数据规整:连接、联合和重塑
数据规整:连接、联合和重塑
层次化索引
# 创建一个Series,并用一个由列表(或数组)构成的列表作为索引
data = pd.Series(
np.random.uniform(size=9),
index=[['a','a','a','b','b','c','c','d','d'],
[1,2,3,1,3,1,2,2,3]])
# a 1 0.522148
# 2 0.218709
# 3 0.090737
# b 1 0.935800
# 3 0.019236
# c 1 0.521339
# 2 0.132961
# d 2 0.370182
# 3 0.368036
# dtype: float64
# 层次化索引对象,可以使用部分索引
data["b"]
# 1 0.802418
# 3 0.384905
# dtype: float64
data["b":"c"]
data.loc[["b","d"]]
# 在“内部”层级中进行选取也是可行的;下面选取第二层索引值为2的数据
data.loc[:,2]
# 通过unstack方法将数据重排到DataFrame中
data.unstack()
# 1 2 3
# a 0.179548 0.259897 0.511953
# b 0.545412 NaN 0.899350
# c 0.276509 0.232216 NaN
# d NaN 0.219718 0.258017
# unstack的逆运算是stack
data.unstack().stack()
# DataFrame,每个轴都可以有分层索引
frame = pd.DataFrame(np.arange(12).reshape((4,3)),
index=[['a','a','b','b'],[1,2,1,2]],
columns=[['Ohio','Ohio','Colorado'],['Green','Red','Green']])
# Ohio Colorado
# Green Red Green
# a 1 0 1 2
# 2 3 4 5
# b 1 6 7 8
# 2 9 10 11
# 各层都可以有名称(可以是字符串,也可以是任意Python对象)
frame.index.names=['key1','key2']
frame.columns.names=['state','color']
# nlevels属性,可以知道索引有多少层
frame.index.nlevels
# 使用部分列索引,可以轻松选取列分组
frame["Ohio"]
# 可以单独创建MultiIndex,然后复用
pd.MultiIndex.from_arrays([
["Ohio","Ohio","Colorado"],
["Green","Red","Green"]],
names=["state","color"]
)
重排序和层级排序
# waplevel方法接收两个层级编号或名称,并返回一个层级互换的新对象(但数据不会发生变化)
frame.swaplevel("key1","key2")
# sort_index默认根据所有索引层级中的字母顺序对数据进行排序,但你也可以通过传入level参数只选取单层级或层级的子集
frame.sort_index(level=1)
frame.swaplevel(0,1).sort_index(level=0)
如果索引从最外层开始是按字母顺序排序的,即数据是执行了sort_index(level=0)或sort_index()之后的结果,则对数据进行选取的性能会高得多。
按层级进行汇总统计
许多对DataFrame和Series的描述性和汇总性统计都有一个level选项,用于指定在某条轴的特定层级进行聚合。
frame.groupby(level="key2").sum()
# state Ohio Colorado
# color Green Red Green
# key2
# 1 6 8 10
# 2 12 14 16
frame.groupby(level="color",axis="columns").sum()
使用DataFrame的列进行索引
人们通常不会将DataFrame的单列或多列用作行索引,但是可能将行索引用作DataFrame的列。
frame = pd.DataFrame({
"a":range(7),
"b":range(7,0,-1),
"c":["one","one","one","two","two","two","two"],
"d":[0,1,2,0,1,2,3]
})
# a b c d
# 0 0 7 one 0
# 1 1 6 one 1
# 2 2 5 one 2
# 3 3 4 two 0
# 4 4 3 two 1
# 5 5 2 two 2
# 6 6 1 two 3
# set_index函数会将单列或多列转换为行索引
frame2 = frame.set_index(["c","d"])
# a b
# c d
# one 0 0 7
# 1 1 6
# 2 2 5
# two 0 3 4
# 1 4 3
# 2 5 2
# 3 6 1
# 默认情况下,这些列会从DataFrame中移除,但也可以通过传入drop=False将其保留下来
frame3 = frame.set_index(["c","d"],drop=False)
# reset_index的功能与set_index相反,它将层次化索引的层级转移到列
frame2.reset_index()
联合与合并数据集
pandas对象中的数据可以通过多种方式进行联合:
-
pandas.merge
可根据单个或多个键将不同DataFrame中的行连接起来。SQL或其他关系型数据库的用户对此应该会比较熟悉,因为它实现的就是数据库的join(连接)操作。
-
pandas.concat
沿一条轴将多个对象连接或“堆叠”到一起。
-
combine_first
将重复数据拼接在一起,用一个对象中的值填充另一个对象中的缺失值。
数据库风格的DataFrame连接
df1 = pd.DataFrame({
"key":["b","b","a","c","a","a","b"],
