数据预处理
为什么要进行数据预处理?
数据质量
数据质量包括准确性、完整性、一致性、时效性、可信性和可解释性
数据质量的三个要素:准确性、完整性、一致性。
不正确、不完整和不一致的数据是现实世界的大型数据库和数据仓库的共同特点
数据预处理的主要任务
- 数据清理
- 数据集成
- 数据规约
- 数据变换
数据清理
现实世界的数据一般是不完整的、有噪声的和不一致的。数据清理例程试图填充缺失的、光滑噪声并识别离群点、纠正数据中的不一致性。
缺失值
- 忽略元组
- 人工填写缺失值
- 使用一个全局常量填充缺失值
- 使用属性的中心度量(如均值或者中位数)填充缺失值
- 使用与给定元组属同一类的所有样本的属性均值或中位数
- 使用最有可能的值填充缺失值:可以利用回归、贝叶斯、决策树等方法预测缺失值
噪声数据
噪声是被测量的变量的随机误差或者方差。
-
分箱去噪
![在这里插入图片描述]()
-
回归去噪:用一个函数拟合数据来光滑数据,线性回归涉及找出拟合两个属性的“最佳”直线,使得一个属性可以用来预测另一个。
-
离群点分析:通过聚类检测离群点

数据清理作为一个过程
- 第一步偏差检测
- 每个属性的数据类型和定义域是什么
- 每个属性可接受的值是多少
- 找出均值、中位数、众数
- 数据是堆成还是倾斜的
- 值域是什么
- 所有的值是否都落在期望的区间内
- 每个属性的标准差
- 属性之间是否存在依赖
- 第二步数据变换
- 两步过程迭代执行
数据集成
数据分析任务多半涉及数据集成。数据集成将多个数据源中的数据合并,存放在一个一致的数据存储中,如数据仓库。这些数据源可能包括数据库、数据立方体或一般文件。
冗余和相关分析
- 标称数据的X2\mathcal{X}^2X2的相关检验
![-]()
![在这里插入图片描述]()
实例(括号中的数是期望频率eije_{ij}eij):
![在这里插入图片描述]()
其中(男,小说)的期望频率是:
![在这里插入图片描述]()
以此类推:
![在这里插入图片描述]()
对于上表自由度是(2−1)(2−1)=1(2-1)(2-1) =1(2−1)(2−1)=1,对于自由度为1,在0.001的置信水平下,拒绝假设的值是10.828,由于我们计算的值大于该值,因此可以拒绝“性别”和“阅读类型”独立的假设,对于给定的人群,这两个属性是强相关的。 - 数值数据的相关系数(Pearson积矩系数)
![在这里插入图片描述]()



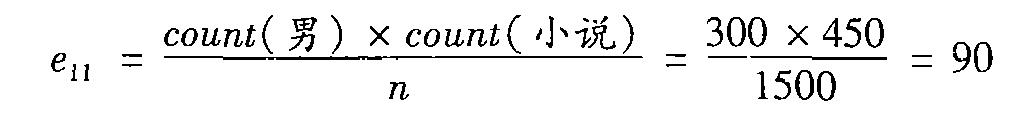
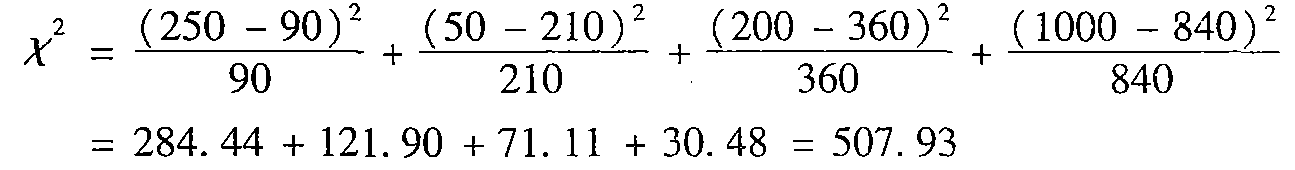

如果rA,Br_{A,B}rA,B大于0,则A和B是正相关的,该值越大,相关性越强。
- 数值数据的协方差
![在这里插入图片描述]()

元素重复
除了检测属性之间的冗余外,还应当在元组级检测重复。
数据值冲突的检测与处理
如一所大学开设俺们数据库系统课程,用A−FA - FA−F评分,另一所大学可能采用学期制,开设两门数据库课程,用1−101-101−10评分,很难在这两所大学之间制定精确的课程成绩变换规则,这使得信息交换非常困难。
数据规约
数据规约技术可以用来得到数据集的规约表示(即数据集的简化表示,但能产生同样的分析结果)
数据规约概述
- 维归约:减少所考虑的随机变量或属性的个数,方法包括
小波变换和主成分分析(PCA),属性子集选择是一种维归约方法,其中不相关、弱相关、或者冗余的属性或者维被检测和删除。 - 数量归约:用替代的、较小的数据表示形式替换原数据。这些技术可以是参数或者非参数的。对于参数方法,使用模型估计数据,使得一般只需要存放模型参数,而不是实际数据,如
回归和对数线性模型。非参数方法:直方图、聚类、抽样、数据立方体聚集 - 数据压缩:使用变换,以便得到原数据的规约或者“压缩表示”。有
无损压缩和有损压缩
小波变换(DWT)
DWT和离散傅里叶变换(DFT)有密切关系。

主成分分析
属性子集选择
回归和对数线性模型:参数化数据规约
使用模型估计数据,使得一般只需要存放模型参数,而不是实际数据。回归和对数线性模型可以用来近似给定的数据。
直方图
直方图使用分箱来近似数据分布,是一种流行的数据规约形式,将某个属性的数据分布划分为不相交的子集或桶。
桶的划分规则:
- 等宽
- 等频
例子:

聚类
聚类技术把数据元组看作对象,将对象划分为簇,使得在一个簇中的对象相互相似,而与其他簇中的对象相异。
抽样
- 无放回简单随机抽样
- 有放回简单随机抽样
- 簇抽样
- 分层抽样
![在这里插入图片描述]()

数据立方体聚集

数据变换与数据离散化
数据变换将数据变换成适合挖掘的形式,数据离散化通过把值映射到区间或概念标号变换数值数据,这种方法可以用来自动产生数据的概念分层,而概念分层允许在多个粒度层进行挖掘。
数据变换策略概述
- 光滑:去掉数据中的噪声,包括分箱、回归和聚类。
- 属性构造(特征构造):由给定的属性构造新的属性添加到属性集中。
- 聚集:对数据进行汇总或者聚集。
- 规范化:把属性数据按比例缩放,使落如一个特定的小区间,如[0.0, 1.0]。
- 离散化: 数值属性(例如年龄)的原始值用区间标签(0~10, 11~20)或者概念标签(如youth、adult、senior)替换。
- 由标称数据产生概念分层
通过规范化变换数据
- 最小-最大规范化
![在这里插入图片描述]()
- z分数规范化
![在这里插入图片描述]()
- 小数定标规范化
![-]()



通过分箱离散化
通过直方图分析离散化
通过聚类、决策树和相关分析离散化
标称数据的概念分层产生
- 根据每个属性的不同值的个数产生概念分层
![在这里插入图片描述]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号