


2020系统综合实践 第4次实践作业
一、使用Docker-compose实现Tomcat+Nginx负载均衡
要求:
- 理解nginx反向代理原理;
- nginx代理tomcat集群,代理2个以上tomcat;
- 了解nginx的负载均衡策略,并至少实现nginx的2种负载均衡策略;
参考资料:
Nginx 配置详解
Nginx服务器之负载均衡策略
1、nginx反向代理原理
1.1 介绍nginx
Nginx是一款自由的、开源的、高性能的HTTP服务器和反向代理服务器;同时也是一个IMAP、POP3、SMTP代理服务器;支持FastCGI、SSL、Virtual Host、URL Rewrite、Gzip等功能。Nginx可以作为一个HTTP服务器进行网站的发布处理,另外Nginx可以作为反向代理进行负载均衡的实现。
1.2 正向代理
正向代理,"它代理的是客户端",是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端必须要进行一些特别的设置才能使用正向代理。
1.3 反向代理

反向代理,"它代理的是服务端",主要用于服务器集群分布式部署的情况下,反向代理隐藏了服务器的信息。
反向代理的作用:
(1)保证内网的安全,通常将反向代理作为公网访问地址,Web服务器是内网
(2)负载均衡,通过反向代理服务器来优化网站的负载
2、nginx代理tomcat集群(代理2个以上tomcat)
2.1 文档结构
├── docker-compose.yml
├── nginx
│ └── default.conf
├── tomcat1
│ └── index.html
├── tomcat2
│ └── index.html
└── tomcat3
└── index.html
2.2 Nginx配置文件default.conf
upstream tomcats {
server tom1:8080; # 主机名:端口号
server tom2:8080; # tomcat默认端口号8080
server tom3:8080; # 默认使用轮询策略
}
server {
listen 2222;
server_name localhost;
location / {
proxy_pass http://tomcats; # 请求转向tomcats
}
}
2.3 Docker-compose.yml
version: "3"
services:
nginx:
image: nginx
container_name: ngtom
ports:
- 80:2222
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件
depends_on:
- tomcat01
- tomcat02
- tomcat03
tomcat01:
image: tomcat
container_name: tom1
volumes:
- ./tomcat1:/usr/local/tomcat/webapps/ROOT # 挂载web目录
tomcat02:
image: tomcat
container_name: tom2
volumes:
- ./tomcat2:/usr/local/tomcat/webapps/ROOT
tomcat03:
image: tomcat
container_name: tom3
volumes:
- ./tomcat3:/usr/local/tomcat/webapps/ROOT
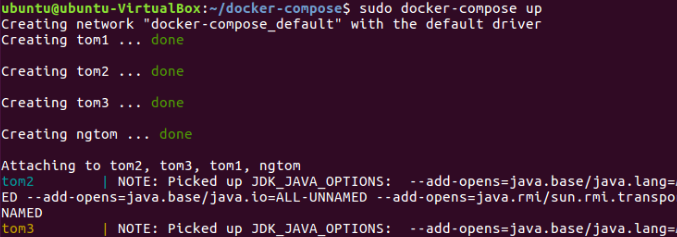
3、了解并实现nginx的负载均衡策略
3.1 轮询
最基本的配置方法,上面配置的就是轮询的方式,它是upstream模块默认的负载均衡默认策略。每个请求会按时间顺序逐一分配到不同的后端服务器。
3.1.1 nginx配置文件:
upstream tomcats {
server tom1:8080 ;
server tom2:8080 ;
server tom3:8080 ;
}
...
3.1.2 检测负载均衡的结果
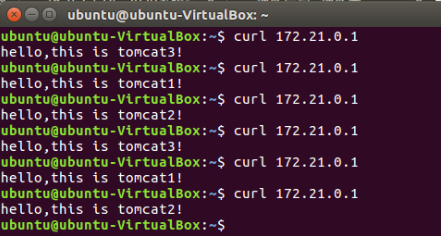
法一:通过浏览器访问localhost显示的index.html界面来判断使用的是哪个服务器
法二:命令行输入curl 172.18.0.1(该网址可以通过输入localhost在终端界面可以看到)


