时间序列
日期和时间数据的类型及工具
from datetime import datetime
# datetime
now = datetime.now()
print(now.year,now.month,now.day)
# datetime.timedelta表示两个datetime对象之间的时间差
delta = datetime(2011,1,7)-datetime(2008,6,24,8,15) # 926 days, 15:45:00
delta.days # 926
delta.seconds # 56700
# 可以给datetime对象加上(或减去)一个或多个timedelta
from datetime import timedelta
start = datetime(2011,1,7)
start+timedelta(12)
start-2*timedelta(12)
# 利用str或strftime方法并传入指定格式,可以将datetime对象和pandas的Timestamp对象格式化为字符串
stamp = datetime(2011,1,3)
str(stamp) # '2011-01-03 00:00:00'
stamp.strftime("%Y-%m-%d") # '2011-01-03'
# 使用datetime.strptime和这些格式编码(但不能使用某些编码,比如%F),可以将字符串转换为日期:
value = "2011-01-03"
datetime.strptime(value,"%Y-%m-%d")
datetime模块中的数据类型:
- date:以公历形式存储日历日期(年、月、日)
- time:将时间存储为时、分、秒和微秒
- datetime:存储日期和时间
- timedelta:两个datetime值之间的差(日、秒、微秒)
- tzinfo:存储时区信息的基础类型
datetime格式说明(兼容ISO C89):
-
%Y:四位数的年
-
%y:两位数的年
-
%m:两位数的月[01,12]
-
%d:两位数的日[01,31]
-
%H:小时(24小时制)[00,23]
-
%I:小时(12小时制)[01,12]
-
%M:两位数的分[00,59]
-
%S:秒[00,61](秒60和61用于闰秒)
-
%f:整数形式的微秒,零填充(从000000到999999)
-
%j:年中的第几天,为零填充的整数(从001到366)
-
%w:用整数表示的星期几[0(星期天),6]
-
%u:用整数表示的星期几,从1开始,1为星期一
-
%U:每年的第几周[00,53]:星期天作为每周的第一天,每年第一个星期天之前的若干天属于“第0周”
-
%W:每年的第几周[00,53]:星期一被认为是每周的第一天,每年第一个星期一之前的若干天属于“第0周”
-
%z:以+HHMM或-HHMM表示的UTC时区偏移量,如果没有时区则为空
-
%Z:字符串形式的时区名,如果没有时区则为空字符串
-
%F:%Y-%m-%d的快捷简写(例如,2012-4-18)
-
%D:%m/%d/%y的快捷简写(例如,04/18/12)
pandas通常用于处理日期数组,不管这些日期是DataFrame的轴索引还是列:
# pandas.to_datetime方法可以解析多种不同的日期表示形式
datestrs = ["2011-07-06 12:00:00","2011-08-06 00:00:00"]
pd.to_datetime(datestrs) # DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00'], dtype='datetime64[ns]', freq=None)
# pandas.to_datetime方法还可以处理应当作为缺失值的值(None、空字符串等)
idx = pd.to_datetime(datestrs+[None]) # NaT(Not a Time)用于表示pandas中时间戳数据的空值
# DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00', 'NaT'], dtype='datetime64[ns]', freq=None)
特定地区的日期格式化:
- %a:简写的工作日名称
- %A:工作日全称
- %b:简写的月份
- %B:完整的月份
- %c:完整的日期和时间(例如,Tue01May201204:20:57PM)
- %p:表示AM或PM的本地格式
- %x:适合本地的日期格式(例如,在美国May1,2012会变为05/01/2012)
- %X:适合本地的时间格式(例如,04:24:12PM)
时间序列基础知识
# 以时间戳为索引的Series
dates = [datetime(2011,1,2),datetime(2011,1,5),
datetime(2011,1,7),datetime(2011,1,8)
,datetime(2011,1,10),datetime(2011,1,12)]
ts = pd.Series(np.random.standard_normal(6),index=dates)
# 不同索引的时间序列之间的算术运算会自动按日期对齐
ts + ts[::2]
# 2011-01-02 2.479692
# 2011-01-05 NaN
# 2011-01-07 3.979818
# 2011-01-08 NaN
# 2011-01-10 0.445173
# 2011-01-12 NaN
# dtype: float64
索引、选取、子集构造
# 根据标签进行索引和选取数据
stamp = ts.index[2]
ts[stamp]
# 传入一个可以解释为日期的字符串
ts["2011-01-10"]
# 对于较长的时间序列,只需传入“年”或“年月”即可轻松选取数据的切片
longer_ts = pd.Series(np.random.standard_normal(1000),
index=pd.date_range("2000-01-01",periods=1000))
# 2000-01-01 0.149029
# 2000-01-02 -0.436183
# 2000-01-03 -0.285143
# 2000-01-04 1.617606
# 2000-01-05 -0.216020
# 选取2001年5月份的数据
longer_ts["2001-05"]
# 时间切片
ts[datetime(2011,1,7):]
ts[datetime(2011,1,7):datetime(2011,1,10)]
