
CUDA学习笔记
 本笔记旨在简单记录一些《CUDA by Example. An Introduction to General-Purpose GPU Programming》书籍上的重要概念。
介绍了CUDA的一些基本操作和核心概念
本笔记旨在简单记录一些《CUDA by Example. An Introduction to General-Purpose GPU Programming》书籍上的重要概念。
介绍了CUDA的一些基本操作和核心概念
CUDA
[!NOTE]
本笔记推荐使用Typora的Mdmdt主题渲染
本笔记旨在简单记录一些《CUDA by Example. An Introduction to General-Purpose GPU Programming》书籍上的重要概念。
核函数
我们通常把CPU和系统的内存称为主机(host),把GPU以及其内存称为设备(device)
在设备上执行的函数称为核函数(kernal)
核函数的声明和调用
标识符__global__告知编译器,该函数应该被编译成运行在设备上而不是主机上
标识符__device__告知编译器,该函数运行在设备上,而且仅能由__global__或__device__标识的函数所调用
CUDA的编译器和运行时会处理好从主机上调用核函数的一些琐碎事务,包括将核函数参数传递给设备
语法<<<Blocks, ThreadsPerBlock>>>告知CUDA运行时如何启动该核函数;第一个参数的含义是我们想让设备分配多少并行块来运行该核函数;第二个参数表示我们希望CUDA运行时为我们创建的每个块的线程数。
上面提到的,运行在GPU上的并行块的集合称为网格(grid)
[!NOTE]
分配并行块的数量和每个块的线程数量都有限制,若超出限制可能会导致核函数调用失败,因此任务的计算量最好不能与这两个参数有关联,最好的情况是任务的计算量限制仅与设备内存相关
针对上面的问题常见的做法是提前固定好三重括号(<<<_, _>>>)内参数的数量,在核函数内进行多轮循环以覆盖全部任务。(实际上这种做法可能也存在一定的坏处,后面会介绍)
核函数的内部变量
我们前面已经解释了三重括号的作用,我们利用GPU的原因就是其强大的并行处理能力,使用三重括号可以告知CUDA运行时以什么方式并行启动我们的核函数,此时会有多个线程(这些线程共享同一份核函数代码,执行相同的代码逻辑)同时执行,这里有一个问题,既然所有线程都执行相同的逻辑,那么不就是在做重复的工作吗?
为了解决这个问题,CUDA运行时为我们提供了可以在核函数内使用的一些变量,用来标识当前是执行的是哪个线程。也就是说我们在核函数内要做的就是利用这个线程标识来准确的分配我们的计算任务给每一个线程。
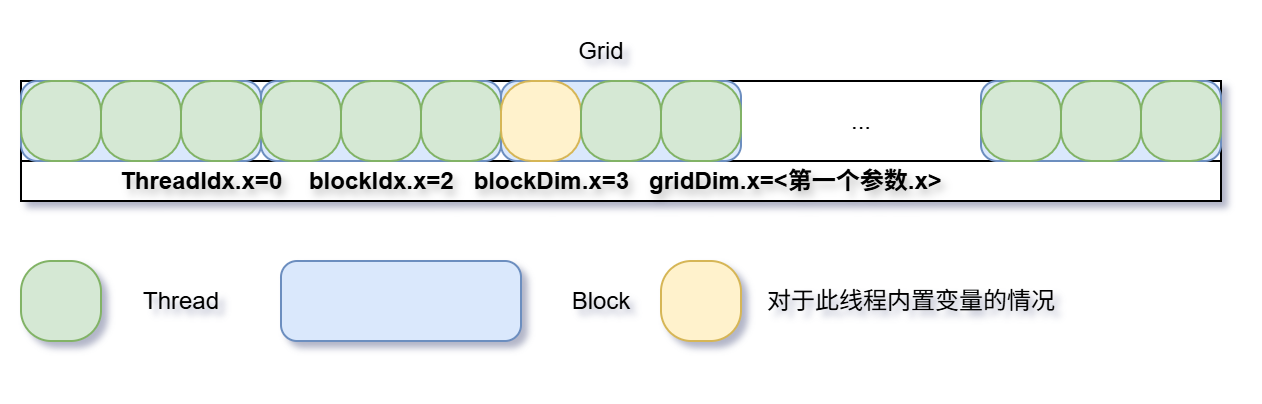
