,如torch.sum、torch.add等;
如果从修改方式的角度来划分,可以分为以下两类:
- 如果从修改方式的角度来划分,可以分为以下两类:
- 修改自身数据,如x.add_(y)(运行符带下划线后缀),运算结果存在x中,x被修改。
import torch
x = torch.tensor([1,2])
y = torch.tensor([3,4])
z = x.add(y)
print(z)
print(x)
x.add_(y)
print(x)
创建Tensor
- Tensor(size):直接从参数构造一个的张量,支持List,Numpy数组
- eye(row, column)创建指定行数,列数的二维单位Tensor
- linspace(start,end,steps)从 start到end,均匀切分成 steps 份
- logspace(start,end,steps)从10start,到10end,均匀切分成 steps份
- rand/randn(size)生成[0,1)均匀分布/标准正态分布数据
- ones(size)返回指定 shape 的张量,元素初始为1
- zeros(*size)返回指定 shape 的张量,元素初始为0
- ones_like(t)返回与T的shape相同的张量,且元素初始为1
- zeros_like(t)返回与T的shape相同的张量,且元素初始为0
- arange(start,end,ste)在区间[start,end)上以间隔 step 生成一个序列张量
- from_Numpy(ndarray)从ndarray创建一个Tensor
print(torch.Tensor([1,2,3,4,5,6]))
print(torch.Tensor(2,3))
t = torch.Tensor([[1,2,3],[4,5,6]])
print(t.size())
print(t.shape)
print(torch.Tensor(t.size()))
注意torch.Tensor与torch.tensor的几点区别:
- torch.Tensor是torch.empty和torch.tensor之间的一种混合,但是,当传入数据时,torch.Tensor使用全局默认dtype(FloatTensor),而torch.tensor是从数据中推断数据类型。
- torch.tensor(1)返回一个固定值1,而torch.Tensor(1)返回一个大小为1的张量,它是随机初始化的值。
#生成一个单位矩阵
torch.eye(2,2)
#自动生成全是0的矩阵
torch.zeros(2,3)
#根据规则生成数据
torch.linspace(1,10,4)
#生成满足均匀分布随机数
torch.rand(2,3)
#生成满足标准分布随机数
torch.randn(2,3)
#返回所给数据形状相同,值全为0的张量
torch.zeros_like(torch.rand(2,3))
修改Tensor形状
- size():返回张量的 shape 属性值,与函数 shape(0.4 版新增)等价
- numel(input):计算 Tensor 的元素个数
- view(*shape):修改 Tensor 的 shape,与Reshape(0.4 版新增)类似,但View返回的对象与源 Tensor 共享内存,修改一个,另一个同时修改。Reshape 将生成新的Tensor,而且不要求源Tensor 是连续的。View(-1)展平数组
- resize:类似于 view,但在 size 超出时会重新分配内存空间
- item:若 Tensor 为单元素,则返回 Python 的标量
- unsqueeze:在指定维度增加一个"1"
- squeeze:在指定维度压缩一个"1"
x = torch.randn(2,3)
print(x.size())
print(x.dim()) # 查看维度
x.view(3,2) # 改变形状
y = x.view(-1) # 拉成一维,-1表示自适应
print(y.size())
z = torch.unsqueeze(y,0) # 在第0维增加一个维度
print(z.size())
print(z.numel()) # 查看元素个数
索引操作
- index_select(input,dim,index):在指定维度上选择一些行或列
- nonzero(input):获取非0元素的下标
- masked_select(input,mask):使用二元值进行选择
- gather(input,dim,index):在指定维度上选择数据,输出的形状与 index(index 的类型必须是LongTensor类型的)一致
- scatter_(input,dim,index,src)为 gather 的反操作,根据指定索引补充数据
# 设置一个随机种子
torch.manual_seed(100)
# 生成一个形状为2行3列的张量
x = torch.randn(2, 3)
# 根据索引获取第一行,所有数据
print(x[0, :])
# 获取最后一列数据
print(x[:, -1])
# 生成是否大于0的Byter张量
mask = x > 0
print(mask)
# 获取大于0的值
torch.masked_select(x, mask)
# 获取非0下标,即行、列索引
print("x:",x)
print(torch.nonzero(mask))
#获取指定索引对应的值,输出根据以下规则得到
#out[i][j] = input[index[i][j]][j] # if dim == 0
#out[i][j] = input[i][index[i][j]] # if dim == 1
index = torch.LongTensor([[0,1,1]])
print(torch.gather(x, 0, index))
index = torch.LongTensor([[0,1,1],[1,1,1]])
a = torch.gather(x, 1, index)
print("a:",a)
# 把a的值返回到一个2行3列的张量中,其他位置补0
z = torch.zeros(2,3)
z.scatter_(1, index, a)
print("z:",z)
gather、scatter_ 再看看。。
广播机制
A= np.arange(0,40,10).reshape(4,1)
B = np.arange(0,3)
# 把ndarray转换为tensor
A1 = torch.from_numpy(A)
B1 = torch.from_numpy(B)
# Tensot自动实现广播
C = A1 + B1
print("C:",C)
# 我们可以根据广播机制,手工进行配置
# 根据规则,B1需要向A1看齐,把B变为(1,3)
B2 = B1.unsqueeze(0) # B2的形状为1x3
# 使用expand函数重复数组,分别的4x3的矩阵
A2 = A1.expand(4,3)
B3 = B2.expand(4,3)
# 然后进行相加,C1与C结果一致
C2 = A2 + B3
逐元素操作
- abs/add:绝对值/加法
- addcdiv(t,v,t1,t2):t1与t2的按元素除后,乘v加t
