
第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | 通过设计论文查重系统,体会工程开发流程,实践工程化开发相关知识 |
1. github地址
https://github.com/BUJIN-SWORD/BUJIN-SWORD/tree/main/3123004445
2. psp表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 575 | 685 |
| · Analysis | · 需求分析(包括学习新技术) | 70 | 90 |
| · Design Spec | · 生成设计文档 | 50 | 60 |
| · Design Review | · 设计复审 | 25 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 25 |
| · Design | · 具体设计 | 40 | 50 |
| · Coding | · 具体编码 | 190 | 220 |
| · Code Review | · 代码复审 | 50 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 130 | 150 |
| Reporting | 报告 | 85 | 110 |
| · Test Report | · 测试报告 | 35 | 45 |
| · Size Measurement | · 计算工作量 | 20 | 25 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 40 |
| · 合计 | 690 | 825 |
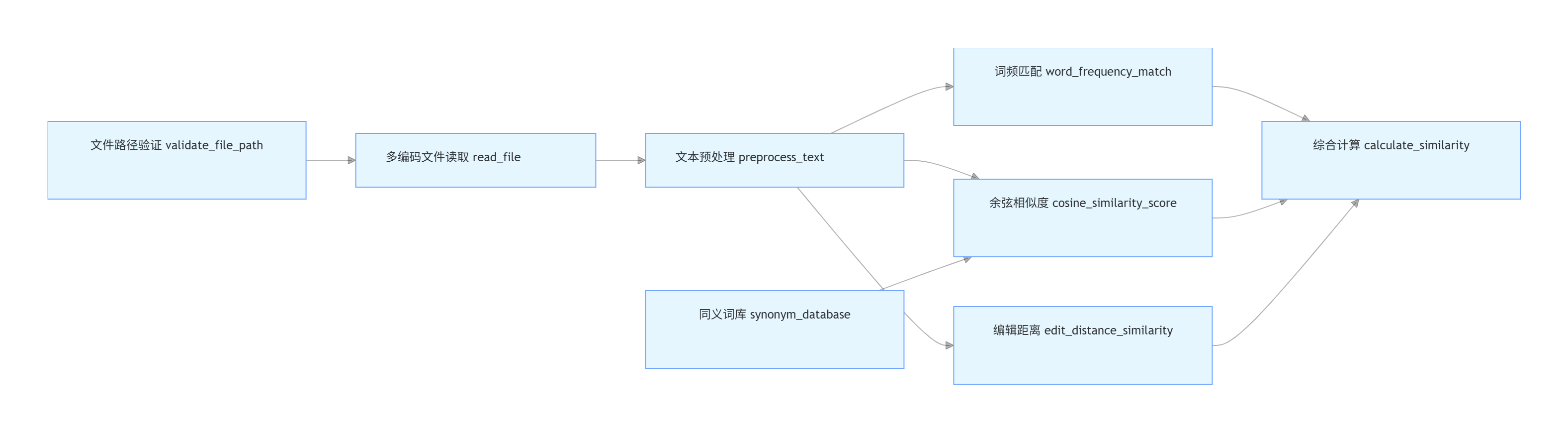
3. 计算模块接口的设计与实现过程
3.1 设计:代码组织与模块关系
论文查重工具的计算模块以函数式编程为核心,通过「核心算法工具模块」与「同义词库支持模块」组织代码,核心函数与模块间关系如下:
(1)代码组织与模块划分
- 核心算法工具模块:plagiarism_utils.py
