寒假作业(2/2)
寒假作业(2/2)
1.作业信息
| 这个作业属于哪个课程 | 2021春软件工程实践|W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 1.重读《构建之法并提问 2.附加题:软件工程发展的过程中有什么你觉得有趣的冷知识和故事? 3.WordCount编程作业 4.根据作业要求撰写第一个博客 5.在deadline之前提交博客 |
| 其他参考文献 | CSDN、简书博客 |
2.重读《构建之法》并提问
2.1 如何有效结对编程?
观看了现代软件工程讲义3结对编程和两人合作,我认识到了结对编程给结对双方带来的开发的互补,也能够剩下以后修改,测试的时间,但是稳重也谈到不能不分情况的强迫每个人物都用结对编程的方式,或者固执遵守一些教条,我的问题是,应当如何有效的结对编程,才能在兼顾效率的同时,避免进入匆忙编程的误区。经过资料学习性,我认识到,等待时间较长的工作无需结对,并且有效的结对编程是一个相互学习、相互磨合的开发模式。我希望在接下来的结对编程任务中,顶住有可能出现的结对编程不比单独开发效率更高的压力,在学习和实践中认识一下结对编程。
2.2 Scrum/Sprint任务分配?
观看了现代软件工程讲义4 Scrum/Sprint,我学习了敏捷开发的开发过程,文中谈到了在这种模式下需要决定当前的冲刺需要解决的事情,任务被进一步的细化,冲刺订单上的任务不会被分派,而是由团队成员签名认领他们喜爱的任务。有了这种模式下的任务如何制定,任务具体又是如何分配的。经过资料查询,我了解到scump模式下的任务细分遵守子任务必须小于5小时,是可检视性的,子任务间相互独立,区分轻重缓急的基本原则。自己挑选任务的自我管理模式有利于适应性而非预见性的提高。但是我还存在的问题是,无人认领,难度较高的任务应该如何分配,这种提高适应性降低非预见性的模式风险是否会频发导致效率的降低,看似细化的工作却让我感觉到了任务之间的联系性下降了。
2.3 调研用户的选择?
观看了现代软件工程讲义6用户调研,我看到一个问题引发了我的好奇,题目是
你要写一个中学生学习英语的软件,你找谁去做用户调研?
中学生 - 最终用户
家长 - 他们是要掏钱的人,他们不会每天都用软件,有些人都不太会英语,但是他们也有需求
学校老师 - 他们是有巨大影响力的人,他们说不定立下一道规矩,我们班级就用某某软件!
不得不说,这是一个关于调研用户选择的问题,网上资料谈到通过用户画像,一方面能找出这类用户进行调研,同时对这类用户特征特征分析。
我认为,中学生,家长,老师确实是经过用户特征,和初步用户画像筛选出来的,同时在做用户调研需对这三种用户按照一定权重来接受他们的需求,根据工程的进度对主要用户的需求先实现。个人认为中学生才是本款软件的最终使用用户,最为重要。
2.4 问卷问题的设计矛盾?
观看了现代软件工程讲义6用户调研,我在用户调查问卷的设计上也存在着疑问,全开放式问题,难以整理量化,二项选择题又无法深入了解客户的需求。我认为一份用户调查问卷的设计关系到调查的有效性和用户的参与度。简单的问卷收集不到全面的结果,复杂的问卷可能连问卷都收集不到,或是草草敷衍。是否还有更高效的问卷设计呢?特别在问题的表达上更好让用户理解接受?
2.5 源代码管理的同时访问修改?
观看了现代软件工程讲义的源代码管理部分,我发现团队合作中源代码的管理方式不易控制,特别是在处理文件的锁定问题上。在有限的时间里,想必很容易发生多个同学修改到同个被签出的文件。文中谈到签出的文件可以被加锁,让别人无法签出,或者所有人自由签出文件。我倾向有所有人自由签出文件,但是在提交的时候还需要附带修改报告,让即将提交的人对照报告和已提交的新代码对手上的程序进行修改,但貌似还是会出现相同时间提交,以及在提交之前频繁修改的情况,加大了工作量。
3.附加题
冯·诺依曼出处:===============
一个学生在走廊上碰上诺依曼,顺便就问了个问题:
S: 呃,打扰一下,冯·诺依曼教授,您能帮我解答一下这个分析问题吗?