3.2权重
权重方式,在轮询策略的基础上指定轮询的几率。
3.2.1 修改nginx配置文件:
upstream tomcats {
server tom1:8080 weight=1;
server tom2:8080 weight=2;
server tom3:8080 weight=3;
}
...
3.2.2 检测负载均衡的结果
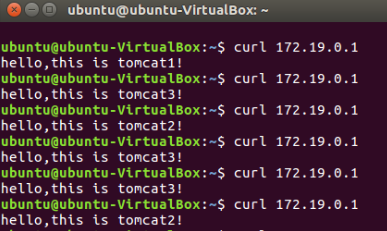
3.3 least-conn
把请求转发给连接数较少的后端服务器。轮询算法是把请求平均的转发给各个后端,使它们的负载大致相同;但是,有些请求占用的时间很长,会导致其所在的后端负载较高。这种情况下,least_conn这种方式就可以达到更好的负载均衡效果。
此负载均衡策略适合请求处理时间长短不一造成服务器过载的情况。
3.3.1 修改nginx配置文件:
upstream tomcats {
server tom1:8080 weight=2;
server tom2:8080 backup;
server tom3:8080 max_fails=3 fail_timeout=10s;
}
...
3.3.2 检测负载均衡的结果

二、 使用Docker-compose部署javaweb运行环境
要求:
- 分别构建tomcat、数据库等镜像服务;
- 成功部署Javaweb程序,包含简单的数据库操作;
- 为上述环境添加nginx反向代理服务,实现负载均衡。
1、构建tomcat、数据库等镜像服务
(以下做的是tomcat+nginx+mysql)
1.1 修改docker-compose.yml文件
version: "3"
services:
nginx:
image: nginx
container_name: ngtom
ports:
- 80:2222
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件
restart: always
tomcat01:
image: tomcat
container_name: tom1
volumes:
- ./tomcat1:/usr/local/tomcat/webapps/ROOT # 挂载web目录
links:
- mysql
restart: always
tomcat02:
image: tomcat
container_name: tom2
volumes:
- ./tomcat2:/usr/local/tomcat/webapps/ROOT
links:
- mysql
restart: always
tomcat03:
image: tomcat
container_name: tom3
volumes:
- ./tomcat3:/usr/local/tomcat/webapps/ROOT
links:
- mysql
restart: always
mysql:
container_name: ngtom_mysql
image: mysql:5.7
ports:
- "3306:3306"
volumes:
- ./mysql/mysql.conf.d:/etc/mysql/mysql.conf.d
- ./mysql/data:/var/lib/mysql
- /etc/localtime:/etc/localtime:ro
environment:
MYSQL_ROOT_PASSWORD: 123456
restart: always
1.2修改nginx中的default.conf文件
upstream tomcats {
server tom1:8080; # 主机名:端口号
server tom2:8080; # tomcat默认端口号8080
server tom3:8080; # 默认使用轮询策略
}
server {
listen 2222;
server_name localhost;
location / {
proxy_pass http://tomcats; # 请求转向tomcats
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
2、成功部署tomcat+nginx+mysql程序,包含简单的数据库操作;