"data1":pd.Series(range(7),dtype="Int64")
})
df2 = pd.DataFrame({
"key":["a","b","d"],
"data2":pd.Series(range(3),dtype="Int64")
})
# 没有指明要用哪个列进行连接,pandas.merge就会将重叠的列名当作键
# 通常,pandas.merge输出结果的列顺序是未指定的。
pd.merge(df1,df2)
# key data1 data2
# 0 b 0 1
# 1 b 1 1
# 2 a 2 0
# 3 a 4 0
# 4 a 5 0
# 5 b 6 1
# 指定列链接
df3 = pd.DataFrame({
"lkey":["b","b","a","c","a","a","b"],
"data1":pd.Series(range(7),dtype="Int64")
})
df4 = pd.DataFrame({
"rkey":["a","b","d"],
"data2":pd.Series(range(3),dtype="Int64")
})
pd.merge(df3,df4,left_on="lkey",right_on="rkey")
pd.merge(df1,df2,how="outer") # 外连接
pd.merge(df1,df2,how="left") # 左连接
pd.merge(df1,df2,how="right") # 右链接
how参数的不同的连接类型:
- how="inner":只使用两张表都有的键
- how="left":使用左表中所有的键
- how="right":使用右表中所有的键
- how="outer":使用两张表中所有的键
left = pd.DataFrame({
"key1":["foo","foo","bar"],
"key2":["one","two","one"],
"lval":pd.Series([1,2,3],dtype="Int64")
})
right = pd.DataFrame({
"key1":["foo","foo","bar","bar"],
"key2":["one","one","one","two"],
"rval":pd.Series([4,5,6,7],dtype="Int64")
})
# 多个键进行合并
pd.merge(left,right,on=["key1","key2"],how="outer")
# key1 key2 lval rval
# 0 bar one 3 6
# 1 bar two <NA> 7
# 2 foo one 1 4
# 3 foo one 1 5
# 4 foo two 2 <NA>
# 重复列
pd.merge(left,right,on="key1") # pandas.merge有一个更实用的suffixes选项,用于在左右两个DataFrame对象的重叠列名后指定需要添加的字符串
# key1 key2_x lval key2_y rval
# 0 foo one 1 one 4
# 1 foo one 1 one 5
# 2 foo two 2 one 4
# 3 foo two 2 one 5
# 4 bar one 3 one 6
# 5 bar one 3 two 7
pandas.merge的函数参数:
- left:参与合并的左侧DataFrame
- right:参与合并的右侧DataFrame
- how:连接方式,"inner""outer""left""right"其中之一。默认为"inner"
- on:用于连接的列名。必须存在于左右两个 DataFrame 对象中。如果未指定且也未指定其他连接键,则以 left 和 right 列名的交集作为连接键
- left_on:left DataFrame 中用作连接键的列。可以是单列列名或列名的组
right_on:rightDataFrame中用作连接键的列 - left_index:将left 的行索引用作连接键(如果是MultiIndex,则为多个键)
- right_index:将right 的行索引用作连接键sort根据连接键,对合并后的数据进行排序,默认为False
- suffixes:如果列名重合,将字符串元组追加到列名的末尾,默认为("_x","_y例如,如果左右两个DataFrame 对象都有"data",则结果中就是"data_x"和 "data_y"
- copy:如果为False,可以在某些特殊情况下避免将数据复制到结果数据结构中。默认总是复制
- validate:确认是否为特定类型的合并,即一对一、一对多或多对多。完整细节请查看该选项的文档字符串
- indicator:添加特殊的列_merge,用于指明每个行的来源。根据每行的连接数据的来源,它的值为"left_only""left_only"或"both"其中之一。
根据索引合并
在某些情况下,DataFrame中的连接键位于其索引(行标签)中。在这种情况下,可以传入left_index=True或right_index=True(也可以两个都传)以说明将索引用作连接键:
left1 = pd.DataFrame({"key":["a","b","a","a","b","c"],"value":pd.Series(range(6),dtype="Int64")})
right1 = pd.DataFrame({"group_val":[3.5,7]},index=["a","b"])
pd.merge(left1,right1,left_on="key",right_index=True)
# key value group_val
# 0 a 0 3.5
# 1 b 1 7.0
# 2 a 2 3.5
# 3 a 3 3.5
# 4 b 4 7.0
# 获取到并集
pd.merge(left1,right1,left_on="key",right_index=True,how="outer")
# 对于层次化索引的数据,事情就有点复杂了,因为索引的连接实际上是多键合并
left = pd.DataFrame({"key1":["Ohio","Ohio","Ohio","Nevada","Nevada"],
