

102302109_胡贝贝_作业2
作业①
(1)实验内容及结果
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
核心代码:
class WeatherDB:
def __init__(self):
self.con = None
self.cursor = None
def openDB(self):
self.con = sqlite3.connect("weathers.db")
self.cursor = self.con.cursor()
self.cursor.execute(
"CREATE TABLE IF NOT EXISTS weathers ("
"wCity VARCHAR(16), wDate VARCHAR(16), "
"wWeather VARCHAR(64), wTemp VARCHAR(32), "
"CONSTRAINT pk_weather PRIMARY KEY (wCity, wDate))"
)
return True
def closeDB(self):
if self.con:
self.con.commit()
self.con.close()
self.con = None
self.cursor = None
def insert(self, city, date, weather, temp):
try:
self.cursor.execute(
"INSERT OR REPLACE INTO weathers (wCity, wDate, wWeather, wTemp) VALUES (?, ?, ?, ?)",
(city, date, weather, temp)
)
return True
except Exception as err:
print(f"插入数据失败: {err}")
return False
def show(self):
self.cursor.execute("SELECT * FROM weathers ORDER BY wCity, wDate")
rows = self.cursor.fetchall()
print(f"{'城市':<8} {'日期':<15} {'天气':<25} {'温度':<12}")
for row in rows:
print(f"{row[0]:<8} {row[1]:<15} {row[2]:<25} {row[3]:<12}")
return rows
class WeatherForecast:
def __init__(self):
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"}
self.cityCode = {
"北京": "101010100", "上海": "101020100", "广州": "101280101",
"深圳": "101280601", "杭州": "101210101", "南京": "101190101"
}
self.db = WeatherDB()
def forecastCity(self, city):
if city not in self.cityCode.keys():
return False
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req, timeout=10).read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
soup = BeautifulSoup(dammit.unicode_markup, "lxml")