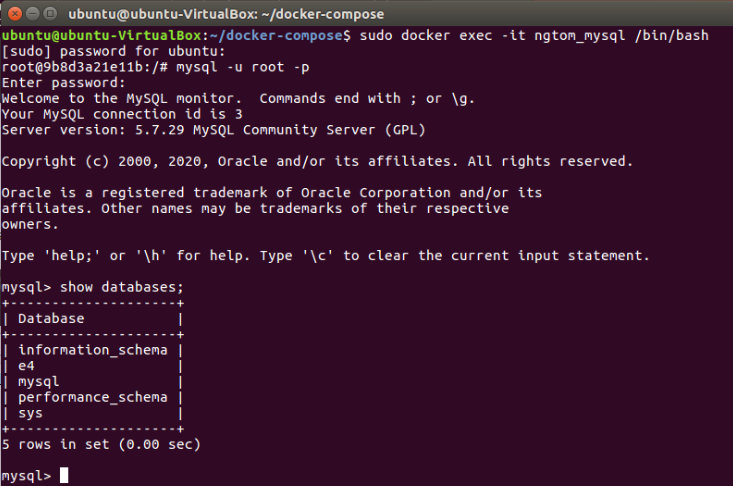
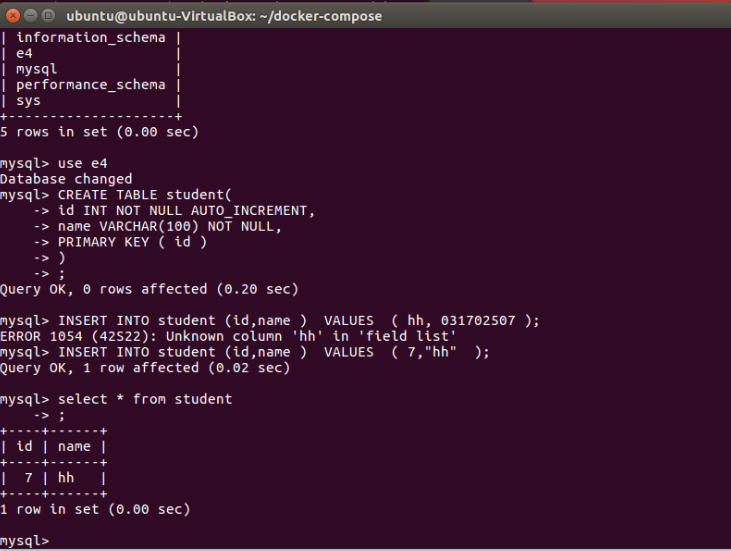
(做到这里发现了自己做错了……部署的不是javaweb程序,于是重新来,借鉴的是这个同学)
2、成功部署Javaweb程序,包含简单的数据库操作;
#文档结构
├── docker-compose.yml
├── nginx
│ └── default.conf
├── mysql
│ └── Dockerfile
│ └── privileges
│ └── schema.sql
│ └── setup.sh
└── webapps
(1)成功部署javaweb程序