- addcmul(t, v, t1,t2):t1与t2的按元素乘后,乘v加t
- ceil/floor:向上取整/向下取整
- clamp(t, min, max):将张量元素限制在指定区间
- exp/log/pow:指数/对数/幂
- mul(或*)/neg:逐元素乘法/取反
- sigmoid/tanh/softmax:激活函数
- sign/sqrt:取符号/开根号
t = torch.randn(1,3)
t1 = torch.randn(3,1)
t2 = torch.randn(1,3)
# t+0.1*(t1/t2)
t3 = torch.addcdiv(t, 0.1, t1, t2)
# 计算sigmoid(t)
torch.sigmoid(t)
# 将t限制在[0,1]之间
torch.clamp(t, 0, 1)
# t+2进行就地运算
t.add_(2)
归并操作
- cumprod(t,axis):在指定维度对t进行累积
- cumsum:在指定维度对t进行累加
- dist(a,b,p=2):返回a,b之间的p阶范数
- mean/median:均值/中位数
- std/var:标准差/方差
- norm(t,p=2):返回t的p阶范数
- prod(t)/sum(t):返回t所有元素的积/和
a = torch.linspace(0,10,6)
a = a.view((2,3))
# 沿y轴方向累加,即dim=0
b = a.sum(dim=0)
# 沿y轴方向累加,即dim=0,并保留含1的维度
b = a.sum(dim=0, keepdim=True)
比较操作
- eq:比较Tensor是否相等,支持broadcast
- equal:比较Tensor是否有相同的 shape与值
- ge/le/gt/lt:大于/小于比较/大于等于/小于等于比较
- max/min(t,axis):返回最值,若指定axis,则额外返回下标
- topk(t,k,axis):在指定的 axis 维上取最高的K个值
x = torch.linspace(0,10,6).view(2,3)
torch.max(x)
torch.max(x, dim=0)
torch.topk(x,1, dim=0) # 每列最大的1个元素
矩阵操作
- dot(t1, t2):计算张量(1D)的内积或点积
- mm(mat1, mat2)/bmm(batch1,batch2):计算矩阵乘法/含 batch 的 3D 矩阵乘法
- mv(tl, v1):计算矩阵与向量乘法
- t:转置
- svd(t):计算t的 SVD 分解
说明:
- Torch的dot与Numpy的dot有点不同,Torch中的dot是对两个为1D张量进行点积运算,Numpy中的dot无此限制。
- Torch的dot与Numpy的dot有点不同,Torch中的dot是对两个为1D张量进行点积运算,Numpy中的dot无此限制。
- 转置运算会导致存储空间不连续,需要调用contiguous方法转为连续。
a = torch.tensor([2,3])
b = torch.tensor([3,4])
torch.dot(a,b) # 运行结果为18
x = torch.randint(10,(2,3))
y = torch.randint(6,(3,4))
torch.mm(x,y) # 矩阵乘法
x = torch.randint(10,(2,2,3))
y = torch.randint(6,(2,3,4))
torch.bmm(x,y) # 批量矩阵乘法
PyTorch与Numpy比较
| 操作类型 | Numpy | PyTorch |
|---|---|---|
| 数据类型 | np.ndarray | torch.Tensor |
| 数据类型 | np.float32 | torch.float32;torch.float |
| 数据类型 | np.float64 | torch.float64;torch..double |
| 数据类型 | np.int64 | torch.int64;torch.long |
| 从已有数据构建 | np.array([3.2,4.3],dtype=np.float64) | torch.tensor([3.2,4.3],dtype=torch.float16) |
| 从已有数据构建 | x.copy() | x.clone() |
| 从已有数据构建 | np.concatenate | torch.cat |
| 线性代数 | np.dot | np.mm |
| 属性 | x.ndim | x.dim() |
| 属性 | x.size | x.nelement() |
| 形状操作 | x.reshape | x.reshape,x.view |
| 形状操作 | x.flatten | x.view(-1) |
| 类型转换 | np.floor(x) | torch.floor(x);x.floor() |
| 比较 | np.le | x.lt |
| 比较 | np.less_equal/np.greater | x.le/x.gt |
| 比较 | np.greater_equal/np.equal/np.not_equal | x.ge/x.eq/x.ne |
| 随机种子 | np.random.seed | torch.maual_sseed |
Tensor与Autograd
torch.autograd包就是用来自动求导的。Autograd包为张量上所有的操作提供了自动求导功能,而torch.Tensor和torch.Function为Autograd的两个核心类,它们相互连接并生成一个有向非循环图。
标量反向传播
假设x、w、b都是标量,z=wx+b,对标量z调用backward()方法,我们无须对backward()传入参数。以下是实现自动求导的主要步骤:
-
定义叶子节点及算子节点:
# 定义输入张量x x = torch.Tensor([2]) # 初始化权重参数W,偏移量b、并设置require_grad属性为True,为自动求导 w = torch.randn(1, requires_grad=True) b = torch.randn(1, requires_grad=True) # 实现前向传播 y = torch.mul(w, x) # 等价与W*x z = torch.add(y, b) # 等价与y + b # 查看x、w、b叶子节点的requite_grad属性 print("x,w,b的require_grad属性分别为:{},{},{}".format(x.requires_grad , w.requires_grad, b.requires_grad)) # x,w,b的require_grad属性分别为:False,True,True打印输出:x,w,b的require_grad属性分别为:False,True,True
-
查看叶子节点、非叶子节点的其他属性