weather_container = soup.select("ul[class='t clearfix'] li")
if not weather_container:
return False
for li in weather_container:
try:
date = li.select('h1')[0].text.strip()
weather = li.select('p[class="wea"]')[0].text.strip()
temp_high = li.select('p[class="tem"] span')
temp_low = li.select('p[class="tem"] i')
temp = temp_high[0].text + "/" + temp_low[0].text if temp_high and temp_low else "N/A"
self.db.insert(city, date, weather, temp)
print(f"{city} {date}: {weather} {temp}")
except Exception:
continue
return True
except Exception as err:
print(f"获取 {city} 天气数据失败: {err}")
return False
def process(self, cities):
self.db.openDB()
for city in cities:
self.forecastCity(city)
self.db.show()
self.db.closeDB()
输出信息:
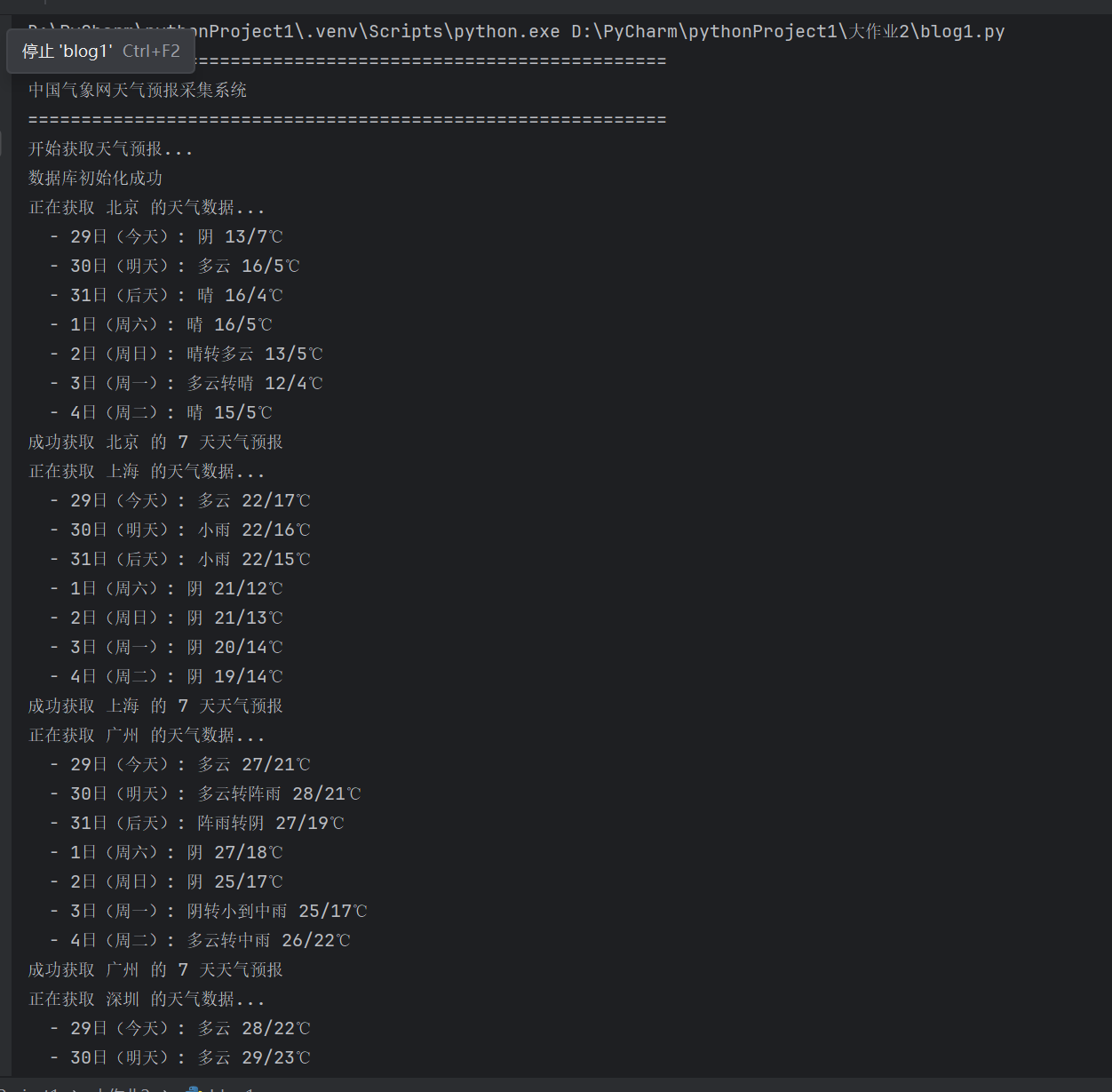
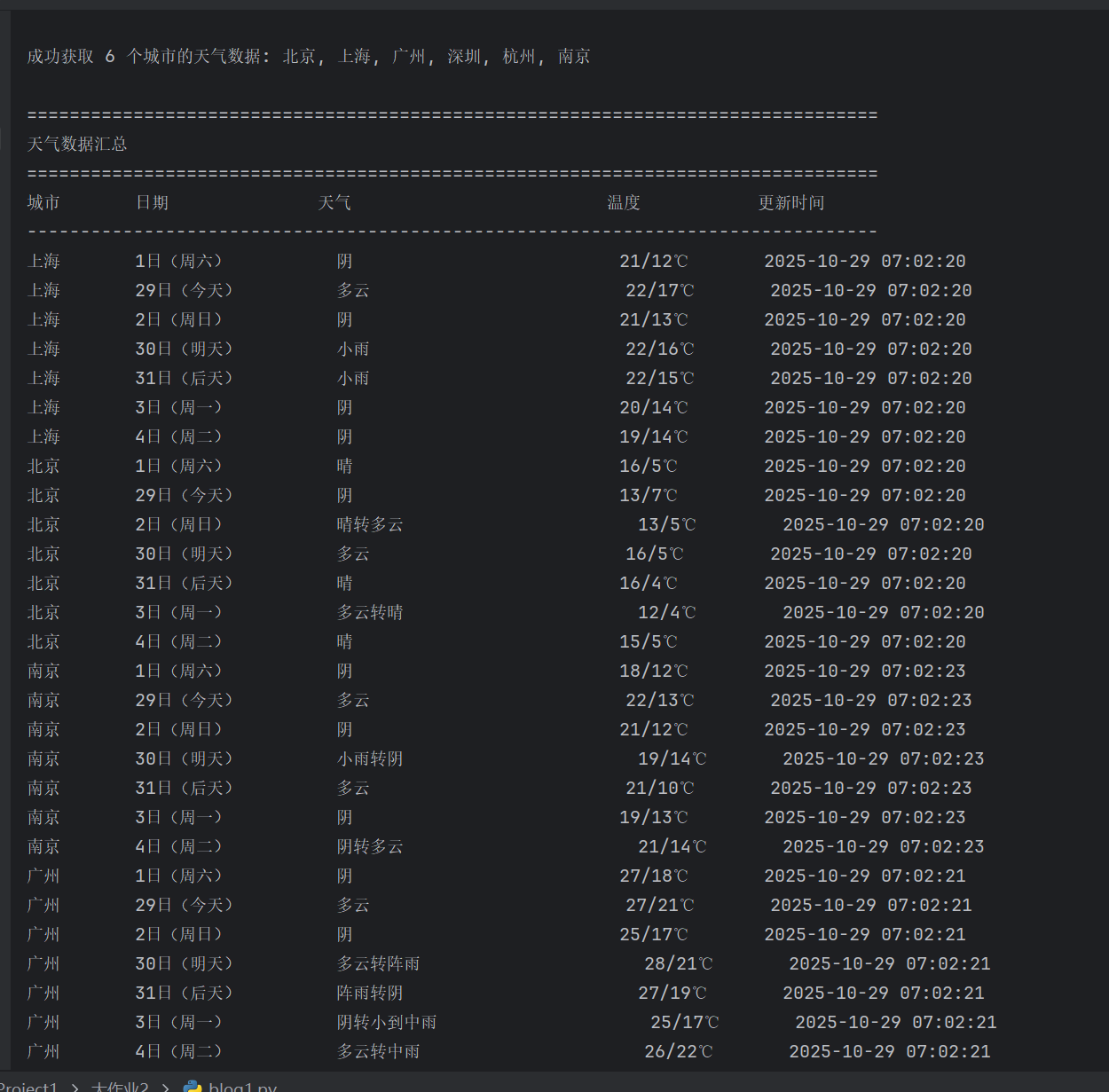