(2)简单的数据库操作
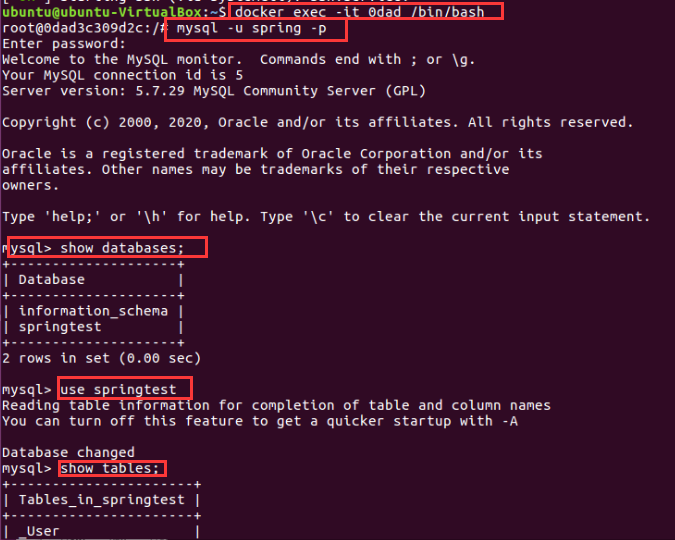
3、为上述环境添加nginx反向代理服务,实现负载均衡(这边用的是轮询)
三、使用Docker搭建大数据集群环境
直接用机器搭建Hadoop集群,会因为不同机器配置等的差异,遇到各种各样的问题;也可以尝试用多个虚拟机搭建,但是这样对计算机的性能要求比较高,通常无法负载足够的节点数;使用Docker搭建Hadoop集群,将Hadoop集群运行在Docker容器中,使Hadoop开发者能够快速便捷地在本机搭建多节点的Hadoop集群。
要求:
- 完成hadoop分布式集群环境配置,至少包含三个节点(一个master,两个slave);
- 成功运行hadoop 自带的测试实例。
1、hadoop分布式集群环境配置
- Docker容器环境:
Ubuntu 16.04 - JDK版本:
openjdk 1.8.0_252 - Hadoop版本:
Hadoop 3.2.1
1.1 创建ubuntu容器
换清华源(并且把每行https改成http)
PS
在创建ubuntu容器的dockerfile文件的同一文件夹下创建一个source.list文件
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial main restricted universe multiverse
# deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates main restricted universe multiverse
# deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
# deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security main restricted universe multiverse
# deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security main restricted universe multiverse
# 预发布软件源,不建议启用
# deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-proposed main restricted universe multiverse
# deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-proposed main restricted universe multiverse
用于创建ubuntu容器的dockerfile文件
FROM ubuntu:16.04
COPY ./sources.list /etc/apt/sources.list
docker build -t ubuntu .
docker run -it --name ubuntu ubuntu
1.2 ubuntu容器初始化
apt-get update #更新系统软件源
apt-get install vim #安装下经常会使用到的vim软件
sudo apt-get install ssh#安装sshd,因为在开启分布式Hadoop时,需要用到ssh连接slave:
/etc/init.d/ssh #运行如下脚本即可开启sshd服务器:
#这启动命令写进~/.bashrc文件,这样我们每次登录Ubuntu系统时,都能自动启动sshd服务;
vim ~/.bashrc
#在该文件中最后一行添加如下内容:
/etc/init.d/ssh start
#免密码ssh设置
cd ~/.ssh
ssh-keygen -t rsa # 一直按回车即可
cat id_rsa.pub >> authorized_keys
#apt-get默认安装的是JDK11,而Hadoop 3.x目前仅支持Java 8,2.x支持Java 7/8.JDK版本太高的原因,可能会出现版本依赖的各种问题。
apt-cache search jdk
apt-get install openjdk-8-jdk
vim ~/.bashrc # 在文件末尾添加以下两行,配置Java环境变量:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
export PATH=$PATH:$JAVA_HOME/bin
source ~/.bashrc # 使.bashrc生效
做完以上步骤之后另开一个终端存个档:
docker ps # 查看当前容器id
docker commit 容器ID ubuntu/jdk8 # 存档
docker run -it -v /home/ubuntu/hadoop/build:/root/build --name ubuntu-jdk8 ubuntu/jdk8
#挂载是为了容器与宿主机之间共享文件,读取Hadoop安装文件,也可以直接用docker cp命令
#docker cp :用于容器与主机之间的数据拷贝。

