
2.3 MySQL索引
索引介绍
索引:是排序的快速查找的特殊数据结构,定义作为查找条件的字段上,又称为键key,索引通过存储引擎实现
索引的作用相当于书的目录,可以根据目录中的页码快速找到
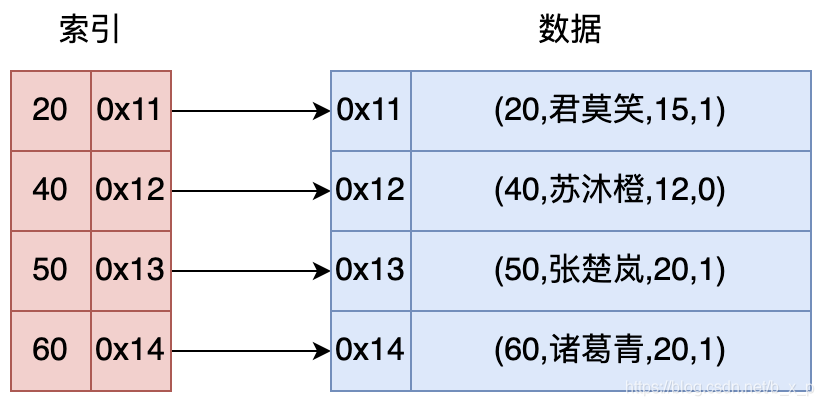
索引是为了加速对表中数据行的检索而创建的一种分散存储的数据结构。其工作机制如图: 图中,如果现在有一条sql语句 select * from user where id = 40,如果没有索引的条件下,我们要找到这条记录,我们就需要在数据中进行全表扫描,匹配id = 13的数据。 如果有了索引,我们就可以通过索引进行快速查找,如上图中,可以先在索引中通过id = 40进行二分查找,再根据定位到的地址取出对应的行数据。
优点vs缺点
优点:
索引可以降低服务需要扫描的数据量,减少了IO次数
