
Python-groupby
1. 有行索引的df进行df.groupby(cols)
df原本的行索引不会自动转为列保留,而是被直接替换成cols。
cols_3 = ['val1','val2','val3'] cols_2 = ['val1','val2'] df1 = pd.DataFrame({'val1':['杭州','大连','大连','大连'], 'val2':[1,2,2,2], 'val3':[2,3,4,5], 'val4':[3,4,5,6], 'i0':[3,4,3,2], 'i1':[3,4,5,5]}).set_index(cols_3) display(df1) df1_max = df1[['i0','i1']].reset_index(cols_2) # df1_max的列为cols_2 + ['i0','i1'],行索引为'val3' display(df1_max) df1_max = df1_max.groupby(cols_2).max() # 有行索引的df1_max进行groupby; df.max()默认是对df每个列求该列的最大值 display(df1_max)

2. df中新增一列, 求每个分组内的记录 在某指定列上的和、平均值(会把 0 也加上去算平均值)、记录个数、最大值、最小值
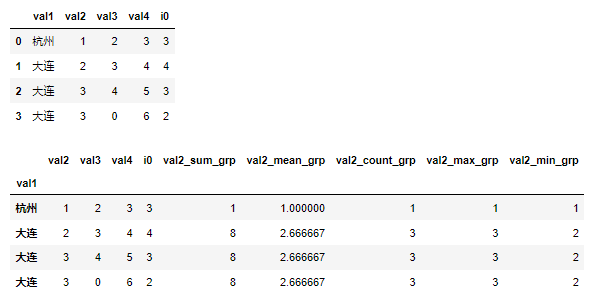
df = pd.DataFrame({'val1':['杭州','大连','大连','大连'],'val2':[1,2,3,3],'val3':[2,3,4,0],'val4':[3,4,5,6],'i0':[3,4,3,2]})
display(df)
df['val2_sum_grp'] = df.groupby(['val1'])['val2'].transform('sum')
# df = df.set_index(['val1'])
# df['val2_sum_grp'] = df['val2'].sum(level=['val1']) # 分组内求和
df['val2_mean_grp'] = df.groupby(['val1'])['val2'].transform('mean')
# 等价于以下两句
# df = df.set_index(['val1'])
# df['val2_mean_grp'] = df['val2'].mean(level=['val1']) # 分组内求平均值
df['val2_count_grp'] = df.groupby(['val1'])['val2'].transform('count') # 分组内求记录个数
df['val2_max_grp'] = df.groupby(['val1'])['val2'].transform('max') # 分组内求某一列的最大值
# 等价于以下两句
# df = df.set_index(['val1'])
# df['val2_max_grp'] = df['val2'].max(level=['val1'])
df['val2_min_grp'] = df.groupby(['val1'])['val2'].transform('min') # 分组内求某一列的最小值
# 等价于以下两句
# df = df.set_index(['val1'])
# df['val2_min_grp'] = df['val2'].min(level=['val1'])
display(df)
3. df中不新增列、只留分组依据列+某一列,并将某一列替换为:每个分组内的记录在该列上的统计指标(平均值、和、记录数、最大值、最小值)
df = pd.DataFrame({'val1':['杭州','大连','大连','大连'],'val2':[1,2,3,3],'val3':[2,3,4,0],'val4':[3,4,5,6],'i0':[3,4,3,2]})
display(df)
df = df.groupby(['val1','val2'])[['val3']].mean()
# df = df.groupby(['val1','val2'])[['val3']].sum()
# df = df.groupby(['val1','val2'])[['val3']].count()
# df = df.groupby(['val1','val2'])[['val3']].max()
# df = df.groupby(['val1','val2'])[['val3']].min()
display(df)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号