# 查看非叶子节点的requres_grad属性 print("y,z的require_grad属性分别为:{},{}".format(y.requires_grad, z.requires_grad)) # 因与w,b有依赖关系,故y,z的require_grad属性均为True # 查看各节点是否为叶子节点 print("x,w,b,y,z是否为叶子节点分别为:{},{},{},{},{}".format(x.is_leaf, w.is_leaf, b.is_leaf, y.is_leaf, z.is_leaf)) # x,w,b,y,z是否为叶子节点分别为:True,True,True,False,False # 查看叶子节点的grad_fn属性 print("x,w,b的grad_fn属性分别为:{},{},{}".format(x.grad_fn, w.grad_fn, b.grad_fn)) # 因x,w,b为用户创建的,为通过其他张量计算得到,故x,w,b的grad_fn属性均为None # 查看非叶子节点的grad_fn属性 print("y,z的grad_fn属性分别为:{},{}".format(y.grad_fn, z.grad_fn)) # y,z的grad_fn属性分别为:<MulBackward0 object at 0x0000017BE4165C60>,<AddBackward0 object at 0x0000017BE4165C30> -
自动求导,实现梯度方向传播,即梯度的反向传播
# 基于z张量进行梯度反向传播,执行backward之后计算图会自动清空 z.backward() # 等价与dz/dw, dz/db # 如果需要多次随时用backward,需要修改参数retain_graph=True,此时梯度是累加的 # z.backward(retain_graph=True) # 查看叶子节点的梯度,x是叶子节点但它无需求导,故其梯度为None print("w,b的梯度分别为:{},{}".format(w.grad, b.grad)) # w,b的梯度分别为:tensor([2.]),tensor([1.]) # 非叶子节点的梯度,执行backward之后,会自动清空 print("y,z的梯度分别为:{},{}".format(y.grad, z.grad)) # y,z的梯度分别为:None,None
非标量反向传播
PyTorch有个简单的规定,不让张量(Tensor)对张量求导,只允许标量对张量求导,因此,如果目标张量对一个非标量调用backward(),则需要传入一个gradient参数,该参数也是张量,而且需要与调用backward()的张量形状相同。
传入这个参数就是为了把张量对张量的求导转换为标量对张量的求导。这有点拗口,我们举一个例子来说,假设目标值为loss=(y1,y2,…,ym),传入的参数为v=(v1,v2,…,vm),那么就可把对loss的求导,转换为对loss*vT标量的求导。即把原来 $ frac{dloss}{dx} $ 得到的雅可比矩阵(Jacobian)乘以张量vT,便可得到我们需要的梯度矩阵。
backward函数的格式为:
backward(gradient=None, retain_graph=None, create_graph=False)
实例说明:
-
定义叶子节点及计算节点
# 定义叶子节点张量x,形状为1x2 x = torch.tensor([[2,3]],dtype=torch.float,requires_grad=True) # 初始化Jacobian 矩阵 J = torch.zeros(2,2) # 初始化目标张量,形状为1x2 y = torch.zeros(1,2) # 定义y与x之间的映射关系: # y1 = x1**2 + 3*x2, y2 = x2**2+2*x1 y[0,0] = x[0,0]**2 + 3*x[0,1] y[0,1] = x[0,1]**2 + 2*x[0,0] -
计算y对x的梯度
# 生成y1对x的梯度 y.backward(torch.Tensor([[1,0]]), retain_graph=True) J[0]=x.grad # 梯度是累加的,故需要对x的梯度清零 x.grad = torch.zeros_like(x.grad) # 生成y2对x的梯度 y.backward(torch.Tensor([[0,1]])) J[1] = x.grad # 显示jacobian矩阵的值 print("Jacobian矩阵为:\n", J)Jacobian矩阵为: tensor([[4., 3.], [2., 6.]])
使用Numpy实现机器学习
首先,我们用最原始的Numpy实现有关回归的一个机器学习任务,不用PyTorch中的包或类。主要步骤包括:
- 首先,给出一个数组x,然后基于表达式 $ y=3x^2+2 $,加上一些噪音数据到达另一组数据y。
- 然后,构建一个机器学习模型,学习表达式y=wx2+b的两个参数w、b。利用数组x,y的数据为训练数据。
- 然后,构建一个机器学习模型,学习表达式y=wx2+b的两个参数w、b。利用数组x,y的数据为训练数据。
- 最后,采用梯度梯度下降法,通过多次迭代,学习到w、b的值。
# 1、生成输入数据x及目标数据y。
# 设置随机数种子,生成同一个份数据,以便用多种方法进行比较。
np.random.seed(100)
x = np.linspace(-1,1,100).reshape(100,1)
y = 3*np.power(x,2) + 2 + 0.2*np.random.randn(x.size).reshape(100,1)
# 2查看x、y数据的分布情况
plt.scatter(x, y)
plt.show()
# 3、初始化权重参数
w1 = np.random.randn(1,1)
b1 = np.random.randn(1, 1)
# 4、训练模型
for i in range(800):
# 前向传播,计算预测值
y_pred = np.power(x,2)*w1 + b1
# 定义损失函数
loss = 0.5 * (y_pred - y)**2
loss = loss.sum()
# 计算梯度
grad_w = np.sum((y_pred-y)*np.power(x,2))
grad_b = np.sum(y_pred - y)
# 更新参数
w1 -= 0.01 * grad_w
b1 -= 0.01 * grad_b
# 5、可视化结果
plt.plot(x,y_pred, 'r-', label='预测值')
plt.scatter(x, y,color='blue',marker='o', label='真实值')
plt.xlim(-1,1)
plt.ylim(0,6)
plt.legend()
plt.show()
print("w1=", w1, "b1=", b1)
使用Tensor及Antograd实现机器学习
import torch as t
from matplotlib import pyplot as plt
# 1.生成训练数据,并可视化数据分布情况
t.manual_seed(100)
dtype = t.float
# 生成x坐标数据,x为tenor类型,需要吧x转为100x1
x = t.unsqueeze(t.linspace(-1, 1, 100), dim=1) # unsqueeze在第1维增加一个维度
y = 3*x.pow(2)+ 2 + 0.2*t.rand(x.size())
# 画图
plt.scatter(x.numpy(), y.numpy())
