


job提交流程源码解析
job提交的源码中(面试重点):
源码解析:
//找到Driver中提交job的代码(入手点) boolean b = job.waitForCompletion(true); System.exit(b? 0 : 1); //进入后找到submit(提交)方法 if (state == JobState.DEFINE) { submit(); } //submit方法内部 public void submit() throws IOException, InterruptedException, ClassNotFoundException { ensureState(JobState.DEFINE);//校验当前JobState的状态 setUseNewAPI();//新旧API的兼容 connect();//连接有两种:1.集群模式下连接YarnClinet 2.本地模式下连接LocalClient //验证连接的是那种,进入connect()中,找到return new Cluster return new Cluster(getConfiguration()); //进入Cluster中,找到初始化initialize initialize(jobTrackAddr, conf); //进入initialize找到initProviderList()方法,循环for之后,为LocalClient for (ClientProtocolProvider provider : frameworkLoader) { localProviderList.add(provider); } //随后退出重新回到submit方法内部中,已经有了连接,开始提交相关信息 return submitter.submitJobInternal(Job.this, cluster); //进入到submitJobInternal核心代码: checkSpecs(job);//检测输出路径是否正确 Configuration conf = job.getConfiguration(); addMRFrameworkToDistributedCache(conf); Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf); //进入checkSpecs(job),找到output.checkOutputSpecs(job); output.checkOutputSpecs(job); //进入到其中 //判断输出路径是否为空 if (outDir == null) { throw new InvalidJobConfException("Output directory not set."); } // get delegation token for outDir's file system TokenCache.obtainTokensForNamenodes(job.getCredentials(), new Path[] { outDir }, job.getConfiguration()); //判断输出路径是否已经存在 if (outDir.getFileSystem(job.getConfiguration()).exists(outDir)) { throw new FileAlreadyExistsException("Output directory " + outDir + " already exists"); } } //重新回到了submitJobInternal方法中,来到这里 Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf); //Path会生成一个临时文件,用来存储job提交所需要的信息 //file:/tmp/hadoop/mapred/staging/MJS36909941/.staging //继续向下走 JobID jobId = submitClient.getNewJobID();//每一个job任务都会有一个独一无二的jobId job.setJobID(jobId);//设置jobId Path submitJobDir = new Path(jobStagingArea, jobId.toString()); //临时文件下,添加一层以jobId创建的文件目录(此时还不会真正创建) //file:/tmp/hadoop/mapred/staging/MJS36909941/.staging/job_local36909941_0001 //继续向下走,找到提交jar包的代码(本地模式不会提交jar包) copyAndConfigureFiles(job, submitJobDir); //进入后,找到上传资源信息的代码 rUploader.uploadResources(job, jobSubmitDir); //进入后,继续向下走,找到 mkdirs(jtFs, submitJobDir, mapredSysPerms); //执行完mkdirs代码后,会真正的创建file:/tmp/hadoop/mapred/staging/MJS36909941/.staging/job_local36909941_0001 //返回submitJobInternal中,找到设置切片数的代码 int maps = writeSplits(job, submitJobDir); //执行完writeSplits后, //file:/tmp/hadoop/mapred/staging/MJS36909941/.staging/job_local36909941_0001 //目录下会生成切片相关的文件 //继续向下走,找到 writeConf(conf, submitJobFile); //执行完后,会在file:/tmp/hadoop/mapred/staging/MJS36909941/.staging/job_local36909941_0001 //文件下生成job提交所需要的参数信息 //随后继续向下走,jobstate的状态变为running state = JobState.RUNNING;
1.本地模式提交:
1).会产生切片相关信息
2).会产生Job提交的参数信息
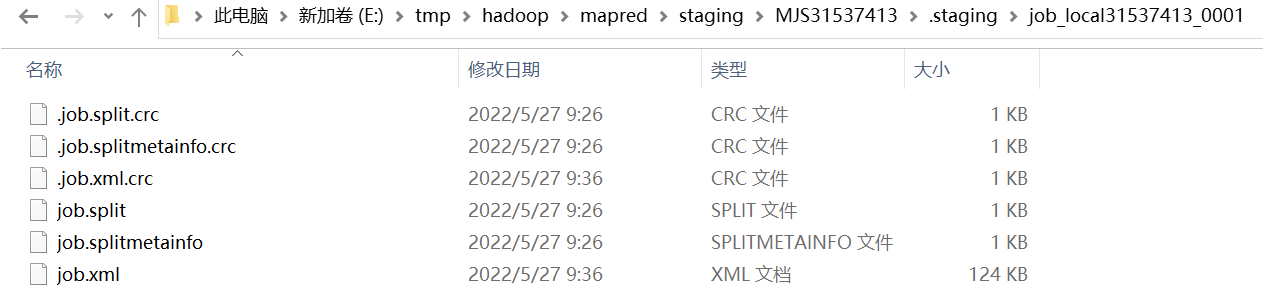
2.集群模式提交:
1)会产生切片相关的文件信息
2)会产生Job提交的参数xml文件
3)会产生Job的jar包


 浙公网安备 33010602011771号
浙公网安备 33010602011771号