# 由于大部分时间序列数据都是按照时间先后排序的,因此也可以用不存在于该时间序列中的时间戳对其进行范围查询
ts["2011-01-06":"2011-01-11"]
与之前一样,可以传入字符串日期、datetime或Timestamp。注意,这样切片所产生的是原时间序列的视图,与NumPy数组的切片运算是一样的。这意味着不会复制数据,对切片进行修改会反映到原始数据上。
# 还有一个等价的实例方法truncate,也可以截取两个日期之间的Series
ts.truncate(after="2011-01-09")
# 所有这些操作对DataFrame也有效,并对DataFrame的行进行索引
dates = pd.date_range("2000-01-01",periods=100,freq="W-WED")
long_df = pd.DataFrame(np.random.standard_normal((100,4)),
index=dates,
columns=["Colorado","Texas","New York","Ohio"])
long_df.loc["2001-05"]
带有重复索引的时间序列
dates = pd.DatetimeIndex(["2000-01-01","2000-01-02","2000-01-02","2000-01-02","2000-01-03"])
dup_ts = pd.Series(np.arange(5),index=dates)
# 通过检查索引的is_unique属性,就可以知道索引是不是唯一的
dup_ts.index.is_unique
# 对这个时间序列进行索引,取决于时间戳是否重复,要么生成标量值,要么生成切片
dup_ts["2000-01-02"]
# 2000-01-02 1
# 2000-01-02 2
# 2000-01-02 3
# 假设你想对具有重复时间戳的数据进行聚合,一个办法是使用groupby,并传入level=0(存在的唯一层级
grouped = dup_ts.groupby(level=0)
grouped.mean()
grouped.count()
日期的范围、频率以及移位
dates = [datetime(2011,1,2),datetime(2011,1,5),
datetime(2011,1,7),datetime(2011,1,8)
,datetime(2011,1,10),datetime(2011,1,12)]
ts = pd.Series(np.random.standard_normal(6),index=dates)
# 通过调用resample方法,可以将样本时间序列转换为具有固定日频率的序列:
# 符串"D"被解释为每日的频率
resampler = ts.resample("D")
生成日期范围
# pandas.date_range还可以用于根据指定频率生成特定长度的DatetimeIndex
index = pd.date_range("2012-04-01","2012-06-01")
# 如果只传入起始日期或结束日期,还必须传入要生成的周期个数
pd.date_range(start="2012-04-01",periods=20)
pd.date_range(end="2012-06-01",periods=20)
# 如果你想生成一个由每月最后一个工作日组成的日期索引,可以传入频率"BM"
pd.date_range("2000-01-01","2000-12-01",freq="BM")
基本的时间序列频率:
| 别名 | 偏移量类型 | 说明 |
|---|---|---|
| D | Day | 日历日的每天 |
| B | BusinessDay | 工作日的每天 |
| H | Hour | 每时 |
| T 或 min | Minute | 每分 |
| S | Second | 每秒 |
| L 或 ms | Milli | 每毫秒(即每千分之一秒) |
| U | Micro | 每微秒(即每百万分之一秒) |
| M | MonthEnd | 每月最后一个日历日 |
| BM | BusinessMonthEnd | 每月最后一个工作日 |
| MS | MonthBegin | 每月第一个日历日 |
| BMS | BusinessMonthBegin | 每月第一个工作日 |
| W-MON,W-TUE,.. | Week | 从指定的星期几(MON、TUE、WED、THU、FRI、SAT、SUN)开始算起,每周取日期 |
| WOM-1MON,WOM-2MON,... | k0fMonth | 产生每月第一、第二、第三或第四周,..的星期几。例如WOM-3FRI表示每月第3个星期五 |
| Q-JAN, Q-FEB,... | QuarterEnd | 对于以指定月份(JAN、FEB、MAR、APRMAY、JUN、JUL、AUG、SEP、OCT、NOV、DEC)结束的年度,每季度最后一月的最后一个日历日 |
| BQ-JAN,BQ-FEB,.. | BusinessQuarterEnd | 对于以指定月份结束的年度,每季度最后一月的最后一个工作日 |
| QS-JAN, QS-FEB,... | QuarterBegin | 对于以指定月份结束的年度,每季度最后一月的第一个日历日 |
| BQS-JAN,BQS-FEB | BBusinessQuarterBegin | 对于以指定月份结束的年度,每季度最后一月的第一个工作日 |
| A-JAN,A-FEB,.. | YearEnd | 每年指定月份(JAN、FEB、MAR、APR、MAY、JUN、JUL、AUG、SEP、OCT、NOV、DEC)的最后一个日历日 |
| BA-JAN, BA-FEB,... | BusinessYearEnd | 每年指定月份的最后一个工作日 |
| AS-JAN,AS-FEB,... | YearBegin | 每年指定月份的第一个日历日 |
| BAS-JAN,BAS-FEB,... | BusinessYearBegin | 每年指定月份的第一个工作日 |
# pandas.date_range默认会保留起始时间戳和结束时间戳的时间信息(如果有的话)
pd.date_range("2012-05-02 12:56:31",periods=5)