Gitee文件夹链接:https://gitee.com/hu_beibei/data-collection-practice/blob/master/102302109_胡贝贝_作业2/blog1.py
(2)实验心得
通过 requests 获取中国气象网的天气数据,并存入数据库。实验让我熟悉了接口分析和 JSON 解析,也进一步理解了数据从网站到入库的完整流程。
作业②
(1)实验内容及结果
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
核心代码:
def get_stock_data(page=1):
"""请求东方财富API并解析股票信息"""
url = (
"https://push2.eastmoney.com/api/qt/clist/get?"
"pn={}&pz=50&po=1&np=1&fltt=2&invt=2&fid=f3&fs=m:1+t:2,m:1+t:23&"
"fields=f12,f14,f2,f3,f4,f5,f6,f7"
).format(page)
resp = requests.get(url, headers={"User-Agent": "Mozilla/5.0"})
text = resp.text
# 提取 JSON 内容
match = re.search(r"\{.*\}", text)
if not match:
print("未找到 JSON 数据")
return []
data = json.loads(match.group())
# 判断接口返回是否正常
if "data" not in data or "diff" not in data["data"]:
print("返回数据结构异常")
return []
stocks = []
for item in data["data"]["diff"]:
# 数据清洗与转换
row = (
item.get("f12", ""), # 股票代码
item.get("f14", ""), # 股票名称
round(float(item.get("f2", 0)), 2), # 最新价
round(float(item.get("f3", 0)), 2), # 涨跌幅(%)
round(float(item.get("f4", 0)), 2), # 涨跌额
round(float(item.get("f5", 0)) / 10000, 2), # 成交量(万手)
round(float(item.get("f6", 0)) / 100000000, 2),# 成交额(亿元)
round(float(item.get("f7", 0)), 2), # 振幅(%)
)
stocks.append(row)
return stocks
def save_to_db(stocks):
"""保存股票信息到SQLite数据库"""
conn = sqlite3.connect(r"D:\PyCharm\pythonProject1\大作业2\stocks.db")
cur = conn.cursor()
cur.execute("""
CREATE TABLE IF NOT EXISTS stock_info (
id INTEGER PRIMARY KEY AUTOINCREMENT,
code TEXT,
name TEXT,
price REAL,
change_percent REAL,
change REAL,
volume REAL,
turnover REAL,
amplitude REAL
)
""")
cur.executemany("""