N: 好吧小子,最好快点,我很忙。
S: 我不太懂这个积分...
N: 我们来看看 (短暂的思考后) 好了小子,结果是2π/5。
S: 答案我都知道,老师,但我不懂怎么推导出来。
N: 好吧,我再看看 (又一次思考后)答案是2π/5。
S: (沮丧的说)诶,老师,我知道答案,就是不明白该怎么推导。
N: 你还想怎样嘛小子,我都用了两种方法做了!-----------------------
个人理解,我认为这段有趣的故事非常地符合学生时代的学习现状,学生在遇到困难问题的时候,往往会因为ddl压迫的紧迫性,而片面的追求快速的答案,而这则轶事的学生还是比较好学的,他向老师询问答案,但两次的结果,都是“答案”。我认为,现实中编码的我们复制代码的过程和他有点类似,往往得出了正确的结果,却不知从何理出答案的逻辑,这大概就是学习的死穴吧,还是得多花时间,好好掌握吧。
4.WordCount编程作业
4.1 给出Github项目地址。
4.2 PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 15 |
| ·Estimate | 估计这个任务需要多少时间 | 15 | 15 |
| Development | 开发 | 510 | 695 |
| ·Analysis | ·需求分析(包括学习新技术) | 30 | 30 |
| ·Design Spec | ·生成设计文档 | 20 | 30 |
| ·Design Review | ·设计复审 | 10 | 10 |
| ·Coding Standard | ·代码规范(为目前的开发指定合适的规范) | 30 | 40 |
| ·Design | ·具体设计 | 30 | 30 |
| ·Coding | ·具体编码 | 300 | 480 |
| ·Code Review | ·代码复审 | 30 | 30 |
| ·Test | ·测试(自我测试,修改代码,提交修改) | 60 | 45 |
| Reporting | 报告 | 130 | 130 |
| ·Test Repor | ·测试报告 | 40 | 30 |
| ·Size Measurement | ·计算工作量 | 60 | 60 |
| ·Postmortem & Process Improvement Plan | ·事后总结,并提出过程改进计划 | 30 | 30 |
| 合计 | 655 | 840 |
4.3 解题思路 & 计算模块接口的设计与实现过程
阅读完题目之后,我大致列出了题目要求完成的功能。
- 一个读取文件路径的接口。
- 一个实现统计字符数的接口。countCharacters(File file)
- 一个统计单词总数的接口。countTotalWords(File inputFile)
- 一个统计有效行数的接口。countValidLines(File inputFile)
- 一个统计单词出现次数的接口。countWords(File inputFile)
- 和一个将上述计算结果输出文件的接口。
解题思路
- 设计一个Lib方法类,在该类中提供静态方法
(1)countCharacters(File file),
(2)countTotalWords(File inputFile),
(3) countValidLines(File inputFile),
(4) countWords(File inputFile)对四个主要功能的接口进行封装。
- 同时将1和6的功能结合形成outputFile(File inputFile, File outputFile)用于结果文件的产生。
- 统计字符数功能设计:使用BufferedInputStream接收传入的文件路径,通过bufferedInputStream.read()是否等于-1来判断文件是否读尽。
设计思路:查阅网上博客得知,BufferedInputStream缓冲输入字节流的处理效率高,速度快。通过逐个判断字节并累加的方式统计出识别到的ascii码字符。
说明:
- 只需要统计Ascii码,汉字不需考虑
- 空格,水平制表符,换行符,均算字符