plt.show()
# 初始化权重参数
# 随机初始化参数,参数w、b为需要学习的,故需requires_grad=True
w = t.randn(1,1, dtype=dtype,requires_grad=True)
b = t.zeros(1,1, dtype=dtype, requires_grad=True)
# 训练模型
lr = 0.001 # 学习率
for ii in range(800):
# 前向传播,并定义损失函数loss
y_pred = x.pow(2).mm(w) + b # mm为矩阵乘法
loss = 0.5 * (y_pred - y).pow(2)
loss = loss.sum() # sum后也是tensor类型
# 自动计算梯度,梯度存放在grad属性中
loss.backward()
# 手动更新参数,需要用torch.no_grad(),使上下文环境中切断自动求导的计算
with t.no_grad():
w -= lr * w.grad
b -= lr * b.grad
# 清空梯度
w.grad.zero_()
b.grad.zero_()
# 可视化训练结果
plt.plot(x.numpy(), y_pred.detach().numpy(), 'r-', label='predicted')
plt.scatter(x.numpy(),y.numpy(),color='blue',marker='o',label='true')
plt.xlim(-1,1)
plt.ylim(2,6)
plt.legend()
plt.show()
print(w,b)
PyTorch神经网络工具箱
实现神经网络实例
构建网络层可以基于Module类或函数(nn.functional)。nn中的大多数层(Layer)在functional中都有与之对应的函数。nn.functional中函数与nn.Module中的Layer的主要区别是后者继承Module类,会自动提取可学习的参数。而nn.functional更像是纯函数。两者功能相同,且性能也没有很大区别,那么如何选择呢?像卷积层、全连接层、Dropout层等因含有可学习参数,一般使用nn.Module,而激活函数、池化层不含可学习参数,可以使用nn.functional中对应的函数。
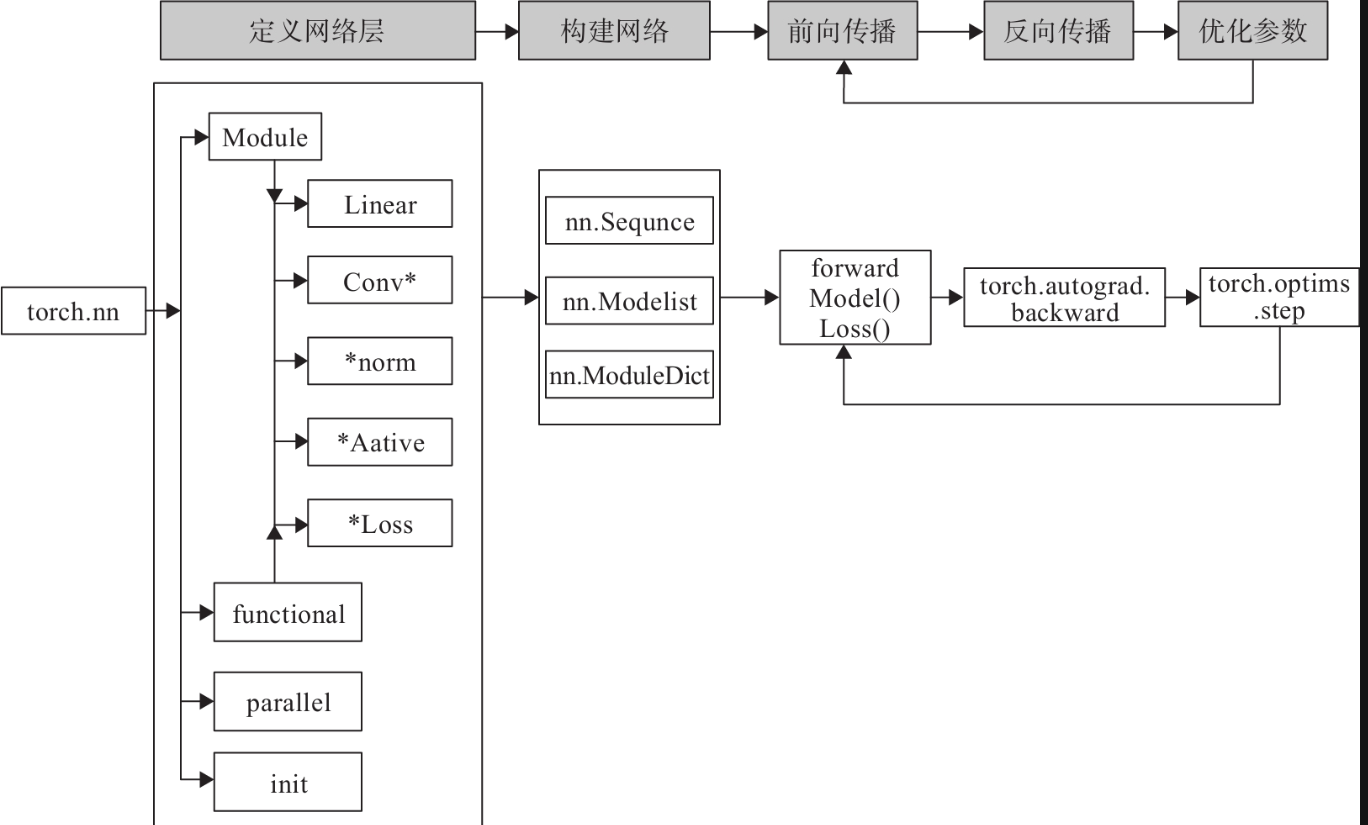
利用神经网络完成对手写数字进行识别的实例,来说明如何借助nn工具箱来实现一个神经网络,并对神经网络有个直观了解:
import numpy as np
import torch
# 导入PyTorch内置的 minist 数据
from torchvision.datasets import mnist
# 导入预处理模块
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# 导入nn及优化器
import torch.nn.functional as F
import torch.optim as optim
from torch import nn
import matplotlib.pyplot as plt
# 顶级一些超参数
train_batch_size = 64
test_batch_size = 128
learnini_rate=0.01
num_epoches = 20
lr = 0.001
momentum = 0.5
# 下载数据并对数据进行预处理
# 定义预处理函数,这些预处理依次放在Compose函数中
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5],[0.5])])
# 下载数据,并对数据进行预处理
train_dataset = mnist.MNIST("./data",train=True,transform=transform,download=True)
test_dataset = mnist.MNIST('./data',train=False,transform=transform)
# dataloader是一个可迭代队形,可以使用迭代器一样使用
train_loader = DataLoader(train_dataset,batch_size=train_batch_size,shuffle=True)
test_loader = DataLoader(test_dataset,batch_size=test_batch_size,shuffle=False)
# 可视化源数据
examples = enumerate(test_loader)
batch_ids,(example_data,example_targets) = next(examples)
# fig = plt.figure()
# for i in range(6):
# plt.subplot(2,3,i+1)
# plt.tight_layout()
# plt.imshow(example_data[i][0],cmap='gray',interpolation='none')
# plt.title("Ground TruthL{}".format(example_targets[i]))
# plt.xticks()
# plt.yticks()
# plt.show()
# 构建模型
class Net(nn.Module):
'''
使用sequential构建网络,Senquential函数的功能是将网络的层组合到一起
'''
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(Net,self).__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim,n_hidden_1),nn.BatchNorm1d(n_hidden_1))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1,n_hidden_2),nn.BatchNorm1d(n_hidden_2))
self.layer3 = nn.Sequential(nn.Linear(n_hidden_2,out_dim))
def forward(self,x):
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
x = F.relu(self.layer3(x))
return x
# 实例化网络
# 检测是否有可用的GPU,有则会用,否则使用GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 实例化网络
model = Net(28*28,300,100,10)
model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=lr,momentum=momentum)
# 训练模型
# 开始训练
losses = []
acces=[]
eval_losses=[]
eval_acces=[]
for epoch in range(num_epoches):
train_loss = 0
train_acc=0