INSERT INTO stock_info (code, name, price, change_percent, change, volume, turnover, amplitude)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
""", stocks)
conn.commit()
conn.close()
print(f"已成功保存 {len(stocks)} 条股票数据到数据库 stocks.db")
输出信息:


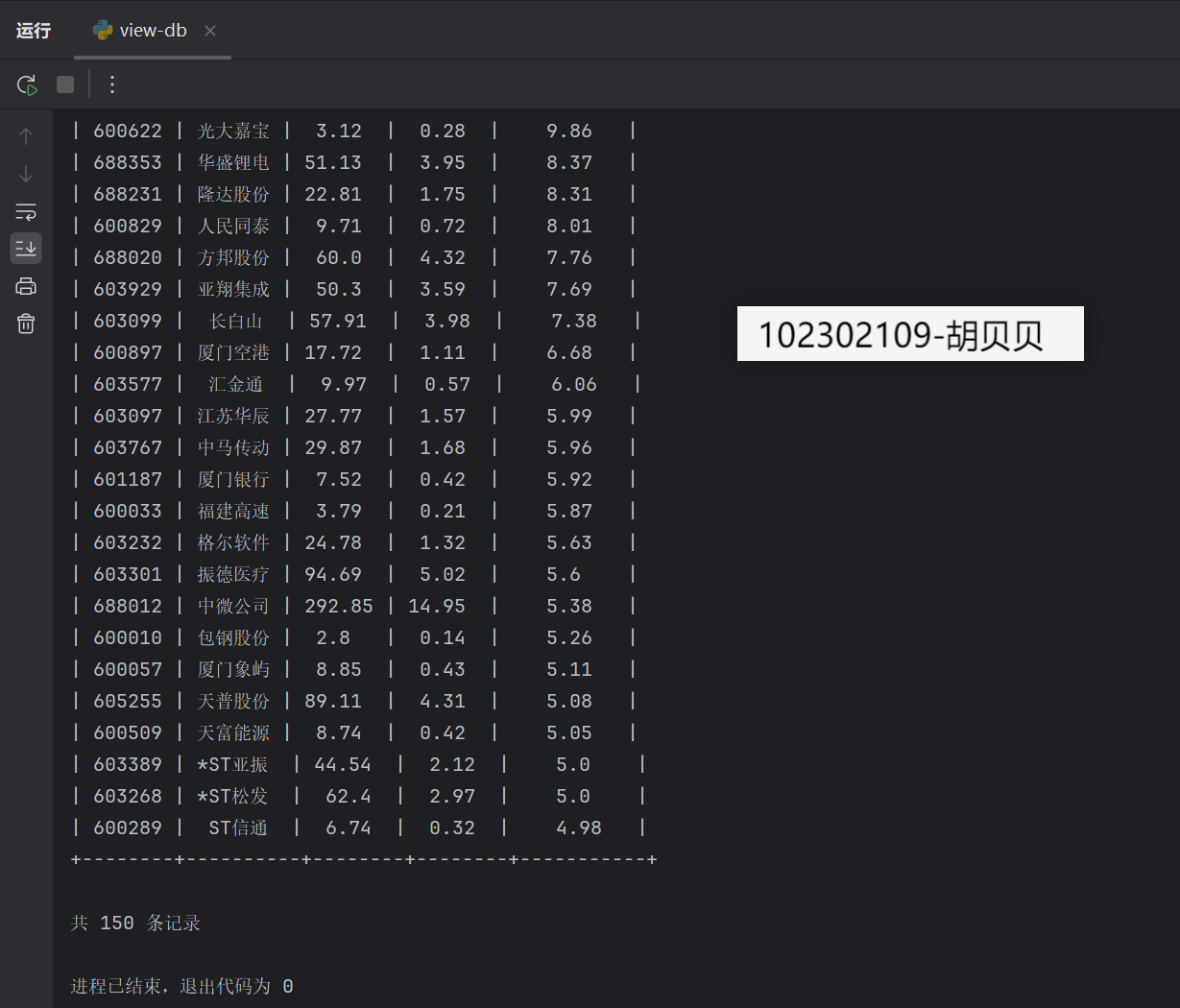
Gitee文件夹链接:https://gitee.com/hu_beibei/data-collection-practice/blob/master/102302109_胡贝贝_作业2/blog2.py
(2)实验心得
使用 F12 抓包找到股票数据接口,通过 requests 获取并解析,再写入数据库。实验提升了我对接口参数分析和数据处理的能力,对爬虫更熟练了。
作业③
(1)实验内容及结果
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
核心代码:
import re
import csv
# 文件路径
path = r"D:\PyCharm\pythonProject1\大作业2\payload.json"
# 省份映射表
province_map = {
"q": "北京", "D": "上海", "k": "江苏", "y": "安徽", "w": "湖南",
"s": "陕西", "F": "福建", "u": "广东", "n": "山东", "v": "湖北",
"x": "浙江", "r": "辽宁", "M": "重庆", "K": "甘肃", "C": "吉林",
