

102302109-胡贝贝-作业3
作业①
(1)实验内容及结果
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
核心代码:
点击查看代码
def single_thread_crawler():
"""单线程爬虫"""
print("--- 开始单线程爬虫 ---")
global visited_urls, downloaded_images_count, crawled_pages_count
visited_urls.clear()
downloaded_images_count = 0
crawled_pages_count = 0
urls_to_visit = [
BASE_URL,
'http://www.weather.com.cn/news/',
'http://pic.weather.com.cn/',
'http://www.weather.com.cn/sj/'
]
while urls_to_visit and crawled_pages_count < MAX_PAGES and downloaded_images_count < MAX_IMAGES:
current_url = urls_to_visit.pop(0)
if current_url in visited_urls:
continue
visited_urls.add(current_url)
new_urls = crawl_page(current_url)
urls_to_visit.extend([url for url in new_urls if url not in visited_urls])
time.sleep(1)
print("--- 单线程爬虫结束 ---")
def multi_thread_crawler():
"""多线程爬虫"""
print("--- 开始多线程爬虫 ---")
global visited_urls, downloaded_images_count, crawled_pages_count, url_queue
visited_urls.clear()
downloaded_images_count = 0
crawled_pages_count = 0
# 清空队列
while not url_queue.empty():
url_queue.get()
seed_urls = [
BASE_URL,
'http://www.weather.com.cn/news/',
'http://pic.weather.com.cn/',
'http://www.weather.com.cn/sj/'
]
for url in seed_urls:
url_queue.put(url)
# 创建工作线程
max_workers = min(5, len(seed_urls))
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = [executor.submit(worker_thread) for _ in range(max_workers)]
for future in as_completed(futures):
try:
future.result()
except Exception as e:
print(f"线程异常: {e}")