model.train()
# 动态修改参数学习率
if epoch%5==0:
optimizer.param_groups[0]['lr']*=0.1
for img,label in train_loader:
img = img.to(device)
label = label.to(device)
img = img.view(img.size(0),-1)
# 前向传播
out = model(img)
loss = criterion(out,label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss+=loss.item()
# 计算分类的准确率
_,pred = out.max(1)
num_correct = (pred==label).sum().item()
acc = num_correct/img.shape[0]
train_acc+=acc
losses.append(train_loss/len(train_loader))
acces.append(train_acc/len(train_loader))
# 在测试集事实上验证效果
eval_loss=0
eval_acc=0
# 将模型改为预测模式
model.eval()
for img,label in test_loader:
img=img.to(device)
label=label.to(device)
img=img.view(img.size(0),-1)
out=model(img)
loss = criterion(out,label)
# 记录误差
eval_loss+=loss.item()
# 记录准确率
_,pred = out.max(1)
num_correct = (pred==label).sum().item()
acc = num_correct/img.shape[0]
eval_acc+=acc
eval_losses.append(eval_loss/len(test_loader))
eval_acces.append(eval_acc/len(test_loader))
print('epoch: {}, Train Loss: {:.4f}, Train Acc: {:.4f}, Test Loss: {:.4f}, Test Acc: {:.4f}'
.format(epoch, train_loss / len(train_loader), train_acc / len(train_loader),
eval_loss / len(test_loader), eval_acc / len(test_loader)))
# 可视化训练及测试损失值
plt.title("trainloss")
plt.plot(np.arange(len(losses)),losses)
# plt.legend(['Train Loss'], loc='upper rigth')
plt.show()
如何构建神经网络
构建网络层
如果要对每层定义一个名称,我们可以采用Sequential的一种改进方法,在Sequential的基础上,通过add_module()添加每一层,并且为每一层增加一个单独的名字。此外,还可以在Sequential基础上,通过字典的形式添加每一层,并且设置单独的层名称。
以下是采用字典方式构建网络的一个示例代码:
import torch
from collections import OrderedDict
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv = torch.nn.Sequential(
OrderedDict(
[
("vonv1",torch.nn.Conv2d(3,32,3,1,1)),
("result",torch.nn.ReLU),
("pool",torch.nn.MaxPool2d(2))
]
)
)
self.dense = torch.nn.Sequential(
OrderedDict([
("dense1",torch.nn.Linear(32*3*3,128)),
("relu2",torch.nn.ReLU),
("dense2",torch.nn.Linear(128,10))
])
)
训练模型
训练模型时需要注意使模型处于训练模式,即调用model.train()。调用model.train()会把所有的module设置为训练模式。如果是测试或验证阶段,需要使模型处于验证阶段,即调用model.eval(),调用model.eval()会把所有的training属性设置为False。
缺省情况下梯度是累加的,需要手工把梯度初始化或清零,调用optimizer.zero_grad()即可。训练过程中,正向传播生成网络的输出,计算输出和实际值之间的损失值。调用loss.backward()自动生成梯度,然后使用optimizer.step()执行优化器,把梯度传播回每个网络。
神经网络工具箱nn
前面我们使用Autograd及Tensor实现机器学习实例时,需要做不少设置,如对叶子节点的参数requires_grad设置为True,然后调用backward,再从grad属性中提取梯度。对于大规模的网络,Autograd太过于底层和烦琐。为了简单、有效解决这个问题,nn是一个有效工具。在nn工具箱中有两个重要模块:nn.Model、nn.functional,接下来将介绍这两个模块
nn.Module
nn.Module是nn的一个核心数据结构,它可以是神经网络的某个层(Layer),也可以是包含多层的神经网络。在实际使用中,最常见的做法是继承nn.Module,生成自己的网络/层,如上面代码中,所定义的Net类就采用这种方法(class Net(torch.nn.Module))。nn中已实现了绝大多数层,包括全连接层、损失层、激活层、卷积层、循环层等,这些层都是nn.Module的子类,能够自动检测到自己的Parameter,并将其作为学习参数,且针对GPU运行进行了cuDNN优化。
nn.functional
nn中的层,一类是继承了nn.Module,其命名一般为nn.Xxx(第一个是大写),如nn.Linear、nn.Conv2d、nn.CrossEntropyLoss等。另一类是nn.functional中的函数,其名称一般为nn.funtional.xxx,如nn.funtional.linear、nn.funtional.conv2d、nn.funtional.cross_entropy等。从功能来说两者相当,基于nn.Moudle能实现的层,使用nn.funtional也可实现,反之亦然,而且性能方面两者也没有太大差异。不过在具体使用时,两者还是有区别,主要区别如下:
- nn.Xxx继承于nn.Module,nn.Xxx需要先实例化并传入参数,然后以函数调用的方式调用实例化的对象并传入输入数据。它能够很好地与nn.Sequential结合使用,而nn.functional.xxx无法与nn.Sequential结合使用。
- nn.Xxx不需要自己定义和管理weight、bias参数;而nn.functional.xxx需要自己定义weight、bias参数,每次调用的时候都需要手动传入weight、bias等参数,不利于代码复用。
