











String字符串性能优化的探究
一.背景
String 对象是我们使用最频繁的一个对象类型,但它的性能问题却是最容易被忽略的。String 对象作为 Java 语言中重要的数据类型,是内存中占用空间最大的一个对象,高效地使用字符串,可以提升系统的整体性能,比如百M内存轻松存储几十G数据。
如果不正确对待 String 对象,则可能导致一些问题的发生,比如因为使用了正则表达式对字符串进行匹配,从而导致并发瓶颈。
接下来我们就从 String 对象的实现、特性以及实际使用中的优化三方面入手,深入了解。
二.String对象的实现
在开始之前,先思考一个问题:通过三种不同的方式创建了三个对象,再依次两两匹配,每组被匹配的两个对象是否相等?
String str1 = "abc"; String str2 = new String("abc"); String str3 = str2.intern(); System.out.println(str1 == str2); System.out.println(str2 == str3); System.out.println(str1 == str3);
对于上面的问题,你可以先思考下答案,以及这样思考的原因。
现在我们回到正题来:String 对象是如何实现的?
在Java语言中,Sun 公司的工程师们对String对象做了大量的优化,来节约内存空间,提升 String 对象在系统中的性能。如下图: 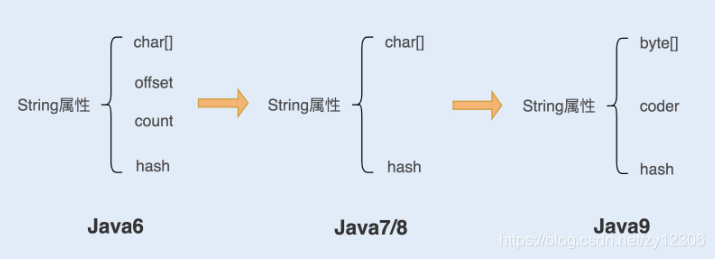
1.在 Java6 以及之前的版本中,String 对象是对 char 数组进行了封装实现的对象,主要有4个成员变量: char 数组、偏移量 offset、字符数量 count、哈希值 hash。
String 对象是通过 offset 和 count 两个属性来定位 char[] 数组,获取字符串。这么做可以高效、快速地共享数组对象,同时节省内存空间,但这种方式很有可能会导致内存泄漏。
2.从 Java7 版本开始到 Java8 版本,Java 对 String 类做了一些改变。String 类中不再有 offset 和 count 两个变量了。这样的好处是 String 对象占用的内存稍微少了些,同时 String.substring 方法也不再共享 char[],从而解决了使用该方法可能导致的内存泄露问题。
3.从 Java9 版本开始,工程师将 char[] 字段改为了 byte[] 字段,又维护了一个新的属性 coder,它是一个编码格式的标识。
工程师为什么这样修改呢?
我们知道一个 char 字符占16位,2个字节。这个情况下,存储单字节编码内的字符(占一个字节的字符)就显得非常浪费。JDK1.9 的 String 类为了节约内存空间,于是使用了占8位,1个字节的 byte 数组来存放字符串。
而新属性 coder 的作用是,在计算字符串长度或者使用 indexOf() 函数时,我们需要根据这个字段,判断如何计算字符串长度。coder 属性默认有 0 和 1 两个值,0 代表 Latin-1(单字节编码),1 代表 UTF-16。如果 String 判断字符串只包含了 latin-1,而 coder 属性值为 0, 反之则为 1。
三. String对象的不可变性
在实现代码中 String 类被 final 关键字修饰了,而且变量 char 数组也被 final修饰了。我们知道类被 final 修饰代表该类不可继承,而 char[] 被 final+private 修饰,代表了 String 对象不可被更改。Java实现的这个特性叫作 String 对象的不可变性,即 String 对象一旦创建成功,就不能再对它进行改变。
Java 这样做的好处在哪里呢?