print("--- 多线程爬虫结束 ---")
输出信息:
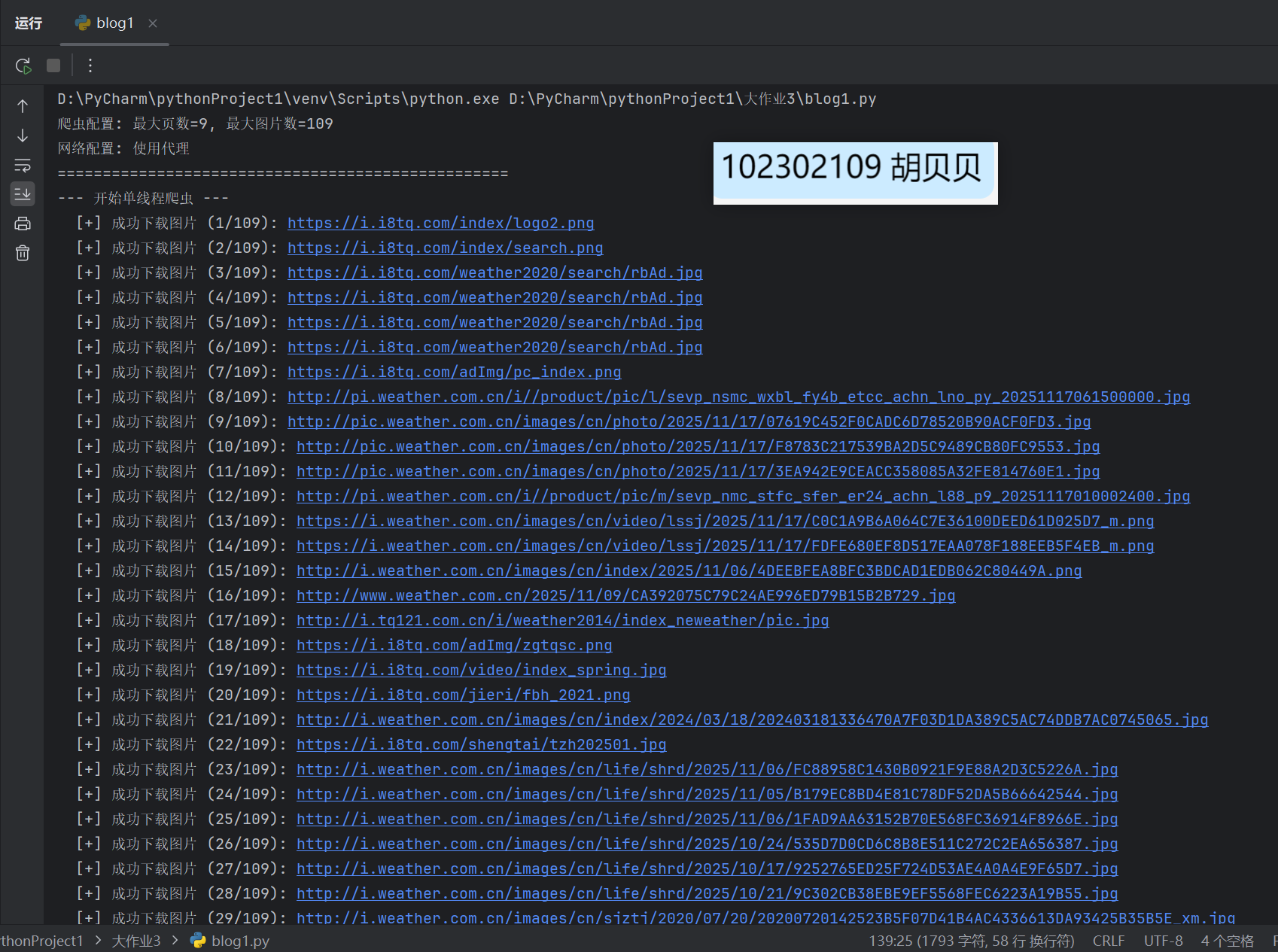
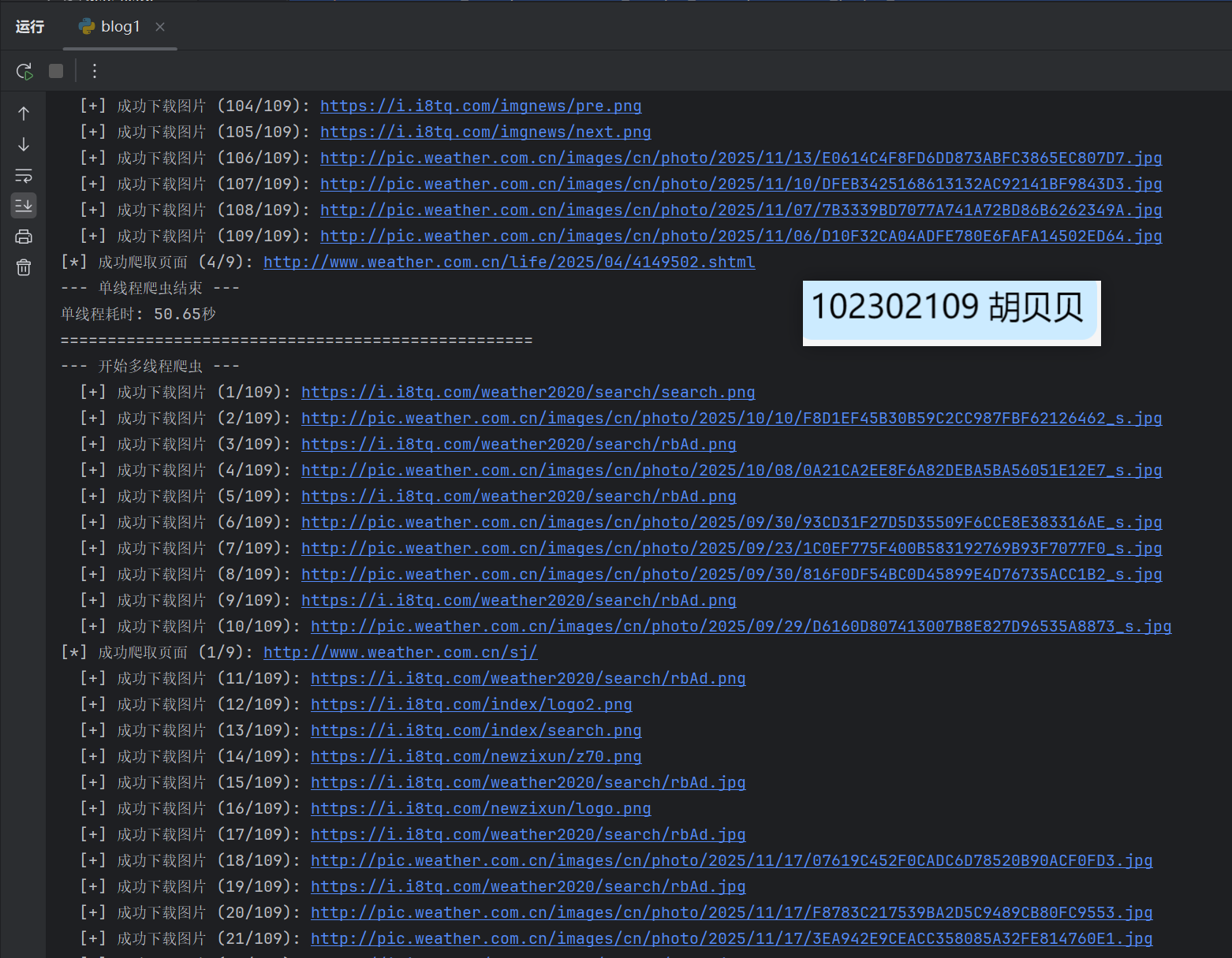
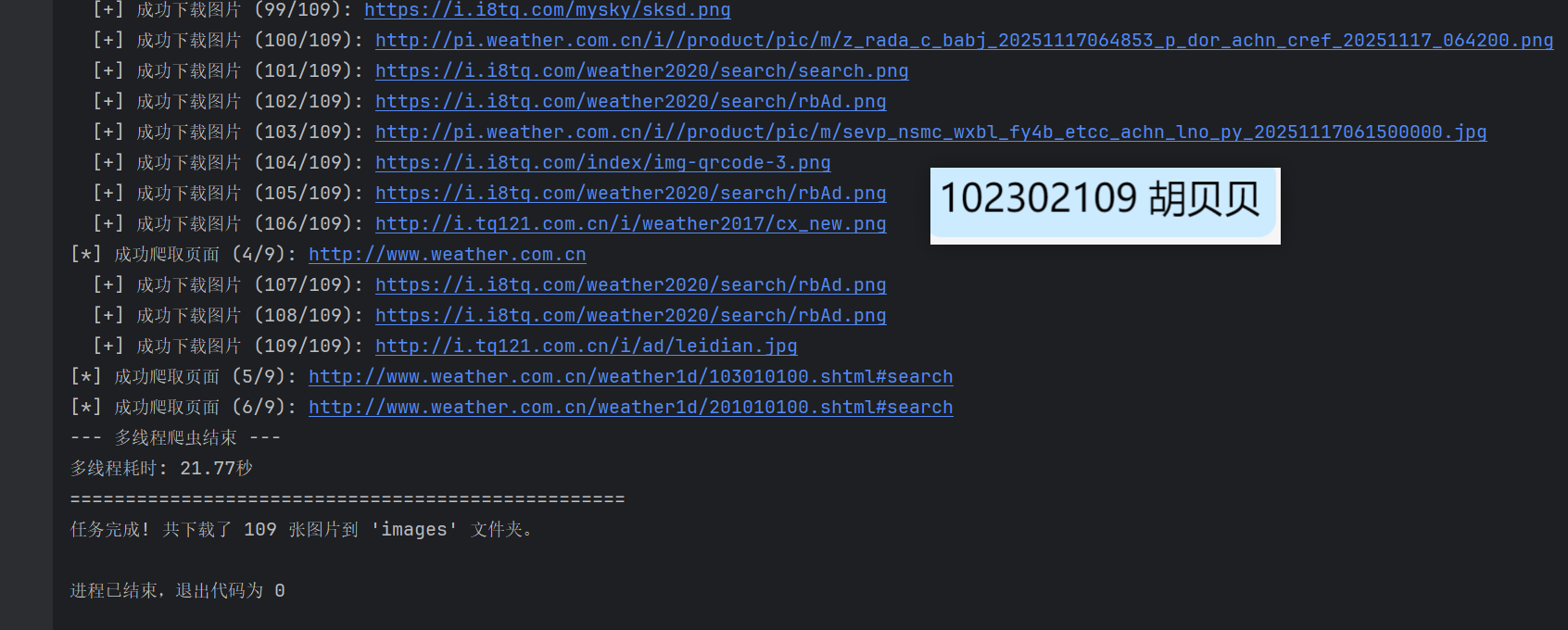
Gitee文件夹链接:https://gitee.com/hu_beibei/data-collection-practice/tree/master/102302109_胡贝贝_作业3/作业1
(2)实验心得
通过爬取中国气象网图片,我掌握了单线程与多线程爬虫的实现方法,并认识到合理控制请求频率的重要性。多线程显著提升了爬取效率,但需注意线程数量以避免反爬机制。
作业②
(1)实验内容及结果
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
核心代码:
点击查看代码
class EastmoneyStockSpider(scrapy.Spider):
name = 'eastmoney_stock'
def start_requests(self):
self.logger.info("开始爬取东方财富股票数据")
base_url = "http://82.push2.eastmoney.com/api/qt/clist/get"
params = {
'pn': '1',
'pz': '500',
'po': '1',
'np': '1',
'ut': 'bd1d9ddb04089700cf9c27f6f7426281',
'fltt': '2',
'invt': '2',
