


Kmeans算法
1、概述
该方法属于无监督学习算法(无y值)。根据已有的数据,利用距离远近的思想将目标数据集聚为指定的k个簇。簇内样本越相似,聚类的效果越好。需要注意的是如若数据存在量纲上的差异,必须先进行标签化处理。或者数据集中含有离散型字符变量,需先设置成哑变量或进行数值化。对于未知簇个数的数据集,需要先确定簇数,再进行聚类操作。
应用方面常用在聚类模型中。比如电商平台历史交易数据,划分不同的价值等级(如VIP,高价值,潜在价值,低价值)等等,还可用于异常值的监控(远离任何簇的异常点),如(信用卡交易异常,社交平台点击异常(如遇爬虫脚本),电商网站交易异常(一张银行卡被用于多个Id支付,送货地址大致集中在相近区域))
2、过程
- 任选k个对象作为初始簇的中心
- 计算各对象到初始簇的中心的距离,重新划分簇
- 计算各个簇的均值,为新的簇中心
- 再次计算各对象到新的簇中心的距离,重新划分簇,然后再重新计算均值,划分簇,repeat...until 新簇(簇中心)不在发生变化。
3、缺点
- 结果容易受异常值(离群点)影响。(中心点通过样本均值确定)
- 该方法不适合样本中非球形的簇。
4、实现Kmeans聚类方式
- 原始代码的方式
- sklean
模拟kmeans实现案例:
数据集:

手动模拟 实现过程:

代码实现:
import numpy as np
def kmeans(X, k, maxIt): # X数据集矩阵,maxIt为最多迭代的次数
numPoints, numDim = X.shape
dataSet = np.zeros((numPoints, numDim + 1))
dataSet[:,:-1] = X
# centroids = dataSet[np.random.randint(numPoints, size = k), :] # 随机选2行作为初始簇中心点
centroids = dataSet[0:2,:] # 选择1、2行作为初始簇中心
centroids[:,-1] = range(1,k+1) #划分簇类别
iterations = 0
OldCentriods = None
while not shouldStop(OldCentriods, centroids, iterations, maxIt):
print("iteration:\n", iterations)
print("dataSet:\n", dataSet)
print("centroids:\n", centroids)
OldCentriods = np.copy(centroids)
iterations +=1
updateLabels(dataSet, centroids) # 对中心点和数据集重新归类
centroids = getCentroids(dataSet, k) # 根据均值生成新中心点
return dataSet
def shouldStop(OldCentriods, centroids , iterations , maxIt):
if iterations > maxIt:
return True
return np.array_equal(OldCentriods,centroids)
def updateLabels(dataSet, centroids):
numPoints , numDim = dataSet.shape
for i in range(0, numPoints):
dataSet[i, -1] = getLabelFromClosestCentroid(dataSet[i, :-1], centroids)
# 遍历数据中的每个对象,每个对象跟2个中心点距离比较以后,获取新的label将数据集中的对象label更新
def getLabelFromClosestCentroid(dataSetRow, centroids):
label = centroids[0,-1]
minDist = np.linalg.norm(dataSetRow - centroids[0, :-1])
for i in range(1, centroids.shape[0]):
dist = np.linalg.norm(dataSetRow - centroids[i, :-1])
if dist < minDist:
minDist = dist
label = centroids[i,-1]
print('minDist', minDist)
return label
# 求均值中心点
def getCentroids(dataSet, k):
result = np.zeros((k, dataSet.shape[1]))
for i in range(1,1+k):
oneCluster = dataSet[dataSet[:,-1] ==i , :-1]
result[i-1,:-1] = np.mean(oneCluster,axis = 0)
result[i-1,-1] = i
return result
x1 = np.array([1,1])
x2 = np.array([2,1])
x3 = np.array([4,3])
x4 = np.array([5,4])
testX = np.vstack((x1,x2,x3,x4))
result = kmeans(testX,2, 10)
print('final result:' ,result)
结果迭代2次,打印结果与以上一致。

