
秋天网址评分排名爬虫
一、选题的背景
为什么要选择此选题?
要达到的数据分析的预期目标是什么?(10 分)
从社会、经济、技术、数据来源等方面进行描述(200 字以内)
互联网时代,许多影视软件出现在大家的眼前,在众多的影视软件中如何选取其中的优质影视软件呢,所以我选取秋天网址评分排名里的休闲娱乐方面对影视软件的评分信息进行爬取分析,来得到优质的评分软件
二、主题式网络爬虫设计方案(10 分)
1.主题式网络爬虫名称
秋天网址评分排名爬虫,url='http://www.top1oftops.com/cat.do?cat1id=4&web=3&cat2id=0'
2.主题式网络爬虫爬取的内容与数据特征分析
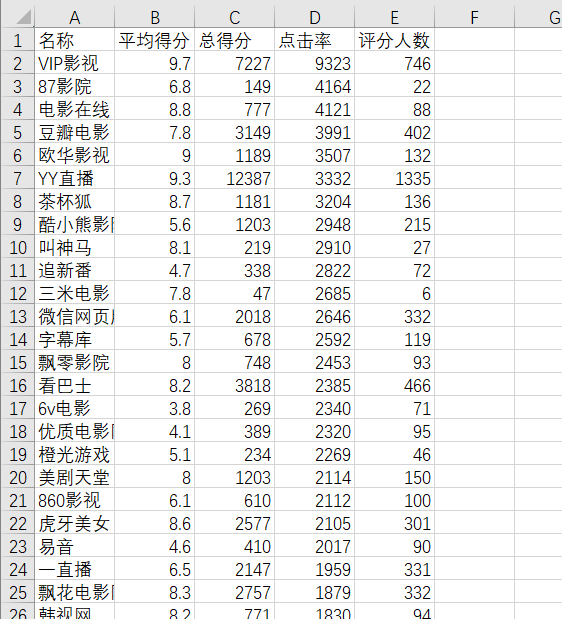
爬取他们的软件名称、总得分、点击率、评分人数、平均得分,这些数据可以反应软件的热度和用户体验感,具有一定的可参考价值
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
查看页面的源代码查看数据是在css文件还是在js文件中,观察css文件中的数据分布,数据与其它数据的特点,是使用正则表达式还是使用数据标签来查找数据,数据在css文件中,还是比较好提取的
三、主题页面的结构特征分析(10 分)
1.主题页面的结构与特征分析
网址的主页如下

爬取获得的text文本如下
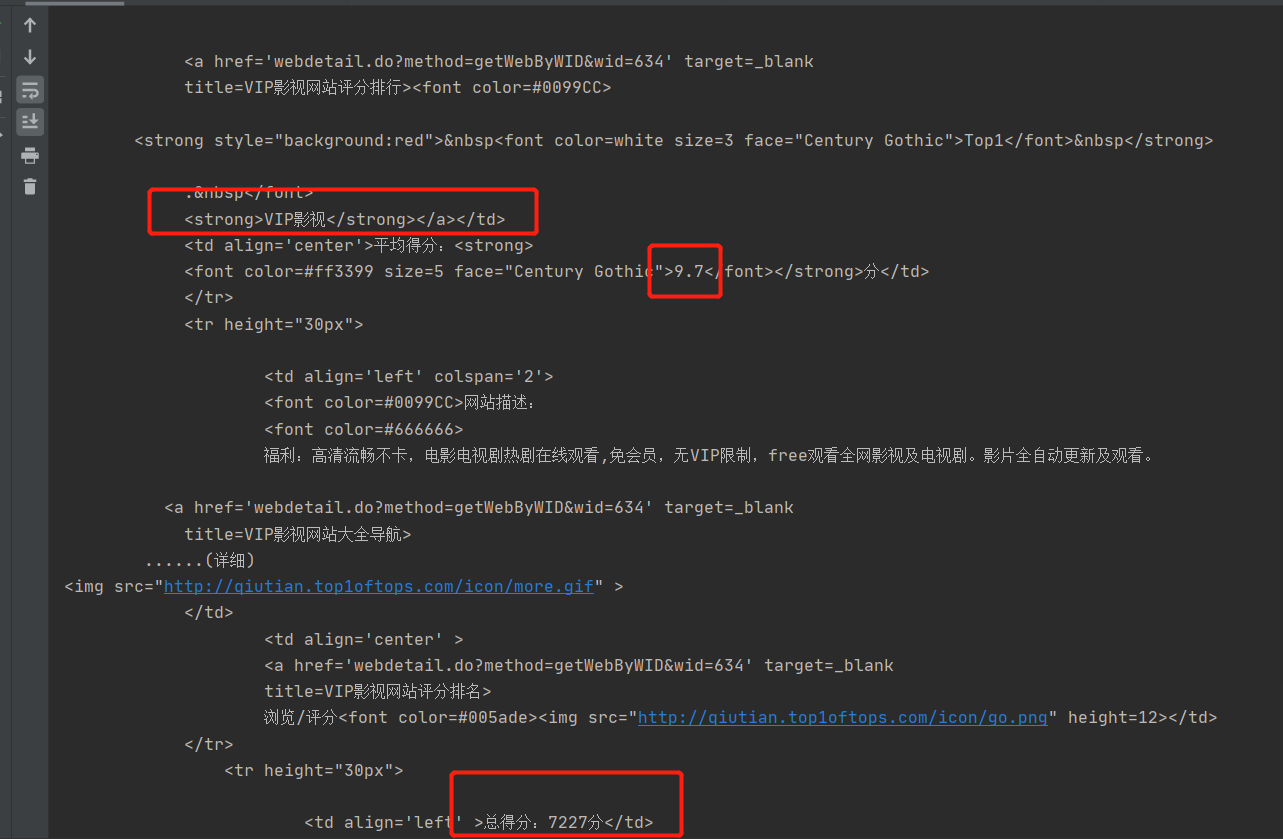

一个软件的数据在一个td标签内,数据分散在各个标签中,部分可以通过标签属性直接获取,部分使用正则表达式来获取更佳
2.Htmls 页面解析
一个软件一个td标签,软件名在strong标签下,平均得分在font标签下,其它在小td标签下面
3.节点(标签)查找方法与遍历方法 (必要时画出节点树结构)
vip影视纯字符并不能用正则表达式提取,比较适合用标签提取,选取用a标签后strong标签来获取。总得分和评分人数用正则表达式提取更加方便快捷,点击率用其独特属性来获取
平均得分的标签font属性'color':'#0099CC','size':'2'是唯一的可以定位来查找数据,点击率用font标签的'color':'#0099CC','size':'2'属性可以快速定位获取
四、网络爬虫程序设计(60 分)
1 import requests 2 import re 3 from bs4 import BeautifulSoup 4 from matplotlib import pyplot as plt 5 import pandas as pd 6 from wordcloud import WordCloud 7 import numpy as np 8 9 #秋天网址评分排名-休闲娱乐 10 url='http://www.top1oftops.com/cat.do?cat1id=4&web=3&cat2id=0' 11 r= requests.get(url) 12 r.raise_for_status() 13 r.encoding =r.apparent_encoding 14 15 #正则表达式来获取总得分 16 score=re.findall(r'.{3}\:[0-9]{1,5}.', r.text) 17 #整理 18 score_list=[] 19 for i in score: 20 score_list.append(i[4:-1]) 21 22 #点击量 23 soup=BeautifulSoup(r.text, 'html.parser') 24 click_dict={'color':'#0099CC','size':'2'} 25 click=soup.find_all('font',click_dict) 26 click_list=[] 27 for i in click: 28 str_click=str(i.string) 29 click_list.append(str_click) 30 #整理 31 click_list=click_list[2:] 32 33 #评分人数 34 grade=re.findall(r'.