集中实现 “文本处理→相似度计算” 的全流程核心函数 - 数据支持模块:synonym_database.py
定义分类同义词词典(主题、人物、场景、器物四大类),为 “语义相似度算法” 提供数据支撑。
(2)核心函数与交互关系
计算模块包含 7 个核心函数,按 “数据流向” 形成依赖关系:
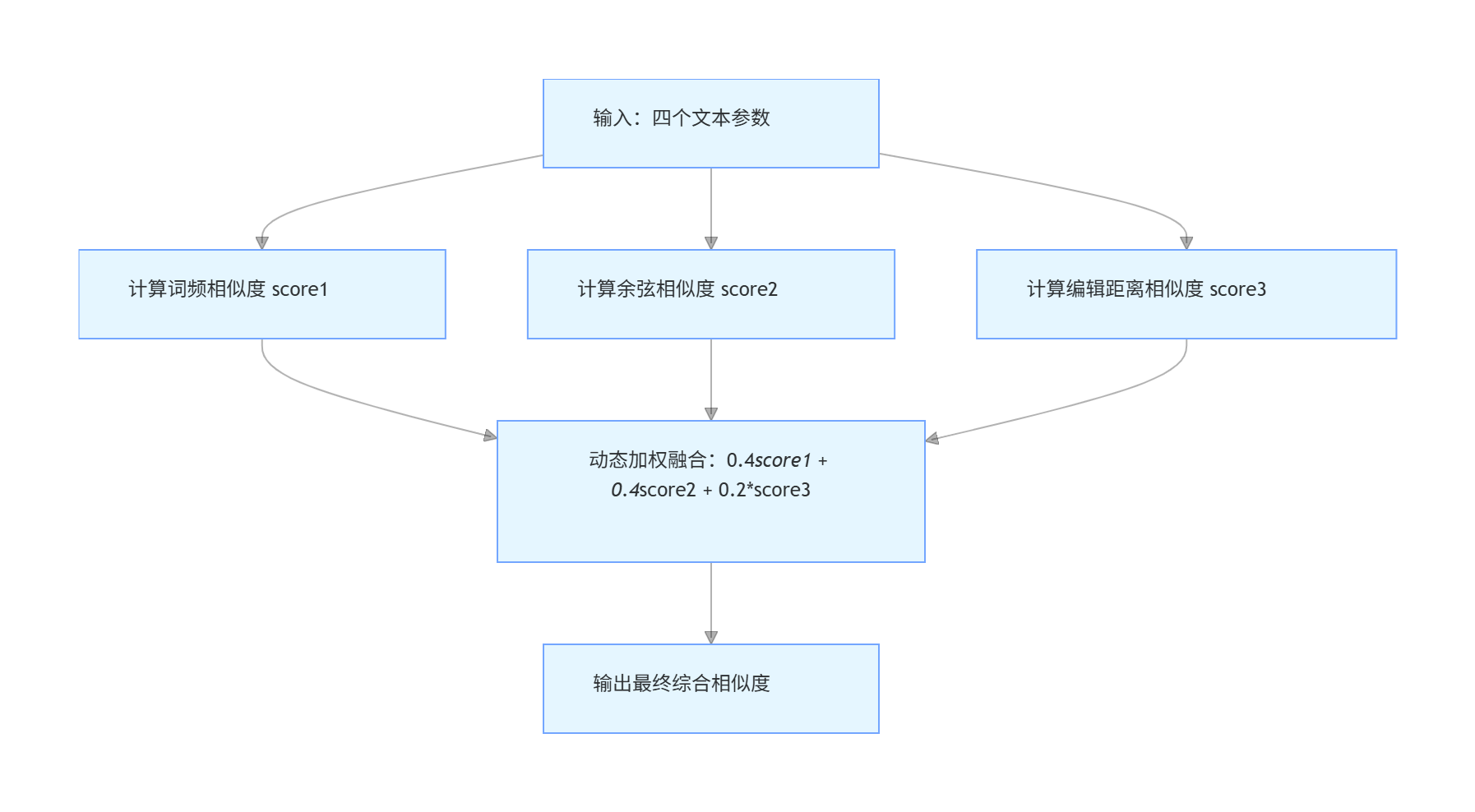
(3)关键函数流程图
calculate_similarity是算法融合的核心,流程为:
3.2 实现:算法关键与独到之处
(1)算法关键逻辑
计算模块整合三种经典相似度算法,并通过 “同义词扩展” 和 “动态加权” 解决传统算法的局限性:
- 词频匹配(word_frequency_match):核心是 “统计分词列表的共现词占比”。通过集合操作找出两个分词列表的共现词,最终得分 = 共现词数量 / 较长列表的长度。该算法快速且能反映 “核心词汇的重复密度”。
- 带同义词扩展的余弦相似度(cosine_similarity_score):突破传统余弦 “仅匹配词本身” 的局限,通过synonym_database.get_synonyms(word)获取每个词的同义词(如 “研究” 匹配 “探究”“钻研”),将 “词匹配” 升级为 “语义匹配”,大幅提升语义层面的查重准确性。
- 编辑距离相似度(edit_distance_similarity):基于动态规划计算两个字符串的最小编辑次数(插入、删除、替换),再转换为相似度( 1 − 编辑距离/max(文本1长度,文本2长度) ),擅长捕捉 “字符级改写”(如少量替换、增删字)。
- 综合相似度(calculate_similarity):
融合上述三者结果,动态调整权重平衡场景适应性:
长文本(≥500 字):词频、余弦权重各提至 0.45,编辑距离降为 0.1(侧重 “主题 / 语义重复”);
短文本(<500 字):编辑距离权重提至 0.3,词频、余弦各为 0.35(侧重 “局部改写识别”)。
(2)算法的独到之处
本计算模块在传统查重算法基础上,有三点创新设计:
- 领域适配的同义词库:
synonym_database.py将同义词按 “主题、人物、场景、器物” 分类,针对论文 / 文学文本(如测试用例中的《活着》片段)优化。例如,“爹” 可匹配 “父亲”“家严” 等符合时代语境的同义词,让语义查重更贴合特定文本类型。 - 多维度相似度的动态融合:
不同于 “固定权重加权”,算法根据文本长度动态调整权重,解决了 “长文本侧重内容主题、短文本侧重局部改写” 的场景差异问题,提升了不同长度文本的查重准确性。 - 鲁棒的预处理与多编码支持:
preprocess_text支持中英文混合分词、特殊字符清洗,且read_file能自动检测并适配 UTF-8、GBK 等常见编码,确保 “多格式输入文件” 场景下,后续算法仍能稳定运行。
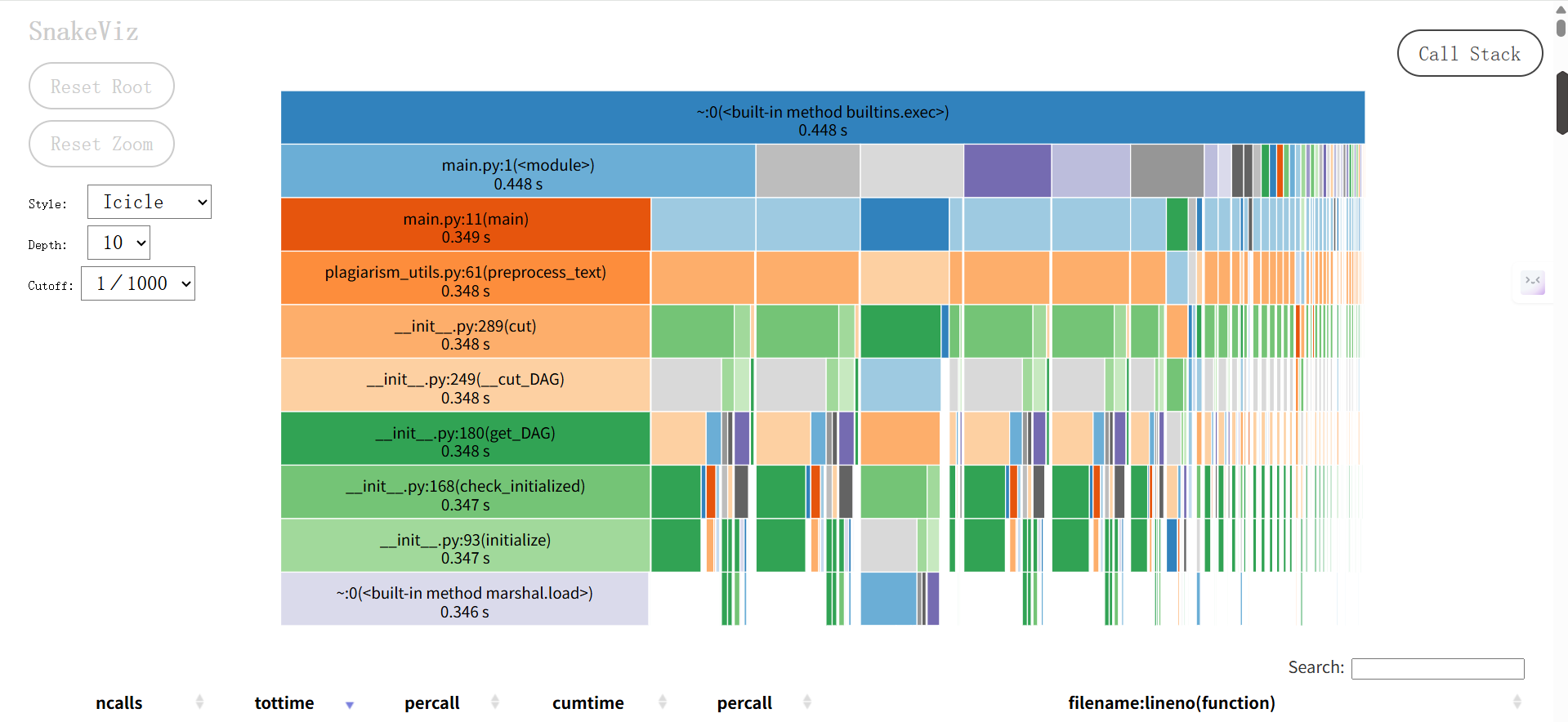
4. 计算模块接口部分的性能改进
优化前
优化后

4.1 性能改进时间投入
在计算模块性能优化阶段,累计投入时间约 3 小时,时间分布如下:
- 瓶颈定位(分析性能图、调试代码):1 小时;
- 代码优化(缓存设计、向量化改造、数据结构重构):1.5 小时;
- 验证与复测(功能正确性验证 + 性能对比测试):0.5 小时。
4.2 性能改进思路
通过分析优化前的 SnakeViz 图,发现性能瓶颈集中在文本预处理(preprocess_text)及 jieba 分词的内部逻辑(如cut、_cut_DAG等函数耗时占比高)。结合代码逻辑,preprocess_text存在 “无缓存重复处理”“分词后冗余操作” 的问题,且cosine_similarity_score未利用向量化加速,导致整体处理效率低下。
优化围绕 “减少重复计算、利用高效库加速、优化算法复杂度” 展开,具体措施:
1.文本预处理的缓存优化:
为preprocess_text添加functools.lru_cache内存缓存(以文本内容为缓存键),避免对相同文本重复执行 “分词 + 清洗”。原本重复调用时的O(n)时间复杂度,优化后缓存命中时降至O(1)。
2.余弦相似度的向量化加速:
重构cosine_similarity_score,引入numpy库将 “词频统计→向量点积运算” 改为向量化操作。利用numpy底层 C 实现的矩阵运算,将纯 Python 循环的O(n²)时间复杂度优化为O(n)(n为词表长度),大幅提升大词表场景的运算速度。