'fid': 'f3',
'fs': 'm:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23',
'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152',
'_': str(int(time.time() * 1000))
}
api_url = base_url + '?' + '&'.join([f"{k}={v}" for k, v in params.items()])
yield scrapy.Request(
url=api_url,
callback=self.parse_api,
headers={
'Referer': 'http://quote.eastmoney.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
},
meta={'source': 'api'}
)
def parse_api(self, response):
self.logger.info("解析API数据")
try:
json_text = response.text
# 处理JSONP格式
if json_text.startswith('jQuery') or json_text.startswith('callback'):
start_index = json_text.find('({')
end_index = json_text.rfind('})') + 2
if start_index != -1 and end_index != -1:
json_text = json_text[start_index:end_index]
data = json.loads(json_text)
stocks = data.get('data', {}).get('diff', [])
self.logger.info(f" 从API获取到 {len(stocks)} 只股票数据")
current_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
count = 0
for stock in stocks:
item = StockItem()
item['id'] = count + 1
item['stock_code'] = stock.get('f12', '')
item['stock_name'] = stock.get('f14', '')
item['latest_price'] = stock.get('f2', 0)
item['change_percent'] = stock.get('f3', 0)
item['change_amount'] = stock.get('f4', 0)
item['volume'] = self.format_number(stock.get('f5', 0))
item['amplitude'] = stock.get('f7', 0)
item['high'] = stock.get('f15', 0)
item['low'] = stock.get('f16', 0)
item['open_price'] = stock.get('f17', 0)
item['close_price'] = stock.get('f18', 0)