所以可以帮助服务器避免排除和使用临时表
所以可以帮助将随机IO转为顺序IO
缺点:
占用额外空间,影响插入速度
数据发生变化必定要更新索引,更新索引必定要带来io操作
索引类型
二叉树
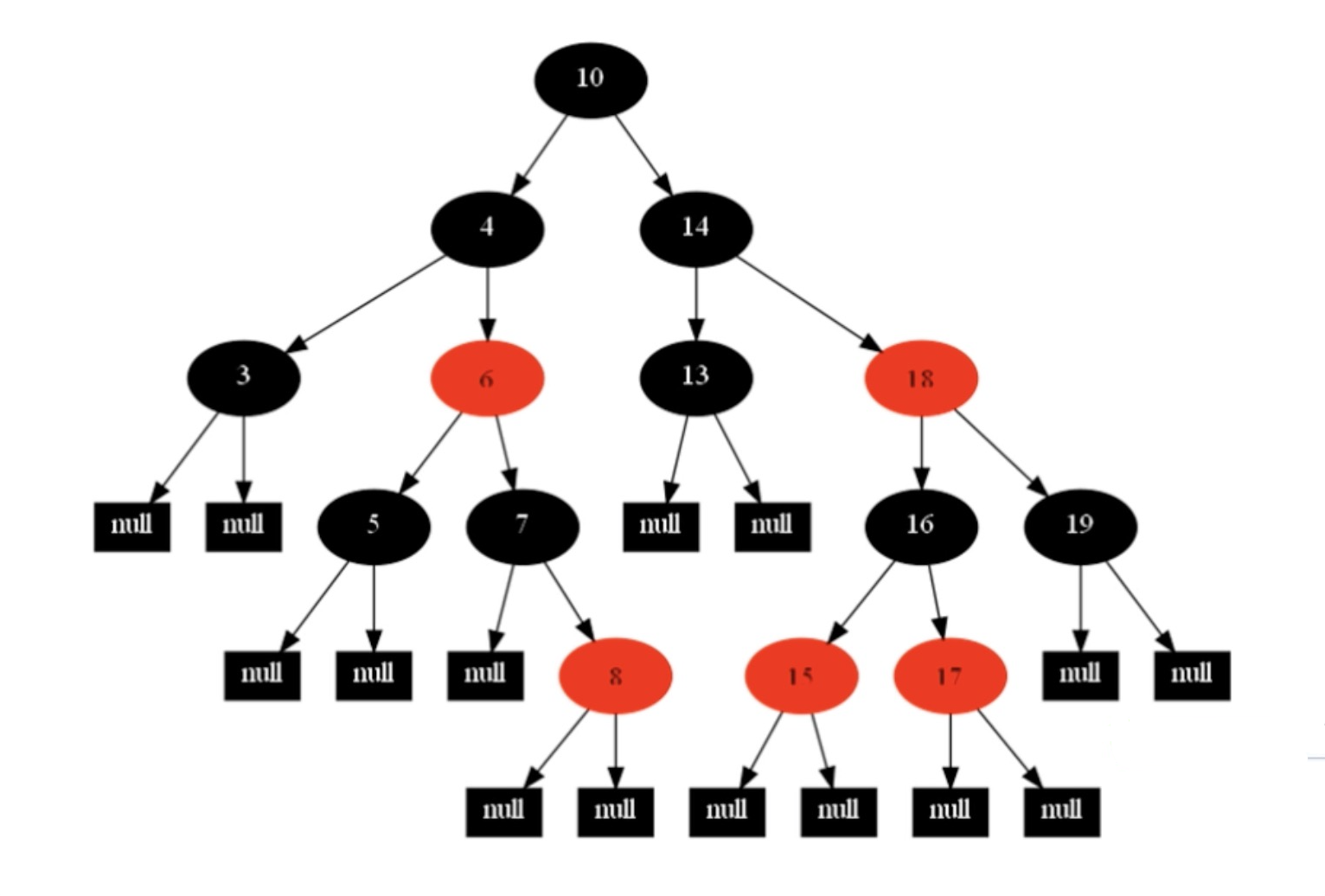
红黑树
B-Tree索引
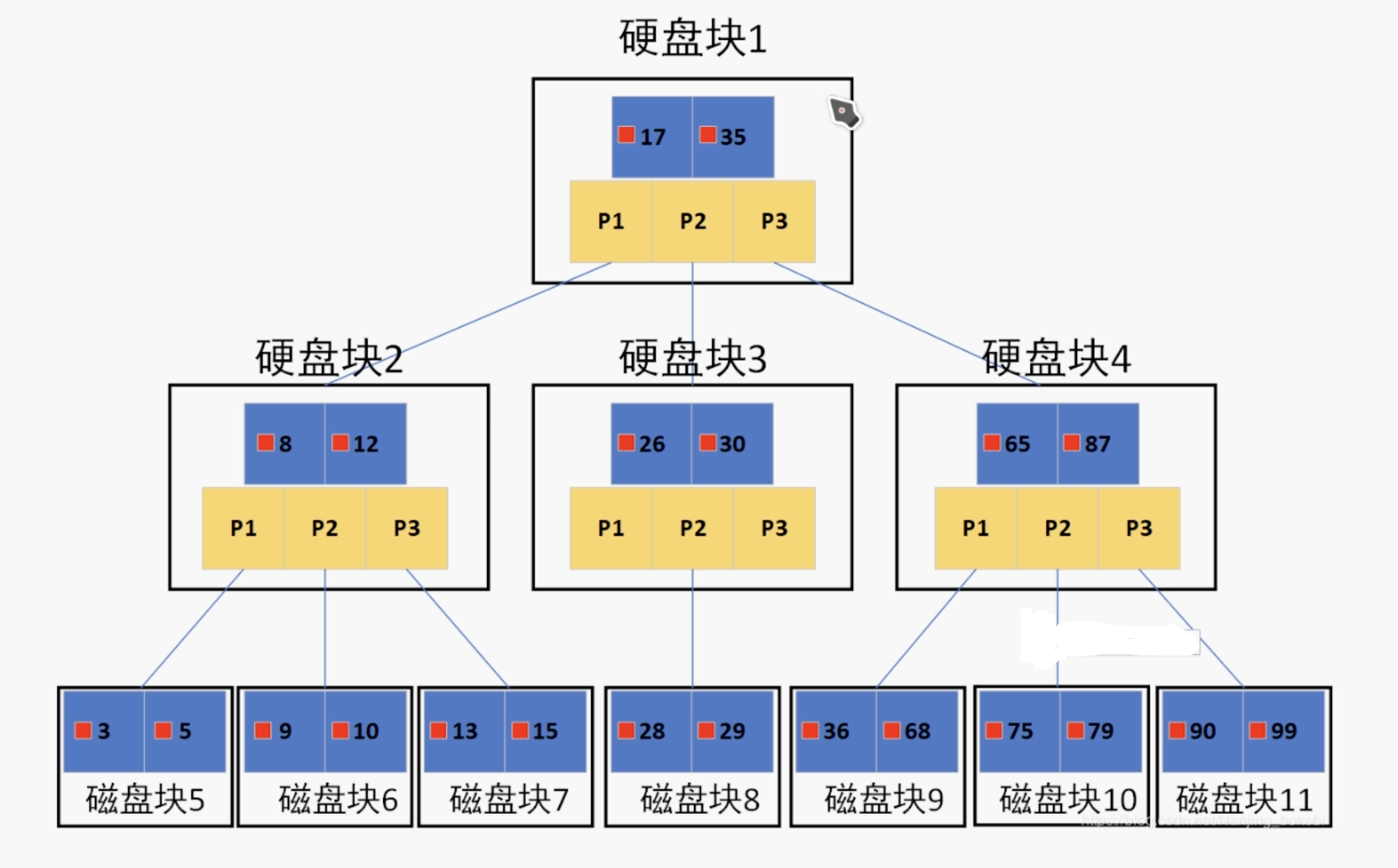
B+Tree索引
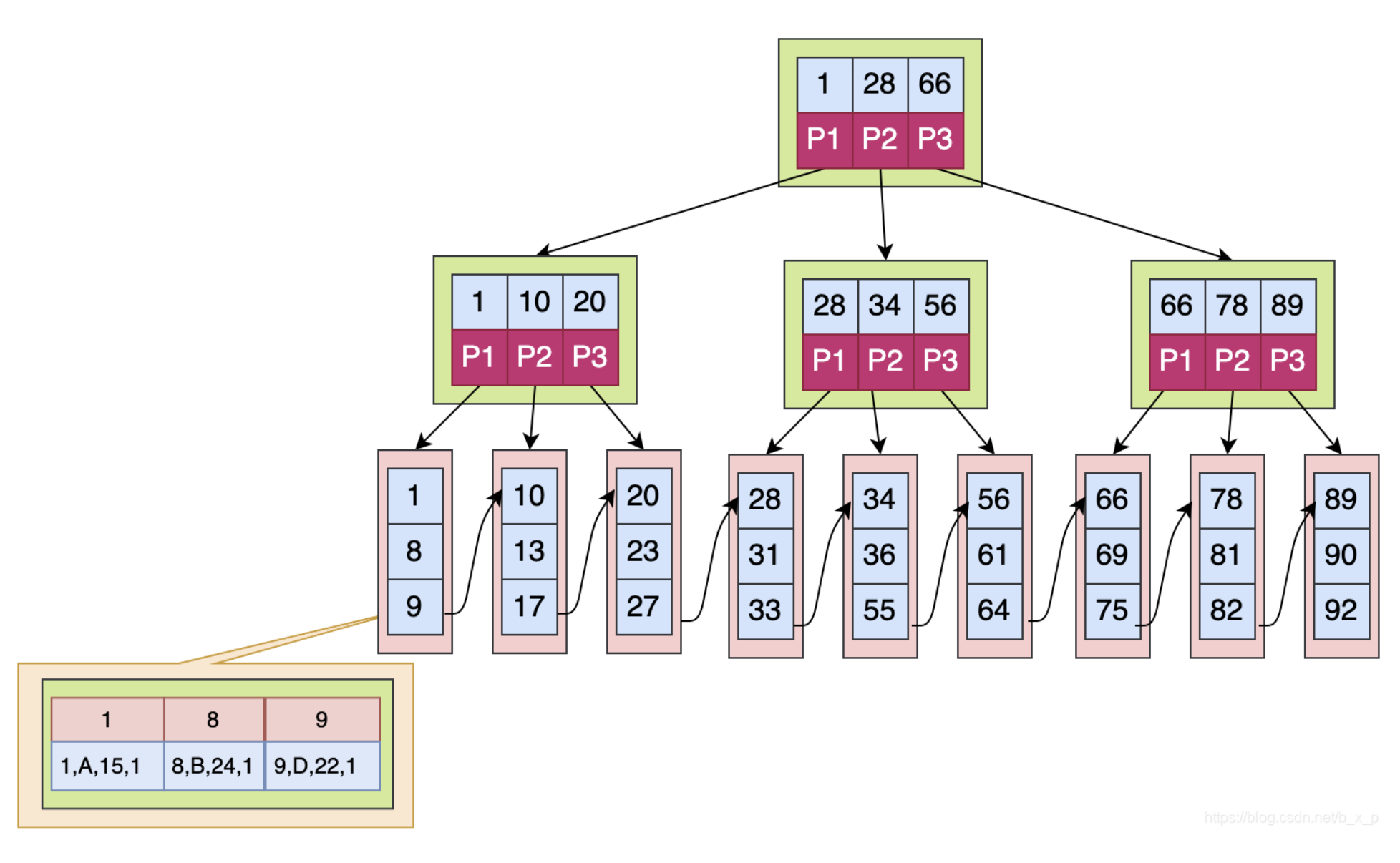
如果上图中是用ID做的索引,如果是搜索X = 1的数据,搜索规则如下: 1.取出根磁盘块,加载1,28,66三个关键字。 2.X <= 1 走P1,取出磁盘块,加载1,10,20三个关键字。 3.X <= 1 走P1,取出磁盘块,加载1,8,9三个关键字。 4.已经到达叶子节点,命中1,接下来加载对应的数据,图中数据区中存储的是具体的数据。