{4}\:\s[0-9]{1,9}.',r.text) 35 grade_list=[] 36 #选取数字部分 37 for i in grade: 38 grade_list.append(i[6:-1]) 39 40 #平均得分 41 goal_dict={'color':'#ff3399','size':'5'} 42 goal=soup.find_all('font',goal_dict) 43 goal_list=[] 44 for i in goal: 45 str_goal=str(i.string) 46 goal_list.append(str_goal) 47 48 #名字 49 a_dict={'target':'_blank'} 50 #采用逐步提取先a 后strong 51 name=soup.find_all('a',a_dict) 52 names=[] 53 for i in name: 54 strong_name=i.find_all('strong') 55 for j in strong_name: 56 #一些a标签没有strong 去空列表 57 if len(j)!=0: 58 names.append(j.string) 59 name_list=[] 60 #去None 61 for i in names: 62 if(i!=None): 63 name_list.append(i) 64 65 #数据放进一个列表 66 alls=[] 67 all=[] 68 all.append("名称") 69 all.append("平均得分") 70 all.append("总得分") 71 all.append("点击率") 72 all.append("评分人数") 73 alls.append(all) 74 all=[] 75 for i in range(0,len(name_list)): 76 all.append(name_list[i]) 77 all.append(goal_list[i]) 78 all.append(score_list[i]) 79 all.append(click_list[i]) 80 all.append(grade_list[i]) 81 alls.append(all) 82 all=[] 83 84 import pandas as pd 85 #显示所有列 86 pd.set_option('max_columns',100) 87 #显示所有行 88 pd.set_option('max_rows', 100) 89 #设置value的显示长度为100,默认为50 90 pd.set_option('max_colwidth',100) 91 92 #数据写入文件 93 import csv 94 file = open('d:\\autumn.csv','w',newline='') 95 w= csv.writer(file) 96 for i in alls: 97 w.writerow(i) 98 file.close() 99 100 #pandas数据显示 101 display=pd.read_csv('d:\\autumn.csv',encoding='gb18030') 102 display.head()

1 #词云 2 #词云的文本 3 yun='' 4 for i in range(len(name_list)): 5 goal_float=float(goal_list[i]) 6 goal_int=int(goal_float) 7 na=name_list[i]+'\t' 8 ci=na*goal_int 9 yun+=ci 10 11 #中文包地址 12 path='D:\SimHei.ttf' 13 w=WordCloud(font_path=path, 14 background_color='green', 15 width=800, 16 height=600, 17 ) 18 #文本 19 w.generate(yun) 20 plt.imshow(w) 21 plt.axis() 22 #显示 23 plt.show() 24 #词云保存地 25 w.to_file('d:/qiu.png')

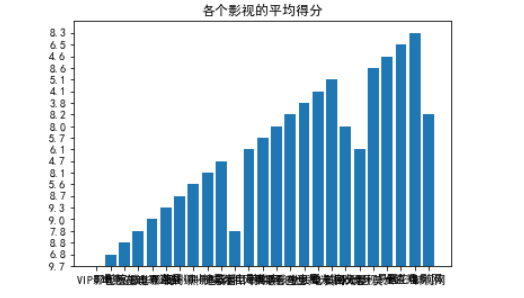
1 #平均得分的条形图 2 import matplotlib.pyplot as plt 3 # 这两行代码解决 plt 中文显示的问题 4 plt.rcParams['font.sans-serif'] = ['SimHei'] 5 plt.rcParams['axes.unicode_minus'] = False 6 7 x =name_list 8 y =goal_list 9 10 plt.bar(x,y) 11 plt.title('各个影视的平均得分') 12 plt.show()
