











多线程高并发编程(11) -- 非阻塞算法实现ConcurrentLinkedQueue源码分析
一.背景
要实现对队列的安全访问,有两种方式:阻塞算法和非阻塞算法。阻塞算法的实现是使用一把锁(出队和入队同一把锁ArrayBlockingQueue)和两把锁(出队和入队各一把锁LinkedBlockingQueue)来实现;非阻塞算法使用自旋+CAS实现。
今天来探究下使用非阻塞算法来实现的线程安全队列ConcurrentLinkedQueue,它是一个基于链接节点的无界线程安全队列,采用先进先出的规则对节点进行排序,当我们添加一个元素的时候,它会添加到队列的尾部,当我们获取一个元素时,它会返回队列头部的元素。它采用了“wait-free”算法(即CAS算法)来实现。即当入队时,插入的元素依次向后延伸,形成链表;而出队时,则从链表的第一个元素开始获取,依次递增。
ConcurrentLinkedQueue的类图结构:
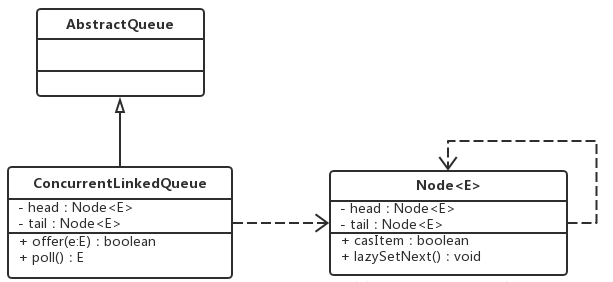
从类图中可以看到,ConcurrentLinkedQueue由head和tail节点组成,每个节点Node由节点元素item和指向下一个节点的引用next组成,节点与节点之间通过next关联起来组成一张链表结构的队列。
二.源码解析
-
构造方法
private static class Node<E> { volatile E item;//元素 volatile Node<E> next;//下一节点 Node(E item) {//添加元素 UNSAFE.putObject(this, itemOffset, item); } boolean casItem(E cmp, E val) {//cas修改元素 return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val); } void lazySetNext(Node<E> val) {//添加节点 UNSAFE.putOrderedObject(this, nextOffset, val); } boolean casNext(Node<E> cmp, Node<E> val) {//cas修改节点 return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val); } private static final sun.misc.Unsafe UNSAFE; private static final long itemOffset; private static final long nextOffset; static { try { UNSAFE = sun.misc.Unsafe.getUnsafe(); Class<?> k = Node.class; //获得元素的偏移位置 itemOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("item")); //获得下一节点的偏移位置 nextOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("next")); } catch (Exception e) { throw new Error(e); } } } //头节点 private transient volatile Node<E> head; //尾节点 private transient volatile Node<E> tail; public ConcurrentLinkedQueue() { //默认情况下head节点存储的元素为空,tail节点等于head节点。 