线程索引(threadIdx)和块索引(blockIdx)分别用来标识当前线程位于块中的第几个,以及位于网格的哪个块中
块维度(blockDim)和网格维度(girdDim)分别用来表示块的线程数量好网格的块数量
上面的三个变量的数据类型都是dim3,也就是有三个维度用来适配在1、2、3维做计算的计算任务
向三重括号传递时既可以直接传递整数(运行时自动识别为1维的配置),或者传入像这样初始化的变量(推测是用了宏处理)🚩
dim3 grid(dimX, dimY);
核函数内置变量的使用
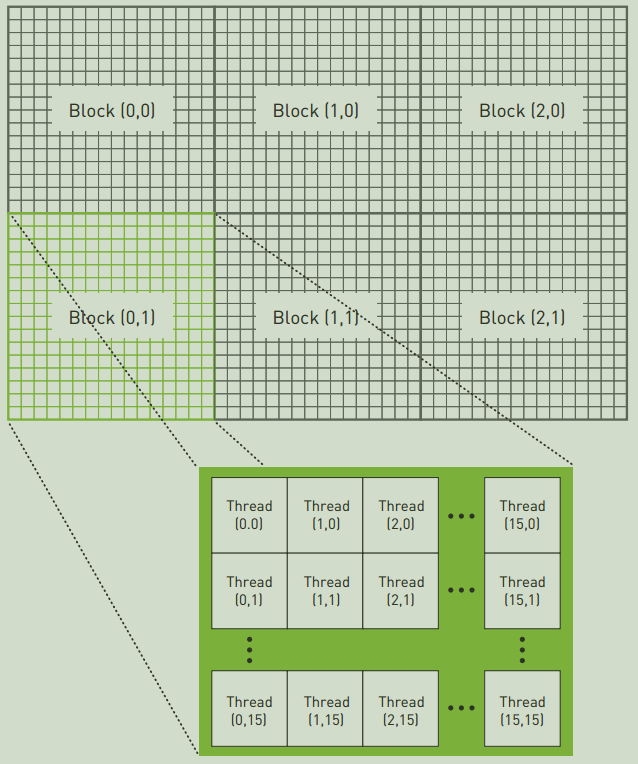
1D
在一维的情况下(也就是直接向三重括号传递整数),Grid的情况可以理解为下图:
因此该线程的索引便是:
int idx = blockIdx.x * blockDim.x + threadIdx.x;
2D
2维的情况下(也就是向三重括号传递上面的dim3 ),Grid如下所示:
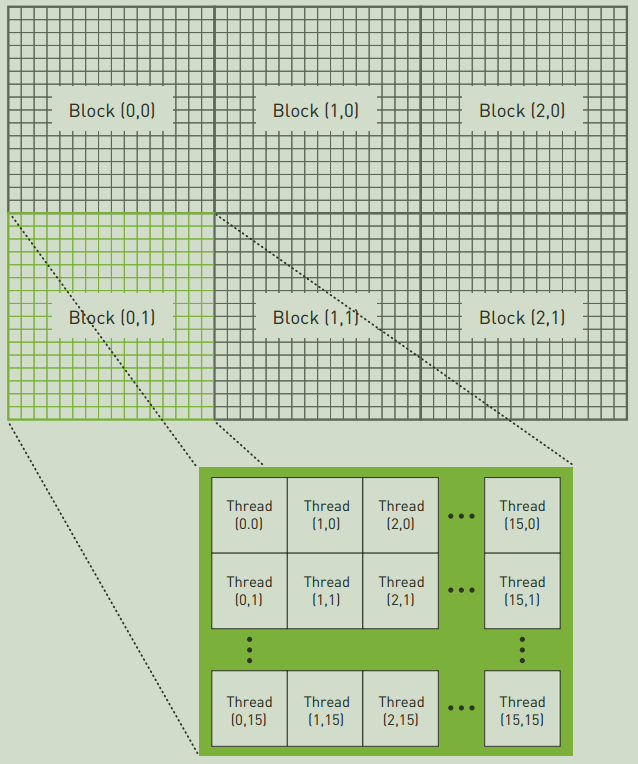
其中方括号内的分别代表着blockIdx.x、blockIdx.y、threadIdx.x和threadIdx.y,由图gridDim为(3, 2),blockDim为(16, 16)。
因此,线程索引可以这样计算:
int idxX = blockIdx.x * blockDim.x + threadIdx.x; // same as 1D
int idxY = blockIdx.y * blockDim.y + threadIdx.y;
int idx = idxY * gridDim.x * blockDim.x + idxX;
设备内存
在设备上计算需要用到设备的内存而不是主机内存,常用的分配设备内存的方法是cudaMalloc()
[!IMPORTANT]
不能在主机代码上解引用指向设备指针,不能在设备代码上解引用指向主机的指针
想要在主机上访问设备内存的内容,可以通过cudaMemcpy()将设备内存的内容复制到主机后访问
共享内存和同步
使用修饰符__shared__可以使你的变量驻留在共享内存,可是我们为什么要使用共享内存呢?
__shared__ float cache[N];
首先作为共享内存的变量会被复制到每个块中,块之间的共享内存不可见,块内的线程可以访问该内存,也就是说可以作为块内线程通信的手段。
更重要的是共享内存的缓冲区驻留在GPU上,而不会像普通变量一样在片下DRAM,这意味着其内存访问延迟更小。
[!WARNING]
涉及到共享就不得不提到同步或数据依赖的问题
考虑内积(点乘)的计算,我们需要先将向量对应的分部相乘,然后再相加。仔细考虑然后这个地方,若是有部分线程计算较快提前进入了相加阶段,而此时慢的线程还没有将正确结果写入共享内存,此时就会出问题!
