











MySQL笔记(4)-- 索引优化
- 索引失效情况:
- 最佳左前缀法则:如果索引了多列,要遵循最左前缀法则,指的是查询从索引的最左前列开始并且不跳过索引中的列;【覆盖索引有a,b,c,条件中使用了b或bc都导致该索引失效;如果条件使用了ac,导致部分索引生效,只使用了a】【索引开头第一个不能去掉,中间部分不能断】
- 不在索引列上做任何操作(计算、函数、(自动或手动)类型转换),会导致索引失效而进行全表扫描;【where条件的字段不做任何操作,否则导致索引失效】
- 存储引擎不能使用索引中范围条件右边的列;【覆盖索引有a,b,c,a是常量,b是范围,导致索引用到了a,b,后面的c失效】
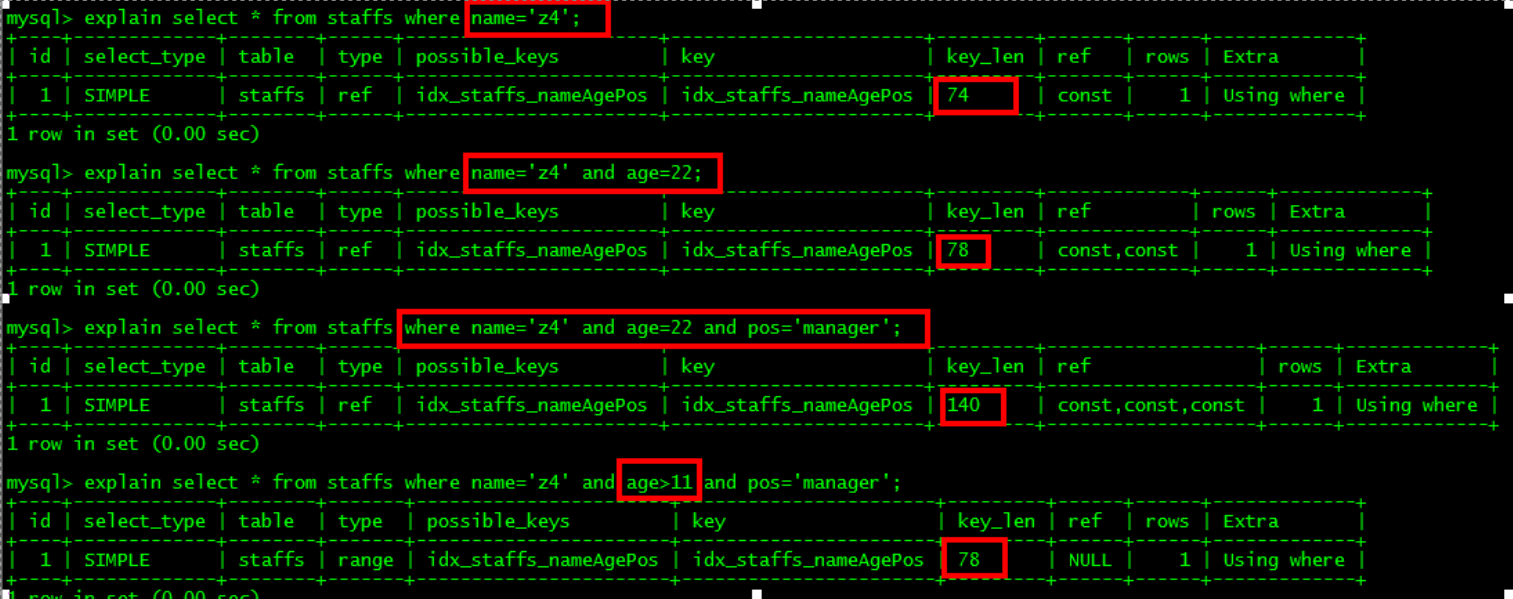
- 尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select *;


- MySQL在使用不等于(!=或<>)的时候无法使用索引会导致全表扫描;
- is null和is not null无法使用索引;
- like以通配符开头('%abc...'或'%abc'),MySQL索引失效导致全表扫描;【'abc...%'不会导致索引失效】【解决方法:使用覆盖索引来解决,即对select的字段创建索引】【id是主键,默认创建索引】


下面的SQL索引失效【使用*或多了字段】:

- 字符串不加单引号导致索引失效;【例如name是varchar类型,条件where name=1做了隐形类型转换,还会导致索引失效,降低MySQL性能】
- 少用or,用它来连接会导致索引失效;
- 总结:
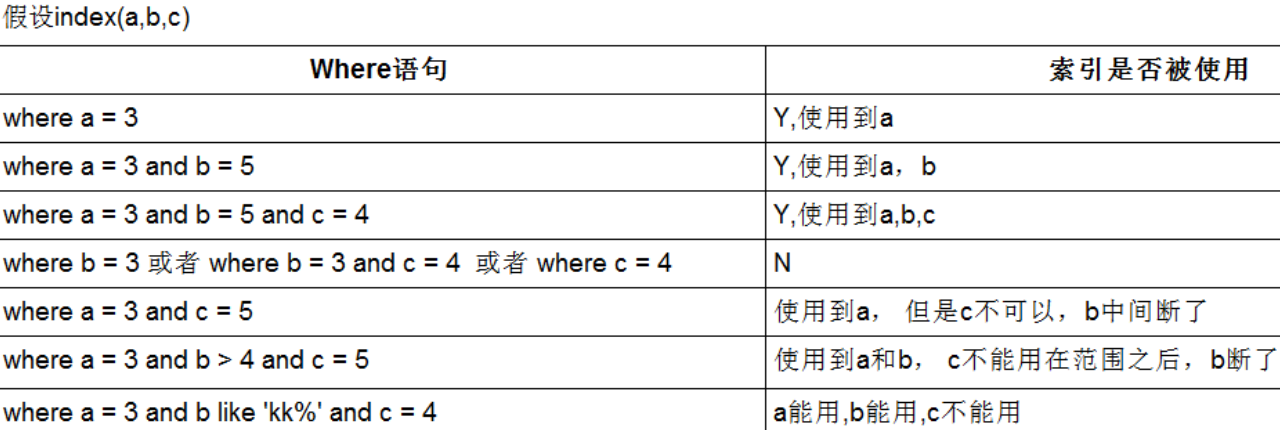
- 查询优化:
-
小表驱动大表:小的数据集驱动大的数据集
1.当B表的数据集必须小于A表的数据集时,用in优于exists select * from A where id in (select id from B) 等价 for select id from B for select *from A where A.id=B.id 2.当A表的数据集小于B表的数据集时,用exists优于in select *from A where exists (select 1 from B where B.id=A.id); 等价 for select *from A for select *from B where B.id=A.id
-
-
-
- exists:select ...from table where exists(subquery) 将主查询的数据,放到子查询中做条件判断,根据验证结果true或false来决定主查询的数据结果是否可以保留;
- exists(subquery)只返回true或false,因此子查询中的select *可以是select 1或其他,因为在实际执行时会忽略select清单;
- exists子查询可以用条件表达式、其他子查询或join;
- exists:select ...from table where exists(subquery) 将主查询的数据,放到子查询中做条件判断,根据验证结果true或false来决定主查询的数据结果是否可以保留;
- order by关键字优化:文件排序、扫描有序索引排序两种方式;
建立索引:key abc(a,b,c) order by使用索引最左前缀原则:(有序索引排序,using index) --order by a --order by a,b --order by a,b,c --order by a desc,b desc,c desc(升降序一致) 如果where使用索引的最左前缀定义为常量,则使用索引且是有序索引排序(using index): --where a=const order by b,c --where a=const and b=const order by c --where a=const and b>const order by b,c 产生文件排序(using filesort): --order by b(非最左前缀) --order by b,a(顺序颠倒) --order by a asc,b desc,c desc (排序不一致) --where d=const order by b,c (a丢失) --where a=const order by c(b丢失) --where a=const order by a,d(d不是索引的一部分) --where a in(..) order by b,c(范围查询)
- group by关键字优化:group by实质是先排序后进行分组,遵照索引的最左前缀原则;当无法使用索引列时,增大max_length_for_sort_data参数的设置和增大sort_buffer_size参数的设置;where高于having,能写在where限定的条件就不要去having限定;
-
- 慢查询日志的配置:
在my.cnf文件中[mysqld]增加或修改参数: slow_query_log=1 slow_query_log_file=/文件存储路径/fileName.log【若没有指定,系统默认给一个指定的文件host_name-slow.log】
查看达到写入慢查询日志的阀值:SHOW VARIABLES LIKE 'long_query_time%';【默认情况下为10秒,即查询时间大于10秒的sql会记录到日志中】
设置阀值:set global long_query_time=数值;【设置结束后需要新开一个会话或重新连接才看见修改信息,或使用show global variables like 'long_query_time'查看】
查看当前系统的慢查询SQL总条数:show global status like '%Slow_queries%';
作者:huangrenhui
欢迎任何形式的转载,但请务必注明出处。
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【码猿手】。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【码猿手】。
限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号