head = tail = new Node<E>(null); } public ConcurrentLinkedQueue(Collection<? extends E> c) { Node<E> h = null, t = null; //遍历集合 for (E e : c) { checkNotNull(e);//检查是否为空,如果为空抛出空指针异常 //创建节点和将元素存储到节点中 Node<E> newNode = new Node<E>(e); if (h == null)//头节点为空 h = t = newNode;//头和尾节点是创建的节点 else { t.lazySetNext(newNode);//添加节点 t = newNode;//修改尾节点的标识 } } //如果集合没有元素,设置队列的头尾节点为空 if (h == null) h = t = new Node<E>(null); head = h;//更新队列的头节点标识 tail = t;//更新队列的尾节点标识 } private static void checkNotNull(Object v) { if (v == null) throw new NullPointerException(); }
-
入队add:

-
入队操作主要做两件事情,第一是将入队节点设置成当前队列尾节点的下一个节点;第二是更新tail节点,如果tail节点的next节点不为空,则将入队节点设置成tail节点,如果tail节点的next节点为空,则将入队节点设置成tail的next节点,所以tail节点不总是尾节点;
-
上面的分析让我们从单线程入队的角度来理解入队过程,但是多个线程同时进行入队情况就变得更加复杂,因为可能会出现其他线程插队的情况。如果有一个线程正在入队,那么它必须先获取尾节点,然后设置尾节点的下一个节点为入队节点,但这时可能有另外一个线程插队了,那么队列的尾节点就会发生变化,这时当前线程要暂停入队操作,然后重新获取尾节点。
-
源码解析:从下面可以看出,入队永远是返回true,所以不要通过返回值判断是否入队成功
public boolean add(E e) { return offer(e); } public boolean offer(E e) { checkNotNull(e);//检查是否为空 //创建入队节点,将元素添加到节点中 final Node<E> newNode = new Node<E>(e); //自旋队列CAS直到入队成功 // 1、根据tail节点定位出尾节点(last node);2、将新节点置为尾节点的下一个节点;3、casTail更新尾节点 for (Node<E> t = tail, p = t;;) { //p是尾节点,q得到尾节点的next Node<E> q = p.next; //如果q为空 if (q == null) { //p是last node,将尾节点的next修改为创建的节点 if (p.casNext(null, newNode)) { //p在遍历后会变化,因此需要判断,如果不相等即p != t = tail,表示t(= tail)不是尾节点,则将入队节点设置成tail节点,更新失败了也没关系,因为失败了表示有其他线程成功更新了tail节点 if (p != t) casTail(t, newNode);//入队节点更新为尾节点,允许失败,因此t= tail并不总是尾节点 return true;//结束 } } //重新获取head节点:多线程操作时,轮询后p有可能等于q,此时,就需要对p重新赋值 //(多线程自引用的情况,只有offer()和poll()交替执行时会出现) else if (p == q) //因为并发下可能tail被改了,如果被改了,则使用新的t,否则跳转到head,从链表头重新轮询,因为从head开始所有的节点都可达 p = (t != (t = tail)) ? t : head;//运行到这里再继续自旋遍历 else /** * 寻找尾节点,同样,当t不等于p时,说明p在上面被重新赋值了,并且tail也被别的线程改了,则使用新的tail,否则循环检查p的下个节点 * (多offer()情况下会出现) * p=condition?result1:result2 * 满足result1的场景为 : * 获取尾节点tail的快照已经过时了(其他线程更新了新的尾节点tail),直接跳转到当前获得的最新尾节点的地方 * 满足result2的场景为: * 多线程同时操作offer(),执行p.casNext(null, newNode)CAS成功后,未更新尾节点(未执行casTail(t, newNode)方法:两种原因 1是未满足前置条件if判断 2是CAS更新失败),直接找next节点 */ p = (p != t && t != (t = tail)) ? t : q;//运行到这里再继续自旋遍历 } }