# DatetimeIndex(['2012-05-02 12:56:31', '2012-05-03 12:56:31',
# '2012-05-04 12:56:31', '2012-05-05 12:56:31',
# '2012-05-06 12:56:31'],
# dtype='datetime64[ns]', freq='D')
# 虽然起始日期和结束日期带有时间信息,但你希望生成一组标准化到晚间零点的时间戳,normalize选项可以实现该功能
pd.date_range("2012-05-02 12:56:31",periods=5,normalize=True)
频率和日期偏移量
pandas中的频率是由基础频率和倍数组成的。基础频率通常以一个字符串别名表示,比如"M"表示每月,"H"表示每小时。对于每个基础频率,都有一个称为日期偏移量的对象与之对应。
# 每小时的频率可以用Hour类表示
from pandas.tseries.offsets import Hour,Minute
hour = Hour()
# 传入一个整数即可定义偏移量的倍数
four_hours = Hour(4)
# 对于大多数应用,无须显式创建这样的对象,只需使用诸如"H"或"4H"这样的字符串别名。在基础频率前面加上一个整数即可创建倍数
pd.date_range("2000-01-01","2000-01-03 23:59",freq="4H")
# DatetimeIndex(['2000-01-01 00:00:00', '2000-01-01 04:00:00',
# '2000-01-01 08:00:00', '2000-01-01 12:00:00',
# '2000-01-01 16:00:00', '2000-01-01 20:00:00',
# '2000-01-02 00:00:00', '2000-01-02 04:00:00',
# '2000-01-02 08:00:00', '2000-01-02 12:00:00',
# '2000-01-02 16:00:00', '2000-01-02 20:00:00',
# '2000-01-03 00:00:00', '2000-01-03 04:00:00',
# '2000-01-03 08:00:00', '2000-01-03 12:00:00',
# '2000-01-03 16:00:00', '2000-01-03 20:00:00'],
# dtype='datetime64[ns]', freq='4h')
# 大部分偏移量对象都可通过加法进行连接
Hour(2)+Minute(30)
# 也可以传入频率字符串,比如"1h30min",它可以被高效地解析为等效的表达式
pd.date_range("2000-01-01",periods=10,freq="1h30min")
list(monthly_dates)
# [Timestamp('2012-01-20 00:00:00'), Timestamp('2012-02-17 00:00:00'), Timestamp('2012-03-16 00:00:00'), Timestamp('2012-04-20 00:00:00'), Timestamp('2012-05-18 00:00:00'), Timestamp('2012-06-15 00:00:00'), Timestamp('2012-07-20 00:00:00'), Timestamp('2012-08-17 00:00:00')]
对超前和滞后数据进行移位
移位(shifting)是指沿着时间轴将数据前移或后移。Series和DataFrame都有一个shift方法,用于执行单纯的前移或后移操作,并保持索引不变:
ts = pd.Series(np.random.standard_normal(4),
index=pd.date_range("2000-01-01",periods=4,freq="M"))
# 2000-01-31 0.677049
# 2000-02-29 -1.828040
# 2000-03-31 0.878885
# 2000-04-30 -1.142629
# Freq: ME, dtype: float64
ts.shift(2)
# 2000-01-31 NaN
# 2000-02-29 NaN
# 2000-03-31 -1.247258
# 2000-04-30 -0.700633
# Freq: ME, dtype: float64
ts.shift(-2)
# 2000-01-31 0.802095
# 2000-02-29 0.736439
# 2000-03-31 NaN
# 2000-04-30 NaN
# Freq: ME, dtype: float64
# shift通常用于计算一个时间序列或多个时间序列(如DataFrame的列)中的连续百分比变化。可以这样表达:
ts / ts.shift(1) - 1
# 由于单纯的移位操作不会修改索引,因此部分数据会被丢弃。如果频率已知,则可以将其传给shift以便实现对时间戳进行移位,而不是对数据进行简单位移:
ts.shift(2,freq="M")
# 2000-03-31 -1.202354
# 2000-04-30 -2.380137
# 2000-05-31 -1.475926
# 2000-06-30 0.082859
# Freq: ME, dtype: float64
ts.shift(3,freq="D") # 天
# 这里的T代表的是分钟。注意,参数freq表明移位是针对时间戳的,但没有修改底层的数据频率(如果存在的话)。
ts.shift(1,freq="90T")
通过偏移量对日期进行移位:
# pandas的日期偏移量还可以用在datetime或Timestamp对象上
from pandas.tseries.offsets import Day,MonthEnd
now = datetime(2011,11,17)
now + 3 * Day()
# pandas的日期偏移量还可以用在datetime或Timestamp对象上
now+MonthEnd()
now + MonthEnd(2)
# 通过锚定偏移量的rollforward和rollback方法,可显式地将日期向前或向后“滚动
offset = MonthEnd()
offset.rollback(now) # 向后
offset.rollback(now) # 向前
# 日期偏移量还有一个巧妙的用法,即结合groupby使用这两个“滚动”方法
ts = pd.Series(np.random.standard_normal(20),
index=pd.date_range("2000-01-15",periods=20,freq="4D"))
ts.groupby(MonthEnd().rollforward).mean()