"key2":[2000,2001,2002,2001,2002],
"data":pd.Series(range(5),dtype="Int64")})
right_index = pd.MultiIndex.from_arrays([
["Nevada","Nevada","Ohio","Ohio","Ohio","Ohio"],
[2001,2000,2000,2000,2001,2002]
])
right = pd.DataFrame({"event1":pd.Series([0,2,4,6,8,10],dtype="Int64",index=right_index),
"event2":pd.Series([1,3,5,7,9,11],dtype="Int64",index=right_index)})
# 以列表的形式指明用作合并键的多个列(注意,使用how="outer"处理重复索引值):
pd.merge(left,right,left_on=["key1","key2"],right_index=True)
# key1 key2 data event1 event2
# 0 Ohio 2000 0 4 5
# 0 Ohio 2000 0 6 7
# 1 Ohio 2001 1 8 9
# 2 Ohio 2002 2 10 11
# 3 Nevada 2001 3 0 1
pd.merge(left,right,left_on=["key1","key2"],right_index=True,how="outer")
# 同时使用双方索引
left2 = pd.DataFrame([[1.,2.],[3.,4.],[5.,6.]],index=["a","b","c"],columns=["Ohio","Nevada"]).astype("Int64")
right2 = pd.DataFrame([[7.,8.],[9.,10.],[11.,12.],[12,14]],index=["b","c","d","e"],columns=["Missouri","Alabama"]).astype("Int64")
pd.merge(left2,right2,how="outer",left_index=True,right_index=True)
# Ohio Nevada Missouri Alabama
# a 1 2 <NA> <NA>
# b 3 4 7 8
# c 5 6 9 10
# d <NA> <NA> 11 12
# e <NA> <NA> 12 14
# DataFrame还有一个join实例方法,能更加方便地实现按索引合并。它还可用于合并多个带有相同或相似索引的DataFrame对象,但要求没有重叠的列。
left2.join(right2,how="outer") # 等同上面(DataFrame的join方法默认使用的是左连接)
left1.join(right1,on="key") # 支持在调用的DataFrame的列上连接传入DataFrame的索引
# 对于简单的索引合并,你还可以向join传入一组DataFrame
another = pd.DataFrame([[7.,8.],[9.,10.],[11.,12.],[16.,17.]],index=["a", "c", "e", "f"],columns=["New York", "Oregon"])
left2.join([right2,another])
left2.join([right2,another],how="outer")
轴向拼接
# NumPy的concatenate函数可以实现对NumPy数组的拼接
arr = np.arange(12).reshape((3,4))
np.concatenate([arr,arr],axis=1)
np.concatenate([arr,arr],axis=1)
# [[ 0 1 2 3 0 1 2 3]
# [ 4 5 6 7 4 5 6 7]
# [ 8 9 10 11 8 9 10 11]]
s1 = pd.Series([0,1],index=["a","b"],dtype="Int64")
s2 = pd.Series([2,3,4],index=["c","d","e"],dtype="Int64")
s3 = pd.Series([5,6],index=["f","g"],dtype="Int64")
pd.concat([s1,s2,s3]) # 默认情况下,pandas.concat是在axis="index"上工作的,最终生成一个新Series
# a 0
# b 1
# c 2
# d 3
# e 4
# f 5
# g 6
pd.concat([s1,s2,s3],axis="columns") # 这种情况下,另外的轴上没有重叠,实际上就是索引的并集(即外连接)
# 0 1 2
# a 0 <NA> <NA>
# b 1 <NA> <NA>
# c <NA> 2 <NA>
# d <NA> 3 <NA>
# e <NA> 4 <NA>
# f <NA> <NA> 5
# g <NA> <NA> 6
s4 = pd.concat([s1,s3])
pd.concat([s1,s4],axis="columns",join="inner") # 传入join="inner"即可得到它们的交集
# 在拼接轴上创建层次化索引。可以使用参数keys来实现
pd.concat([s1,s2,s3],keys=["one","two","three"])
pd.concat([s1,s2,s3],axis="columns",keys=["one","two","three"])
# dataframe
df1 = pd.DataFrame(np.arange(6).reshape((3,2)),index=["a","b","c"],columns=["one","two"])
df2 = pd.DataFrame(5+np.arange(4).reshape((2,2)),index=["a","c"],columns=["three","four"])