-
debug断点测试案例:
public static void main(String[] args) throws IndexOutOfBoundsException { ConcurrentLinkedQueue c = new ConcurrentLinkedQueue(); new Thread(()->{ int i; for(i=0;i<10;){ c.offer(i++); Object poll = c.poll();//注释或取消进行测试 System.out.println(Thread.currentThread().getName()+":"+poll); } }).start(); new Thread(()->{ int i; for(i=200;i<210;){ c.offer(i++); Object poll = c.poll();//注释或取消进行测试 System.out.println(Thread.currentThread().getName()+":"+poll); } }).start(); }
-
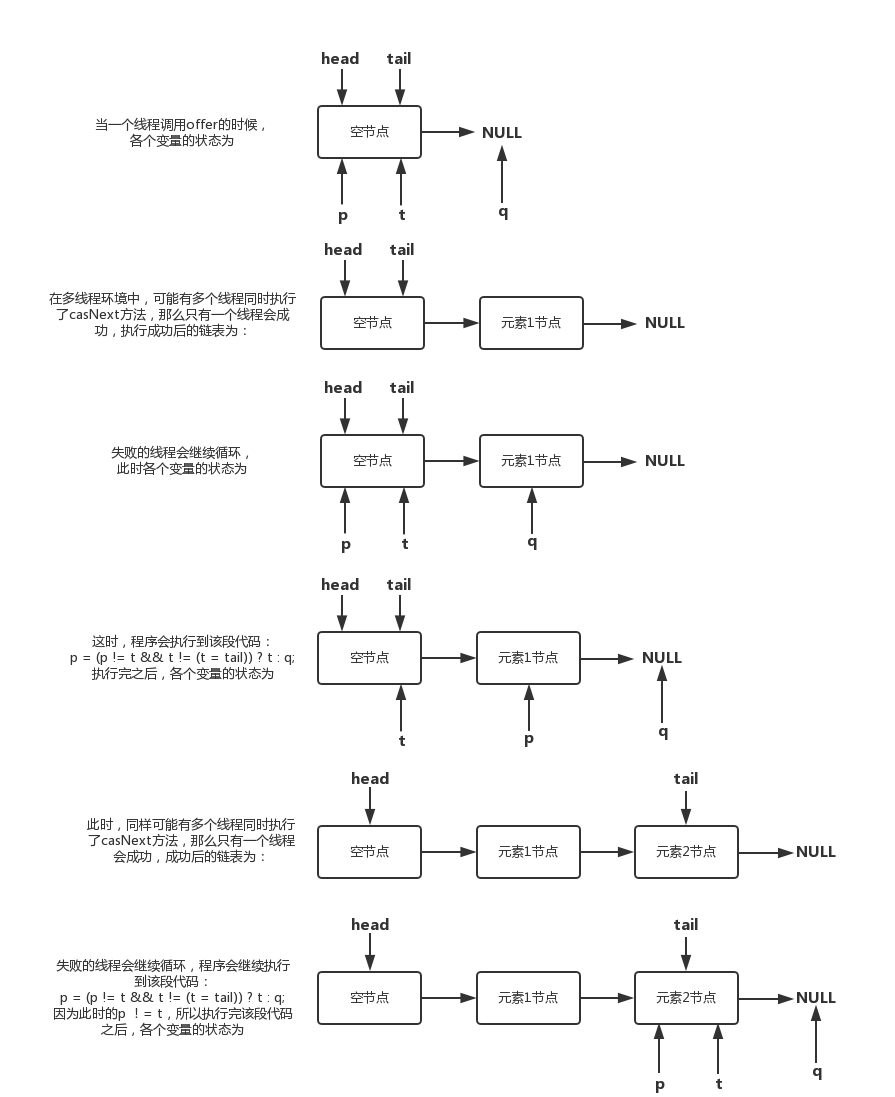
tail多线程的更新情况:通过p和t是否相等来判断
-
-
出队poll:

- 从上图可知,并不是每次出队时都更新head节点,当head节点里有元素时,直接弹出head节点里的元素,而不会更新head节点。只有当head节点里没有元素时,出队操作才会更新head节点。采用这种方式也是为了减少使用CAS更新head节点的消耗,从而提高出队效率。
-
源码解析:
public E poll() { restartFromHead: //自旋 for (;;) { //获得头节点 for (Node<E> h = head, p = h, q;;) { E item = p.item;//获得头节点元素 //如果头节点元素不为null并且cas删除头节点元素成功 if (item != null && p.casItem(item, null)) { //p被修改了 if (p != h) // hop two nodes at a time // 如果p 的next 属性不是null ,将 p 作为头节点,而 q 将会消失 updateHead(h, ((q = p.next) != null) ? q : p); return item; } //如果头节点的元素为空或头节点发生了变化,这说明头节点已经被另外一个线程修改了。 // 那么获取p节点的下一个节点,如果p节点的下一节点为null,则表明队列已经空了 // 如果 p(head) 的 next 节点 q 也是null,则表示没有数据了,返回null,则将 head 设置为null // 注意:updateHead 方法最后还会将原有的 head 作为自己 next 节点,方便offer 连接。 else if ((q = p.next) == null) { updateHead(h, p); return null; } //如果 p == q,说明别的线程取出了 head,并将 head 更新了。就需要重新开始获取head节点 else if (p == q) continue restartFromHead; // 如果下一个元素不为空,则将头节点的下一个节点设置成头节点 else p = q; } } } final void updateHead(Node<E> h, Node<E> p) { if (h != p && casHead(h, p)) // 将旧的头结点h的next域指向为h h.lazySetNext(h); }