# 更简单、更快速地实现该功能的办法是使用resample
ts.resample("M").mean()
时区处理
在Python中,时区信息来自第三方库pytz(使用pip或conda进行安装),它使Python可以使用Olson数据库(汇编了世界时区信息)。
pytz.common_timezones[-5:] # ['US/Eastern', 'US/Hawaii', 'US/Mountain', 'US/Pacific', 'UTC']
# 要从pytz中获取时区对象,使用pytz.timezone即可
tz = pytz.timezone("America/New_York") # America/New_York
时区本地化和转换
默认情况下,pandas中的时间序列就是简单的时区。
dates = pd.date_range("2012-03-09 09:30",periods=6)
ts = pd.Series(np.random.standard_normal(len(dates)),index=dates)
ts.index.tz # None
# 可以用时区集合生成日期范围:
pd.date_range("2012-03-09 09:30",periods=10,tz="UTC")
# DatetimeIndex(['2012-03-09 09:30:00+00:00', '2012-03-10 09:30:00+00:00',
# '2012-03-11 09:30:00+00:00', '2012-03-12 09:30:00+00:00',
# '2012-03-13 09:30:00+00:00', '2012-03-14 09:30:00+00:00',
# '2012-03-15 09:30:00+00:00', '2012-03-16 09:30:00+00:00',
# '2012-03-17 09:30:00+00:00', '2012-03-18 09:30:00+00:00'],
# dtype='datetime64[ns, UTC]', freq='D')
# 从简单时区到本地化时区(以特定时区重新观测数据)的转换是通过tz_localize方法实现的:
ts_utc = ts.tz_localize("UTC")
# 一旦时间序列被本地化到某个特定时区,就可以用tz_convert将其转换到其他时区了
ts_utc.tz_convert("America/New_York")
# tz_localize和tz_convert也是DatetimeIndex的实例方法:
ts_utc.index.tz_localize("Asia/Shanghai")
对时区型时间戳对象的操作
# 独立的Timestamp对象也能从简单型本地化为时区型,并从一个时区转换到另一个时区
stamp = pd.Timestamp("2011-03-12 04:00")
stamp_utc = stamp.tz_localize("utc")
stamp_utc.tz_convert("America/New_York")
# 在创建Timestamp时,还可以传入时区信息:
stamp_moscow = pd.Timestamp("2011-03-12 04:00",tz="Europe/Moscow")
# 时区型Timestamp对象在内部保存了UTC时间戳值——一个自UNIX纪元(1970年1月1日)算起的纳秒数。
# 因此转换时区不会改变内部UTC值:
stamp_utc.value
stamp_utc.tz_convert("America/New_York").value
当使用pandas的DateOffset对象执行时间算术运算时,运算过程会自动关注是否存在夏令时转变期。这里,我们创建了在DST转变之前的时间戳(通过运算在转变期的前后移动。
# 来看夏令时转变前的30分钟
stamp = pd.Timestamp("2012-03-11 01:30",tz="US/Eastern") # 2012-03-11 01:30:00-05:00
stamp + Hour() # 2012-03-11 03:30:00-04:00
# 夏令时转变前的90分钟
stamp = pd.Timestamp("2012-03-11 00:30",tz="US/Eastern") # 2012-03-11 00:30:00-05:00
stamp +2 * Hour() # 2012-03-11 03:30:00-04:00
不同时区之间的运算
如果两个时间序列的时区不同,在将它们合并到一起时,最终结果就会是UTC。由于时间戳其实是存储在UTC内部的,因此这是个直接运算,不需要做任何转换:
ts1 = ts[:7].tz_localize("Europe/London")
ts2 = ts1[2:].tz_convert("Europe/Moscow")
result = ts1 + ts2
result.index
# DatetimeIndex(['2012-03-07 09:30:00+00:00', '2012-03-08 09:30:00+00:00',
# '2012-03-09 09:30:00+00:00', '2012-03-12 09:30:00+00:00',
# '2012-03-13 09:30:00+00:00', '2012-03-14 09:30:00+00:00',
# '2012-03-15 09:30:00+00:00'],
# dtype='datetime64[ns, UTC]', freq=None)
简单型和时区型的对象间不支持运算,如果运算将会抛出异常。
周期及其算术运算
周期表示的是时间段,比如数日、数月、数季、数年等。pandas.Period类所表示的就是这种数据类型,它需要用到字符串或整数,以及表中的频率:
# Period对象表示的是从2011年1月1日到2011年12月31日之间的整段时间
p = pd.Period("2011",freq="A-DEC")
# 只需对周期对象加上或减去一个整数,就可以移动其频率
p + 5 # 2016
p-2
# 如果两个周期对象拥有相同的频率,则二者的差就是它们之间日期偏移量的单位数量
pd.Period("2014",freq="A-DEC") - p # <3 * YearEnds: month=12>
# period_range函数可用于创建规则的周期范围
periods = pd.period_range("2000-01-01","2000-06-30",freq="M")