"I": "广西", "N": "天津", "B": "黑龙江", "z": "江西", "H": "云南",
"t": "四川", "o": "河南", "J": "贵州", "L": "新疆", "G": "海南",
"aA": "青海", "aB": "宁夏", "aC": "西藏"
}
# 类型映射表
category_map = {
"f": "综合", "e": "理工", "h": "师范", "m": "农业", "S": "林业",
"i": "医药", "a": "财经", "j": "政法", "g": "民族", "d": "语言",
"b": "艺术", "c": "体育"
}
# 读取文件
with open(path, "r", encoding="utf-8") as f:
text = f.read()
# 匹配大学数据
pattern = re.compile(
r'univNameCn:\s*"([^"]+)"[\s\S]*?univCategory:\s*(\w+)[\s\S]*?province:\s*(\w+)[\s\S]*?score:\s*([\d.]+)',
re.MULTILINE
)
matches = pattern.findall(text)
print(f"共提取到 {len(matches)} 所大学信息\n")
# 输出前100所大学
print("=== 中国大学排名 2021(前100) ===")
print(f"{'排名':<4}{'学校':<12}{'省市':<8}{'类型':<8}{'总分'}")
print("-" * 40)
# 写入 CSV
with open("ranking2021.csv", "w", newline="", encoding="utf-8-sig") as f:
writer = csv.writer(f)
writer.writerow(["排名", "学校", "省市", "类型", "总分"])
for i, (name, category_var, prov_var, score) in enumerate(matches[:100], start=1):
province = province_map.get(prov_var, prov_var)
category = category_map.get(category_var, category_var)
print(f"{i:<4}{name:<12}{province:<8}{category:<8}{score}")
writer.writerow([i, name, province, category, score])
print("\n数据已写入 ranking2021.csv")
输出信息:


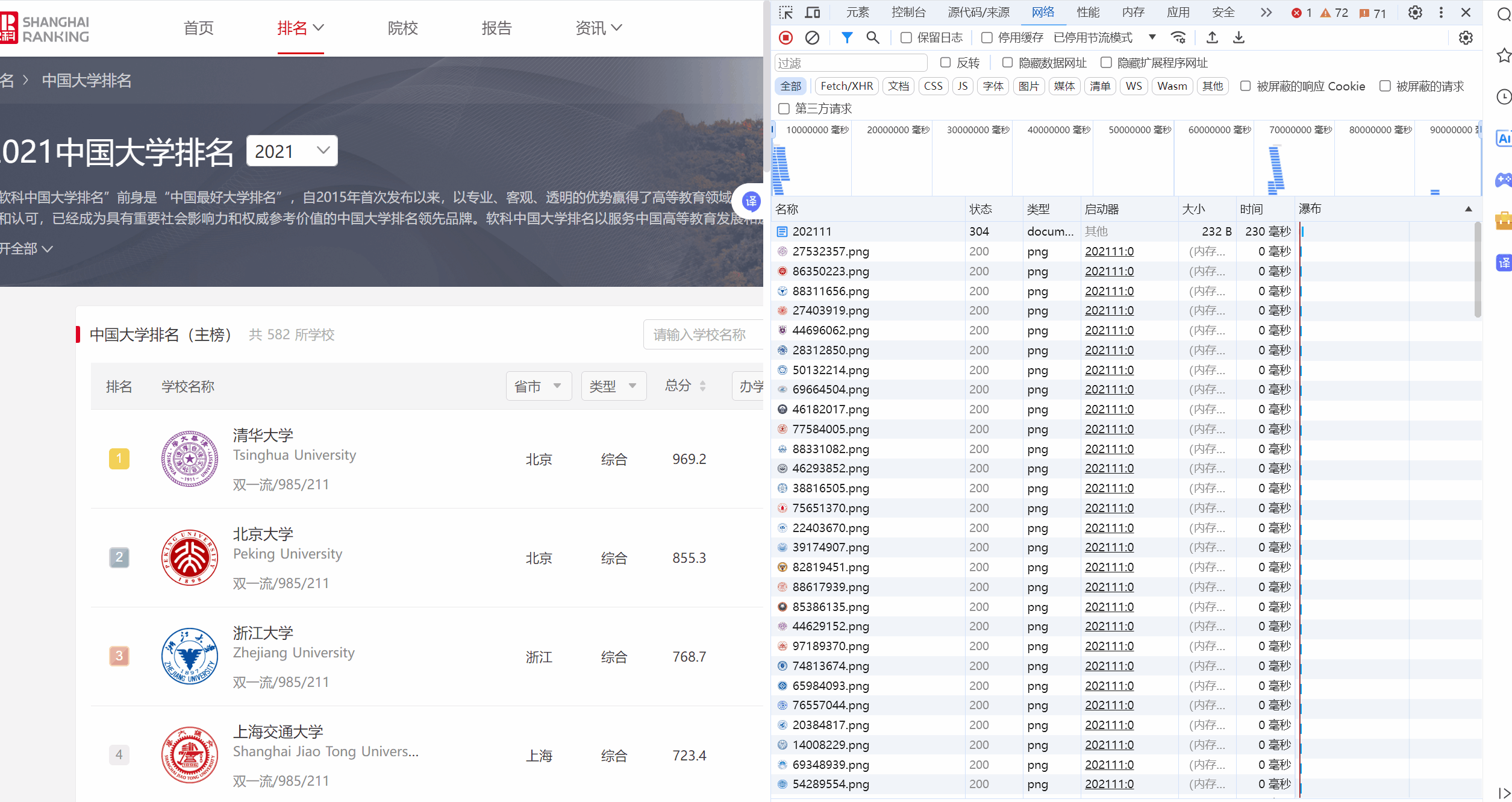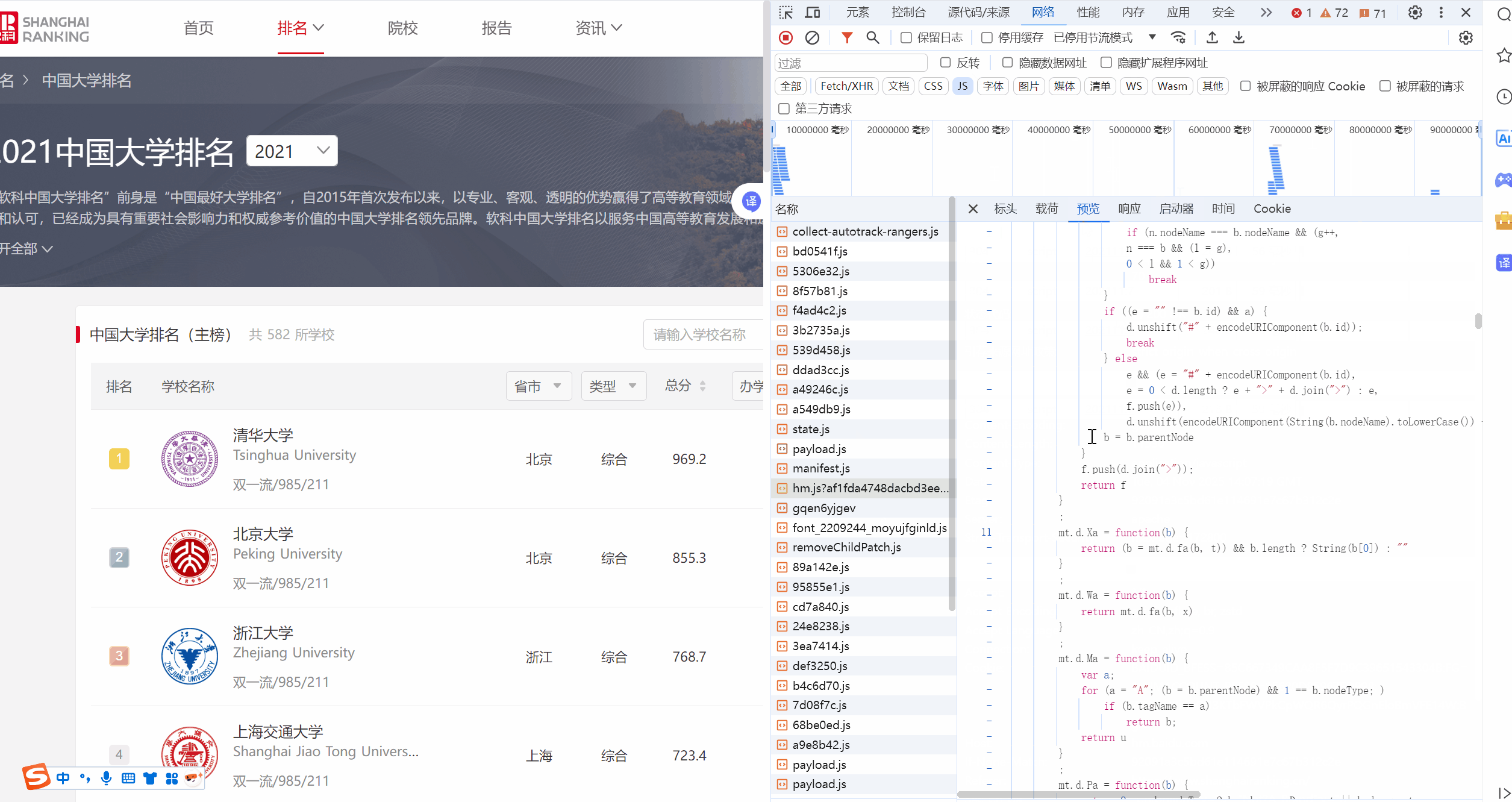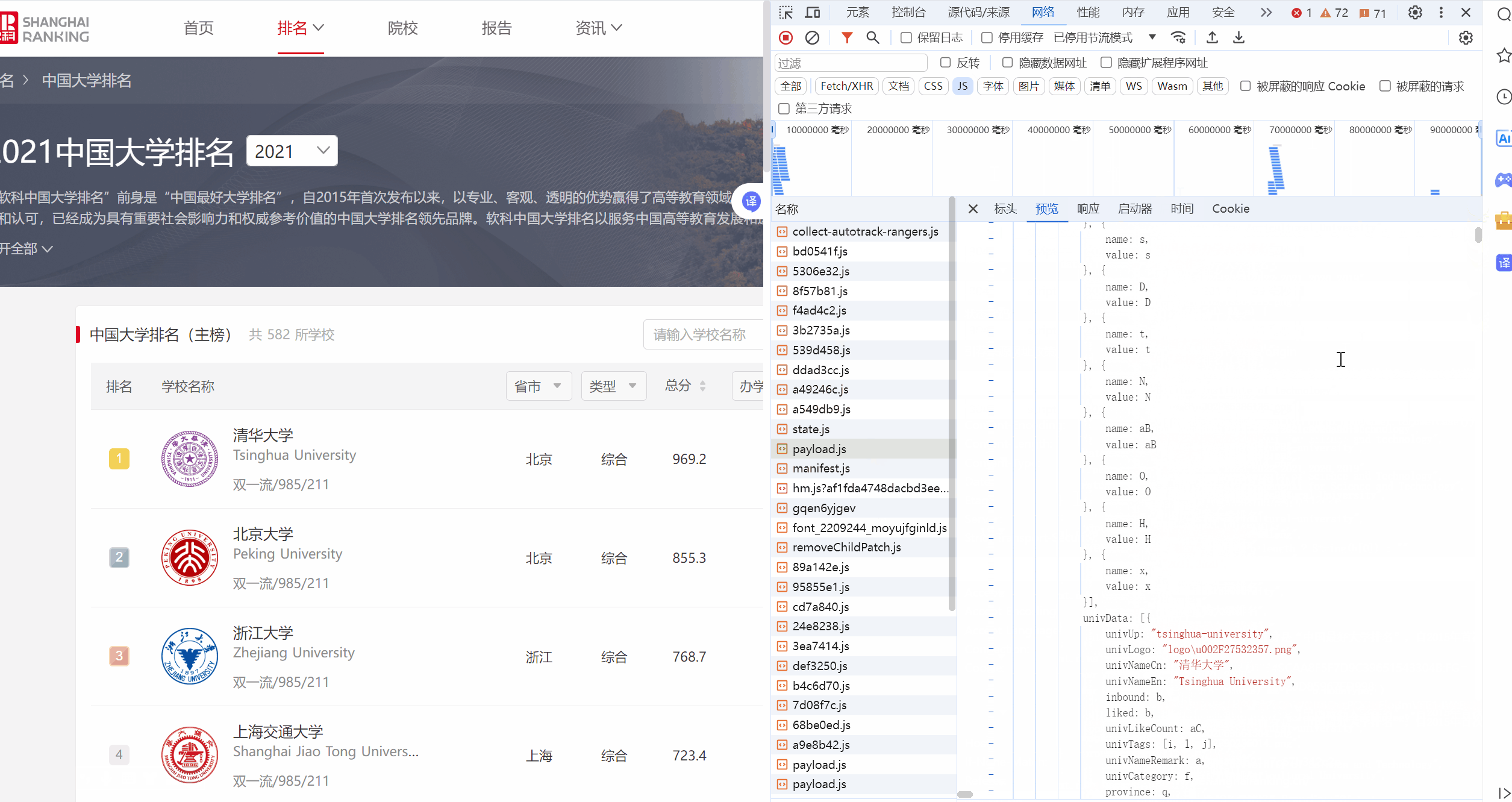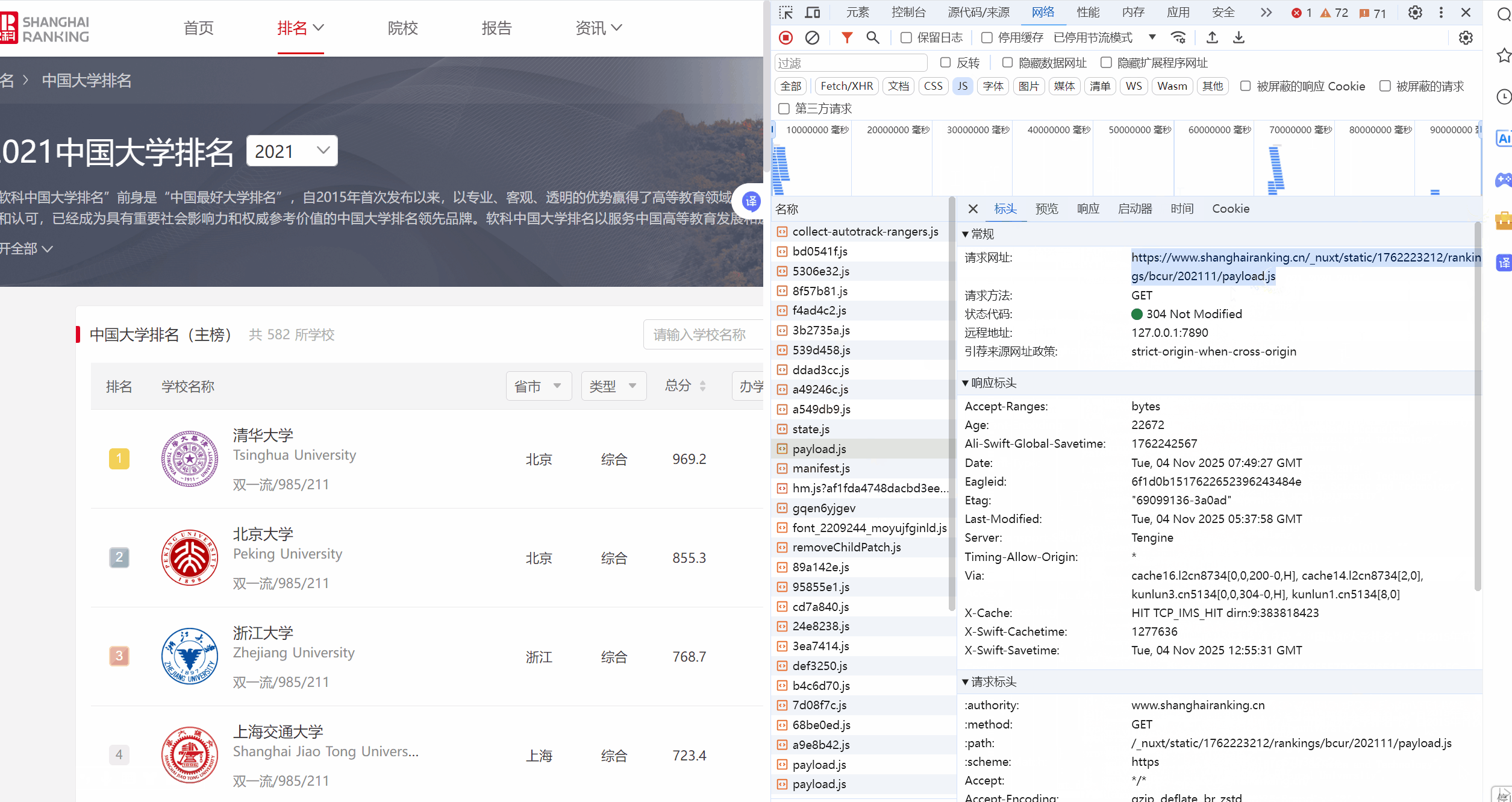
Gitee文件夹链接:https://gitee.com/hu_beibei/data-collection-practice/blob/master/102302109_胡贝贝_作业2/blog3.py
(2)实验心得
通过分析中国大学排名网站的接口,直接获取数据并存入数据库,同时录制抓包过程为 GIF。实验加深了我对 API 分析和数据爬取流程的理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号