若改变数据集为10个点
A1 = np.array([0.5,2]) A2 = np.array([0.8,3]) A3 = np.array([1.2,0.6]) A4 = np.array([1.6,2.2]) A5 = np.array([2.4,3.6]) A6 = np.array([2.5,2.8]) B1 = np.array([2.2,1.8]) B2 = np.array([3,2.5]) B3 = np.array([2.8,1.6]) B4 = np.array([4,1])
以上代码会生成不同的聚类效果:


取k=3时结果:

5、k值的确定方法
常采用探索法确定k值:给定不同的k值,对比某些评估指标的变动情况。进而选择合理的k值。常用方法如下
- 簇内离差平方和拐点法
- 轮廓系数法
- 间隔统计量法
1)拐点法
使用sclearn子模块cluster中KMeans类,思路是使簇内离差平方和总和最小。(随着簇的增加,离差平方和之和趋于稳定(波动小于阀值),可以通过绘制各簇离差平方和之和与簇的个数之间的折线图,观察k值拐点变化的位置(斜率变化的点)。
离差反映的是变量与数学期望偏离的程度,集x-E(x),其平方和为:
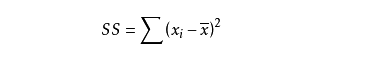
实现函数:
def k_SSE(X, clusters):
K = range(1, clusters+1) # 设定簇k的取值范围
TSSE = [] # 存储总的簇内离差平方和
for k in K :
SSE = [] # 存储各个簇内离差平方和
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
labels = kmeans.labels_ # 返回簇标签
centers = kmeans.cluster_centers_ # 返回簇中心
for label in set(labels):
SSE.append(np.sum((X.loc[labels == label,]-centers[label,:])**2)) # 计算个簇内离差平方和并存于列表SSE
TSSE.append(np.sum(SSE)) # 计算k值下总离差平方和
plt.style.use('ggplot')
plt.plot(K,TSSE,'b*-')
plt.xlabel('簇的个数')
plt.ylabel('簇内离差平方和之和')
plt.show()
X = pd.DataFrame(np.concatenate([ np.array([x1,y1]),np.array([x2,y2]),np.array([x3,y3])],axis = 1).T)
k_SSE(X,15)
用此方法验证一下上面10个数据集的最佳k值如下:
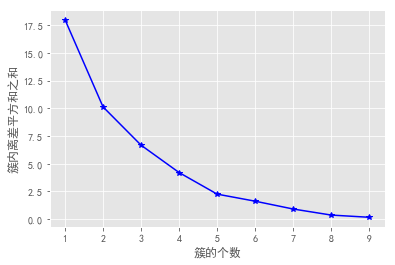
从图中可以发现k为2时图线斜率明显变化,且变化最大,所以取最佳k值为2。
2)轮廓系数法
使用的是sklearn子模块metrics中的silhouette_score函数,该方法要求簇的个数大于等于2(k>=2),轮廓系数计算公式如下:
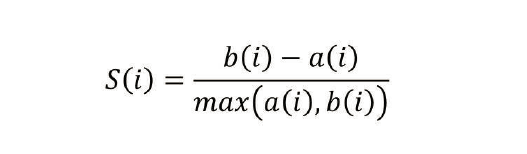
s(i)为轮廓系数,a(i)为样本i与其簇内其他样本距离的平均值。反应了簇内的密集性。b(i)为样本i与其他每个簇簇内距离的平均值的最小值。
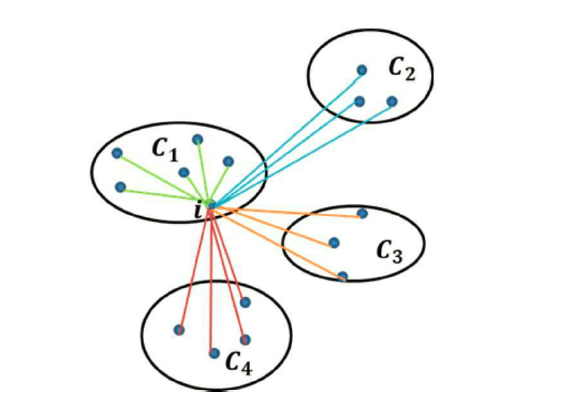
如图表示的i与C1中其他样本点距离的平均值为a(i),i分别与C2、C3、C4各自簇内样本点距离的平均值m1,m2,m3,比较3个值取最小值mx为b(i)。
s(i)的大小:s(i)值越接近-1,说明i分配不合理,聚类效果不佳,轮廓系数接近0说明i落在了模糊地带,可能在簇的边界处。轮廓系数接近1说明i的分配是合理的,聚类效果不错。
实现函数:
from sklearn import metrics
def k_silhouette(X , clusters):
K = range(2, clusters+1)
S = [] # 空列表用于存放不同簇下的轮廓系数
for k in K:
kmeans = KMeans(n_clusters = k)
kmeans.fit(X)
labels = kmeans.labels_
S.append(metrics.silhouette_score(X,labels, metric = 'euclidean')) #调用子模块metrics中函数计算轮廓系数
plt.style.use('ggplot')
plt.plot(K, S, 'b*-')
plt.xlabel('簇的个数')
plt.ylabel('轮廓系数')
plt.show()
k_silhouette(X,9)
图形:
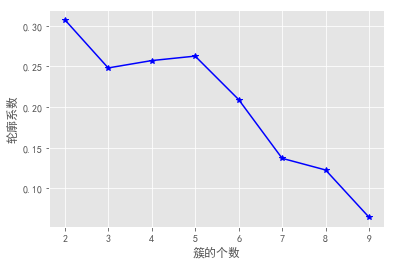
还是以上10个数据集,可见k=2时,轮廓系数大于0,且最接近1,所以k=2时分类效果最好。
3)间隔统计量法 (Gap Statistic)
公式:
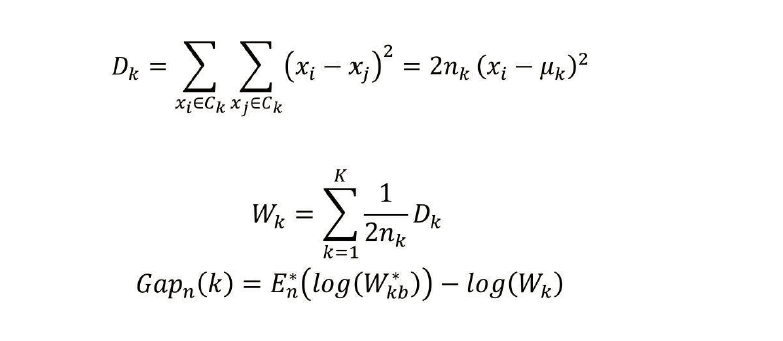
各参数Dk:簇内样本点之间的欧式距离
nk为第k个簇内的样本量。uk为第k个簇内的样本均值,Wk为Dk的标准化结果。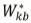 为参照组数据集的Wk向量。
为参照组数据集的Wk向量。
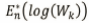 的值为
的值为![]() ,通过参照数据集的数学期望与实际数据集的对数的差比较,找到实际数据集下降最快的k值。
,通过参照数据集的数学期望与实际数据集的对数的差比较,找到实际数据集下降最快的k值。
