
redis
1.redis的应用场景
- 1.5大value类型:
![]()
- 2.基本上就是缓存。

2.redis是单线程还是多线程?
- 1.无论什么版本工作线程就是一个。
- 2.6.x版本出现了IO多线程。
- 3.单线程,满足redis的串行原子性,只不过IO多线程后,把输入和输出放到更多的线程里面去并行,好处:1.执行时间缩短,更快。2.更好的压榨系统资源。
![]()
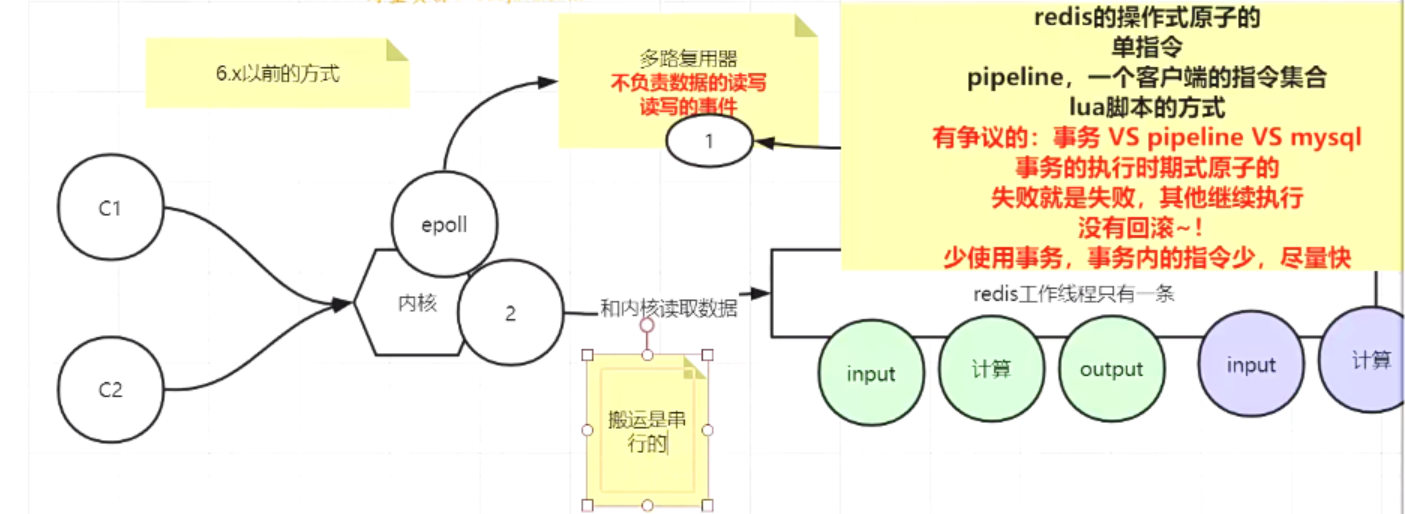
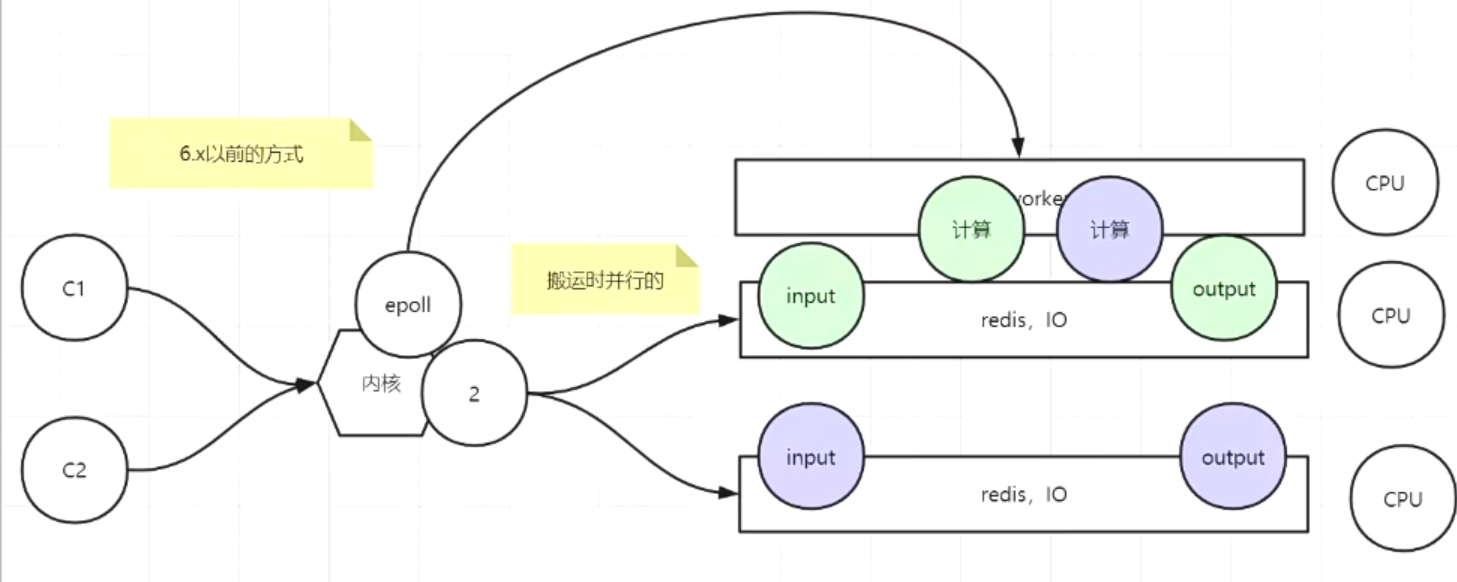
3.redis存在线程安全的问题吗?为什么?
redis可以保证内部串行,外界使用时要自行保障顺序。
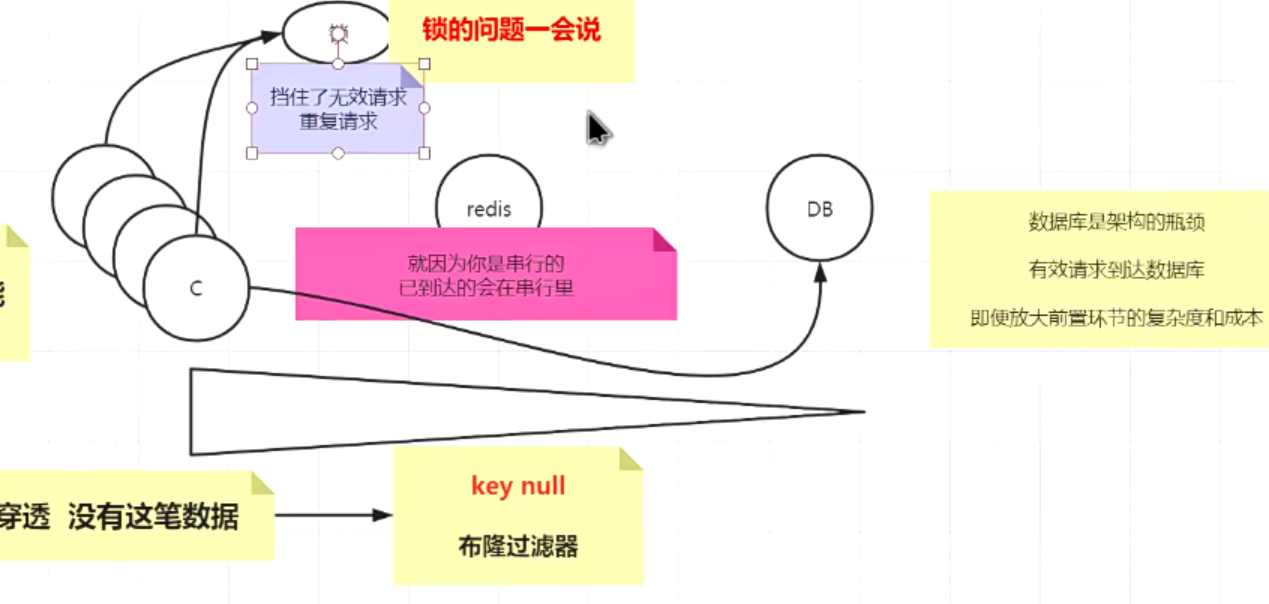
4.遇到缓存穿透?