pd.concat([df1,df2],axis="columns",keys=["level1","level2"])
# level1 level2
# one two three four
# a 0 1 5.0 6.0
# b 2 3 NaN NaN
# c 4 5 7.0 8.0
# 传入的不是列表而是对象字典,则字典的键就会用于keys选项
pd.concat({"level1":df1,"level2":df2},axis="columns")
# 还有用于管理层次化索引创建方式的参数,可以用names参数命名创建的轴层级
pd.concat([df1,df2],axis="columns",keys=["level1","level2"],names=["upper","lower"])
# upper level1 level2
# lower one two three four
# a 0 1 5.0 6.0
# b 2 3 NaN NaN
# c 4 5 7.0 8.0
# ignore_index=True,它丢弃了两个DataFrame的索引,只是将列数据做了拼接,并赋值创建了一个默认的新索引
df1 = pd.DataFrame(np.random.standard_normal((3,4)),columns=["a","b","c","d"])
df2 = pd.DataFrame(np.random.standard_normal((2,3)),columns=["b","d","a"])
pd.concat([df1,df2],ignore_index=True)
# a b c d
# 0 1.705795 1.924797 0.968727 2.559045
# 1 -2.114243 -0.027911 -0.140382 -1.792394
# 2 0.746318 1.315602 -0.913124 0.945428
# 3 -0.111784 1.013329 NaN -2.247821
# 4 0.900988 -0.139223 NaN -0.063431
pandas.concat函数的参数:
- objs:参与连接的 pandas 对象的列表或字典,这是唯一的必需参数
- axis:指明拼接的轴,默认为沿着行拼接(axis="index")
- join:连接方式,"inner"或"outer"(默认为"outer")。指明其他轴向上的索引是按交集("inner")还是并集("outer")进行合并
- keys:与要拼接的对象有关的值,用于形成连接轴向上的层次化索引。可以是任意值的列表或数组、任意元组数组或数组列表(如果向levels 参数传入多层级数组)
- levels:如果传入了keys,则指定用作层次化索引各层级上的索引
- names:如果设置了keys和(或)levels,则用作多层索引l的层级名称
- verify_integrity:检查拼接得到的对象新轴是否存在重复项,如果发现重复则抛出异常。默认(False)允许重复项
- ignore_index:不保留拼接轴上的索引l,而是产生一个新索引丨range(total_length)
联合重叠数据
还有一种数据联合场景不能用合并或拼接来处理。比如说,你可能有索引全部或部分重叠的两个数据集。
# 对于NumPy的where函数,它可以实现面向数组且等价于if-else表达式的操作
a = pd.Series([np.nan,2.5,0.0,3.5,4.5,np.nan],index=["f","e","d","c","b","a"])
b = pd.Series([0.,np.nan,2.,np.nan,np.nan,5.],index=["a","b","c","d","e","f"])
np.where(pd.isna(a),b,a) # [0. 2.5 0. 3.5 4.5 5. ]
# 按照索引排列值,需要使用Series的combine_first方法
a.combine_first(b)
# a 0.0
# b 4.5
# c 3.5
# d 0.0
# e 2.5
# f 5.0
# dtype: float64
# 对于DataFrame,combine_first也会逐列做同样的操作,因此可以认为用传入对象的数据为调用对象的缺失数据“打补丁”:
df1 = pd.DataFrame({"a": [1., np.nan, 5., np.nan],"b": [np.nan, 2., np.nan, 6.],"c": range(2, 18, 4)})
df2 = pd.DataFrame({"a":[5., 4., np.nan, 3.,7.],"b": [np.nan, 3., 4., 6., 8.]})
df1.combine_first(df2)
# a b c
# 0 1.0 NaN 2.0
# 1 4.0 2.0 6.0
# 2 5.0 4.0 10.0
# 3 3.0 6.0 14.0
# 4 7.0 8.0 NaN
重塑和透视
有多种基础操作用于重新排列表格型数据。这些操作也称作重塑或透视。
使用层次化索引进行重塑
层次化索引为重排DataFrame数据提供了一种具有良好一致性的方式。主要有两种操作:
- stack:将数据的列“旋转”为行。
- unstack:将数据的行透视为列。
data = pd.DataFrame(np.arange(6).reshape((2,3)),
index=pd.Index(["Ohio","Colorado"],name="state"),
columns=pd.Index(["one","two","three"],name="number"))
# number one two three
# state
# Ohio 0 1 2
# Colorado 3 4 5
result = data.stack()
# state number
# Ohio one 0
# two 1
# three 2
# Colorado one 3
# two 4
# three 5
# dtype: int64
result.unstack()