-
入队和出队操作中,都有p == q的情况,在下面这种情况中:

- 在弹出一个节点之后,tail节点有一条指向自己的虚线,这是什么意思呢?在poll()方法中,移除元素之后,会调用updateHead方法,其中有h.lazySetNext(h),可以看到,在更新完head之后,会将旧的头结点h的next域指向为h,上图中所示的虚线也就表示这个节点的自引用。
-
如果这时,再有一个线程来添加元素,通过tail获取的next节点则仍然是它本身,这就出现了p == q的情况,出现该种情况之后,则会触发执行head的更新,将p节点重新指向为head,所有“活着”的节点(指未删除节点),都能从head通过遍历可达,这样就能通过head成功获取到尾节点,然后添加元素了。
-
获取首部元素peek:
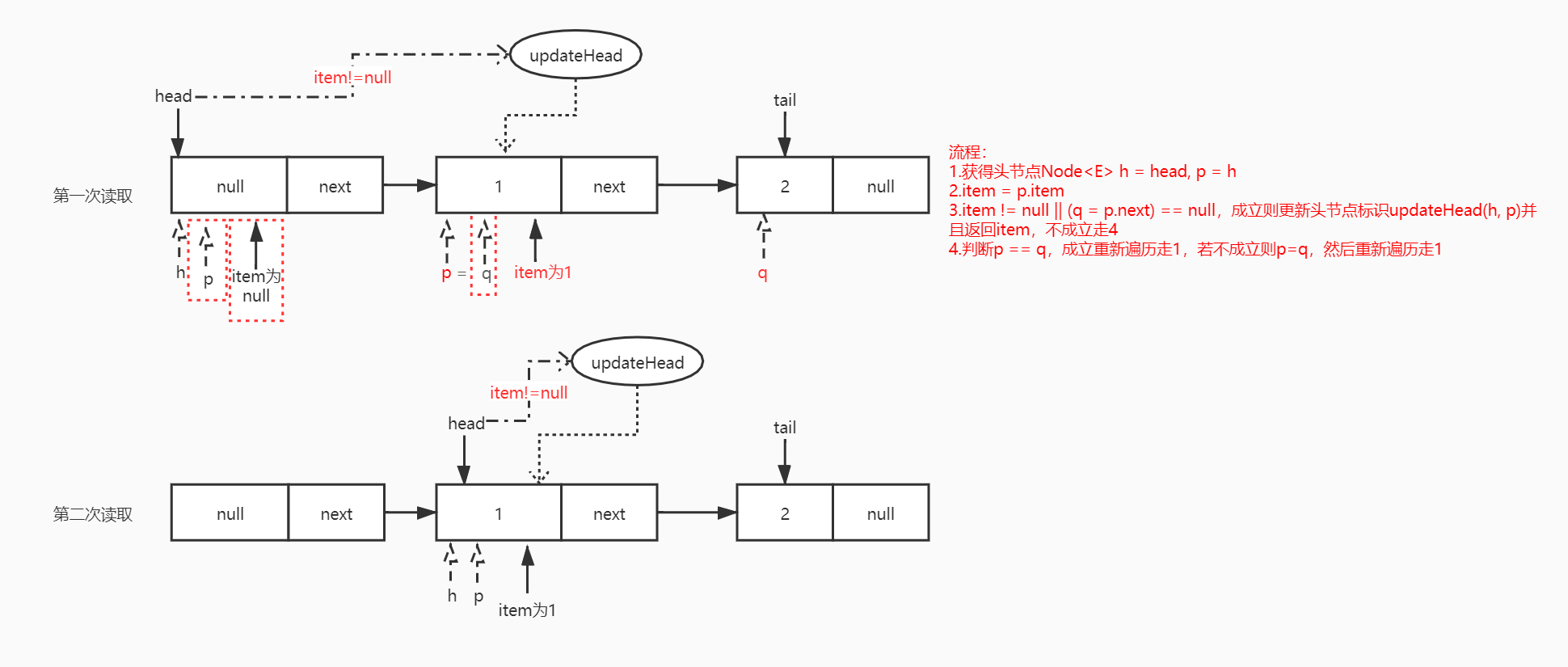
- 从图中可以看到,peek操作会改变head指向,执行peek()方法后head会指向第一个具有非空元素的节点。
- 源码解析:
// 获取链表的首部元素(只读取而不移除) public E peek() { restartFromHead: //自旋 for (;;) { for (Node<E> h = head, p = h, q;;) { //获得头节点元素 E item = p.item; //头节点元素不为空或头节点下一节点为空(表示链表只有一个节点) if (item != null || (q = p.next) == null) { updateHead(h, p);//更新头节点标识 return item; } /如果 p == q,说明别的线程取出了 head,并将 head 更新了。就需要重新开始获取head节点 else if (p == q) continue restartFromHead; // 如果下一个元素不为空,则将头节点的下一个节点设置成头节点 else p = q; } } }
-
判断队列是否为空isEmpty:
public boolean isEmpty() { return first() == null; } Node<E> first() { restartFromHead: for (;;) { for (Node<E> h = head, p = h, q;;) { //头节点是否有元素 boolean hasItem = (p.item != null); //头节点有元素或当前链表只有一个节点 if (hasItem || (q = p.next) == null) { updateHead(h, p); return hasItem ? p : null;//头节点有值返回节点,否则返回null } else if (p == q) continue restartFromHead; else p = q; } } }
-
获取个数size:在并发环境中,其结果可能不精确,因为整个过程都没有加锁,所以从调用size方法到返回结果期间有可能增删元素,导致统计的元素个数不精确。【在队列元素很多的时候,size()方法十分消耗性能和时间,只是单纯的判断队列为空使用isEmpty()即可!!!】
public int size() { int count = 0; // first()获取第一个具有非空元素的节点,若不存在,返回null // succ(p)方法获取p的后继节点,若p == p的后继节点,则返回head for (Node<E> p = first(); p != null; p = succ(p)) //节点有元素数量+1 if (p.item != null) if (++count == Integer.MAX_VALUE) break; return count; } //取下一节点 final Node<E> succ(Node<E> p) { Node<E> next = p.next; //若p == p的后继节点(自引用情况下会出现),则返回head return (p == next) ? head : next; }
