
bigtable阅后感
regionserver会在zookeeper指定目录创建一个特定的文件夹和文件,hmaster监视这个服务器目录,发现regionserver.并创建一个独占的排他锁。这个锁只能自己享用。
若regionserver挂掉,会丢失锁,之后,若之前创建的文件还存在。regionserver会重新尝试创建独占排他锁,如果尝试成功,可以对外继续提供服务。若创建失败,regionserver进程就自杀,不再对外提供服务。
根据业务需求:有的需要极大的吞吐量,有的需要及时响应客户端的访问。
bigtable集群配置:有的集群只有几台服务器,有的则需要上千台。
bigtable使用了很多数据库的实现策略,它不支持完整的关系数据模型。但提供了一个简单的数据模型,客户可以使用这个模型来动态控制数据的分布和格式。用数据库
的语言来说,就是数据没有schema,用户需要自己定义schema.bigtable将数据都视为字符串,通常把结构化或半结构化的数据存储在这些字符串。
bigtable是一个稀疏的,分布式的,持久化存储的多维度排序map。map的索引是行关键字,列关键字,时间戳(rowkey:String,column:String,timestamp:int64)->String。
map中的每个value都是一个未解析的字节数组。
webtable:使用反向url(com.baidu.www)作为关键字,网页的属性作为列族,网页的内容存放在列content:中,并用获取该网页的
时间戳(获取时间不同,存储多个版本的网页数据)来作为标识。
行键:
行键可以是任何字符串(最大64kb,10byte-100byte是常用的),用户对同一行键中的数据的读写都是原子性的(不管读写这一行中多少个不同的列)。
bigtable通过行键的字典序来组织数据,每个行都可以作为一个分区region,region是数据分布和负载均衡的最小调整单位。
列族:
列关键字组成的集合叫做列族,列族是访问控制的基本单位。列关键字的命名--列族:限定词
访问控制,磁盘和内存的使用统计都是在列族层面进行的。
时间戳的类型是64位整型,可以给时间戳赋值,用来表示精确到毫秒的时间。为了减轻版本过多带来的存储负担,bigtable提供了2种方式进行垃圾清楚:1.通过保存最后n个版本的数据,
2.只保存足够新的版本。
bigtable支持单行数据的事务处理功能,用户可以对行关键字下的数据进行原子性的读,写,更新。虽然允许用户跨行写入数据,但目前还不支持跨行事务功能。
bigtable集群建立在一个共享的机器池中,bigtable内部存储数据的文件是google的sstable格式的。sstable是一个持久化,排序,不可改变的map结构
sstable是一系列数据块(通常每个快大小都是64k,可以配置)。sstable使用索引来定位数据块,打开sstable时,索引被加载到内存中,每次加载都可以通过一次
磁盘搜索来完成。首先在内存索引中找到数据块的位置,然后通过访问磁盘来获取数据。也可以把整个sstable放入内存,这样就可以不用访问磁盘了。
bigtable还依赖一个高可用,序列化,分布式式锁服务组建。一个chubby服务包括了5个活动的副本,其中一个作为master,负责处理请求。只有在大多数副本都存活,并且
之间可以正常通信的情况下,chubby才对外提供服务。当副本失效的时候,chubby使用paxos来保证副本的一致性。chubby提供了一个名字空间,里面包括目录和小文件。
每个目录或文件都可以当成一个锁。读写操作都是原子性的。chubby客户程序库提供对chubby文件的一致性缓存。每个chubby客户程序都维护一个与chubby服务的会话。
如果客户程序在租约到期后指定时间内未重新签订会话和租约,这个会话就失效了。当这个会话失效时,拥有的锁和打开的句柄都失效。chubby客户程序可以在文件和
目录上注册回调函数,当文件或目录改变,或者会话过期时,回调函数会通知客户程序。
bigtable使用chubby完成以下几个任务:确保任何给定的时间只有一个活动的master副本;存储bigtable自引导指令位置;查找tablet服务器,以及在tablet服务器失效时进行
善后;存储bigtable的模式信息(每张表的列族信息);存储访问控制列表。chubby长时间无法访问,bigtable就会失效。
bigtable可以动态的向集群中添加tablet服务器。
master服务器主要功能:1.为tablet服务器分配table
2检测新加入或者过期失效的tablet服务器
3对tablet服务器进行负载均衡
4对保存在GFS上的文件进行垃圾收集;
5处理对模式的修改操作,如建立表和列族
看图: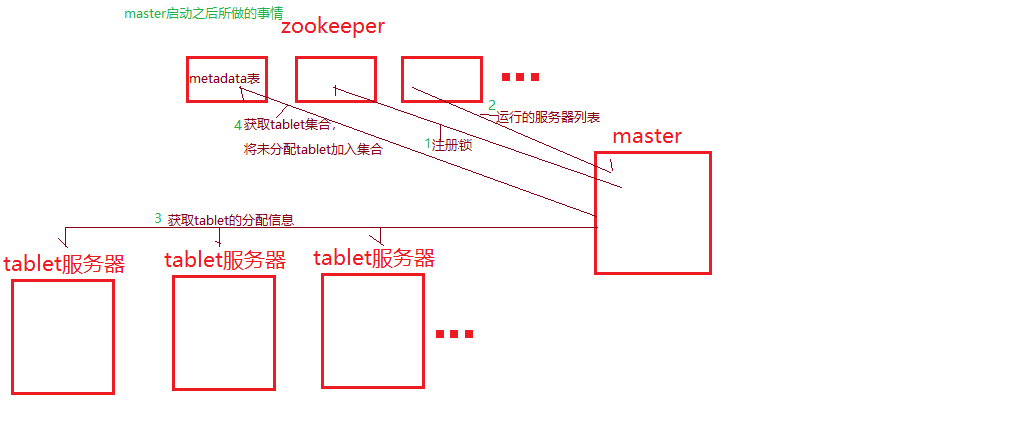
通常一个tablt服务器管理大约10-1000个tablet
tablet服务器负责的内容:1.负责处理客户端的读写请求
2.在tablets过大时进行切分
bigtable集群属于single-master类型的分布式系统。客户端大多数操作完全不经过master,所以master的负载并不重。
缺省(tablet未被分割)情况下,每个tablet的大小在100-200M之间
第一层是一个存储在chubby文件中的文件,它包含了root tablet的位置信息。roottablet包含一个特殊的metadata表里的tablet的位置信息,metadata表的每个tablet包含一个用户