1)保证 String对象的安全性。假设 String 对象是可变的,那么 String 对象将可能被恶意修改。
2)保证 hash 属性值不会频繁变更,确保了唯一性,使得类型 HashMap 容器才能实现相应的 key-value 缓存功能。
3)可以实现字符串常量池。在 Java 中,通常有两种创建字符串对象的方式,一种是通过字符串常量的方式创建,如 String str = "abc";另一种是字符串变量通过 new 形式的创建,如 String str = new String("abc")。
当代码中使用第一种方式创建字符串对象时,JVM 首先会检查该对象是否在字符串常量池中,如果在,就返回该对象引用,否则新的字符串将在常量池中被创建。这种方式可以减少同一个值的字符串对象的重复创建,节约内存。
String str = new String("abc")这种方式,首先在编译类文件时,“abc”常量字符串将会放入到常量结构中,在类加载时,“abc”将会在常量池中创建;其次,在调用 new 时,JVM 命令将会调用 String 的构造函数,同时引用常量池中的 “abc” 字符串,在堆内存中创建一个 String 对象;最后, str 将引用 String 对象。
说到这里,将讲述一个特殊例子:平常编程时,对一个 String 对象 str 赋值 ”hello“,然后又让 str 赋值为 ”world“,这个时候 str 的值变成了 ”world“,那么 str 值确实改变了,为什么还说 String 对象不可变呢?
在这里要说明对象和对象引用的区别,在 Java 中要比较两个对象是否相等,往往要用 == ,而要判断两个对象的值是否相等,则需要用 equals 方法来判断。
上面的 str 只是 String 对象的引用,并不是对象本身。对象在内存中是有一块内存地址,str 则是一个指向该内存的引用。所以在前面例子中,第一次赋值的时候,创建了一个 ”hello“对象, str 引用指向 ”hello“ 地址;第二次赋值的时候,又重新创建了一个对象 ”world“,str 引用指向了 ”world“,但 “hello” 对象依然存在于内存中。
也就是说 str 并不是对象,而只是一个对象引用。真正的对象依然在内存中,没有被改变。
四.String对象的优化
1.如何构建超大字符串?
编程过程中,字符串的拼接很常见。前面讲过 String 对象是不可变的,如果使用 String 对象相加,拼接想要的字符串,是不是就会产生多个对象呢?例如下面代码:
String str = "ab" + "cd" + "ef";
分析代码可知:首先会生成 ab 对象,再生成 abcd 对象,最后生成 abcdef 对象,从理论上来说,这段代码是低效的。
但实际运行中,我们发现只有一个对象生成,这是为什么呢?我们来看看编译后的代码,你会发现编译器自动优化了这段代码,如下:
String str = "abcdef";
上面讲的是字符串常量的累计,下面看字符串变量的累计:
String str = "abcdef"; for(int i = 0; i < 100; i++){ str = str + i; }
上面的代码编译后,可以看到编译器同样对这段代码进行了优化,Java 在进行字符串的拼接时,偏向使用 StringBuilder,这样可以提高程序的效率。
String str = "abcdef"; for(int i = 0; i < 100; i++){ str = (new StringBuilder(String.valueOf(str))).append(i).toString(); }
综上已知:即使使用 + 号作为字符串的拼接,也一样可以被编译器优化成 StringBuilder 的方式。但再细致些,你会发现在编译器优化的代码中,每次循环都会生成一个新的 StringBuilder 实例,同样也会降低系统的性能。
所以平时做字符串的拼接时,建议显示地使用 StringBuilder 来提升系统性能。
如果在多线程编程中, String 对象的拼接涉及到线程安全,可以使用 StringBuffer,但是由于 StringBuffer 是线程安全的,涉及到锁竞争,所以从性能上来说,要比 StringBuilder 差一些。
2.如何使用 String.intern节省内存?
说完了构建字符串,接下来说下 String 对象的存储问题。先看下面一个案例:
Twitter 每次发布消息状态的时候,都会产生一个地址信息,以当时 Twitter 用户的规模预估,服务器需要 32G 的内存来存储地址信息。
public class Location{ private String city; private String region ; private String countryCode; private double longitude; private double latitude; }
考虑到其中又很多用户在地址信息上是有重合的,比如:国家、省份、城市等,这时可以将这部分信息单独列出一个类,以减少重复。
public class ShareLocation{ private String city; private String region ; private String countryCode; } public class Location{ private ShareLocation shareLocation; private double longitude; private double latitude; }
通过优化,数据存储大小减少到了 20G 左右,但对于内存存储这个数据来说,依然很大,怎么办?