补充:之前有考虑通过readline方式读取文本单行的字符串,通过累加字符串长度的方式得出文件字符数,但是经过测试后发现会缺少统计换行符的数量,便改用了现在的模式。
关键代码部分:
BufferedInputStream bufferedInputStream
= new BufferedInputStream(new FileInputStream(inputFile));
while((bufferedInputStream.read()) != -1){
characters ++;
}
4.统计单词总数设计:以行为单位读入文件,将行读入存在一个String类里,使用正则表达式[a-zA-Z]{4}([a-zA-Z0-9])*,结合Pattern将正则表达式封装到Matcher里,通过调用matcher.find()方法,来查找匹配的合法单词。
说明:
- 英文字母: A-Z,a-z
- 字母数字符号:A-Z, a-z,0-9
- 分割符:空格,非字母数字符号
- 例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
补充:之前采用的是单个字符读入,知道读到一个分割符停止,拼装成一个字符串的放法,然后再将拼装好的string放入isValidWord(自己写的一个判断合法单词的方法),这样的方法笨拙,且使用了大量的char内存。通过网上的学习,我认识到了正则表达式结合Pattern,Matcher的办法,瞬间感觉减少了代码量。
关于正则表达式的含义,代表着前四个是有英文字母组成,后接字母或数字字符。
关键代码部分:
BufferedReader bufferedReader
= new BufferedReader(new FileReader(inputFile));
String line = "";
while((line = bufferedReader.readLine()) != null){
Pattern pattern = Pattern.compile("[a-zA-Z]{4}([a-zA-Z0-9])*");
Matcher matcher = pattern.matcher(line);
while(matcher.find()){
total++;
}
}
5.统计有效行数设计:使用 BufferedReader以行的形式读入文件信息,并将string与“”进行比较,如果一致,则代表存在为空字符行,不予记录。
说明:
- 任何包含非空白字符的行,都需要统计。
补充:代码测试阶段发现,纯空白字符行因为存在空白的字符也会被记录到结果中,使用string.trim()方法能够将空白符去掉后再进行比较。
关键代码部分:
BufferedReader bufferedReader
= new BufferedReader(new FileReader(inputFile));
while((line = bufferedReader.readLine()) != null){
if(!line.trim().equals(""))
lines++;
}
bufferedReader.close();
6.统计单词出现次数设计:延续之前统计合法单词总数算法中的判断合法单词的思想,将合法的单词通过matcher.group()方法提取出来,并进行小写转换toLowerCase(),这样就可以以单词作为key索引,将统计单词的工作记录在一张TreeMap上,这个思想我是参考了一篇博客。
将收集结束的Map通过自己编写sortMap函数进行排序,其中,我重写了Collections接口中的sort方法,判断依据为,先判断key的value值,相同value值的key,判断它们key的字典优先级(CompareTo方法),sortMap函数返回一个List< Map.Entry< String, Integer>>有序的List队列,用于10个高频单词的输出。
说明:
- 频率相同的单词,优先输出字典序靠前的单词。
- 输出的单词统一为小写格式。
关键代码部分:
将检索到的合法单词在map中进行查找,没有的话,设置num为1,有则num+1.