# PeriodIndex(['2000-01', '2000-02', '2000-03', '2000-04', '2000-05', '2000-06'], dtype='period[M]')
# PeriodIndex类保存了一组周期序列,它可以在任何pandas数据结构中用作轴索引
pd.Series(np.random.standard_normal(6),index=periods)
# 如果你有一个字符串数组,也可以使用PeriodIndex类(所有值均为周期对象)
values = ["2001Q3","2002Q2","2003Q1"]
index = pd.PeriodIndex(values,freq="Q-DEC")
周期的频率转换
周期和PeriodIndex对象都可以通过其asfreq方法转换为别的频率。
# 假设我们有一个年度周期,希望将其转换为当年年初或年末的一个月度周期,可以如下实现:
p = pd.Period("2011",freq="A-DEC")
p.asfreq("M",how="start")
p.asfreq("M",how="end")
p.asfreq("M")
可以将Period('2011','A-DEC')看作一个时间段中的游标,该时间段被划分为多个月度周期。对于不是以十二月作为结束月的财政年度,相应的月度的子周期是不同的:
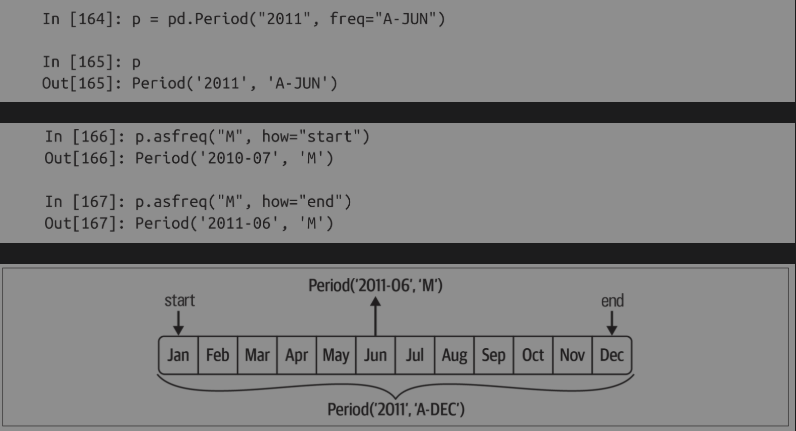
# 在将高频率转换为低频率时,根据父周期的归属情况,pandas确定了周期
# 在A-JUN频率中,月份Aug-2011实际上是属于周期2012的
p = pd.Period("Aug-2011","M")
p.asfreq("A-JUN") # 2012
# 完整的PeriodIndex或时间序列也可以用相同的语法进行转换
periods = pd.period_range("2006","2009",freq="A-DEC")
ts = pd.Series(np.random.standard_normal(len(periods)),index=periods)
# 2006 0.105699
# 2007 -0.309283
# 2008 -0.925747
# 2009 -0.159156
# Freq: Y-DEC, dtype: float64
ts.asfreq("M",how="start")
# 2006-01 0.105699
# 2007-01 -0.309283
# 2008-01 -0.925747
# 2009-01 -0.159156
# Freq: M, dtype: float64
ts.asfreq("B",how="end")
# 2006-12-29 1.278334
# 2007-12-31 0.366932
# 2008-12-31 0.710241
# 2009-12-31 -0.168008
# Freq: B, dtype: float64
季度周期频率
季度数据在会计、金融等领域很常见。许多季度数据都会涉及“财年末”的概念,通常是一年12个月中某月的最后一个日历日或工作日。就这一点来说,周期2012Q4根据财年末的不同会有不同的含义。
# pandas支持12种可能的季度频率,即Q-JAN到Q-DEC:
p = pd.Period("2012Q4",freq="Q-JAN") # 在以1月结束的财年中,2012Q4是从2011年11月到2012年1月。
不同季度频率之间的转换如下图:
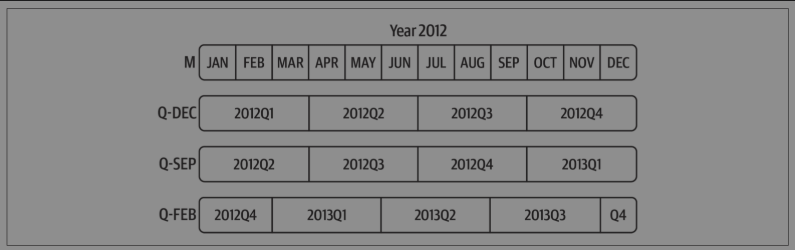
# 要获取该季度倒数第二个工作日下午4点的时间戳,可以这样做
p4pm = (p.asfreq("B",how="end") - 1).asfreq("T",how="start") + 16 * 60
# pandas.period_range可用于生成季度时间范围。季度时间范围的算术运算跟上面是一样的:
periods = pd.period_range("2011Q3","2012Q4",freq="Q-JAN")
ts = pd.Series(np.arange(len(periods)),index=periods)
# 2011Q3 0
# 2011Q4 1
# 2012Q1 2
# 2012Q2 3
# 2012Q3 4
# 2012Q4 5
# Freq: Q-JAN, dtype: int64
new_periods = (periods.asfreq("B","end") -1 ).asfreq("H","start") + 1
ts.index = new_periods.to_timestamp()
# 2010-10-28 01:00:00 0
# 2011-01-28 01:00:00 1
# 2011-04-28 01:00:00 2
# 2011-07-28 01:00:00 3
# 2011-10-28 01:00:00 4
# 2012-01-30 01:00:00 5
# dtype: int64
时间戳和周期的相互转换
通过使用to_period方法,可以将由时间戳索引的Series和DataFrame对象转换为以周期作为索引:
dates = pd.date_range("2000-01-01",periods=3,freq="M")
ts = pd.Series(np.random.standard_normal(3),index=dates)
# 2000-01-31 0.409628
# 2000-02-29 -1.218067
# 2000-03-31 -0.473066
# Freq: ME, dtype: float64
pts = ts.to_period()
# 2000-01 0.059742
# 2000-02 1.174967
# 2000-03 -0.645208
# Freq: M, dtype: float64
由于周期指的是非重叠时间段,因此对于给定的频率,一个时间戳只能属于一个周期。新PeriodIndex的频率默认是从时间戳推断而来的,你也可以指定任何支持的频率:
dates = pd.date_range("2000-01-29",periods=6)
ts2 = pd.Series(np.random.standard_normal(6),index=dates)
# 2000-01-29 0.467004
# 2000-01-30 0.879966
# 2000-01-31 0.032719
# 2000-02-01 -1.150564
# 2000-02-02 0.601257
# 2000-02-03 0.252213
# Freq: D, dtype: float64
ts2.to_period("M")