1 #三维图 2 from mpl_toolkits.mplot3d import Axes3D 3 intgoal=[] 4 for i in range(len(name_list)): 5 goal_float=float(goal_list[i]) 6 goal_int=int(goal_float) 7 intgoal.append(goal_int) 8 mydpi = 96 9 plt.figure(figsize=(480 / mydpi, 480 / mydpi), dpi=mydpi) 10 11 df = pd.DataFrame({'X': grade_list, 'Y': click_list, 12 'Z': intgoal}) 13 fig = plt.figure() 14 ax = fig.add_subplot(111, projection='3d') 15 ax.scatter(df['X'], df['Y'], df['Z'], c='skyblue', s=60) 16 ax.view_init(50, 200) 17 plt.show()

1 #饼图 2 a=0 3 b=0 4 c=0 5 d=0 6 e=0 7 f=0 8 g=0 9 h=0 10 j=0 11 k=0 12 for i in grade_list: 13 intgrade=eval(i) 14 if 0<=intgrade<50: 15 a+=1 16 elif 50<=intgrade<100: 17 b+=1 18 elif 100<=intgrade<150: 19 c+=1 20 elif 150<=intgrade<200: 21 d+=1 22 elif 200<=intgrade<250: 23 e+=1 24 elif 250<=intgrade<350: 25 f+=1 26 elif 350<=intgrade<450: 27 g+=1 28 elif 450<=intgrade<550: 29 h+=1 30 elif 550<=intgrade<1000: 31 j+=1 32 else: 33 k+=1 34 number=[a,b,c,d,e,f,g,h,j,k] 35 table=['0~50','50~100','100~150','150~200','200~250','250~350','350~450',"450~550",'550~1000','1000+'] 36 plt.pie(x = number, labels=table) 37 plt.show()

1 #散点图 2 x=score_list 3 y=goal_list 4 plt.scatter(x, y,marker='>') 5 plt.show()
1 from openpyxl import Workbook 2 mybook = Workbook() 3 wa = mybook.active 4 for i in alls: 5 wa.append(i) 6 #存放文件地址 7 mybook.save('d://autw.xlsx')
1 # 2 import requests 3 import re 4 from bs4 import BeautifulSoup 5 from matplotlib import pyplot as plt 6 import pandas as pd 7 from wordcloud import WordCloud 8 import numpy as np 9 10 #秋天网址评分排名-休闲娱乐 11 url='http://www.top1oftops.com/cat.do?cat1id=4&web=3&cat2id=0' 12 r= requests.get(url) 13 r.raise_for_status() 14 r.encoding =r.apparent_encoding 15 16 #正则表达式来获取总得分 17 score=re.findall(r'.{3}\:[0-9]{1,5}.', r.text) 18 #整理 19 score_list=[] 20 for i in score: 21 score_list.append(i[4:-1]) 22 23 #点击量 24 soup=BeautifulSoup(r.text, 'html.parser') 25 click_dict={'color':'#0099CC','size':'2'} 26 click=soup.find_all('font',click_dict) 27 click_list=[] 28 for i in click: 29 str_click=str(i.string) 30 click_list.append(str_click) 31 #整理 32 click_list=click_list[2:] 33 34 #评分人数 35 grade=re.findall(r'.