# number one two three
# state
# Ohio 0 1 2
# Colorado 3 4 5
# 默认情况下,unstack操作的是最内层(stack也是如此)。传入层级编号或名称,即可对其他层级进行unstack操作:
result.unstack(level=0)
state Ohio Colorado
number
one 0 3
two 1 4
three 2 5
result.unstack(level="state")
# state Ohio Colorado
# number
# one 0 3
# two 1 4
# three 2 5
# 如果在各子分组中不能找到所有层级的值,则unstack操作可能会导入缺失数据:
s1 = pd.Series([0,1,2,3],index=["a","b","c","d"],dtype="Int64")
s2 = pd.Series([4,5,6],index=["c","d","e"],dtype="Int64")
data2 = pd.concat([s1,s2],keys=["one","two"])
# one a 0
# b 1
# c 2
# d 3
# two c 4
# d 5
# e 6
data2.unstack()
# a b c d e
# one 0 1 2 3 <NA>
# two <NA> <NA> 4 5 6
# stack操作会默认过滤缺失数据,因此该运算是可逆的
data2.unstack().stack()
# one a 0
# b 1
# c 2
# d 3
# two c 4
# d 5
# e 6
# dtype: Int64
data2.unstack().stack(dropna=False)
# one a 0
# b 1
# c 2
# d 3
# e <NA>
# two a <NA>
# b <NA>
# c 4
# d 5
# e 6
# dtype: Int64
# 在对DataFrame进行unstack操作时,被拆分的层级将成为结果中的最低层级:
df = pd.DataFrame({"left":result,"right":result+5},
columns=pd.Index(["left","right"],name="side"))
# side left right
# state number
# Ohio one 0 5
# two 1 6
# three 2 7
# Colorado one 3 8
# two 4 9
# three 5 10
df.unstack(level="state")
# side left right
# state Ohio Colorado Ohio Colorado
# number
# one 0 3 5 8
# two 1 4 6 9
# three 2 5 7 10
df.unstack(level="state").stack(level="side")
# state Ohio Colorado
# number side
# one left 0 3
# right 5 8
# two left 1 4
# right 6 9
# three left 2 5
# right 7 10
将“长格式”透视为“宽格式”
多个时间序列数据通常是以所谓的“长格式”或“堆叠格式”存储在数据库和CSV中的。对于这种格式,表中的每行表示单个值,而不是表示多个值。
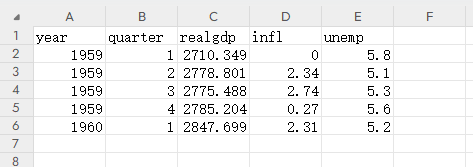
data = pd.read_csv("007.csv")
data = data.loc[:,["year","quarter","realgdp","infl","unemp"]]
# year quarter realgdp infl unemp
# 0 1959 1 2710.349 0.00 5.8
# 1 1959 2 2778.801 2.34 5.1
# 2 1959 3 2775.488 2.74 5.3
# 3 1959 4 2785.204 0.27 5.6
# 4 1960 1 2847.699 2.31 5.2
# 首先,我使用pandas.PeriodIndex(来表示时间区间,而非时间点)将year和quarter列联合并设置索引,让索引包含每个季度末的datetime值
# DataFrame上使用了pop方法,返回一列的同时将其从DataFrame删除
periods = pd.PeriodIndex(year=data.pop("year"),quarter=data.pop("quarter"),name="date") #
# PeriodIndex(['1959Q1', '1959Q2', '1959Q3', '1959Q4', '1960Q1'], dtype='period[Q-DEC]', name='date')
data.index = periods.to_timestamp("D")
# realgdp infl unemp
# date
# 1959-01-01 2710.349 0.00 5.8
# 1959-04-01 2778.801 2.34 5.1
# 1959-07-01 2775.488 2.74 5.3
# 1959-10-01 2785.204 0.27 5.6
# 1960-01-01 2847.699 2.31 5.2
data = data.reindex(columns=["realgdp","infl","unemp"])
data.columns.name="item"
# 使用stack操作进行重塑,并使用reset_index将新的索引层级移到列,最后将包含数据值的列命名为"value"
long_data = (data.stack().reset_index().rename(columns={0:"value"}))