这是可以通过使用 String.intern 来节省内存空间,从而优化 String 对象的存储。
具体做法就是:在每次赋值的时候使用 String 的 intern 方法,如果常量池有相同值,就会重复使用该对象,返回对象引用,这样一开始的对象就可以被回收掉。这种方式可以使重复性非常高的地址信息大小从 20G 降到几百兆。
ShareLocation shareLocation = new ShareLocation(); shareLocation.setCity(messageInfo.getCity().intern()); shareLocation.setRegion(messageInfo.getRegion().intern()); shareLocation.setCountryCode(messageInfo.getCountryCode().intern()): Location location = new Location(); location.set(shareLocation); location.set(messageInfo.getLongitude()); location.set(messageInfo.getLatitude());
为了更好的理解,下面讲述一个简单的例子:
String a = new String("abc").intern(); String b = new String("abc").intern(); if(a == b){ System.out.println("a == b"); } 运行结果: a == b
在字符串常量池中,默认会将对象放入常量池;在字符串变量中,对象是会在堆中创建,同时也会在常量池中创建一个字符串对象,String 对象中的 char 数组将会引用常量池中的 char 数组,并返回堆内存对象引用。
如果调用 intern 方法,会去查看字符串常量池中是否有等于该对象的字符串的引用,如果没有,在 JDK1.6 版本中去复制堆中的字符串到常量池中,并返回该字符串引用,堆内存中原有的字符串由于没有引用指向它,将会通过垃圾回收器回收。
在 JDK1.7 版本以后,由于常量池合并到了堆中,所以不会再复制具体字符串了,只是会把首次遇到的字符串的引用添加到常量池中;如果有,就返回常量池的字符串引用。
现在再来看上面的例子,在一开始字符串 “abc” 会在加载类时,在常量池中创建一个字符串对象。
创建 a 变量时,调用 new String() 会在堆中创建一个 String 对象,String 对象中的 char 数组将会引用常量池中字符串,调用 intern 方法之后,会去常量池中查找是否有等于该字符串对象的引用,有就返回引用。
创建 b 变量时,调用 new String() 会在堆中创建一个 String 对象,String 对象中的 char 数组将会引用常量池中字符串,调用 intern 方法之后,会去常量池中查找是否有等于该字符串对象的引用,有就返回引用。
而在堆内存中的两个对象,由于没有引用指向它,将会被垃圾回收。所以 a 和 b 引用的是同一个对象。
如果在运行时,创建字符串对象,将会直接在堆内存中创建,不会在常量池中创建。所以动态创建的字符串对象,调用 intern 方法,在 JDK1.6 版本中会去常量池中创建运行时常量以及返回字符串引用,在 JDK1.7 版本之后,会将堆中的字符串常量的引用放入到常量池中,当其他堆中的字符串对象通过 intern 方法获取字符串对象时,则会去常量池中判断是否有相同值的字符串的引用,此时有,则返回该常量池中字符串引用,跟之前的字符串指向同一地址的字符串对象。
以一张图来总结 String 字符串的创建分配内存地址情况: 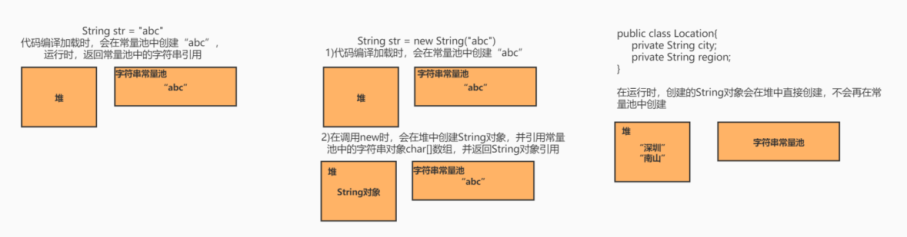
使用 intern 方法需要注意的一点是,一定要结合实际场景,因为常量池的实现是类似于一个 HashTable 的实现方式,HashTable 存储的数据越大,遍历的时间复杂度就会增加。如果数据过大,会增加整个字符串常量池的负担。
3.如何使用字符串的分割方法?
Split() 方法使用了正则表达式实现了其强大的分割功能,而正则表达式的性能是非常不稳定的,使用不恰当会引起回溯问题,很可能导致 CPU 高居不下。
所以应该慎重使用 split() 方法,可以用 String.indexOf() 方法代替 split() 方法完成字符串的分割。如果实在无法满足需求,在使用 split() 方法时,对回溯问题需要加以重视。
五.总结
1)做好 String 字符串性能优化,可以提高系统的整体性能。在这个理论基础上,Java 版本在迭代中通过不断地更改成员变量,节约内存空间,对 String 对象优化。
2)String 对象的不可变性的特性实现了字符串常量池,通过减少同一个值的字符串对象的重复创建,进一步节约内存。
也是因为这个特性,我们在做长字符串拼接时,需要显示使用 StringBuilder,以提高字符串的拼接性能。
3)使用 intern 方法,让变量字符串对象重复使用常量池中相同值的对象,进而节约内存。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【码猿手】。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号