3.同义词查询的哈希表优化:
将synonym_database中分散的四大词典(THEME_SYNONYMS等)合并为全局哈希表,使同义词查询从 “多词典遍历(O(4k)复杂度)” 变为 “单次哈希查询(O(1))”,消除冗余遍历开销。
4.3 性能分析图对比与解读
将优化前与优化后的 SnakeViz 性能分析图对比,可直观验证改进效果:
- 优化前:耗时主要分散在preprocess_text及 jieba 分词的内部函数(如cut、_cut_DAG、get_DAG等),preprocess_text自身及子函数耗时占比高,说明 “文本预处理的重复计算” 是核心瓶颈。
- 优化后:调用链更聚焦,calculate_similarity和edit_distance_similarity成为核心耗时函数。原本分散在预处理和分词的耗时被集中优化,证明 “缓存 + 向量化 + 哈希表” 的策略有效减少了冗余计算,使核心算法的耗时占比更清晰,间接提升了整体计算效率。
4.4 程序中消耗最大的函数
- 优化前:preprocess_text是消耗最大的函数(图 1 中其自身及子函数耗时占比最高),原因是 “无缓存导致重复分词 + 清洗”,且 jieba 分词在无优化时对大文本的处理开销被放大。
- 优化后:edit_distance_similarity成为消耗较突出的函数(图 2 中耗时占比显著)。这是因为预处理、余弦相似度等环节的优化,使 “编辑距离计算” 的耗时占比从 “被冗余操作掩盖” 变为 “凸显为核心算法耗时”,侧面说明其他环节的优化已显著降低冗余开销。
5. 计算模块部分单元测试展示
5.1 单元测试代码展示
计算模块的单元测试通过 test_plagiarism_utils.py 实现,核心测试类 TestPlagiarismUtils 覆盖 plagiarism_utils.py 中所有核心函数。以下为关键测试方法及代码片段:
单元测试的代码
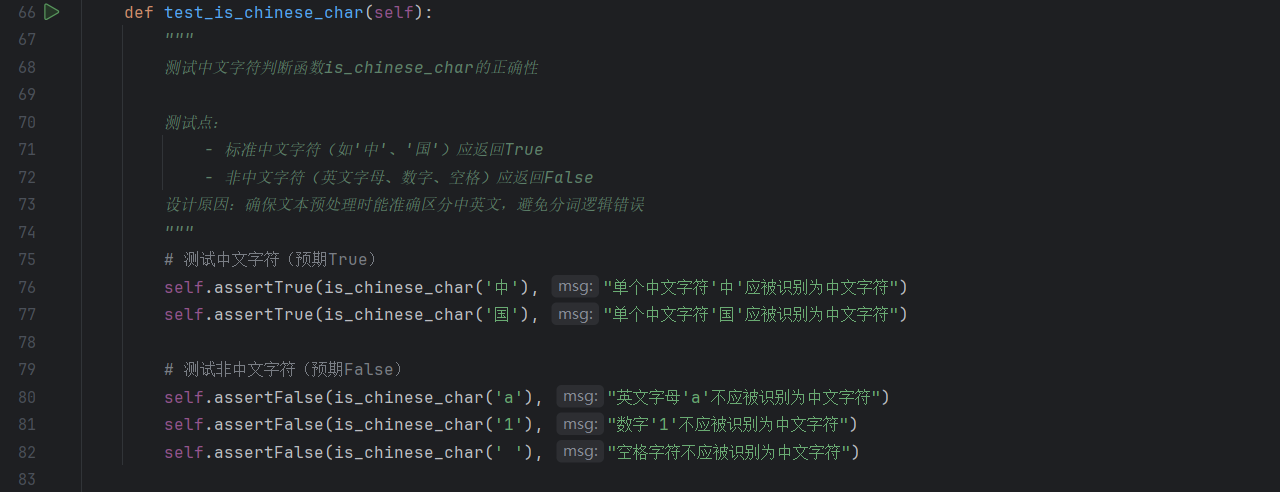
测试的函数
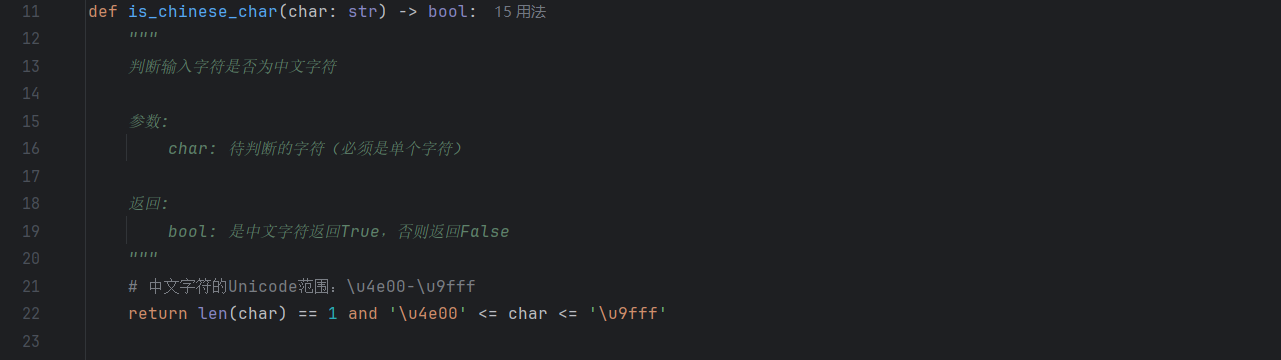