线程同步(__syncthreads())保证了,在执行该语句之前,所有块内线程都已经结束了该语句之前指令的执行,这正是我们想要的。
将输入数组进行一系列计算,最终得到一个更小结果数组的通用过程,我们称之为归约,在并行计算中,归约是非常常见的,以下是一种计算归约的方法。
[!WARNING]
线程分歧当存在分支语句时,必然会出现不同的线程走不同分支的现象,这种现象叫做线程分歧。不要将线程同步放在任何有线程分歧的分支中,否则可能会导致无限等待,以至于程序错误中断
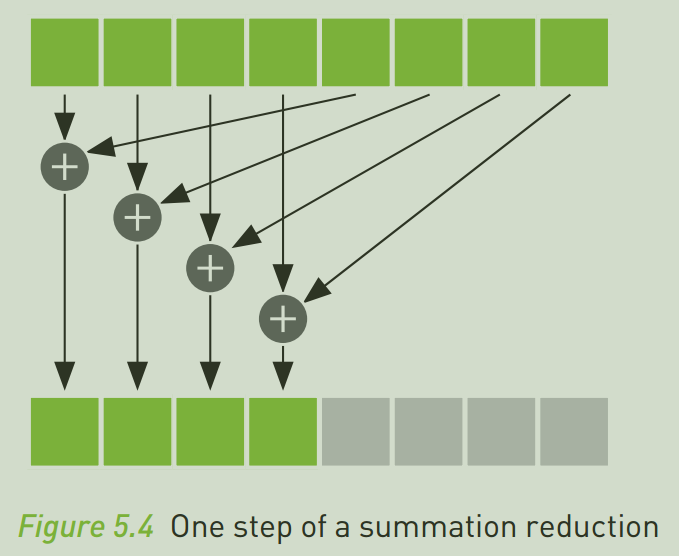
[!NOTE]
像计算点乘这样的操作,在一开始时我们启动了大量的块,线程去并行计算逐项相乘,但是在最后做归约加法时,越是加到最后,这些启动的块的利用率就越低,有时还不如直接返回到主机让CPU执行计算。
常量内存和事件
GPU有着大量的计算单元,事实上在CUDA编程时瓶颈最容易出现的地方往往不是芯片上算法的运行,而是芯片的内存带宽,在某些情况下使用常量内存会比使用全局内存减少内存带宽负载
这里以简单的光线追踪渲染为例讲解常量内存的使用,光线追踪在渲染过程中需要对每个需要渲染的物体遍历计算一些必要信息,而这些物体的数据往往是不变的,因此可以将他们放在常量内存中
类似于共享内存,使用修饰符__constant__可以声明常量内存,不同于共享内存的是该修饰符可以在主机代码中使用。声明常量内存后不必手动为之在设备上分配内存,且复制主机数据到常量内存时使用cudaMemcpyToSymbol(),这与cudaMemcpy()复制时没什么不同,就是终点是常量内存罢了
__constant__ Sphere s[SPHERES];
cudaMemcpyToSymbol(s, temp_s, sizeof(Sphere) * SPHERES);
使用常量内存有两点好处:
- 从常亮内存中读取的单个数据可以广播到其他“临近”的线程
- 常量内存有缓存机制,连续读取同一地址的常量内存,不会造成额外的内存开销
这里的临近是什么意思呢?这需要我们先了解一个概念——线程束(wrap)
线程束是 GPU 上基本的执行单元,由 32 个线程组成,这些线程被硬件自动分组,线程束内的所有线程在同一周期执行相同的指令(单指令多数据,SIMD 模式),但操作的数据可以不同。这种 "锁步执行"(lockstep)意味着如果线程束内的线程出现分支(如 if-else 语句),会导致线程束分化(warp divergence),需要串行执行不同分支,从而降低效率。
当半线程束(16 个线程)中的所有线程请求常量内存中的同一个地址时,GPU 硬件只会发起一次内存读取,然后将结果广播到该半线程束内的所有 16 个线程。
[!WARNING]