while(matcher.find()) {
word = matcher.group();
if(map.containsKey(word)) {
num = map.get(word);
num += 1;
}else {
num = 1;
}
map.put(word, num);
map排序时的比较算法,比较方法是先判断key的value值,相同value值的key,判断它们key的字典优先级(CompareTo方法)
Collections.sort(list, new Comparator<>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
int flag = o2.getValue() - o1.getValue();
if(flag == 0){
flag = (o1.getKey()).compareTo(o2.getKey());
}
return flag;
}
});
4.4 代码规范
4.5 计算模块接口部分的性能改进
性能测试
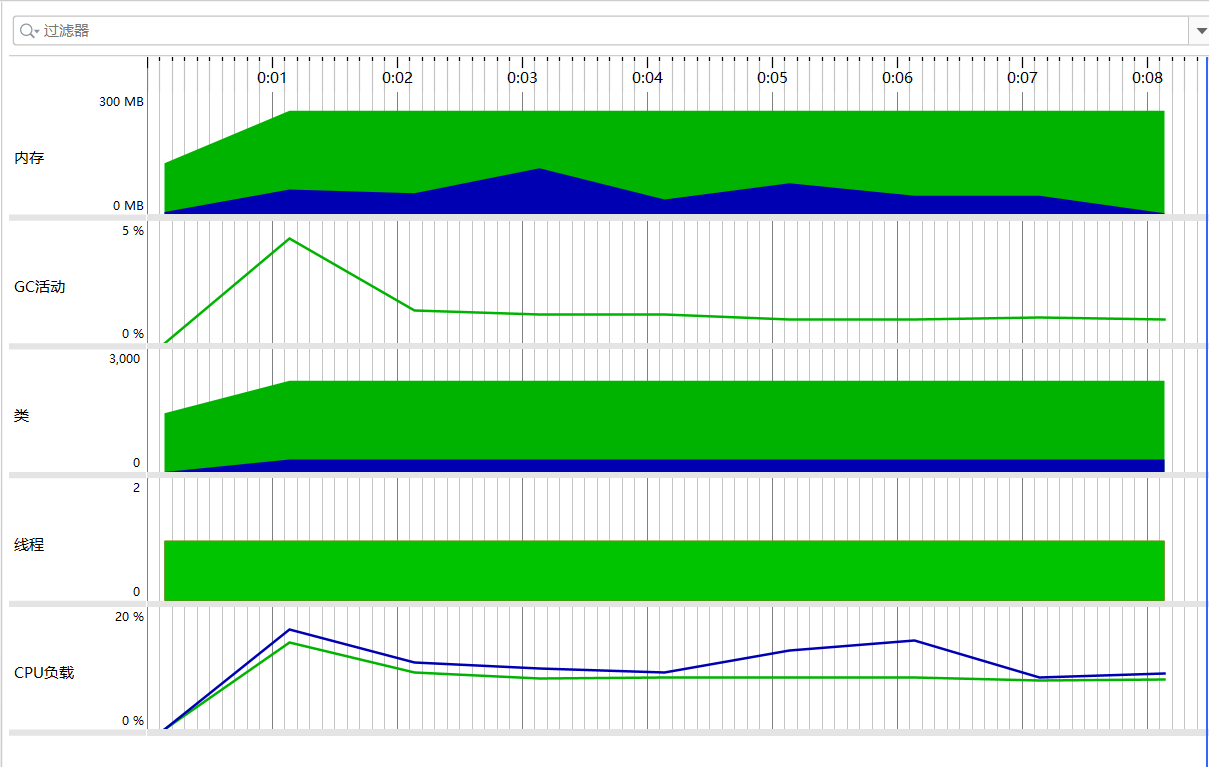
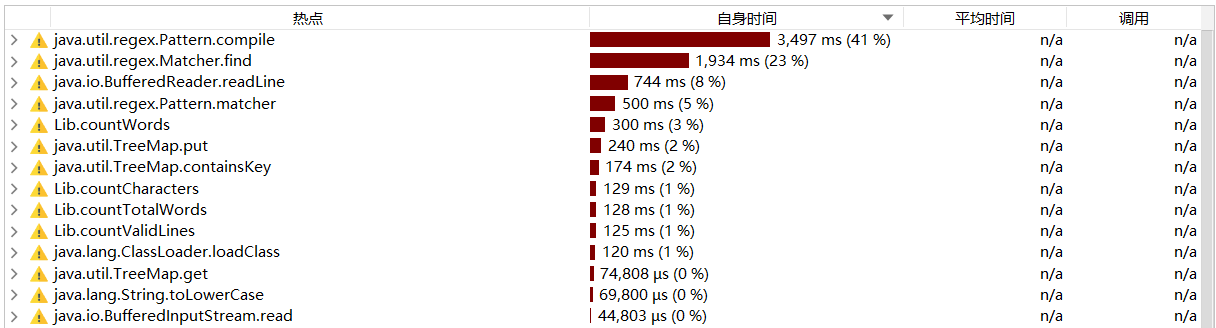
改进方案:
1.使用BufferedInputStream接收传入countCharacters的文件路径,因为一次读入n个字节到输入换成区,接着经中转站写入到输出缓冲区,输入缓冲区为空时再次从硬盘读入批量数据,更加高效。
2.使用正则表达式替换原先逐个字符判断的方法,这样判断合法单词代码更加简洁,cpu工作效率提高。
3.使用Map结合正则表达式统计单词词频,以单词本身为索引,再通过自定义sort方法进行排序。
4.6 计算模块部分单元测试展示
测试选择:使用idea的Junit的Test方法进行测试。其中,测试文件包括了空白文件,合法单词文件,非合法单词文件,大数据文件(文件通过java程序生成2^20次方个合法单词),ascii码字符文件,全空白符文件等。
下面展示大数据文件时单元测试代码
@Test
void outputFile() {
Lib.outputFile(new File("src\\input.txt"), new File("output.txt"));
}
@Test
void countCharacters() {
assertEquals(62914560, Lib.countCharacters(new File("src\\input.txt")));