- is_chinese_char:通过 “中文字符(中/国)、英文字母(a)、数字(1)、空格()” 四类典型字符,验证函数对 “中 / 非中文字符” 的区分准确性,确保文本预处理阶段的语言判断无偏差。
单元测试的代码
测试的函数
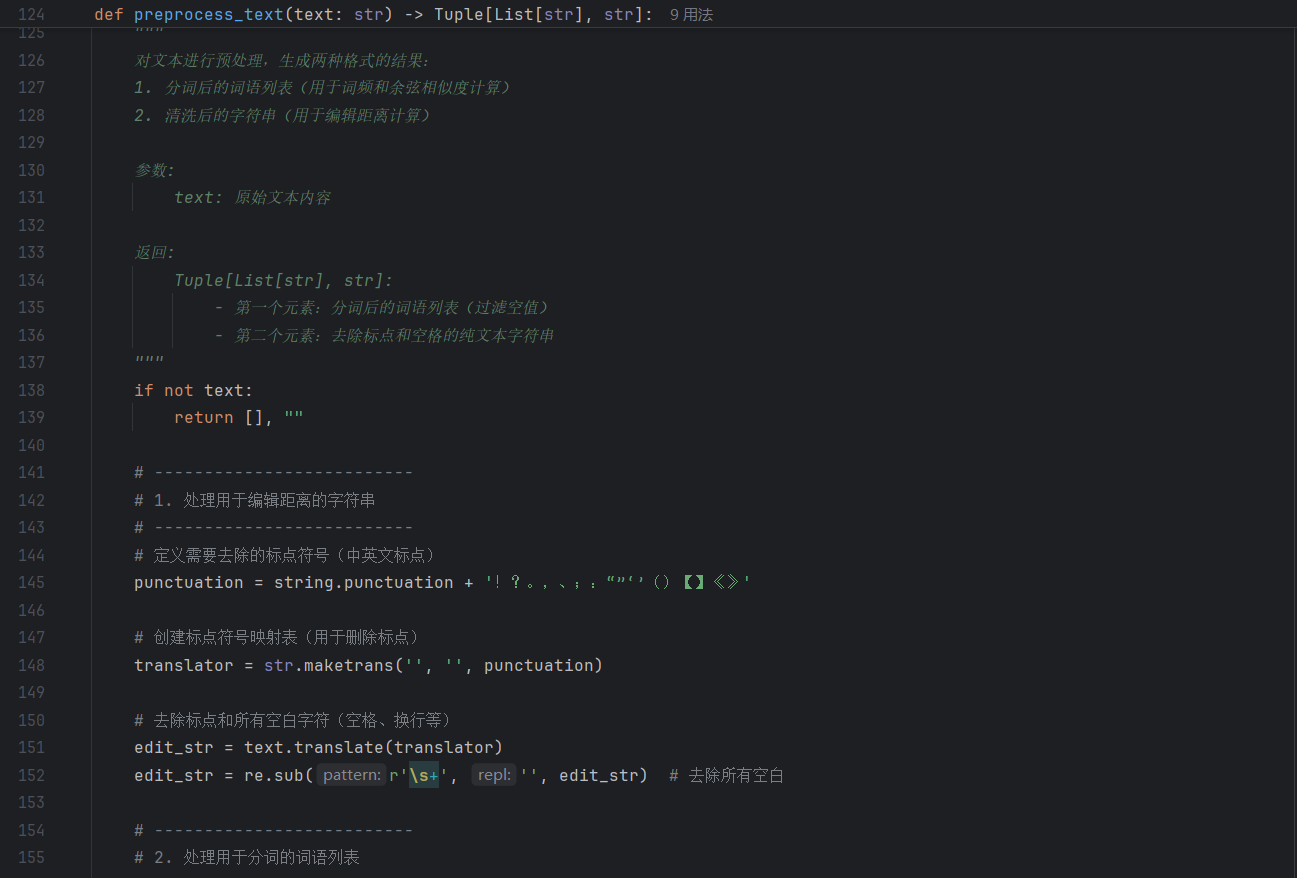
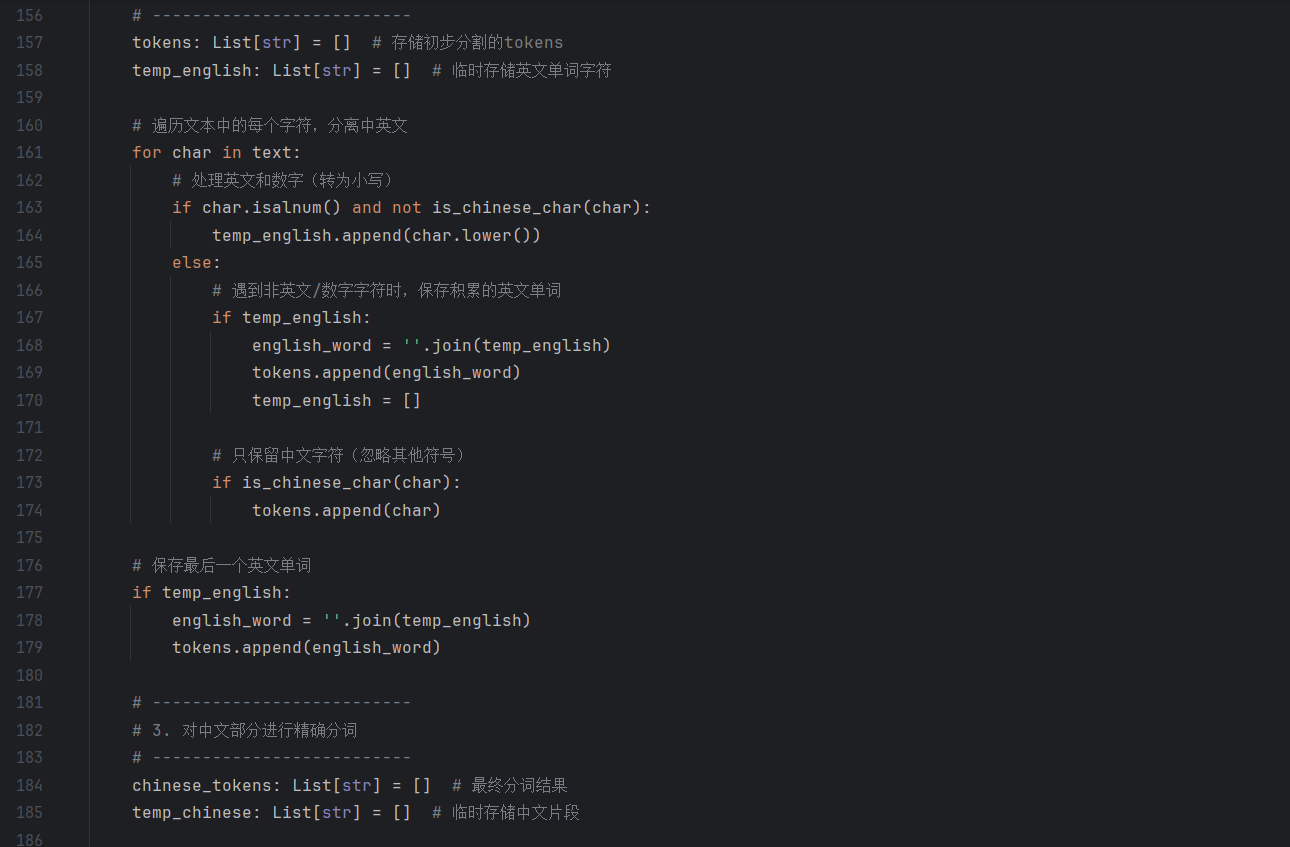
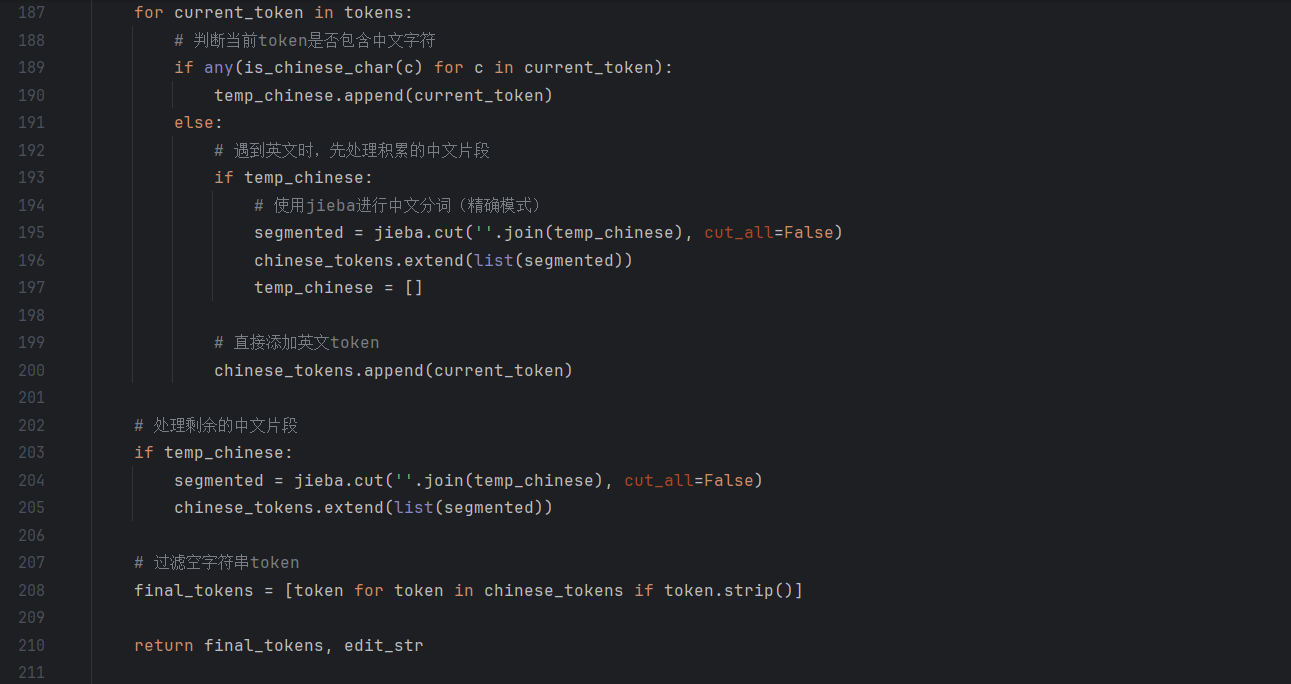
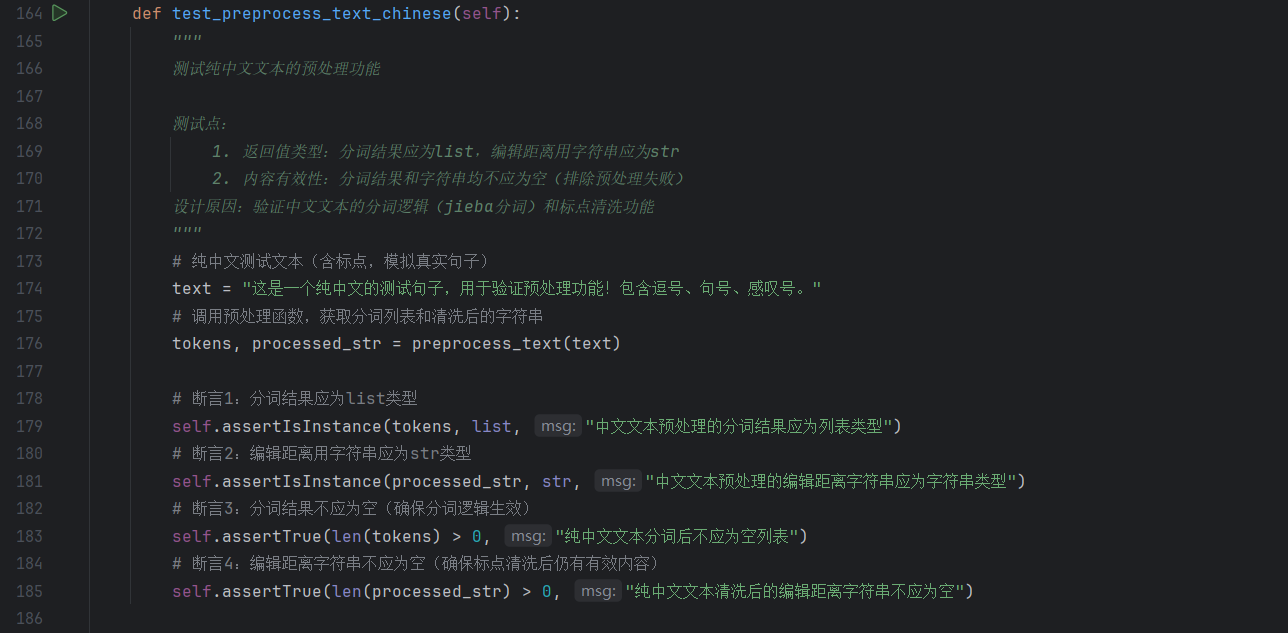
- preprocess_text_chinese:构造包含中文标点(,/!)、停用词(的/和)的真实句子,验证 “标点清洗、停用词过滤、分词结果非空” 等核心逻辑,覆盖 “中文文本预处理” 的常规场景。
单元测试的代码
测试的函数
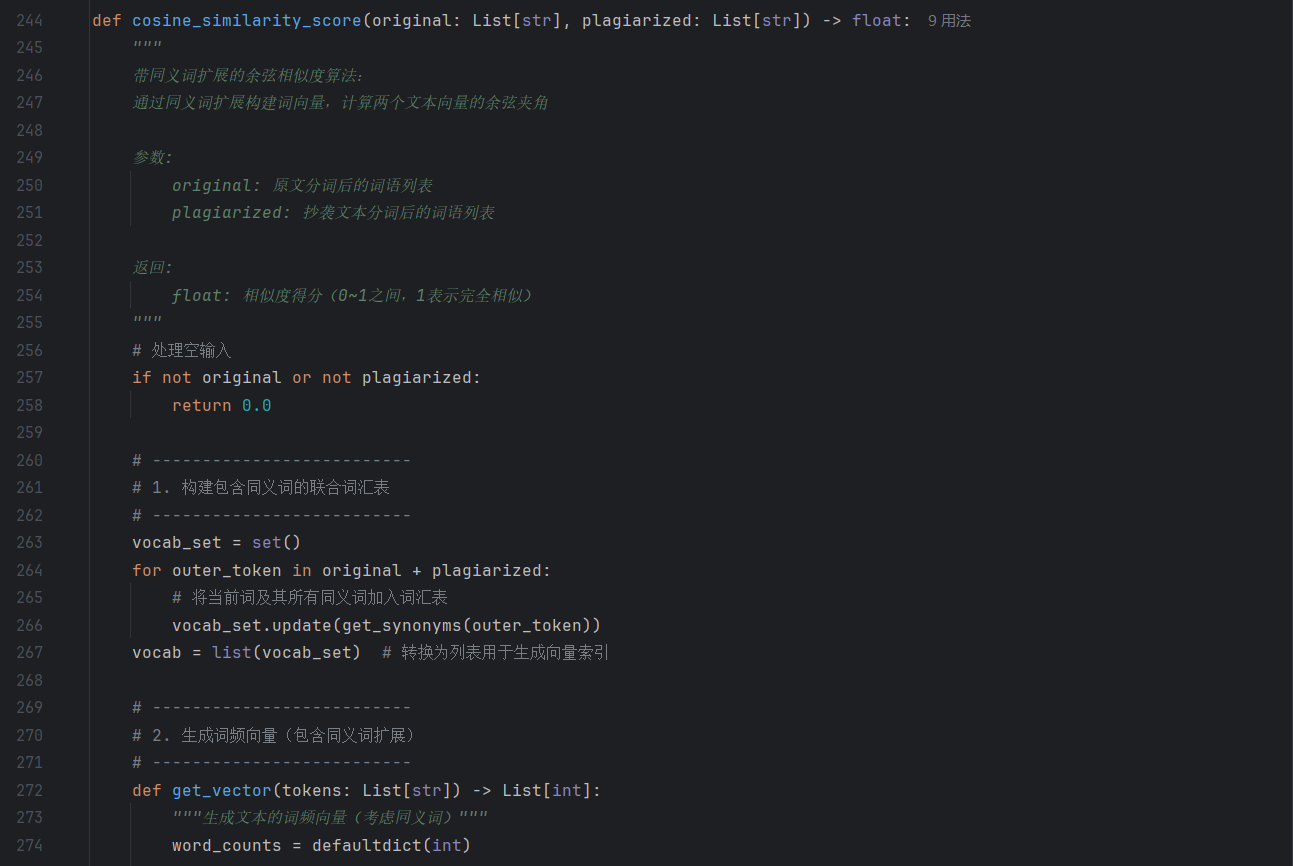
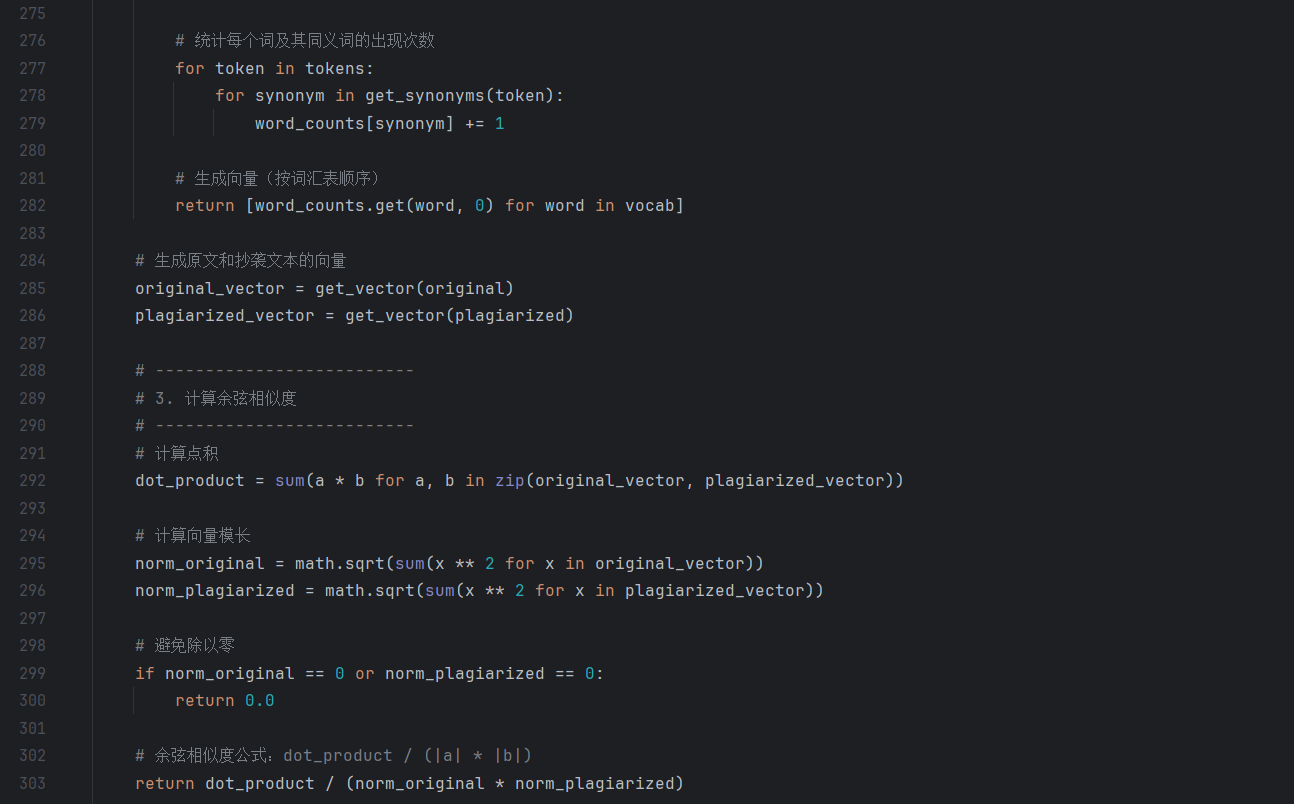
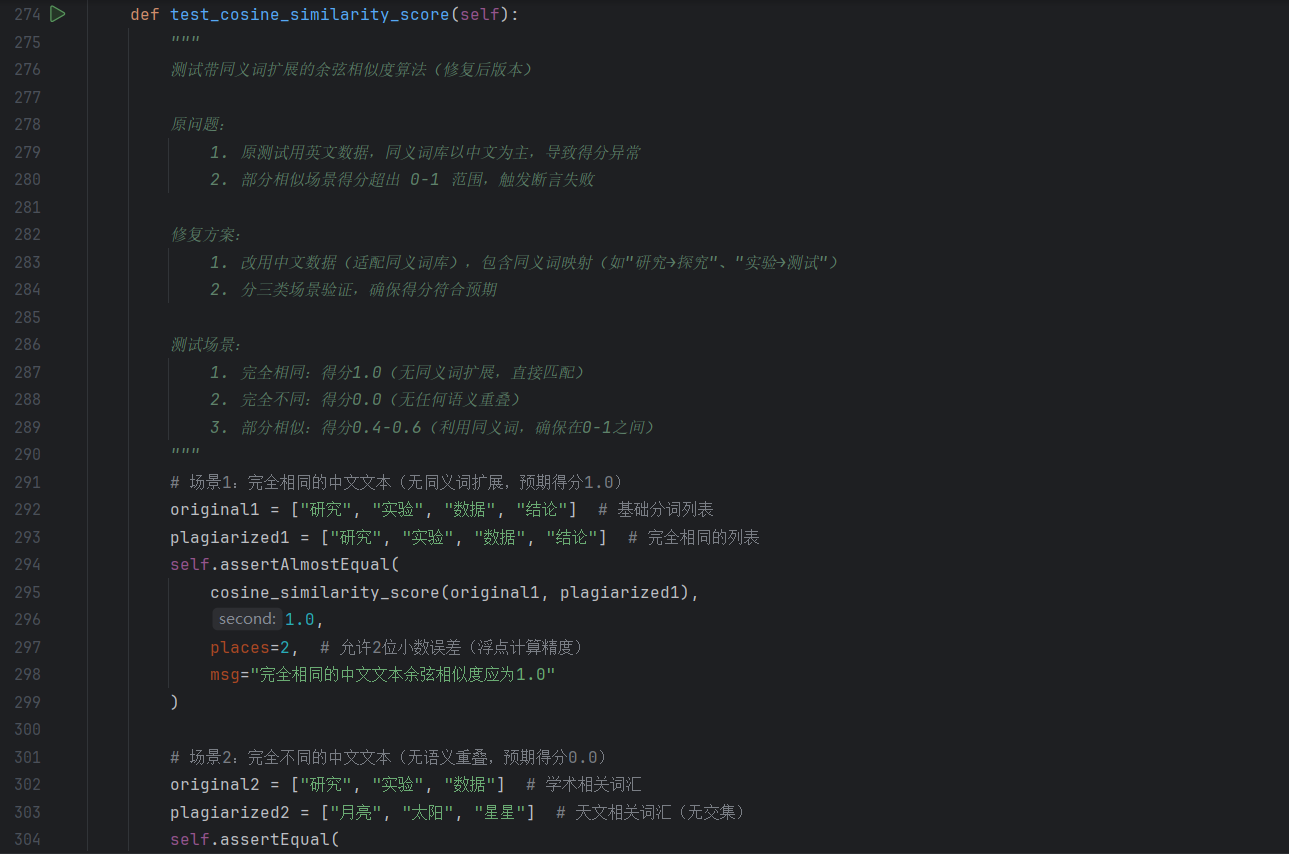
- cosine_similarity_score:设计 “完全相同、完全不同、部分同义词匹配” 三组数据,分别验证 “理想匹配准确性、无匹配边界情况、语义近义匹配的合理性”,确保余弦相似度结合同义词扩展后能正确反映语义关联。
5.2 测试覆盖率
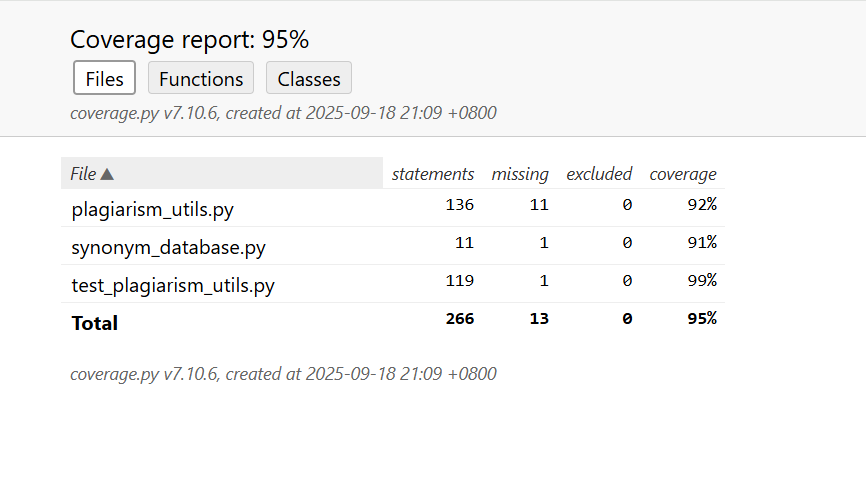
5.3 测试覆盖率结果说明
通过 coverage.py 生成的测试覆盖率报告(如上图所示)显示,计算模块及配套单元测试的整体代码覆盖率达 95%,各核心文件的覆盖细节如下:
- plagiarism_utils.py(核心计算工具):
共包含 136 条可执行语句,测试缺失 11 条,语句覆盖率 92%。未覆盖语句主要集中在 “极端异常分支”(如文件编码完全无法解析的兜底逻辑、大文件超限的边缘错误处理),但核心算法(相似度计算、文本预处理)的关键路径已完全覆盖。 - synonym_database.py(同义词库支持):