首次出现Gap(k)≥Gap(k+1)-sk+1时的k值即为最佳k值。
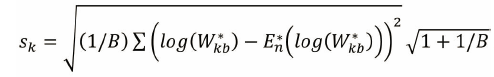
案例:
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn import metrics from pylab import * mpl.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False # 随机生成三组二元正态分布随机数 np.random.seed(1234) mean1 = [0.5, 0.5] cov1 = [[0.3, 0], [0, 0.3]] x1, y1 = np.random.multivariate_normal(mean1, cov1, 1000).T mean2 = [0, 8] cov2 = [[1.5, 0], [0, 1]] x2, y2 = np.random.multivariate_normal(mean2, cov2, 1000).T mean3 = [8, 4] cov3 = [[1.5, 0], [0, 1]] x3, y3 = np.random.multivariate_normal(mean3, cov3, 1000).T plt.scatter(x1,y1) plt.scatter(x2,y2) plt.scatter(x3,y3) plt.show() # 构建数据集 X = pd.DataFrame(np.concatenate([np.array([x1,y1]),np.array([x2,y2]),np.array([x3,y3])], axis = 1).T) # 自定义函数,计算簇内任意两样本之间的欧氏距离 def short_pair_wise_D(each_cluster): mu = each_cluster.mean(axis = 0) Dk = sum(sum((each_cluster - mu)**2)) * 2.0 * each_cluster.shape[0] return Dk # 计算簇内的Wk值 def compute_Wk(data, classfication_result): Wk = 0 label_set = set(classfication_result) # 过滤所有数据集标签值中的相同项,比如2个簇过滤后为{0,1},10个簇为{0,1,...9} for label in label_set: each_cluster = data[classfication_result == label, :] # 数据集中等于标签值如1的那些值 Wk = Wk + short_pair_wise_D(each_cluster)/(2.0*each_cluster.shape[0]) # Dk标准化 return Wk # 计算GAP统计量 def gap_statistic(X, B=10, K=range(1,11), N_init = 10): X = np.array(X) # 将输入数据集转换为数组 shape = X.shape tops = X.max(axis=0) # 列方向求最大值 bots = X.min(axis=0) dists = np.matrix(np.diag(tops-bots)) # 以每列最大值减最小值的值作为对角线元素其他元素为0组成矩阵 rands = np.random.random_sample(size=(B,shape[0],shape[1])) # 生成3维随机数数组 # 建立参照矩阵 for i in range(B): rands[i,:,:] = rands[i,:,:]*dists+bots # 对随机矩阵机右乘对角矩阵(对应列乘以对角矩阵对角线上对应值),再加最小值 gaps = np.zeros(len(K)) Wks = np.zeros(len(K)) Wkbs = np.zeros((len(K),B)) for idxk, k in enumerate(K): # 循环不同的k值,1~k个簇求Kmeans k_means = KMeans(n_clusters=k) k_means.fit(X) classfication_result = k_means.labels_ # 对应于不同簇值(k)的每个对象的标签值集合 Wks[idxk] = compute_Wk(X, classfication_result) # 存储wk值 for i in range(B): # 计算每一个参照数据集下的各簇Wk值 Xb = rands[i,:,:] k_means.fit(Xb) classfication_result_b = k_means.labels_ Wkbs[idxk,i] = compute_Wk(Xb,classfication_result_b) gaps = (np.log(Wkbs)).mean(axis = 1) - np.log(Wks) sd_ks = np.std(np.log(Wkbs), axis=1) sk = sd_ks*np.sqrt(1+1.0/B) # sk为参照组数据集的无偏标准差 gapDiff = gaps[:-1] - gaps[1:] + sk[1:] # 用于判别最佳k的标准,当gapDiff首次为正时,对应的k即为目标值 plt.style.use('ggplot') plt.bar(np.arange(len(gapDiff))+1, gapDiff, color = 'steelblue') plt.xlabel('簇的个数') plt.ylabel('k的选择标准') plt.show() gap_statistic(X)
图形效果如下:
1)散点图