tablet的集合,roottablet实际上是metadata表的第一个tablet。roottablet不会被分割,保证了tablt的位置信息存储结构不会超过3层。在metadata表里面。每个tablet的位置信息
都存放在一个行关键字下面。这个行关键字是由tablet所在的表的标识符和tablet的最后一行编码而成。metadata的每一行都存储了大约1kb的内存数据,在一个大小适中,
容量限制未128M的metadatatablet中,采用这种3层结构的存储,可以表示2^34个table地址
客户程序使用的库会缓存tablet的位置信息,如果客户程序没有缓存某个region的地址信息,或者发现它缓存的地址信息不正确,客户程序就在树状的存储结构中递归的
查询region的位置信息;如果客户端缓存是空的,那么寻址算法需要通过三次网络来回通信寻址,其中包括一次chubby读操作;如果客户端缓存的地址信息过期了,那么
寻址算法需要6此网络通信才能跟新数据,因为只有在缓存中没有查到数据的时候才能发现数据过期(其中3次发现数据缓存,3次更新数据缓存,假设metadata的table没有被频繁移动)
tablet的地址信息是存放在内存里的,对它的操作不必访问GFS文件系统。通常,我们会通过预取tablet地址来进一步减少访问的开销:即每次需要从metadata表中
读tablet元数据的时候,都会多读取几个tablet的元数据。
每个metadata中还存储了次级信息,包括每个tablet事件日志(比如什么时候一个服务器开始为该tablet提供服务)
table分配
master服务器记录当前有哪些活跃的tablet服务器,哪些tablet分配给了哪些tablet服务器。哪些tablet没有被分配,bigtable使用chubby跟踪记录tablet服务器的状态。当
一个tablet服务启动时,它在chubby的一个指定目录下建立一个唯一性名字的文件,并获取该文件的独占锁
tablet合并和分割时,客户端的读写操作可以继续
hbase优化:
局部性群组:将不会被一起访问的列族合并到一个sstable中,形成局部性群组。例如将网页语言列族和chesum列族合并到一个sstable,将页面内容单独放在一个sstable。访问元数据时就不用
读取网页内容。也可以将局部性群组加入到内存中。
客户可以选择对局部性群组进行压缩,采用不同的压缩方式,相同,相似的文件放在一起,可以提高压缩效率会得到提高。
建立block二级缓存,一级缓存是扫描缓存,主要缓存从storefile获取的kv对,而二级缓存是缓存从hdfs获取的storefile的block块。对于经常要重复读取的数据适用于一级
缓存,对于经常要读取附近数据的的应用来说,使用二级缓存最合适(例如,按照顺序都,或是随机读取局部群组的数据)。
bloom过滤器:背景:如果一个数据不在缓存中的region中,那么就需要访问磁盘查找数据。只要
给缓存中指定一个布隆过滤器,就可以很快知道是否包含指定的行和列。相当于布隆过滤器告诉
了客户端,访问的数据不存在。提高了效率。commit日志实现:给每个regionserver设置一个WALlog,采用追加的方式记录客户端的修改操作。然后,对不同的storefile进行修改。所以一个wallog混合了对多个
表数据的操作。commit日志虽然提高了写的性能,但是恢复的时候确更棘手,当regionserver恢复
以后,会扫描wallog文件,执行原来的修改操作。这样,若有100个服务器承担了原来100个region,那么这个
恢复的regionserver就要执行100次对wal日志的读取。在regionserver恢复之后要读取wallog时,hmaster协同对wallog进行切分64M并行排序(按照,table,row name,log sequence number)这样只需seek一次磁盘就可以顺序读取原来的region
.GFS负载过高会引起网络波动,应对这种情况。regionserver会开启2个线程写日志文件,一个比较慢的时候,
换另一个来写,写入的时候标记序列号,当regionserver在恢复的时候会忽略掉重复的内容。
region恢复提速:
一个region由一个regionserver迁移到另一台regionserver之前,会做一次minorCompaction.合并减少wallog中没有归并的记录,减少恢复事件。在卸载之前还会进行一次
minor合并,消除上一次合并过程中又产生的新记录。之后在上传到新的regionserver
利用不变性:
对memstore采用COW的方式,读去storefile的时候并不影响客户端的写操作。
使用标记-删除的方法对进行废弃的region进行回收。
共享原来的region集合。
性能瓶颈:1.内存2.网络io,网络带宽有限的情况下,在提高节点数量,吞吐率提高的效果并不理想,但是访问速度的提高确是显而易见的。
google使用bigtable踩过的坑
1.fail-stop
2.fail-fast failure
遇到以下情况产生问题:内存数据损坏,网络中断,始终偏差,机器挂起,扩展的和非对称的网络分区
使用的其他系统的Bug:chubby,GFS配额溢出,计划内和计划外的硬件维护。通过修改协议来解决上述问题,比如在RPC协议中加入checksum,在设计系统时,
不对其他部分做假设。另一个教训是,在了解一个新特性后,再决定是否添加这个功能。分布式事务功能大多只适用于二级索引。
简介编码的重要性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号