-
探讨:为何 ConcurrentLinkedQueue 中需要遍历链表来获取 size 而不适用一个原子变量呢?
-
这是因为使用原子变量保存队列元素个数需要保证入队出队操作和操作原子变量是原子操作,而ConcurrentLinkedQueue 是使用 CAS 无锁算法的,所以无法做到这个。
-
-
-
判断元素是否包含contains:该方法和size方法类似,有可能返回错误结果,比如调用该方法时,元素还在队列里面,但是遍历过程中,该元素被删除了,那么就会返回false。
public boolean contains(Object o) { if (o == null) return false; for (Node<E> p = first(); p != null; p = succ(p)) { E item = p.item; // 若找到匹配节点,则返回true if (item != null && o.equals(item)) return true; } return false; }
-
删除元素remove:
public boolean remove(Object o) { //删除的元素不能为null, if (o != null) { Node<E> next, pred = null; //遍历,开始获得头节点, for (Node<E> p = first(); p != null; pred = p, p = next) { boolean removed = false;//删除的标识 E item = p.item;//节点元素 if (item != null) { //节点的元素不等于要删除的元素,获取下一节点进行遍历循环操作 if (!o.equals(item)) { next = succ(p);//将当前遍历的节点移到下一节点 continue; } //节点元素等于删除元素,CAS将节点元素置为null removed = p.casItem(item, null); } next = succ(p);//获取删除节点的下一节点, //有前节点和后置节点 if (pred != null && next != null) // unlink pred.casNext(p, next);//删除当前节点,即当前节点移除出队列 if (removed)//元素删除了返回true return true; } } return false; }
三.总结
- 使用 CAS 原子指令来处理对数据的并发访问,这是非阻塞算法得以实现的基础。
- head/tail 并非总是指向队列的头 / 尾节点,也就是说允许队列处于不一致状态。 这个特性把入队 / 出队时,原本需要一起原子化执行的两个步骤分离开来,从而缩小了入队 / 出队时需要原子化更新值的范围到唯一变量。这是非阻塞算法得以实现的关键。
- 由于队列有时会处于不一致状态。为此,ConcurrentLinkedQueue 使用三个不变式来维护非阻塞算法的正确性。
- 以批处理方式来更新 head/tail,从整体上减少入队 / 出队操作的开销。
- 为了有利于垃圾收集,队列使用特有的 head 更新机制;为了确保从已删除节点向后遍历,可到达所有的非删除节点,队列使用了特有的向后推进策略。
四.参考
- https://blog.csdn.net/qq_38293564/article/details/80798310
- https://www.ibm.com/developerworks/cn/java/j-lo-concurrent/index.html
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【码猿手】。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号