2)k值-gapdiff趋势图
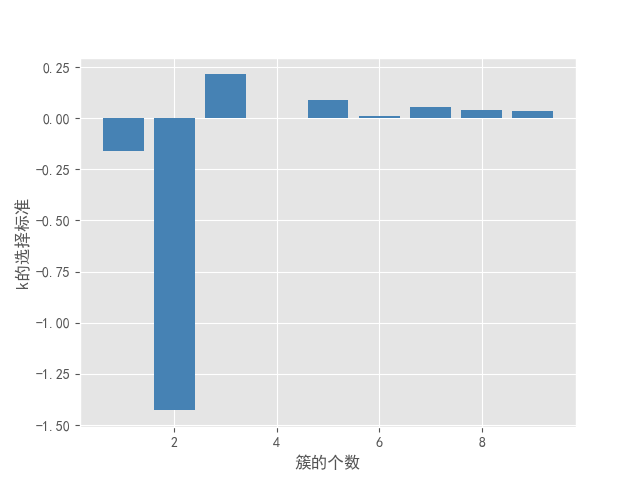
结果可以看出k=3时,条件Gap(k)-Gap(k+1)-sk+1的值首次大于0,固最佳k值取3。注意样本数据量太小时,此方法结果可能存在一定的问题。可以其他2种方法比较确定最佳k值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号