1.3 安装hadoop
Hadoop可以在官网下载(binary→清华镜像)
把下载好的Hadoop放在挂载的目录下home/ubuntu/hadoop/build并安装:
cd /root/build
tar -zxvf hadoop-3.2.1.tar.gz -C /usr/local #解压缩
cd /usr/local/hadoop-3.2.1
./bin/hadoop version # 验证安装
输出如下:
Hadoop 3.2.1
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842
Compiled by rohithsharmaks on 2019-09-10T15:56Z
Compiled with protoc 2.5.0
From source with checksum 776eaf9eee9c0ffc370bcbc1888737
This command was run using /usr/local/hadoop-3.2.1/share/hadoop/common/hadoop-common-3.2.1.jar
1.4 配置hadoop集群
#先进入配置文件存放目录:
cd /usr/local/hadoop-3.2.1/etc/hadoop
hadoop-env.sh
vim hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/ # 在任意位置添加
core-site.xml
vim core-site.xml
<?xml version="1.0" encoding="UTF-8" ?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl" ?>
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
hdfs-site.xml
vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8" ?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl" ?>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/namenode_dir</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/datanode_dir</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
mapred-site.xml
vim mapred-site.xml
<?xml version="1.0" ?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl" ?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1</value>
</property>
</configuration>
yarn-site.xml
vim yarn-site.xml
<?xml version="1.0" ?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
1.5 修改脚本
进入脚本文件存放目录:
cd /usr/local/hadoop-3.2.1/sbin
对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
对于start-yarn.sh和stop-yarn.sh,添加下列参数:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
PS:注意放在合适的位置,比如function{}之后。
做完以上步骤之后另开一个终端存个档:
docker commit 容器ID ubuntu/hadoop # 存档
1.6 运行hadoop集群
#用上面存档的镜像开启三个终端,分别运行集群中的主机:
# 第一个终端
docker run -it -h master --name master ubuntu/hadoop
# 第二个终端
docker run -it -h slave01 --name slave01 ubuntu/hadoop
# 第三个终端
docker run -it -h slave02 --name slave02 ubuntu/hadoop
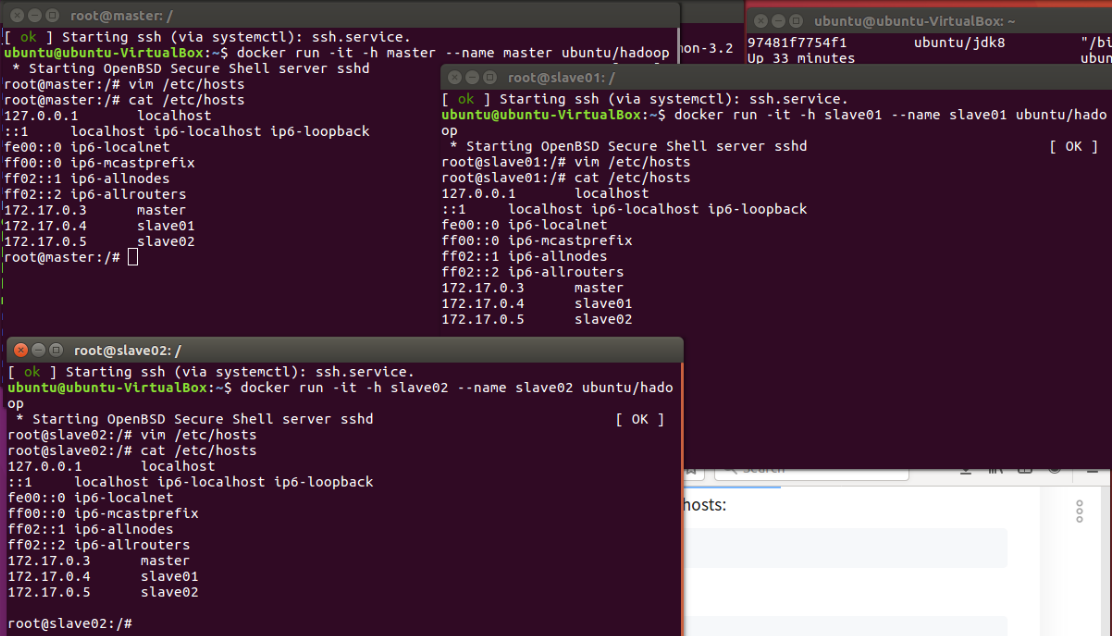
为三台主机配置对方的地址信息,他们才能找到彼此。三个终端分别修改/etc/hosts:
vim /etc/hosts # 查看各终端的IP并修改
内容均修改成如下形式即可
172.17.0.3 master
172.17.0.4 slave01
172.17.0.5 slave02
#测试ssh,在master上,ssh相应主机即可访问目标主机,exit命令可以断开ssh连接。
ssh slave01 # 第一次使用需要输入yes
ssh slave02