{4}\:\s[0-9]{1,9}.',r.text) 36 grade_list=[] 37 #选取数字部分 38 for i in grade: 39 grade_list.append(i[6:-1]) 40 41 #平均得分 42 goal_dict={'color':'#ff3399','size':'5'} 43 goal=soup.find_all('font',goal_dict) 44 goal_list=[] 45 for i in goal: 46 str_goal=str(i.string) 47 goal_list.append(str_goal) 48 49 #名字 50 a_dict={'target':'_blank'} 51 #采用逐步提取先a 后strong 52 name=soup.find_all('a',a_dict) 53 names=[] 54 for i in name: 55 strong_name=i.find_all('strong') 56 for j in strong_name: 57 #一些a标签没有strong 去空列表 58 if len(j)!=0: 59 names.append(j.string) 60 name_list=[] 61 #去None 62 for i in names: 63 if(i!=None): 64 name_list.append(i) 65 66 #数据放进一个列表 67 alls=[] 68 all=[] 69 all.append("名称") 70 all.append("平均得分") 71 all.append("总得分") 72 all.append("点击率") 73 all.append("评分人数") 74 alls.append(all) 75 all=[] 76 for i in range(0,len(name_list)): 77 all.append(name_list[i]) 78 all.append(goal_list[i]) 79 all.append(score_list[i]) 80 all.append(click_list[i]) 81 all.append(grade_list[i]) 82 alls.append(all) 83 all=[] 84 85 import pandas as pd 86 #显示所有列 87 pd.set_option('max_columns',100) 88 #显示所有行 89 pd.set_option('max_rows', 100) 90 #设置value的显示长度为100,默认为50 91 pd.set_option('max_colwidth',100) 92 93 #数据写入文件 94 import csv 95 file = open('d:\\autumn.csv','w',newline='') 96 w= csv.writer(file) 97 for i in alls: 98 w.writerow(i) 99 file.close() 100 101 #pandas数据显示 102 display=pd.read_csv('d:\\autumn.csv',encoding='gb18030') 103 display.head() 104 105 #词云 106 #词云的文本 107 yun='' 108 for i in range(len(name_list)): 109 goal_float=float(goal_list[i]) 110 goal_int=int(goal_float) 111 na=name_list[i]+'\t' 112 ci=na*goal_int 113 yun+=ci 114 115 #中文包地址 116 path='D:\SimHei.ttf' 117 w=WordCloud(font_path=path, 118 background_color='green', 119 width=800, 120 height=600, 121 ) 122 #文本 123 w.generate(yun) 124 plt.imshow(w) 125 plt.axis() 126 #显示 127 plt.show() 128 #词云保存地 129 w.to_file('d:/qiu.png') 130 131 #平均得分的条形图 132 import matplotlib.pyplot as