
各种熵及其在机器学习中的应用
此熵不是智商、情商、逆境商。最开始是热力学的概念,后来被祖师爷香农用来表示信息/信源的不确定度。
自信息量
信源符号 \(x_i\) 本身的不确定度,称为其自信息量,记为 \(I(x_i)\)
\[I(x_i) = H(x_i) = \log_2\frac{1}{p(x_i)}\]
单符号离散信源的熵
如果一个单符号离散无记忆信源的信息符号可以表示为一个独立的离散随机变量 \(X\),则称这个随机变量的平均不确定度为离散无记忆信源的熵,记为
\[H(X)= \sum_{i=i}^{n}p(x_i)\log_2\frac{1}{p(x_i)}\]
熵函数具有非负性、对称性、确定性和连续性。
联合熵和条件熵
参考单符号离散信源,定义联合信源的二维消息符号的自信息量如下:
\[I(x_i,y_j) = -\log_2p(x_i,y_j)\]
条件自信息量如下:
\[I(x_i/y_j) = -\log_2p(x_i/y_j)\]
二元联合信源输出一个消息符号\((x_i,y_j)\)所发出的平均信息量称为联合熵,如下:
\[H(X,Y) = E[I(x_i,y_j)] = - \sum_{i=1}^{n}\sum_{j=1}^{m}p(x_i,y_j)\log_2p(x_i,y_j)\]
二元联合信源输出\(Y\)(或\(X\))任一状态以后,再输出\(X\)(或\(Y\))任一状态所发出的平均信息量称为条件熵,如下:
\[H(X/Y) = E[I(x_i/y_j)] = - \sum_{i=1}^{n}\sum_{j=1}^{m}p(x_i,y_j)\log_2p(x_i/y_j)\]
如果二维随机变量\(X\)和\(Y\)相互独立,则
\[H(X,Y) = H(X) + H(Y)\\H(X/Y) = H(X)\\H(Y/X) = H(Y) \]
对于一般情况下
\[H(X,Y) = H(X) + H(Y/X) = H(Y) + H(X/Y)\]
交互信息量
给定离散信道\([P(Y/X)]\),接收到随机变量\(Y\)的任一符号\(y_j\)后,从\(y_j\)中获取关于随机变量任一符号\(x_i\)的信息量,称为交互信息量。记为
\[I(x_i;y_j) = H(x_i) - H(x_i/y_j) = I(x_i) - I(x_i/y_j)\]
交互信息量等于接收\(y_j\)前接收者对\(x_i\)存在的不确定度减去接收\(y_j\)后接收者对\(x_i\)仍存在的不确定度。也就是等于通信前后接收者对\(x_i\)的不确定度的变化量。
\[\begin{align}I(x_i;y_j)&= I(x_i) - I(x_i/y_j)\notag\\ &= \log_2\frac{p(x_i/y_j)}{p(x_i)}\notag\\&=\log_2\frac{p(y_j/x_i)}{p(y_j)}\notag\\ &=I(y_j;x_i)\notag\end{align}\]
即从\(y_j\)中获取的关于\(x_i\)的信息量等于从\(x_i\)中获得关于\(y_j\)的信息量,所以称为交互信息量。
给定离散信道\([P(Y/X)]\),接收到随机变量\(Y\)的任一符号后,获取关于随机变量任一符号的平均信息量,称为平均交互信息量。记为
\[I(X;Y) = \sum_{i=1}^{n}\sum_{j=1}^{m}p(x_i,y_j)\log_2\frac{p(x_i/y_j)}{p(x_i)}\]
平均交互信息量具有以下性质
- 非负性
即\(I(X;Y)\geqslant 0\) - 交互性
即\(I(X;Y) = I(Y;X)\) - 极值性
平均交互信息量不可能大于信源熵,也不可能大于信宿熵。
\[I(X;Y) = H(X)-H(X/Y) \leqslant H(X)\\I(Y;X) = H(Y) - H(Y/X) \leqslant H(Y)\] - 凸函数性
信道给定时,平均交互信息量是信源先验概率分布\(p(x_i)\)的上凸函数,即
\[\theta I_1(X;Y) + (1-\theta)I_2(X;Y) \leqslant I(X;Y)\]
交互信息量和熵函数的关系
 

在机器学习中的应用
决策树
在决策树中,最关键的是如何选择最优化分属性。一般而言,我们希望决策树的分支节点所包含的样本尽可能属于同一类别,即节点的“纯度”越来越高。
信息熵可以用来度量纯度。这里我们用 Ent(D) 来表示某个集合的信息熵。
假设用某个离散属性 \(a\) 把样本集合 \(D\) 划分为\(V\)个子集,定义信息增益如下:
\[Gain(D,a) = Ent(D) - \sum_{v=1}^{V}\frac{|D^v|}{|D|}Ent(D^v)\]
其中\(|D|\)表示集合中的元素数目。
信息增益越大,那么使用某个属性来划分获得的“纯度提升”越大。可以使用信息增益来进行决策树的划分属性选择。
贝叶斯分类器
有一种半朴素贝叶斯分类器叫做TAN (Tree Argumented naïve Bayers),是在最大带权生成树算法的基础上经过若干步骤把属性间依赖关系约简为下面的树形结构:
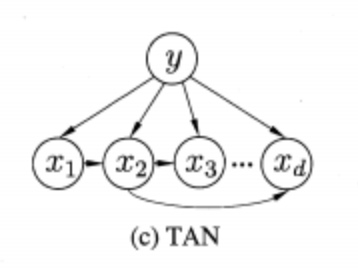 

可以看做是一个带权生成树,每条边的权重就是两个属性之间的条件互信息量:
\[I(x_i,x_j|y) = \sum_{x_i,x_j|c}\log\frac{P(x_i,x_j|c)}{P(x_i|c)P(x_j|c)}\]
参考
- 周志华. 机器学习[M]. 清华大学出版社, 2016.
- 顾学迈, 石硕, 贾敏. 信息与编码理论[M]. 哈尔滨工业大学出版社, 2014.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号