半线程束广播机制是把双刃剑,因为以半线程束为单位,每次只能发出一次内存请求。这意味着,如果半线程束内的每一个线程都有不同地址的请求,那么他们只会顺序执行,而不是一次性解决。
事件
意识到进行某些操作会优化或者反向优化我们的程序,因此我们必须想办法评测我们的程序性能,一个最简单的方法就是测量时间。
事件(event)本质上是记录了用户指定时刻的GPU时间戳,为了记录一个指定时刻我们可以这样做:
cudaEvent_t start;
cudaEventCreate(&start);
cudaEventRecord(start, 0); // 0的含义在后面Stream解释
深入探寻cudaEventRecord(),你可以这样想象,当调用此函数时,GPU的待处理指令队列中加了一个记录时间的指令,直到前面的指令完成后这条指令才会执行。这对我们记录核函数执行时间非常有帮助。
cudaEventRecord(start, 0);
// kernal<<<xx,xx>>>(xx,xx); ....
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
// 使用stop和start的信息计算核函数执行时间
cudaEventElapsedTime(&elapsedTime, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
但是这里有一个问题,那就是CPU和GPU是异步的,当我们打算利用stop和start的信息计算核函数执行时间时,可能核函数的所有指令还未执行完毕,导致stop还未记录。因此我们有必要让CPU等待stop事件记录后再执行,这就是上面代码示例中cudaEventSynchronize()的作用。
cudaEventDestory()用来摧毁创建的事件,cudaEventElapsedTime()返回ms为单位的时间。
[!NOTE]
此处发现了一个奇怪的问题,程序首次编译后运行的时间远大于第二次重新运行的时间
Review\Code\VSC [C v15.2.0-gcc] ❯ nvcc .\6DotProductTimeEvent.cu 6DotProductTimeEvent.cu tmpxft_00000728_00000000-7_6DotProductTimeEvent.cudafe1.cpp Review\Code\VSC [C v15.2.0-gcc][⏱ 2s] ❯ .\a.exe dot product = 102400 time = 13.1625 Review\Code\VSC [C v15.2.0-gcc] ❯ .\a.exe dot product = 102400 time = 0.758816
Waitting For Update...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号