- 穿透即在redis没有这个数据,请求直接到数据库,解决方案:1,将缓存里没有,数据库也没有的数据,请求后将数据以key为null的方式加到redis缓存里。2.使用布隆过滤器。
- 当请求同一个key并大量很大时,因为redis时串行的,大量请求同时到达redis,请求会在redis里排队等待执行,第一个请求查redis没找到,请求会到达数据库,并将null值设置到redis,redis里此时还有剩下的大量串行请求也会按顺序请求到数据库上,造成数据库压力增大。解决方案:加锁,当请求取redis没有取到的时候再去抢锁,抢到锁的请求再去访问数据库,并设值到redis。
5.缓存击穿?
- 热点key过期(或者从来没有被缓存的key),在大量并发请求下,某个key的过期造成大量请求落到数据库上。
解决方案,同上,加锁,请求redis没有的情况下,所有请求取竞争同一把锁,抢到锁的请求再去查询数据库, 并更新redis,没有抢到的就让线程sleep(非阻塞状态,不会占用cpu调度)。
![]()

6.如何避免缓存雪崩?
缓存雪崩:大量的key同时过期,到时大量的请求落到数据库上。
解决方案:1.key的随机过期。2.加锁同上,只不过不同的key要用不同的锁,锁的隔离。AKF的分治。
7.缓存是如何回收的?
1.后台在轮询的时候,分段分批的删除那些过期key。(轮询小号资源,处理变慢)
2.请求的时候判断已经过期的key,删除。(未被访问到的过期key的内存无法及时得到释放)
8.缓存是如何淘汰的?
在内存空间不足的情况下:

9.如何进行缓存预热?
1.提前将热key塞入redis,(你知道哪些是热数据吗?)
2.开发逻辑上规避差集(没缓存的数据),会造成缓存穿透,击穿,雪崩。
10.数据库与缓存不一致如何解决?
11.redis的持久化机制是什么?
- 1.RDB持久化方式:redis会fork出一个子进程,以快照的方式将将所有的键值对在某一个时间点写入一个临时文件,持久化结束后,将临时文件替换为上次持久化的文件,达到数据恢复。
优点:
1.只有一个dump.rdb文件,方便持久化。
2.性能最大化,fork一个子进程来完成写操作,主进程可以继续处理命令,所以是IO最大化,保证redis的高性能。
缺点:
1.数据安全性低,因为是间隔一段时间进行持久化,如果在此期间redis出现故障,就会发生是数据丢失。
- 2.AOF的持久化机制:
将所有的命令行记录保存为aof文件。
优点:
1.数据安全,aof持久化可以配置appendfsync属性,为always,每进行一次命令操作记录就记录到aof文件中一次。
2.aof的rewrite机制,当文件过大时会对命令进行重写,aof没被rewrite之前可以删除其中的某些命令(比如说误操作的fiushall)
缺点:
1.aof文件比rdb文件大,且恢复速度慢。
2.数据集大的时候比rdb启动效率慢。
12.Redis 常见性能问题和解决方案:
1、Master 最好不要写内存快照,如果 Master 写内存快照,save 命令调度 rdbSave
函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性
暂停服务
2、如果数据比较重要,某个 Slave 开启 AOF 备份数据,策略设置为每秒同步一
3、为了主从复制的速度和连接的稳定性,Master 和 Slave 最好在同一个局域网
4、尽量避免在压力很大的主库上增加从
5、主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1
<- Slave2 <- Slave3…这样的结 构方便解决单点故障问题,实现 Slave 对 Master
的替换。如果 Master 挂了,可以立刻启用 Slave1 做 Master,其他不变。
13.redis的删除策略?