# 2000-01 0.467004
# 2000-01 0.879966
# 2000-01 0.032719
# 2000-02 -1.150564
# 2000-02 0.601257
# 2000-02 0.252213
# Freq: M, dtype: float64
# 要转换回时间戳,使用to_timestamp即可
pts.to_timestamp(how="end")
通过数组创建PeriodIndex
固定频率的数据集通常会将时间信息分开存放在多个列中。
year = pd.Series([1959,1960,1961])
quarter = pd.Series([1,2,3])
# PeriodIndex(['1959Q1', '1960Q2', '1961Q3'], dtype='period[Q-DEC]')
index = pd.PeriodIndex(year=year,quarter=quarter,freq="Q-DEC")
重采样及频率转换
重采样指的是将时间序列从一个频率转换到另一个频率的处理过程。将高频率数据连接到低频率称为降采样,而将低频率数据转换到高频率则称为升采样。并不是所有的重采样都能被划分到这两大类中。例如,将W-WED(每周三)转换为W-FRI既不是降采样也不是升采样。
# resample有一个类似于groupby的API,调用resample可以对数据进行分组,然后调用聚合函数:
dates = pd.date_range("2000-01-01",periods=100)
ts = pd.Series(np.random.standard_normal(len(dates)),index=dates)
ts.resample("M").mean()
# 2000-01-31 0.119976
# 2000-02-29 -0.394672
# 2000-03-31 0.157229
# 2000-04-30 -0.143676
# Freq: ME, dtype: float64
ts.resample("M",kind="period").mean()
# 2000-01 0.230413
# 2000-02 0.073806
# 2000-03 0.106564
# 2000-04 -0.121623
# Freq: M, dtype: float64
resample方法的参数:
- rule:用于指明重采样频率的字符串、DateOffset、timedelta对象(例如,M、5min或Second(15))
- axis:重采样的轴,默认为axis=0
- fill_method:升采样时如何插值,比如,"ffill"或"bfill"。默认不插值
- closed:在降采样中各时间段的哪一端是闭合(即包含)的,“right"或“left"
- label:在降采样中如何设置聚合值的标签,分箱边界为"right"或"left"(例如,对于9:30到9:35之间的五分钟区间,标签为9:30或9:35)
- limit:在前向填充或后向填充时,允许填充的最大周期数
- kind:聚合到周期("period")或时间戳("timestamp"),默认聚合到时间序列的索引类型
- convention:当对周期进行重采样时,将低频周期转换为高频周期的惯用法("start”或"end"),默认是"start"
- origin:用于确定重采样分箱边界的“基础”时间戳,可以是"epoch"、"start"、"start_day"、"end"、"end_day"其中之一,完整细节见resample的文档字符串
- offset:添加到origin的偏移时间差,默认为None
降采样
在用resample对数据进行降采样时,需要考虑两件事:
- 各区间哪边是闭合的。
- 如何对各个聚合分箱打标签,是用区间的开头还是末尾。
# 我们来看一些频率为一分钟的数据
dates = pd.date_range("2000-01-01",periods=12,freq="T")
ts = pd.Series(np.arange(len(dates)),index=dates)
# 通过各组求和的方式将这些数据聚合到“五分钟”的数据块或柱状图的柱中
ts.resample("5min").sum() # 传入的频率将会以“五分钟”的增量定义分箱边界。对于这个频率,分箱是默认包含左边界的,因此00:00到00:05的区间是包含00:00的
# 2000-01-01 00:00:00 10
# 2000-01-01 00:05:00 35
# 2000-01-01 00:10:00 21
# Freq: 5min, dtype: int64
# 最终的时间序列是以各分箱左边界的时间戳进行标记的
ts.resample("5min",closed="right").sum()
# 1999-12-31 23:55:00 0
# 2000-01-01 00:00:00 15
# 2000-01-01 00:05:00 40
# 2000-01-01 00:10:00 11
# Freq: 5min, dtype: int64
# 传入label="right",即可用分箱的右边界对其进行标记
ts.resample("5min",closed="right",label="right").sum()
# 2000-01-01 00:00:00 0
# 2000-01-01 00:05:00 15
# 2000-01-01 00:10:00 40
# 2000-01-01 00:15:00 11
# Freq: 5min, dtype: int64
# 你可能希望对结果索引做一些位移,比如从右边界减去一秒,使其更容易分清该时间戳到底表示的是哪个区间;只需对结果索引添加一个偏移量即可实现
from pandas.tseries.frequencies import to_offset
result = ts.resample("5min",closed="right",label="right").sum()
result.index = result.index + to_offset("-1s")
# 1999-12-31 23:59:59 0
# 2000-01-01 00:04:59 15
# 2000-01-01 00:09:59 40
# 2000-01-01 00:14:59 11
# Freq: 5min, dtype: int64
开-高-低-收(OHLC)重采样:
在金融领域,一种常用的时间序列聚合方式是计算各个桶的4个值,即第一个值(open,开盘)、最后一个值(close,收盘)、最大值(high,最高)以及最小值(low,最低)。