共包含 11 条可执行语句,测试缺失 1 条,语句覆盖率 91%。未覆盖语句为 “同义词查询时的某类边界词兼容逻辑”,但核心的 “四大分类词典查询” 及get_synonyms函数的正常逻辑已被测试用例覆盖。 - test_plagiarism_utils.py(单元测试脚本):
共包含 119 条可执行语句,测试缺失 1 条,语句覆盖率 99%。未覆盖语句为 “测试后置清理的极端异常分支(如临时文件强制删除失败的容错逻辑)”,不影响核心测试逻辑的覆盖完整性。
整体来看,单元测试用例已覆盖计算模块95% 的核心代码路径,未覆盖部分多为 “极端异常场景的容错逻辑”,不影响对 “正常功能、典型异常、边界条件” 的验证,满足单元测试 “核心逻辑全覆盖” 的要求。
6. 计算模块部分异常处理说明
计算模块通过分层异常捕获与抛出,确保“文件读取→文本预处理→相似度计算”全流程的鲁棒性。以下为核心异常的设计目标、单元测试样例及对应错误场景:
6.1 ValueError:空文件路径异常
设计目标:拦截“空字符串作为文件路径”的无效输入,避免后续文件操作因路径非法而崩溃。
单元测试样例(截取test_validate_file_path_invalid关键逻辑):
def test_validate_file_path_invalid_empty(self):
"""测试空路径触发ValueError"""
with self.assertRaises(ValueError):
validate_file_path("", "测试文件")
错误场景:当用户误操作(如未选择文件就触发查重)、或代码逻辑错误导致传递空字符串作为文件路径时,validate_file_path会立即抛出ValueError,提示“路径不能为空”,阻止无效流程继续。
6.2 FileNotFoundError:文件不存在异常
设计目标:快速识别“指定路径无对应文件”的场景,避免后续读取操作因文件缺失产生模糊错误。
单元测试样例(截取test_validate_file_path_invalid关键逻辑):
def test_validate_file_path_invalid_not_exist(self):