- Dropout操作在训练和测试阶段是有区别的,使用nn.Xxx方式定义Dropout,在调用model.eval()之后,自动实现状态的转换,而使用nn.functional.xxx却无此功能。
总的来说,两种功能都是相同的,但PyTorch官方推荐:具有学习参数的(例如,conv2d,linear,batch_norm)采用nn.Xxx方式。没有学习参数的(例如,maxpool、loss func、activation func)等根据个人选择使用nn.functional.xxx或者nn.Xxx方式。上面代码中使用激活层,我们采用F.relu来实现,即nn.functional.xxx方式。
优化器
PyTorch常用的优化方法都封装在torch.optim里面,所有的优化方法都是继承了基类optim.Optimizer,并实现了自己的优化步骤。
SGD:随机梯度下降法(SGD)就是最普通的优化器,一般SGD并说没有加速效果,上面代码使用的SGD包含动量参数Momentum,它是SGD的改良版
使用优化器的一般步骤为:
-
建立优化器实例
导入optim模块,实例化SGD优化器,这里使用动量参数momentum(该值一般在(0,1)之间),是SGD的改进版,效果一般比不使用动量规则的要好。
import torch.optim as optim optimizer = optim.SGD(model.parameters(),lr=lr,momentum=momentum) -
向前传播
把输入数据传入神经网络Net实例化对象model中,自动执行forward函数,得到out输出值,然后用out与标记label计算损失值loss。
out = model(img) loss = criterion(out, label) -
清空梯度
缺省情况梯度是累加的,在梯度反向传播前,先需把梯度清零。
optimizer.zero_grad() -
反向传播
基于损失值,把梯度进行反向传播。
loss.backward() -
更新参数
基于当前梯度(存储在参数的.grad属性中)更新参数。
optimizer.step()
动态修改学习率参数
修改参数的方式可以通过修改参数optimizer.params_groups或新建optimizer。新建optimizer比较简单,optimizer十分轻量级,所以开销很小。但是新的优化器会初始化动量等状态信息,这对于使用动量的优化器(momentum参数的sgd)可能会造成收敛中的震荡。
optimizer.param_groups:长度1的list,optimizer.param_groups[0]:长度为6的字典,包括权重参数、lr、momentum等参数。
len(optimizer.param_groups[0])#结果为6
动态修改学习率参数代码:
for epoch in range(num_epoches):
#动态修改参数学习率
if epoch%5==0:
optimizer.param_groups[0]['lr']*=0.1
print(optimizer.param_groups[0]['lr'])
for img, label in train_loader:
######
优化器比较
自适应优化器在深度学习中比较受欢迎,除了性能较好,鲁棒性、泛化能力也更强。
# 1.导入需要的模块
import torch
import torch.utils.data as Data
import torch.nn.functional as F
import matplotlib.pyplot as plt
# 超参数
LR=0.01
BATCH_SIZE=32
EPOCH=12
# 2.生成数据
# 生成训练数据
# torch.unsqueeze()的作用是将一维变二维,torch只能处理二维的数据
x = torch.unsqueeze(torch.linspace(-1,1,1000),dim=1)
# 0.1 * torch.normal(x.size())增加噪点
y = x.pow(2) + 0.1 * torch.normal(torch.zeros(*x.size()))
torch_dataset = Data.TensorDataset(x,y)
# 得到一个带批量的生成器
loader = Data.DataLoader(dataset=torch_dataset,batch_size=BATCH_SIZE,shuffle=True)
# 3.构建神经网络
class Net(torch.nn.Module):
# 初始化
def __init__(self):
super(Net,self).__init__()
self.hidden = torch.nn.Linear(1,20)
self.predict = torch.nn.Linear(20,1)
# 前向传播
def forward(self,x):
x=F.relu(self.hidden(x))
x = self.predict(x)
return x
# 4.使用多种优化器
net_SGD=Net()
net_Momentum=Net()
net_RMSProp=Net()
net_Adam=Net()
nets = [net_SGD,net_Momentum,net_RMSProp,net_Adam]
opt_SGD = torch.optim.SGD(net_SGD.parameters(),lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(),lr=LR,momentum=0.9)
opt_RMProp = torch.optim.RMSprop(net_RMSProp.parameters(),lr=LR,alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(),lr=LR,betas=(0.9,0.99))
optimizers = [opt_SGD,opt_Momentum,opt_RMProp,opt_Adam]
# 5.训练模型
loss_func = torch.nn.MSELoss()
loss_his = [[],[],[],[]] #记录损失
for epoch in range(EPOCH):
for step,(batch_x,batch_y) in enumerate(loader):
for net,opt,l_his in zip(nets,optimizers,loss_his):
output = net(batch_x)
loss = loss_func(output,batch_y)
opt.zero_grad()
loss.backward()
opt.step()
l_his.append(loss.data.numpy())
labels = ['SGD','Momentum','RMSprop','Adam']
# 6.可视化结果
for i,l_his in enumerate(loss_his):
plt.plot(l_his,label=labels[i])
plt.legend(loc="best")
plt.xlabel("Steps")
plt.ylabel("Loss")