# 通过ohlc聚合函数,即可得到一个含有这4种聚合值的DataFrame,整个过程很高效,只需经过一次函数调用
ts = pd.Series(np.random.permutation(np.arange(len(dates))),index=dates)
ts.resample("5min").ohlc()
# open high low close
# 2000-01-01 00:00:00 8 10 0 0
# 2000-01-01 00:05:00 6 9 1 3
# 2000-01-01 00:10:00 4 11 4 11
升采样和插值
升采样是将数据从低频率转换为高频率,不需要做聚合。
frame = pd.DataFrame(np.random.standard_normal((2,4)),
index=pd.date_range("2000-01-01",periods=2,freq="W-WED"),
columns=["Colorado","Texas","New York","Ohio"])
# Colorado Texas New York Ohio
# 2000-01-05 -0.194153 0.556775 2.156055 -0.341275
# 2000-01-12 0.214674 -0.064093 -1.073947 1.186780
# 使用asfreq方法将其转换为高频率数据
df_daily = frame.resample("D").asfreq()
# Colorado Texas New York Ohio
# 2000-01-05 1.241783 -0.911819 -0.998386 -0.877590
# 2000-01-06 NaN NaN NaN NaN
# 2000-01-07 NaN NaN NaN NaN
# 2000-01-08 NaN NaN NaN NaN
# 2000-01-09 NaN NaN NaN NaN
# 2000-01-10 NaN NaN NaN NaN
# 2000-01-11 NaN NaN NaN NaN
# 2000-01-12 0.953335 0.576465 0.822951 0.607682
# 假设你想用前面的每周数值来填充非星期三的日期。
# fillna和reindex方法中可用的填充和插值方法也可以用于重采样:
frame.resample("D").ffill()
# Colorado Texas New York Ohio
# 2000-01-05 0.542464 0.695223 -0.139967 0.744035
# 2000-01-06 0.542464 0.695223 -0.139967 0.744035
# 2000-01-07 0.542464 0.695223 -0.139967 0.744035
# 2000-01-08 0.542464 0.695223 -0.139967 0.744035
# 2000-01-09 0.542464 0.695223 -0.139967 0.744035
# 2000-01-10 0.542464 0.695223 -0.139967 0.744035
# 2000-01-11 0.542464 0.695223 -0.139967 0.744035
# 2000-01-12 -1.067251 -0.281277 0.985272 -0.906820
# 这里也可以只填充指定的周期数,以限制观测值的持续范围:
frame.resample("D").ffill(limit=2)
# Colorado Texas New York Ohio
# 2000-01-05 -0.515932 -1.563824 -1.344832 -0.353373
# 2000-01-06 -0.515932 -1.563824 -1.344832 -0.353373
# 2000-01-07 -0.515932 -1.563824 -1.344832 -0.353373
# 2000-01-08 NaN NaN NaN NaN
# 2000-01-09 NaN NaN NaN NaN
# 2000-01-10 NaN NaN NaN NaN
# 2000-01-11 NaN NaN NaN NaN
# 2000-01-12 -2.730212 1.302561 0.010783 1.074983
# 新的日期索引不必与旧的索引重叠
frame.resample("W-THU").ffill()
# Colorado Texas New York Ohio
# 2000-01-06 -1.033289 0.670375 -0.086887 0.903338
# 2000-01-13 0.303904 -1.170826 -0.807921 -0.167185
使用周期进行重采样
对使用周期作为索引的数据进行重采样,与时间戳的情况类似:
frame = pd.DataFrame(np.random.standard_normal((24,4)),
index=pd.period_range("1-2000","12-2001",freq="M"),
columns=["Colorado","Texas","New York","Ohio"])
frame.head()
# Colorado Texas New York Ohio
# 2000-01 0.599385 -1.026146 0.377846 -0.769628
# 2000-02 -0.415738 -1.616806 0.171898 2.030871
# 2000-03 0.230840 0.893198 0.129828 0.970785
# 2000-04 0.560167 1.678211 -0.648175 0.604873
# 2000-05 -0.484082 -1.751307 0.541053 -0.738717
annual_frame = frame.resample("A-DEC").mean()
# Colorado Texas New York Ohio
# 2000 -0.260185 0.356527 -0.098587 0.189736
# 2001 -0.034842 0.078273 -0.026577 0.041263
升采样要稍微麻烦一些,在重采样之前,你必须决定在新频率时间段的哪一端放置数值。参数convention默认为"start",也可设置为"end":
