


本节内容
- 1.文件操作
- 1.对文件操作流程
- 2.基本操作
- 3.打开文件的模式
- 4.with语句
- 5.其他语法
- 6.Python中文件路径写法
- 2.字符编码与转码
- 1.简介
- 2.默认编码
- 3.其他介绍
- 3.函数
- 1.函数基本语法及特性
- 2.递归
- 3.函数式编程
- 4.高阶函数
- 5.匿名函数
一、文件操作
1、对文件操作流程
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作
- 关闭文件
2、基本操作
f = open('lyrics') #打开文件当前文件夹下lyrics,默认打开方式r
first_line = f.readline()
print('first line:',first_line) #读一行
print('我是分隔线'.center(50,'-'))
data = f.read()# 读取剩下的所有内容,文件大时不要用
print(data) #打印文件
f.close() #关闭文件
3、打开文件的模式
(1) 基本模式
- r,只读模式(默认)
- w,只写模式(不可读:不存在则创建,存在则删除内容。)
- a,追加模式(可读:不存在则创建,存在则只追加内容。)
(2) "+" 表示可以同时读写某个文件
- r+,可读写文件(可读、可写、可追加)
- w+,写读
- a+,同a
(3) "U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
- rU
- r+U
(4) "b"表示处理二进制文件
如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注
- rb
- wb
- ab
4、with语句
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
with open('log','r') as f:
pass
#如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
with open('log1') as obj1, open('log2') as obj2:
pass
5、其他语法
f = open('yesterday','r',encoding='utf-8') #文件句柄
print(f.buffer)
f.flush() #强制刷新,即使内存中数据存入硬盘。默认是当buffer满了才会...
#文件指针操作
print(f.tell()) #文件读指针所在位置,按照读取的字符数计数
print(f.readline()) #读取文件中一行数据
print(f.tell())
print(f.readline())
print(f.readline())
f.seek(72) #使文件读指针返回该位置
print(f.readline())
#使用迭代器(内存中只存一行数据,推荐的方式)
count = 0
for line in f:
if count == 9:
print('9,我是分割线'.center(20,'-'))
else:
print(count,line.strip())
count += 1
#补充
f.read(4) #从文件读指针开始读4个字符
print(f.encoding) #获取文件的编码
print(f.fileno()) #文件句柄在内存中的编号
f.flush() #强制使内存中数据存入硬盘,默认buffer满了才会写
f.truncate(10) #从文件开始保留10个字符截断(10个字符以后的删除)
注:Python写文件只能覆盖(w)或者追加(a)
6、Python中文件路径写法
# \在字符串中被当做转义字符 'd:\\a.txt' #转义的方式 r'd:\a.txt' #声明字符串不需要转义 'd:/a.txt' #使用/
二、字符编码与转码
1、简介
转码过程如下图所示:
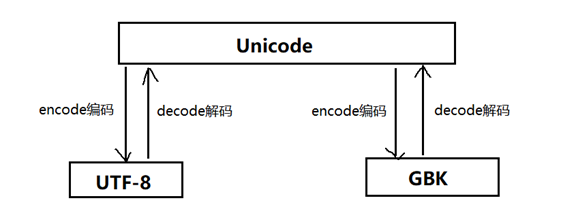
Unicode格式的代码可以在uft-8编码格式中正常显示。
encode()会将内容转换成相应编码格式的二进制形式,需要decode()才能显示中文。
2、Python默认编码
- Python2 -> ASCII
- Python3 -> Unicode(非utf-8)
3、其他介绍
参考:http://www.cnblogs.com/alex3714/articles/5717620.html
三、函数
1、函数基本语法及特性
(1) 编程方法
- 面向对象 -> 类 -> class
- 面向过程 -> 过程 -> def(没有返回值)
- 函数式编程 -> 函数 -> def(有返回值)
编程语言中函数定义:函数是逻辑结构化和过程化的一种编程方法
(2) 使用函数优点
- 代码重用
- 保持一致性
- 可扩展性
(3) 定义方法
def fun1(): #def定义函数关键字,fun1函数名,()内可定义形参
"""My first function""" #文档描述(强烈建议添加)
print('My first function') #代码块或程序处理逻辑
return 0 #返回值,代表函数结束
(4) 函数的调用
#定义函数
def test(x,y): #x,y为形参
print(x)
print(y)
#调用(关键字参数不能写在位置参数之前)
test(1,2) #位置参数调用(1,2为实参,与形参一一对应)
test(y=2,x=1) #关键字调用(与形参顺序无关)
#默认参数
def test1(x,y=2): #调用函数时传了y值就使用,否则使用默认值
print(x)
print(y)
#多个实参
def test2(*args): #接收n个位置参数转换成元组
print(args)
def test3(**kwargs): #接收n个关键字参数转换成字典
print(kwargs)
test2(1,2,3,4) #结果(1,2,3,4)
test3(name='alise',age=8) #结果{'name': 'alise', 'age': 8}
(5) 局部变量
在子程序中定义的变量。只在函数里生效,该函数就是这个变量的作用域。
def change_name(name):
print('before change>>>',name)
name = 'HQ' #局部变量,只在函数里生效(这个函数就是这个变量的作用域)
print('after change>>>',name)
name = 'alise'
change_name(name)
print('name>>>',name)
#结果
'''''
before change>>> alise
after change>>> HQ
name>>> alise
'''
(6) 全局变量
在脚本顶级定义的变量,作用域是整个程序。全局变量应该在脚本顶级显式定义,不能使用global定义全局变量。
在局部可以修改除数字、字符串之外类型的数据。
def change_name(name1):
print('before change>>>',name1)
global name #修改全局变量需要声明(慎用),容易造成不应该改的全局变量被改掉
name = 'HQ' #局部变量,只在函数里生效(这个函数就是这个变量的作用域)
print('after change>>>',name1)
name = 'alise'
change_name(name)
print('name>>>',name)
#结果
'''
before change>>> alise
after change>>> alise
name>>> HQ
#注:当全局变量和局部变量同名时,在定义局部变量的子程序内,局部变量起作用,在其他地方全 局变量起作用。
2、递归
递归:在函数内部,可以调用其他函数。如果一个函数在内部调用自己本身,这个函数就是递归函数。
(1) 特性
- 必须有一个明确的结束条件。
- 每次进入更深一层递归时,问题规模相比上次递归都应有所减少。
- 递归效率不高,递归层次过多会导致栈溢出。
(2) 示例
def calc(n):
print(n)
if int(n/2) >0: #明确的结束条件
return calc( int(n/2) ) #进入更深一层递归时,问题规模相比上次递归有所减少
print("->",n)
calc(10)
3、函数式编程
- 特点:输入是确定的,输出就是确定的(Python做了部分支持)。
- 是一种编程范式,也就是如何编写程序的方法论。
- 主要思想是把运算过程尽量写成一系列嵌套的函数调用。
4、高阶函数
变量可以指向函数(即,函数的结果可以赋值给一个变量),函数的参数能接收变量。
(1) 什么是高阶函数
- 一个函数接收另一个函数的函数名作为参数
- 返回值中包含函数名
(2) 示例
def add(a,b,f): #f为函数名的形参
return f(a)+f(b) #返回值中包含函数名
res = add(3,-6,abs) #函数名abs作为参数传给add函数(abs是Python中一个求绝对值的内置方法)
print(res)
#结果
'''
9
'''
5、匿名函数
lambda ['læmdə] 匿名函数
没有函数名,只支持三元运算
calc = lambda x:x*3 print(calc(3))
参考:
http://www.cnblogs.com/alex3714/articles/5717620.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号