# date item value
# 0 1959-01-01 realgdp 2710.349
# 1 1959-01-01 infl 0.000
# 2 1959-01-01 unemp 5.800
# 3 1959-04-01 realgdp 2778.801
# 4 1959-04-01 infl 2.340
# 5 1959-04-01 unemp 5.100
# 6 1959-07-01 realgdp 2775.488
# 7 1959-07-01 infl 2.740
# 8 1959-07-01 unemp 5.300
# 9 1959-10-01 realgdp 2785.204
# 10 1959-10-01 infl 0.270
# 11 1959-10-01 unemp 5.600
# 12 1960-01-01 realgdp 2847.699
# 13 1960-01-01 infl 2.310
# 14 1960-01-01 unemp 5.200
# 行转列
pivoted = long_data.pivot(index="date",columns="item",values="value")
# item infl realgdp unemp
# date
# 1959-01-01 0.00 2710.349 5.8
# 1959-04-01 2.34 2778.801 5.1
# 1959-07-01 2.74 2775.488 5.3
# 1959-10-01 0.27 2785.204 5.6
# 1960-01-01 2.31 2847.699 5.2
long_data["value2"] = np.random.standard_normal(len(long_data))
pivoted = long_data.pivot(index="date",columns="item") # 带有层次化索引的列
# value value2
# item infl realgdp unemp infl realgdp unemp
# date
# 1959-01-01 0.00 2710.349 5.8 -0.665122 -2.792897 0.220848
# 1959-04-01 2.34 2778.801 5.1 0.334898 1.479825 -0.261793
# 1959-07-01 2.74 2775.488 5.3 -1.937168 -0.440664 1.504955
# 1959-10-01 0.27 2785.204 5.6 -0.385309 1.003587 0.520601
# 1960-01-01 2.31 2847.699 5.2 0.183695 -0.190552 -0.499543
pivoted["value"]
# item infl realgdp unemp
# date
# 1959-01-01 0.00 2710.349 5.8
# 1959-04-01 2.34 2778.801 5.1
# 1959-07-01 2.74 2775.488 5.3
# 1959-10-01 0.27 2785.204 5.6
# 1960-01-01 2.31 2847.699 5.2
# pivot其实就等价于先用set_index创建层次化索引,再用unstack重塑
unstacked = long_data.set_index(["date","item"]).unstack(level="item")
将“宽格式”透视为“长格式”
对于DataFrame,pivot操作的逆运算是pandas.melt。它不是将一列转换为新DataFrame中的多列,而是将多个列合并成一列,并生成比输入更长的DataFrame。
df = pd.DataFrame({"key":["foo","bar","baz"],"A":[1,2,3],"B":[4,5,6],"C":[7,8,9]})
# key A B C
# 0 foo 1 4 7
# 1 bar 2 5 8
# 2 baz 3 6 9
# 当使用pandas.melt时,必须指明哪些列(如果有的话)是分组指标。下面使用"key"作为唯一的分组指标
melted = pd.melt(df,id_vars="key") # 就是行转列吧
# key variable value
# 0 foo A 1
# 1 bar A 2
# 2 baz A 3
# 3 foo B 4
# 4 bar B 5
# 5 baz B 6
# 6 foo C 7
# 7 bar C 8
# 8 baz C 9
# pivot,可以将其重塑回原来的形式
reshaped = melted.pivot(index="key",columns="variable",values="value")
# variable A B C
# key
# bar 2 5 8
# baz 3 6 9
# foo 1 4 7
reshaped = reshaped.reset_index() # 所以我们可以使用reset_index将数据再移回到列
# variable key A B C
# 0 bar 2 5 8
# 1 baz 3 6 9
# 2 foo 1 4 7
pd.melt(df,id_vars="key",value_vars=["A","B"]) # 指定列的子集用作value列
# key variable value
# 0 foo A 1
# 1 bar A 2
# 2 baz A 3
# 3 foo B 4
# 4 bar B 5
# 5 baz B 6
# pandas.melt也可以不使用任何分组指标
pd.melt(df,value_vars=["A","B","c"])
# variable value
# 0 A 1
# 1 A 2
# 2 A 3
# 3 B 4
# 4 B 5
# 5 B 6
# 6 C 7
# 7 C 8
# 8 C 9
pd.melt(df,value_vars=["key","A","B"])
# variable value
# 0 key foo
# 1 key bar
# 2 key baz
# 3 A 1
# 4 A 2
# 5 A 3
# 6 B 4
# 7 B 5
# 8 B 6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号