1 MySQL为什么最终要去选择B+Tree? 2 3 B+Tree是B TREE的变种,B TREE能解决的问题,B+TREE也能够解决(降低树的高度,增大节点存储数据量) 4 5 B+Tree扫库和扫表能力更强。如果我们要根据索引去进行数据表的扫描,对B TREE进行扫描,需要把整棵树遍历一遍,而B+TREE只需要遍历他的所有叶子节点即可(叶子节点之间有引用)。 6 7 B+TREE磁盘读写能力更强。他的根节点和支节点不保存数据区,所以根节点和支节点同样大小的情况下,保存的关键字要比B TREE要多。而叶子节点不保存子节点引用,能用于保存更多的关键字和数据。所以,B+TREE读写一次磁盘加载的关键字比B TREE更多。 8 9 B+Tree排序能力更强。上面的图中可以看出,B+Tree天然具有排序功能。 10 11 B+Tree查询性能稳定。B+Tree数据只保存在叶子节点,每次查询数据,查询IO次数一定是稳定的。当然这个每个人的理解都不同,因为在B TREE如果根节点命中直接返回,确实效率更高。
Hash算法
哈希索引(hash index)基于哈希表实现,只有精确匹配索引所有列的查询才有效。 对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code), 哈希码是一个较小的值,并且不同键值的行计算出来的哈希码也不一样。 哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
索引类型
NDEX 普通索引 UNIQUE 唯一索引 FULLTEXT 全文索引 PRIMARY KEY 主键 FOREIGN KEY 外键

 浙公网安备 33010602011771号
浙公网安备 33010602011771号