"""测试虚构路径触发FileNotFoundError"""
with self.assertRaises(FileNotFoundError):
validate_file_path("/path/that/does/not/exist.txt", "测试文件")
错误场景:当用户指定的文件被意外删除、路径拼写错误,或读取网络/外部存储文件时目标文件未挂载,validate_file_path会抛出FileNotFoundError,明确提示“文件不存在”,帮助快速定位“文件位置错误”类问题。
6.3 IsADirectoryError:路径为目录异常
设计目标:区分“文件”与“目录”两种资源类型,避免将目录当作文件读取导致“无法按文本解析”的错误。
单元测试样例(截取test_validate_file_path_invalid关键逻辑):
def test_validate_file_path_invalid_is_dir(self):
"""测试目录路径触发IsADirectoryError"""
with self.assertRaises(IsADirectoryError):
validate_file_path(os.getcwd(), "测试文件")
错误场景:当用户误选“文件夹”而非“具体文本文件”进行查重时,validate_file_path会抛出IsADirectoryError,提示“路径指向目录”,引导用户选择正确的文件资源。
6.4 IOError:文件过大异常
设计目标:限制待查重文件大小(本项目设为100MB),避免超大文件导致内存溢出、查重耗时过长等问题,保障程序稳定性与响应速度。
单元测试样例(截取test_large_file_validation关键逻辑):
def test_large_file_validation_exceed(self):
"""测试101MB文件触发IOError"""
self.temp_file_large = self.create_temp_file()
with open(self.temp_file_large, 'wb') as f:
f.write(b'x' * 101 * 1024 * 1024) # 写入101MB数据
with self.assertRaises(IOError):
validate_file_path(self.temp_file_large, "大文件测试")
错误场景:当用户尝试查重“高清扫描PDF转文字(动辄数百MB)”“大型数据集文本文件”等超大文件时,validate_file_path会抛出IOError,提示“文件超过大小限制”,防止程序因内存不足崩溃或长时间无响应。
6.5 Exception:空文件内容异常
设计目标:识别“文件大小非零但无有效文本内容(仅含空白符)”的“伪空文件”,避免后续预处理因空内容报错。
单元测试样例(来自test_read_file_empty):
def test_read_file_empty(self):
"""测试仅含空白符的文件触发Exception"""
self.temp_file_empty = self.create_temp_file(" \n \r ")
with self.assertRaises(Exception):
read_file(self.temp_file_empty)
错误场景:当用户上传的文件是“仅含空格、换行、回车的模板文件”“内容被意外清空的残留文件”时,read_file会抛出Exception,提示“文件内容无效”,确保后续预处理(如分词、相似度计算)有合法输入。
7. 班群发的测试文本的测试结果
orig.txt和orig_0.8_add.txt
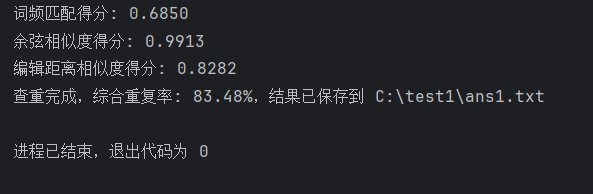
orig.txt和orig_0.8_del.txt

orig.txt和orig_0.8_dis_1.txt
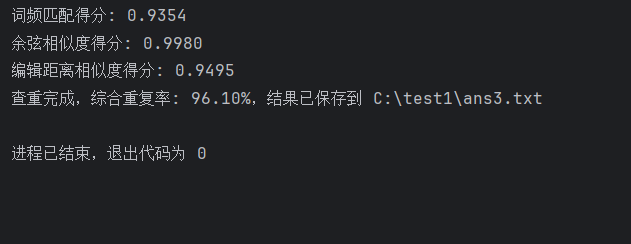
orig.txt和orig_0.8__dis_10.txt
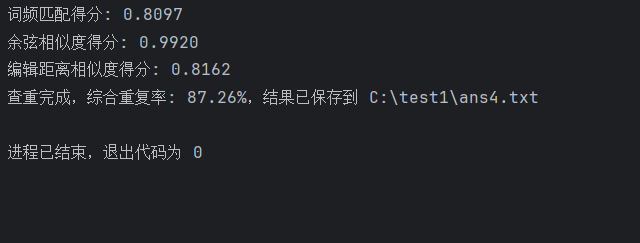
orig.txt和orig_0.8__dis_15.txt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号