# Q-DEC:每季度,年末为12月
annual_frame.resample("Q-DEC").ffill()
# Colorado Texas New York Ohio
# 2000Q1 0.620187 -0.141949 0.157756 0.016274
# 2000Q2 0.620187 -0.141949 0.157756 0.016274
# 2000Q3 0.620187 -0.141949 0.157756 0.016274
# 2000Q4 0.620187 -0.141949 0.157756 0.016274
# 2001Q1 -0.089812 -0.184859 -0.495531 0.156181
# 2001Q2 -0.089812 -0.184859 -0.495531 0.156181
# 2001Q3 -0.089812 -0.184859 -0.495531 0.156181
# 2001Q4 -0.089812 -0.184859 -0.495531 0.156181
annual_frame.resample("Q-DEC",convention="end").asfreq()
# Colorado Texas New York Ohio
# 2000Q4 -0.650872 -0.281441 0.046464 0.029406
# 2001Q1 NaN NaN NaN NaN
# 2001Q2 NaN NaN NaN NaN
# 2001Q3 NaN NaN NaN NaN
# 2001Q4 0.243617 0.253209 -0.287791 -0.081825
由于周期指的是时间段,因此升采样和降采样的规则比较严格:
- 在降采样中,目标频率必须是频率源的子周期。
- 在升采样中,目标频率必须是频率源的父周期。
如果不满足这些条件,就会引发异常。这主要会影响季度、年度、每周的频率。例如,由Q-MAR定义的时间段只能和A-MAR、A-JUN、A-SEP、A-DEC对齐。
对分组时间进行重采样
对于时间序列数据,从语义上讲,resample方法实质是基于时间间隔的分组运算。
N=15
times = pd.date_range("2017-05-20",freq="1min",periods=N)
df = pd.DataFrame({"time":times,"value":np.arange(N)})
# 可以根据"time"进行索引,然后进行重采样:
df.set_index("time").resample("5min").count()
# value
# time
# 2017-05-20 00:00:00 5
# 2017-05-20 00:05:00 5
# 2017-05-20 00:10:00 5
df2 = pd.DataFrame({"time":times.repeat(3),"key":np.tile(["a","b","c"],N),
"value":np.arange(N * 3)})
df2.head(7)
# time key value
# 0 2017-05-20 00:00:00 a 0
# 1 2017-05-20 00:00:00 b 1
# 2 2017-05-20 00:00:00 c 2
# 3 2017-05-20 00:01:00 a 3
# 4 2017-05-20 00:01:00 b 4
# 5 2017-05-20 00:01:00 c 5
# 6 2017-05-20 00:02:00 a 6
# 为了对各个"key"值做相同的重采样,引入pandas.Grouper对象:
time_key = pd.Grouper(freq="5min")
# 接下来设置时间索引,以"key"和time_key进行分组,并进行聚合:
resampled = (df2.set_index("time").groupby(["key",time_key]).sum())
# value
# key time
# a 2017-05-20 00:00:00 30
# 2017-05-20 00:05:00 105
# 2017-05-20 00:10:00 180
# b 2017-05-20 00:00:00 35
# 2017-05-20 00:05:00 110
# 2017-05-20 00:10:00 185
# c 2017-05-20 00:00:00 40
# 2017-05-20 00:05:00 115
# 2017-05-20 00:10:00 190
resampled.reset_index()
# key time value
# 0 a 2017-05-20 00:00:00 30
# 1 a 2017-05-20 00:05:00 105
# 2 a 2017-05-20 00:10:00 180
# 3 b 2017-05-20 00:00:00 35
# 4 b 2017-05-20 00:05:00 110
# 5 b 2017-05-20 00:10:00 185
# 6 c 2017-05-20 00:00:00 40
# 7 c 2017-05-20 00:05:00 115
# 8 c 2017-05-20 00:10:00 190
使用pandas.Grouper存在一个限制,即必须使用时间作为Series或DataFrame的索引。
移动窗口函数
在移动窗口或指数衰减权重上进行统计或运行其他函数,也是一类常见于时间序列的数组变换。这对于圆滑噪声数据或不连续数据很有帮助。
stock_px.csv文件:https://huihuiteresa.github.io/image/files/stock_px.csv
stock_px.csv文件内容如下图:
close_px_all = pd.read_csv("stock_px.csv",parse_dates=True,index_col=0)
close_px = close_px_all[["AAPL","MSFT","XOM"]]
close_px = close_px.resample("B").ffill()
close_px["AAPL"].plot()
close_px["AAPL"].rolling(250).mean().plot()
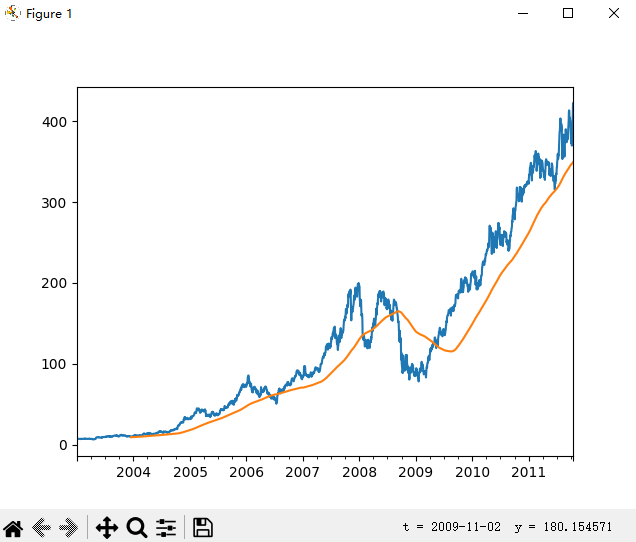
表达式rolling(250)与groupby很像,但它不是进行分组,而是创建一个可以按照250日分组的移动窗口对象。然后,我们就得到了苹果公司股价的250日移动窗口。
未完待续

 浙公网安备 33010602011771号
浙公网安备 33010602011771号