plt.ylim((0,0.2))
plt.show()
PyTorch数据处理工具箱
数据处理工具箱概述
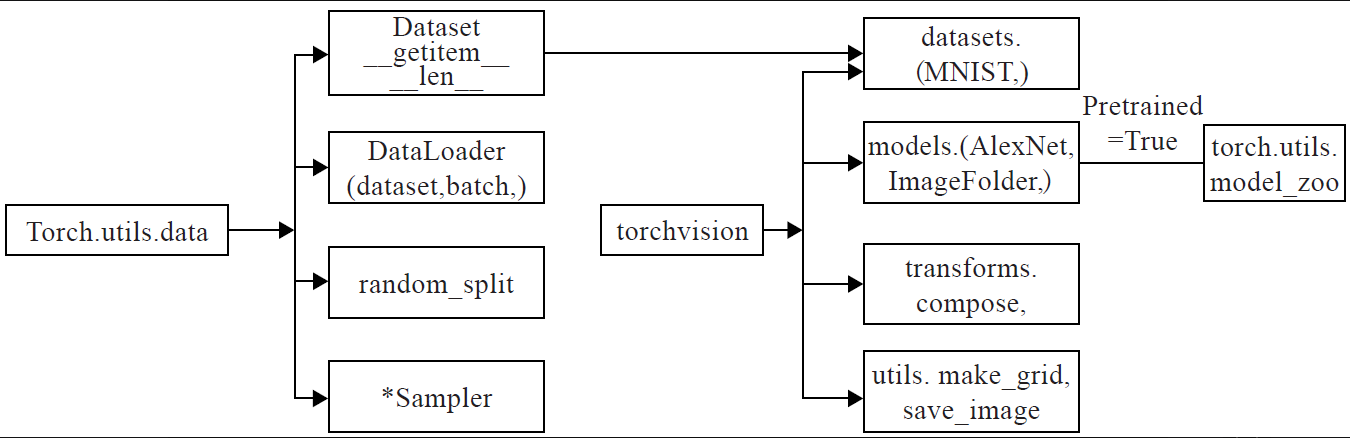
左边是torch.utils.data工具包,它包括以下4个类:
- Dataset:是一个抽象类,其他数据集需要继承这个类,并且覆写其中的两个方法(getitem_、len)。
- DataLoader:定义一个新的迭代器,实现批量(batch)读取,打乱数据(shuffle)并提供并行加速等功能。
- random_split:把数据集随机拆分为给定长度的非重叠的新数据集。
- *sampler:多种采样函数。
中间是PyTorch可视化处理工具(Torchvision),其是PyTorch的一个视觉处理工具包,需要安装:
pip install torchvision #或conda install torchvision
它包括4个类,各类的主要功能如下:
- datasets:提供常用的数据集加载,设计上都是继承自torch.utils.data.Dataset,主要包括MMIST、CIFAR10/100、ImageNet和COCO等。
- models:提供深度学习中各种经典的网络结构以及训练好的模型(如果选择pretrained=True),包括AlexNet、VGG系列、ResNet系列、Inception系列等。
- transforms:常用的数据预处理操作,主要包括对Tensor及PIL Image对象的操作。
- utils:含两个函数,一个是make_grid,它能将多张图片拼接在一个网格中;另一个是save_img,它能将Tensor保存成图片。
utils.data简介
utils.data包括Dataset和DataLoader。torch.utils.data.Dataset为抽象类。自定义数据集需要继承这个类,并实现两个函数,一个是__len__,另一个是__getitem__,前者提供数据的大小(size),后者通过给定索引获取数据和标签。__getitem__一次只能获取一个数据,所以需要通过torch.utils.data.DataLoader来定义一个新的迭代器,实现batch读取。
# 1、导入需要的模块
import torch
from torch.utils import data
import numpy as np
# 2、定义获取数据集的类
# 该类继承基类Dataset,自定义一个数据集及对应标签
class TestDataset(data.Dataset):
def __init__(self):
self.Data = np.asarray([[1,2],[3,4],[2,1],[3,4],[4,5]]) # 一些由二维向量表示的数据集
self.label = np.asarray([0,1,0,1,2]) # 这是数据集对应的标签
def __getitem__(self, index):
# 把numpy数组转换为tensor张量
txt = torch.from_numpy(self.Data[index])
label = torch.tensor(self.Data[index])
return txt,label
def __len__(self):
return len(self.Data)
# 获取数据集中数据
Test = TestDataset()
print(Test[2]) # 相当于调用__getitem__(2)
print(Test.__len__()) # 获取数据集的长度
如果希望批量处理(batch),还要同时进行shuffle和并行加速等操作,可选择DataLoader。DataLoader的格式为:
data.DataLoader(
dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=<function default_collate at 0x7f108ee01620>,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None,
)
- dataset:加载的数据集。
- batch_size:批大小。
- shuffle:是否将数据打乱。
- sampler:样本抽样。
- num_workers:使用多进程加载的进程数,0代表不使用多进程。
- collate_fn:如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可。
- pin_memory:是否将数据保存在pin memory区,pin memory中的数据转到GPU会快一些。
- drop_last:dataset中的数据个数可能不是batch_size的整数倍,drop_last为True会将多出来不足一个batch的数据丢弃。
test_loader = data.DataLoader(Test,batch_size=2,shuffle=False,num_workers=0)
for i,traindata in enumerate(test_loader):
print('i:',i)
Data,Label=traindata
print('data:',Data)
print('Label:',Label)
torchvision简介
torchvision有4个功能模块:model、datasets、transforms和utils。利用datasets可以下载一些经典数据集,本节主要介绍如何使用datasets的ImageFolder处理自定义数据集,以及如何使用transforms对源数据进行预处理、增强等。
transforms
transforms提供了对PIL Image对象和Tensor对象的常用操作。
对PIL Image的常见操作如下:
- Scale/Resize:调整尺寸,长宽比保持不变。
- CenterCrop、RandomCrop、RandomSizedCrop:裁剪图片,CenterCrop和RandomCrop在crop时是固定size,RandomResizedCrop则是random size的crop。
- Pad:填充
- ToTensor:把一个取值范围是[0,255]的PIL.Image转换成Tensor。形状为(H,W,C)的Numpy.ndarray转换成形状为[C,H,W],取值范围是[0,1.0]的torch.FloatTensor。
- RandomHorizontalFlip:图像随机水平翻转,翻转概率为0.5。
- RandomVerticalFlip:图像随机垂直翻转。
- ColorJitter:修改亮度、对比度和饱和度。
对Tensor的常见操作如下:
- Normalize:标准化,即,减均值,除以标准差。
- ToPILImage:将Tensor转为PIL Image。
如果要对数据集进行多个操作,可通过Compose将这些操作像管道一样拼接起来,类似于nn.Sequential。以下为示例代码:
transforms.Compose([
#将给定的 PIL.Image 进行中心切割,得到给定的 size,
#size 可以是 tuple,(target_height, target_width)。