vim /usr/local/hadoop-3.2.1/etc/hadoop/workers # 旧版为slaves
#将`localhost`修改为以下
slave01
slave02
在master上测试hadoop集群:
cd /usr/local/hadoop-3.2.1
bin/hdfs namenode -format # 格式化文件系统
sbin/start-dfs.sh # 开启NameNode和DataNode服务
bin/hdfs dfs -mkdir /user # 建立HDFS文件夹,也可以放到下面示例程序中进行
bin/hdfs dfs -mkdir /user/root
bin/hdfs dfs -mkdir input
bin/hdfs dfs -put etc/hadoop/*.xml input # 将xml复制到input下,作为示例程序输入
sbin/start-yarn.sh # 开启ResourceManager和NodeManager服务
jps # 查看服务状态
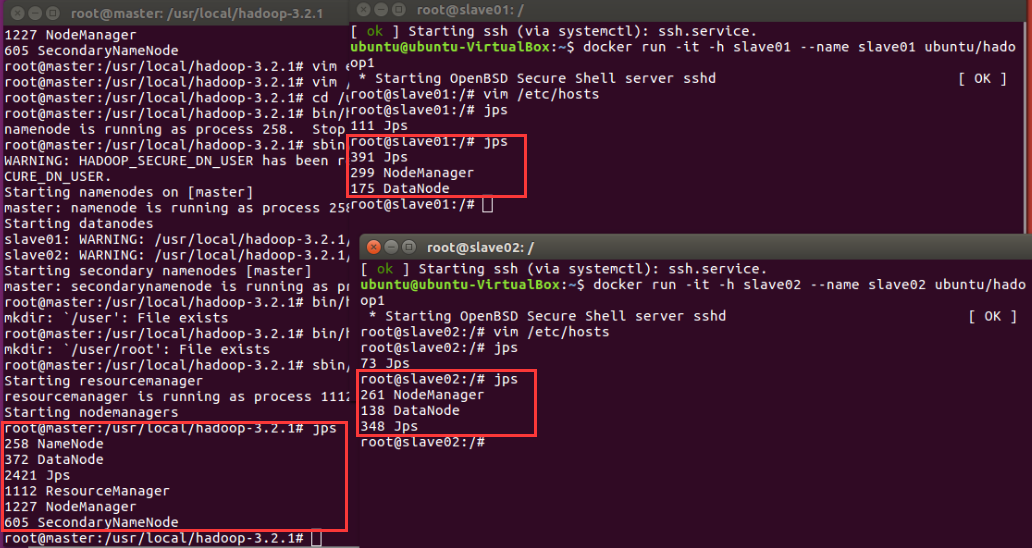
2、运行hadoop 自带的测试实例
在master上:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+' # 运行示例
bin/hdfs dfs -get output output # 获取输出结果
cat output/* # 查看输出结果
sbin/stop-all.sh # 停止所有服务
运行结果:
dfsadmin
dfs.replication
dfs.namenode.name.dir
dfs.datanode.data.dir

四、小结
1、主要问题和解决方法
问题一:docker-compose.yml文件中每行的多个空格不能用tab键
解决方法:一个一个敲空格

问题二:在执行apt-get install ssh的时候出现问题
解决方法:在容器中换源

问题三:Docker挂载本地目录及实现文件共享失败
docker run -it -v /home/hadoop/build:/root/build --name ubuntu-jdk8 ubuntu/jdk8
解决方法:路径错了。宿主机的路径时/home/ubuntu/hadoop/build.文件管理器自动隐藏了用户名ubuntu,在终端下才能看到真实路径。PS:用户名在终端下可以用~代替。
问题四:ssh slave01时候权限不够
解决方法:重新配置sshd无密码登陆
cd ~/.ssh
ssh-keygen -t rsa # 一直按回车即可
cat id_rsa.pub >> authorized_keys
问题五:docker-compose.yml第一行的version如果是3.8会出现版本错误
解决方法:改成version:"3"

2、经验和感想+花费时间
在这次实验中感觉到了阶段性的docker commit,将容器保存成镜像很重要。因为做实验的时候很多时候做到后面会发现前面配置环境的时候出了问题,做后面的实验的时候发现出现错误,只能从前面重新来。如果阶段性的commit就会省下不少力气。
实验花了三个下午+两个晚上,因为小错误实在太多了。归根到底还是没有真正明白那些文件内容的内在联系。导致纠错都花了很多的时间,也很感谢群里同学的帮助。
第二个实验实在是太难了,jsp也不会写,想找合适得war包也没找到。最后还是按照有给出war的同学的教程来做的。因为关于用docker-compose来部署javaweb应用的资料实在是太少了,很多时候是具体场景下,对我们的实验没什么帮助。等同学们的博客都发上来了,我一定好好看一定好好学TT把第二个再研究研究。下次要比这次更顺利才行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号