item['crawl_time'] = current_time
if item['stock_code'] and item['stock_name']:
count += 1
if count <= 50:
self.logger.info(f"提取: {item['stock_name']}({item['stock_code']}) - {item['latest_price']}")
yield item
self.logger.info(f" 成功处理 {count} 只股票数据")
except Exception as e:
self.logger.error(f" API解析失败: {e}")
输出信息:
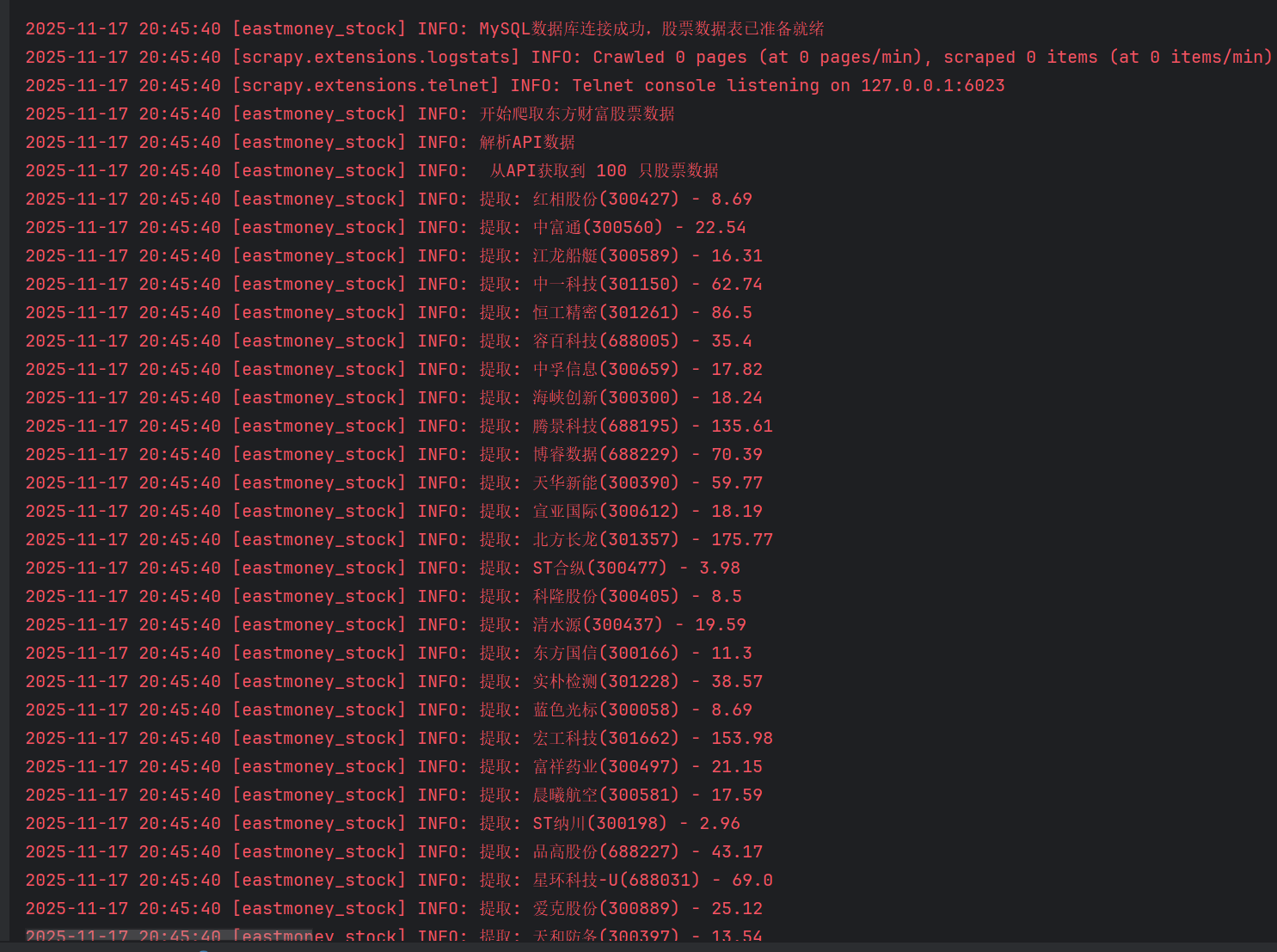
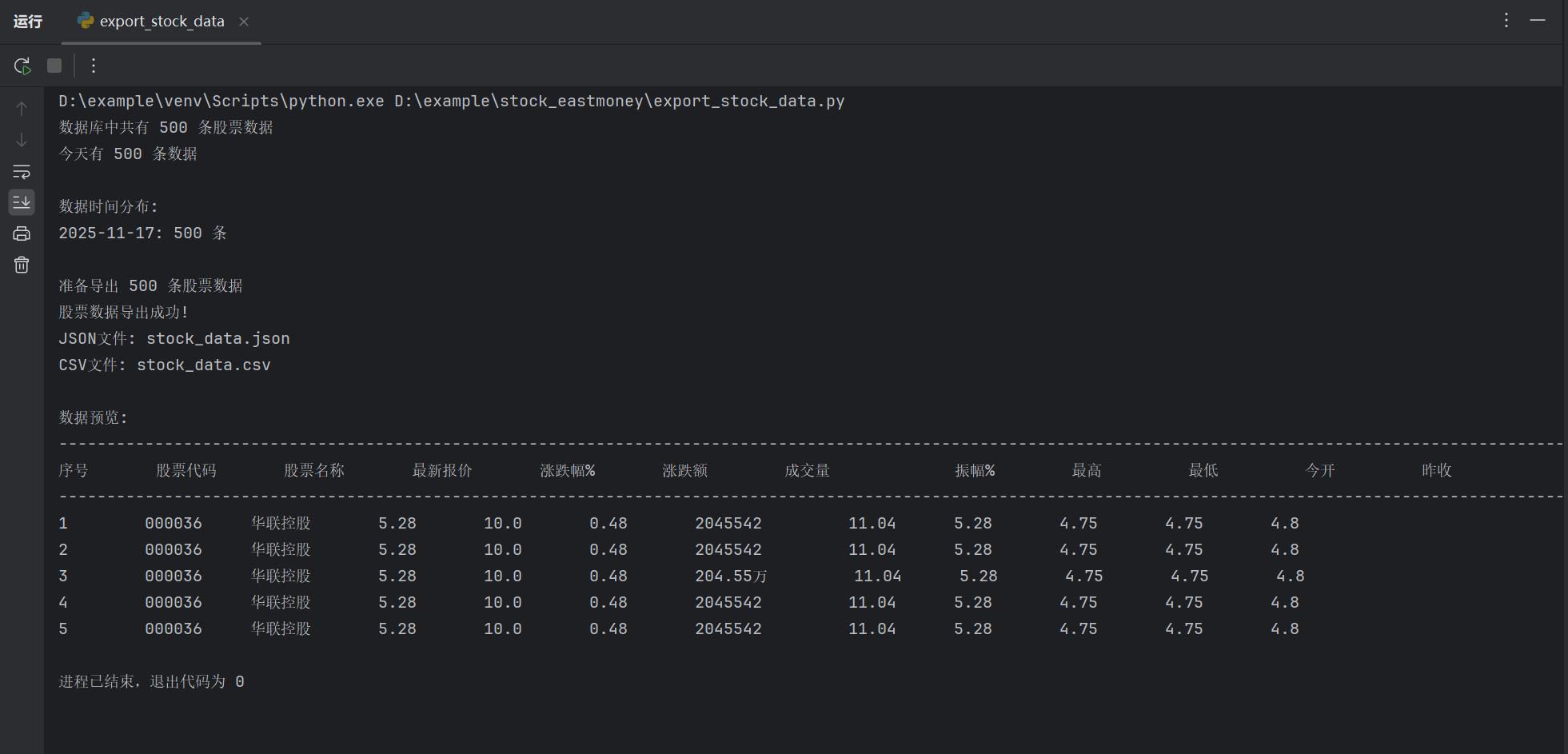
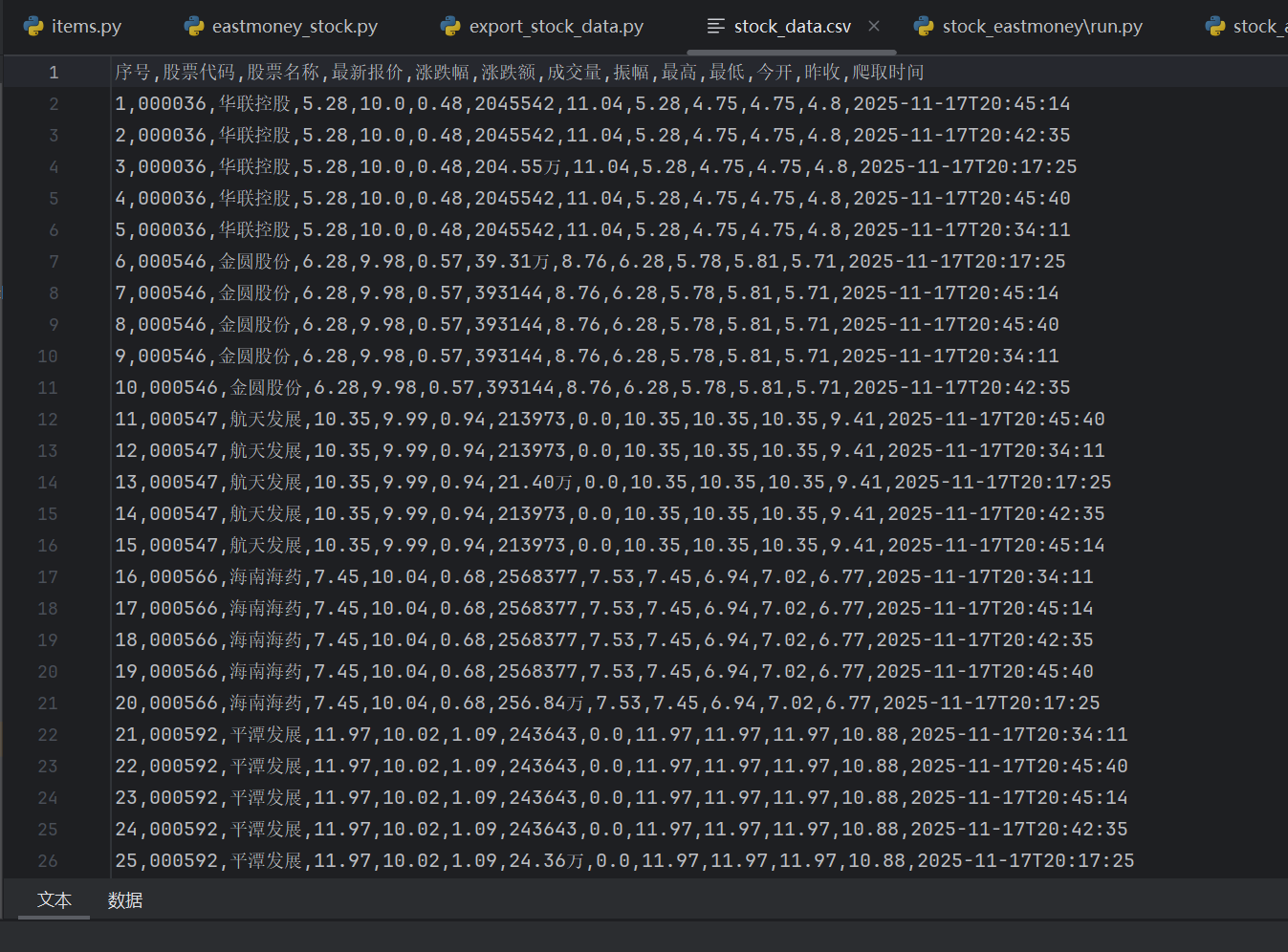
Gitee文件夹链接:https://gitee.com/hu_beibei/data-collection-practice/tree/master/102302109_胡贝贝_作业3/作业2/stock_eastmoney
(2)实验心得
使用Scrapy框架爬取东方财富网股票数据,我熟悉了Xpath选择器和Item、Pipeline的使用。通过将数据存储到MySQL,我理解了数据清洗和持久化的流程。
作业③
(1)实验内容及结果
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
核心代码:
点击查看代码
import scrapy
from forex_project.items import ForexItem
class BocSpiderSpider(scrapy.Spider):
name = 'boc_spider'
allowed_domains = ['www.boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
self.logger.info(f"页面标题: {response.css('title::text').get()}")
rows = response.xpath('//table//tr')
if not rows:
rows = response.xpath('//tr')
self.logger.info(f"使用备用选择器,找到 {len(rows)} 行")
self.logger.info(f"找到 {len(rows)} 行数据")
for i, row in enumerate(rows[1:], 1):
item = ForexItem()
columns = row.xpath('./td//text()').getall()
columns = [col.strip() for col in columns if col.strip()]
self.logger.debug(f"第{i}行数据: {columns}")
if len(columns) >= 7:
try:
item['currency'] = columns[0]
item['tbp'] = columns[1] # 现汇买入价
item['cbp'] = columns[2] # 现钞买入价
item['tsp'] = columns[3] # 现汇卖出价
item['csp'] = columns[4] # 现钞卖出价
item['time'] = columns[6] # 发布时间
if item['currency']:
self.logger.info(f"成功提取: {item['currency']}")
yield item
else:
self.logger.warning(f"第{i}行货币名称为空")
except Exception as e:
self.logger.error(f"处理第{i}行时出错: {e}, 数据: {columns}")
else:
self.logger.warning(f"第{i}行列数不足: {len(columns)}列,期望至少7列")
输出信息:
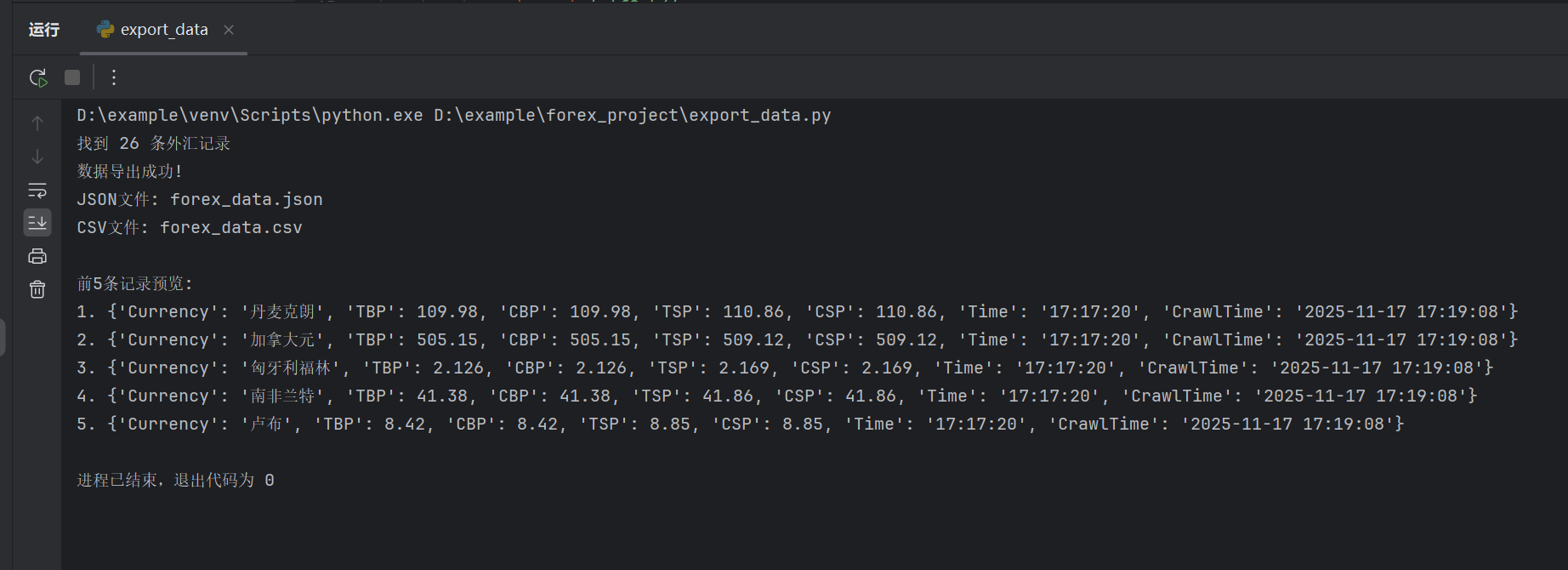
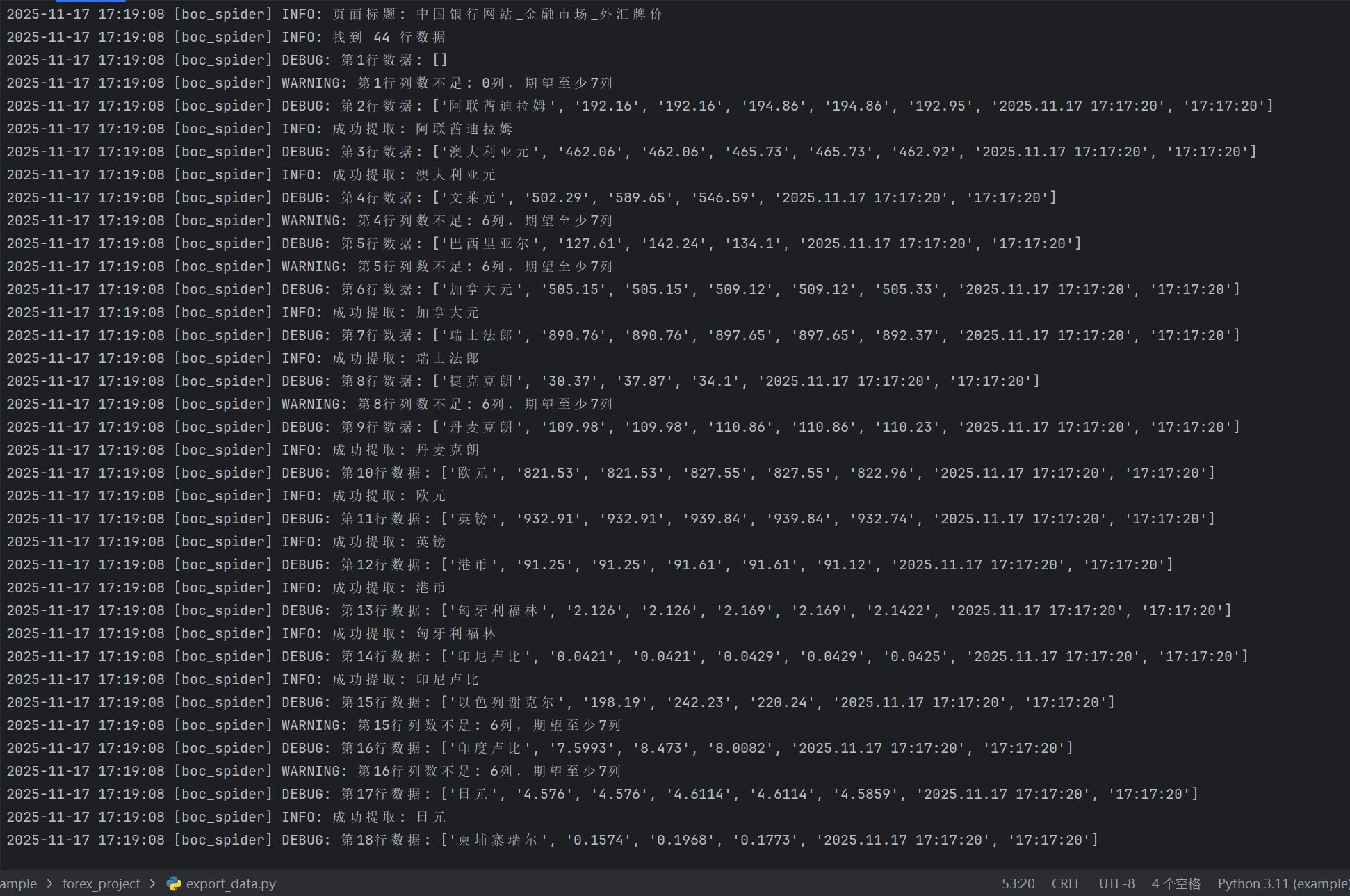
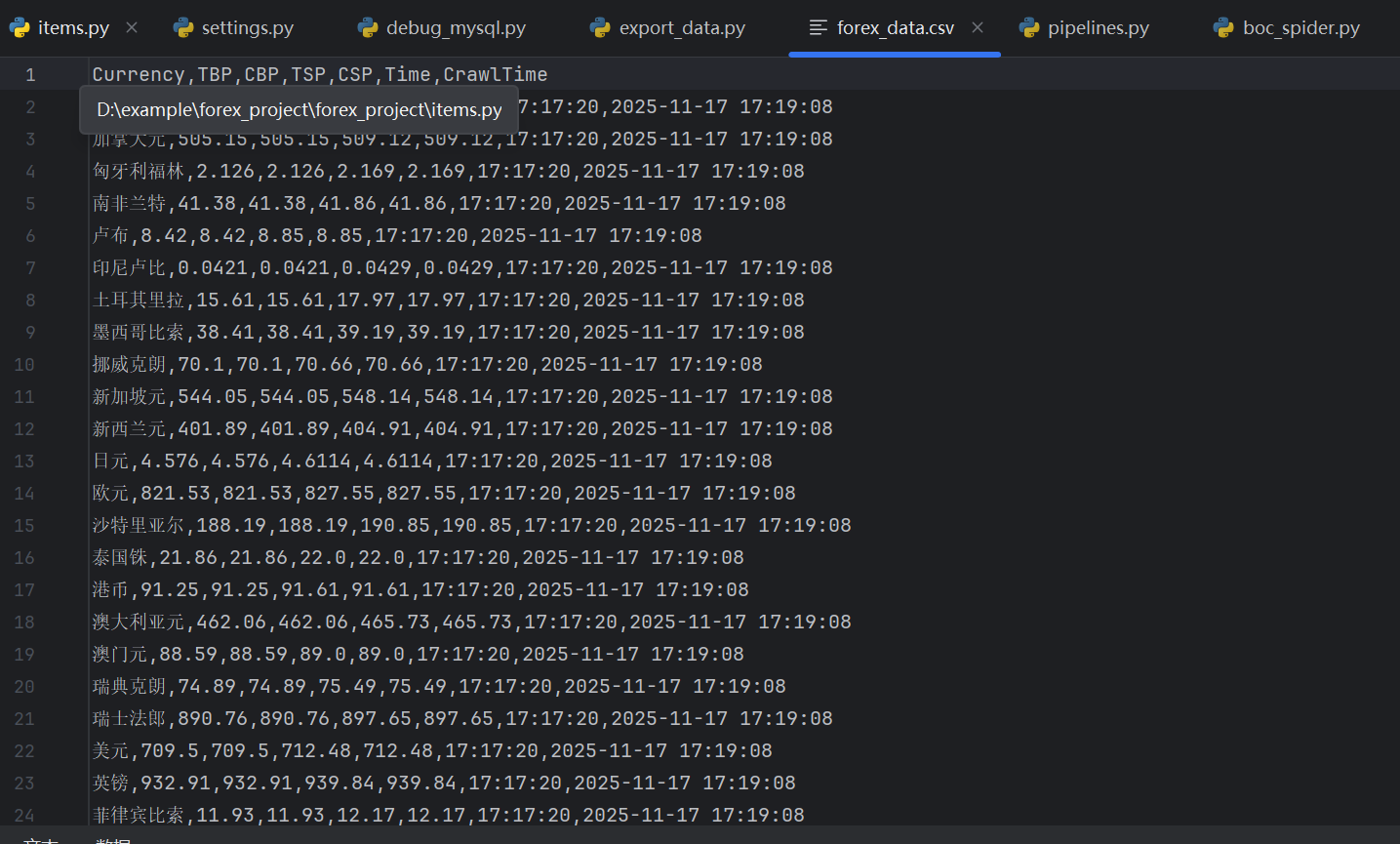
Gitee文件夹链接:https://gitee.com/hu_beibei/data-collection-practice/tree/master/102302109_胡贝贝_作业3/作业3/forex_project
(2)实验心得
爬取中国银行外汇数据让我进一步熟练了Scrapy框架。我体会到精确的Xpath选择器的重要性,并成功将数据序列化存储到数据库。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号