plt 133 # 这两行代码解决 plt 中文显示的问题 134 plt.rcParams['font.sans-serif'] = ['SimHei'] 135 plt.rcParams['axes.unicode_minus'] = False 136 137 x =name_list 138 y =goal_list 139 140 plt.bar(x,y) 141 plt.title('各个影视的平均得分') 142 plt.show() 143 144 #三维图 145 from mpl_toolkits.mplot3d import Axes3D 146 intgoal=[] 147 for i in range(len(name_list)): 148 goal_float=float(goal_list[i]) 149 goal_int=int(goal_float) 150 intgoal.append(goal_int) 151 mydpi = 96 152 plt.figure(figsize=(480 / mydpi, 480 / mydpi), dpi=mydpi) 153 154 df = pd.DataFrame({'X': grade_list, 'Y': click_list, 155 'Z': intgoal}) 156 fig = plt.figure() 157 ax = fig.add_subplot(111, projection='3d') 158 ax.scatter(df['X'], df['Y'], df['Z'], c='skyblue', s=60) 159 ax.view_init(50, 200) 160 plt.show() 161 162 #饼图 163 a=0 164 b=0 165 c=0 166 d=0 167 e=0 168 f=0 169 g=0 170 h=0 171 j=0 172 k=0 173 for i in grade_list: 174 intgrade=eval(i) 175 if 0<=intgrade<50: 176 a+=1 177 elif 50<=intgrade<100: 178 b+=1 179 elif 100<=intgrade<150: 180 c+=1 181 elif 150<=intgrade<200: 182 d+=1 183 elif 200<=intgrade<250: 184 e+=1 185 elif 250<=intgrade<350: 186 f+=1 187 elif 350<=intgrade<450: 188 g+=1 189 elif 450<=intgrade<550: 190 h+=1 191 elif 550<=intgrade<1000: 192 j+=1 193 else: 194 k+=1 195 number=[a,b,c,d,e,f,g,h,j,k] 196 table=['0~50','50~100','100~150','150~200','200~250','250~350','350~450',"450~550",'550~1000','1000+'] 197 plt.pie(x = number, labels=table) 198 plt.show() 199 200 #散点图 201 x=score_list 202 y=goal_list 203 plt.scatter(x, y,marker='>') 204 plt.show() 205 206 #写入excel 207 from openpyxl import Workbook 208 mybook = Workbook() 209 wa = mybook.active 210 for i in alls: 211 wa.append(i) 212 #存放文件地址 213 mybook.save('d://autw.xlsx')
五、总结(10 分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
近一半软件的点击率很低都在一百一下,这些都是冷门不好用的。可以看出受追捧的休闲娱乐影视热门软件是韩剧网、美剧天堂、看巴士、欧华影视、VIP影视、一直播等,我们选取了其中的精华,可以从中选取软件看剧,达到了预期的目标。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
爬虫可以轻松获取数据,我们可以对数据进行任意提取来分析出我们想要的信息,了解一些行业的行情,选取优质部分,弃其糟粕。需要进一步学习数据的分析方法,了解数据之间的奥义