}
@Test
void countTotalWords() {
assertEquals(10485760, Lib.countTotalWords(new File("src\\input.txt")));
}
@Test
void countValidLines() {
assertEquals(5242880, Lib.countValidLines(new File("src\\input.txt")));
}
@Test
void countWords() {
Lib.countWords(new File("src\\input.txt"));
}
得到的结果是
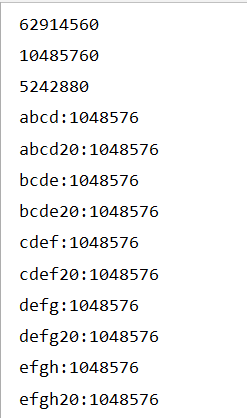
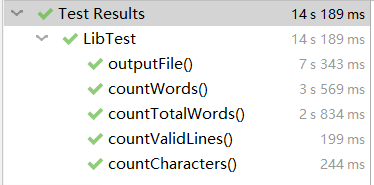
经过测试,代码的覆盖率达到了80%以上,没有包括的部分是程序IOException报异常的代码语句。
如何优化代码覆盖率?
我认为,优化代码覆盖率,是根据代码覆盖率,对代码主要流程的检查,需要设计适合的符合代码中大部分功能的测试用例,同时也需要通过丰富的用例反作用于代码的改进。
但是,覆盖率的计算,还包括着未运行的异常代码段和空行,这部分是无法避免的。至于优化覆盖的成果,不单单是覆盖率上升的体现,目的也是为了发现程序中冗余的代码和漏洞,

4.7 计算模块部分异常处理说明。
- 在文件的开头检测了输入文件路径的个数,确保了路径传入的正确性。
其余的异常处理只有简单IOException,在代码中Catch并打印路径。

4.8 心路历程与收获
本次的寒假作业(2/2)让我受益匪浅。学会了使用git和github Desktop对源程序的代码版本进行更新和保存,这是我之前从没尝试过的,我也体会到了保留历史版本库的好处;同时阅读《构建之法》,让我学习到了敏捷的团队工作方式,也收获学习到了结对编程的合作方式,同时也发现了用户需求在开发过程中的难处,除了不断改变的需求,还有就是调研用户的选择以及问题的设计,我想这些知识和概念在不就之后也会在我们身上实践;然后本次还学习了单元测试的方法,可以通过Jprofiler监测程序运行过程中的内存时间开销。不过,我认为自己在单元测试和性能优化上还需要加深,学会更好的分析监测到的数据,另外,psp表格的计划和实际偏差还比较大,需要再继续磨合。希望下一次的实践还可以有更多的收获!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号