#size 也可以是一个 Integer,在这种情况下,切出来的图片形状是正方形。
transforms.CenterCrop(10),
#切割中心点的位置随机选取
transforms.RandomCrop(20, padding=0),
#把一个取值范围是 [0, 255] 的 PIL.Image 或者 shape 为 (H, W, C) 的 numpy.ndarray,
#转换为形状为 (C, H, W),取值范围是 [0, 1] 的 torch.FloatTensor
transforms.ToTensor(),
#规范化到[-1,1]
transforms.Normalize(mean = (0.5, 0.5, 0.5), std = (0.5, 0.5, 0.5))
])
还可以自己定义一个Python Lambda表达式,如将每个像素值加10,可表示为:transforms.Lambda(lambda x:x.add(10))。
ImageFolder
当文件依据标签处于不同文件下时,如:

可以利用torchvision.datasets.ImageFolder来直接构造出dataset:
import torchvision.datasets as datasets
loader = datasets.ImageFolder(path)
loader = datasets.DatasetFolder(dataset)
ImageFolder会将目录中的文件夹名自动转化成序列,当DataLoader载入时,标签自动就是整数序列了。
下面我们利用ImageFolder读取不同目录下的图片数据,然后使用transforms进行图像预处理,预处理有多个,我们用compose把这些操作拼接在一起。然后使用DataLoader加载。
对处理后的数据用torchvision.utils中的save_image保存为一个png格式文件,然后用Image.open打开该png文件,详细代码如下:
from torchvision import transforms,utils
from torchvision import datasets
import torch
import matplotlib.pyplot as plt
import torch.utils.data as Data
my_trans = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
])
train_data = datasets.ImageFolder('./data/torchvision_data',transform=my_trans)
train_loader = Data.DataLoader(train_data,batch_size=8,shuffle=True,num_workers=0)
for i_batch,img in enumerate(train_loader):
if i_batch==0:
print(img[1])
fig = plt.figure()
grid = utils.make_grid(img[0])
plt.imshow(grid.numpy().transpose((1,2,0)))
plt.show()
utils.save_image(grid,'test01.png')
break
可视化工具
tensorboardX简介
安装
pip install tensorboardX
使用tensorboardX的一般步骤:
-
导入tensorboardX,实例化SummaryWriter类,指明记录日志路径等信息
from tensorboardX import SummaryWriter # 实例化ssummarywriter对象,并指明日志文件保存路径。在当前目录没有logs目录时会自动创建 writer = SummaryWriter(log_dir="logs") # 调用实例 writer.add_xxx() # 关闭writer writer.close()说明:
-
如果是Windows环境,log_dir注意路径解析,如:
writer = SummaryWriter(log_dir=r'D:\myboard\test\logs') -
SummaryWriter的格式为:
SummaryWriter(log_dir=None, comment='', **kwargs) #其中comment在文件命名加上comment后缀 -
如果不写log_dir,系统将在当前目录创建一个runs的目录
-
-
调用相应的API接口,接口一般格式为:
add_xxx(tag-name, object, iteration-number) #即add_xxx(标签,记录的对象,迭代次数) -
启动tensorboard服务:
cd到logs目录所在的同级目录,在命令行输入如下命令,logdir等式右边可以是相对路径或绝对路径。
tensorboard --logdir=logs --port 6006 #如果是Windows环境,要注意路径解析,如 #tensorboard --logdir=r'D:\myboard\test\logs' --port 6006 -
web展示
在浏览器输入:
http://服务器IP或名称:6006 #如果是本机,服务器名称可以使用localhost
用tensorboardX可视化神经网络
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from tensorboardX import SummaryWriter
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1,10,kernel_size=5)
self.conv2 = nn.Conv2d(10,20,kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320,50)
self.fc2 = nn.Linear(50,10)
self.bn = nn.BatchNorm1d(20)
def forward(self,x):
x = F.max_pool2d(self.conv1(x),2)
x = F.relu(x) + F.relu(-x)
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)),2))
x = self.bn(x)
x = x.view(-1,320)
x = F.relu(self.fc1(x))
x = F.dropout(x,training=self.training)
x = self.fc2(x)
x = F.softmax(x,dim=1)
return x
# 把模型保存为graph
# 定义输入
input = torch.rand(32,1,28,28)
# 实例化神经网络
model = Net()
# 将model保存为graph
with SummaryWriter(logdir='logs',comment='Net') as w:
w.add_graph(model,(input,))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号