1.定时删除:给每个键设置一个过期时间,过期时间来临时删除对应的建。
2.惰性删除:当访问到这个键的时候再去判断是否过期,过期就删除这个键,没过期就返回该键,问题:会让那些长时间没被访问过的键一直存在内存中,造成内存的浪费。
3.定期删除,每隔一段时间去扫描所有的键,将那些过期的键删除掉。
14.redis的淘汰策略?
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最
少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过
期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意
选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
注意这里的6种机制,volatile和allkeys规定了是对已设置过期时间的数据集淘汰数据还是从全部数据集淘汰数据,后面的lru、ttl以及random是三种不同的淘汰策略,再加上一种no-enviction永不回收的策略。
使用策略规则:
1、如果数据呈现幂律分布,也就是一部分数据访问频率高,一部分数据访问频率低,则使用allkeys-lru
2、如果数据呈现平等分布,也就是所有的数据访问频率都相同,则使用allkeys-random
15.redis为什么把所有数据放到内存中?
redis为了达到最快的读写速度,将数据都读到内存中,并通过异步的方式将数据写入磁盘,如果不把数据放到内存中,磁盘的IO会严重影响redis的性能。如果设置了最大使用的内存,则数据已有记录数达到内存限值后不
能继续插入新值。
16,redis的同步机制?
- 1.主从复制
redis最基本的数据同步方式,将主节点的数据复制到从节点,使得主节点和从节点的数据保持一致。流程主要如下:
1.从节点连接主节点,发送sync命令请求同步数据。
2.主节点收到sync命令后,开始执行bgsave命令,将数据持久化到磁盘,将生成的RDB文件发送给从节点。
3.从节点接收到RDB文件后,通过LOAD命令加载到内存中,从而与主节点的数据保持一致。
4.从节点开始接受主节点的增量数据,将其应用到自己的数据集中,保持与主节点的同步。
需要注意的是,主从同步是异步的,主从节点的同步不是实时同步的,如果主节点发生故障,从节点可能因为数据延迟出现数据丢失的情况。
- 2。哨兵模式
除了主从复制外,Redis还提供了哨兵模式作为高可用性解决方案。哨兵模式可以自动检测主节点的状态,当主节点发生故障时,会自动将一个从节点切换为主节点。切换过程中,从节点会先将自己的数据与主节点保持一致,然后才能成为新的主节点。因此,在哨兵模式下,数据同步的过程与主从复制类似,但是其实现方式更加自动化。
17.redis集群?
1.Redis Sentinal集群着眼于高可用,在master宕机时会将slave提升为master,继续提供服务。
2.Redis Cluster,着眼于扩展性,单个redis内存不足时,使用cluster可以进行分片存储。
18.什么情况下会导致整个Redis集群方案不可用?
A,B,C三个节点的集群,当B节点失败了,并且在没有复制模型的情况下,那么整个集群会因为缺少5501-11000这个范围的槽而不可用。
redis集群的最大节点个数是16384。
19.怎么理解Redis的事务?
1.事务是一个单独的隔离操作,事务中的命令会被序列化,串行化的执行。
2.事务是一个原子操作,事务中的命令要么全部执行,要么全部都不执行。
20.Redis事务相关的命令?
MULTI、EXEC、DISCARD、WATCH
21.redis过期时间和永久有效怎么设置?
Expire和presist
22.redis如何做内存优化
尽量使用散列表,散列表存储的内存非常小,所以应尽可能将你的数据模型抽象到一个散列表里。如你的web系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的key,而是应该把这个用户的所有信息存储到一张散列表里面.
23.哪些办法可以降低Redis的内存使用情况?
尽量使用hash,set,list等集合数据类型,因为很多情况下很多小的key-value可以用更紧凑的方式存放到一起。
24.假如redis里有一亿个key,10w可key是以某种前缀开头的,如何找出这些key?
使用keys指令可以筛选出指定模式的key列表。
- 如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
redis是单线程的,keys指令会导致线程阻塞一段时间,导致服务暂时不可用,这个时候可以使用scan指令,无阻塞的提出指定模式的key列表,但是可能会有重复的数据,在客户端去重就可以了,但是整体所花费的时间吧比keys命令长。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号