

哈夫曼编码实践
哈夫曼编码实践
实验内容
- 哈夫曼编码实践
- 设有字符集:S={a,b,c,d,e,f,g,h,i,j,k,l,m,n.o.p.q,r,s,t,u,v,w,x,y,z}。
- 给定一个包含26个英文字母的文件,统计每个字符出现的概率,根据计算的概率构造一颗哈夫曼树。
- 并完成对英文文件的编码和解码。
- 要求:
(1)准备一个包含26个英文字母的英文文件(可以不包含标点符号等),统计各个字符的概率
(2)构造哈夫曼树
(3)对英文文件进行编码,输出一个编码后的文件
(4)对编码文件进行解码,输出一个解码后的文件
实验过程及结果
1.设有字符集:S={a,b,c,d,e,f,g,h,i,j,k,l,m,n.o.p.q,r,s,t,u,v,w,x,y,z},给定一个包含26个英文字母的文件,统计每个字符出现的概率。
- 首先,初始化一个含有二十六个字母的字符型数组,a对应的下标为0,以此类推。
- 然后,定义一个容量为26的double型数组,用于统计每个字母的出现次数及概率,注意下标的对应关系,并初始化数组。
char[] S = new char[]{'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z'};
double[] sum = new double[26];
int count = 0;
for (int i = 0; i < 26; i++) {
sum[i] = 0;
}
- 读取文件内容,将内容存储在一个字符串中,然后将其转化为字符型数组,再用两个for循环统计26个字母出现的次数及概率。
File file = new File("D:\\test", "HelloWorld.txt");
Reader reader2 = new FileReader(file);
String result = "";
while (reader2.ready()) {
result += (char) reader2.read();
}
char[] text = result.toCharArray();
for (int j = 0; j < text.length; j++) {
for (int k = 0; k < S.length; k++) {
if (text[j] == S[k] || text[j] == (S[k] - 32)) {
sum[k]++;
count++;
}
}
}
for (int i = 0; i < sum.length; i++) {
sum[i] = sum[i] / count;
}
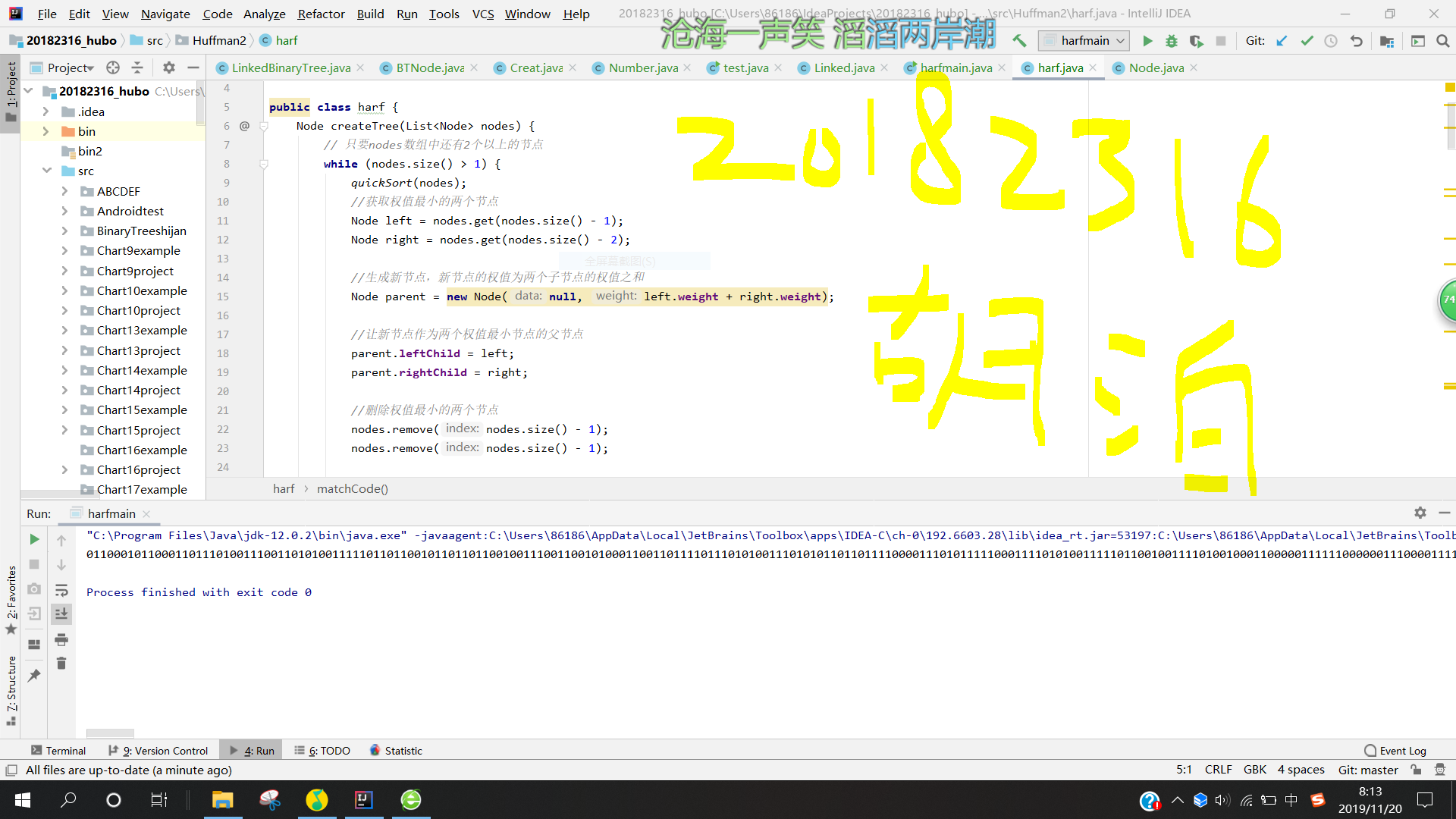
2.根据计算的概率构造一颗哈夫曼树
harf h = new harf();
Node root = h.createTree(nodes);
h.setCode(root);
- 调用的方法为:
public class harf {
Node createTree(List<Node> nodes) {
// 只要nodes数组中还有2个以上的节点
while (nodes.size() > 1) {
quickSort(nodes);
//获取权值最小的两个节点
Node left = nodes.get(nodes.size() - 1);
Node right = nodes.get(nodes.size() - 2);
//生成新节点,新节点的权值为两个子节点的权值之和
Node parent = new Node(null, left.weight + right.weight);
//让新节点作为两个权值最小节点的父节点
parent.leftChild = left;
parent.rightChild = right;
//删除权值最小的两个节点
nodes.remove(nodes.size() - 1);
nodes.remove(nodes.size() - 1);
//将新节点加入到集合中
nodes.add(parent);
}
return nodes.get(0);
}
- 上面的这个步骤是输入一个node型的数组,然后将其排序,将两个最小的组成一个三节点的二叉树,再将其放回数组中,删除两个最小的,重复上述步骤,直到数组里只剩下一个元素,循环结束,哈夫曼树就构造好了。
3.对英文文件进行编码,输出一个编码后的文件。
- 对文件进行编码,其实就是将每个字母用01代码表示,然后全部输入到文件中。
- 而每个字母的01代码由从根节点到对应结点的路径决定,进入到左子树就加‘0’,进入右子树就加’1‘,因此我用了递归来实现:
public void setCode(Node root) {
if (root.leftChild != null) {
root.leftChild.code = root.code + "0";
setCode(root.leftChild);
}
if (root.rightChild != null) {
root.rightChild.code = root.code + "1";
setCode(root.rightChild);
}
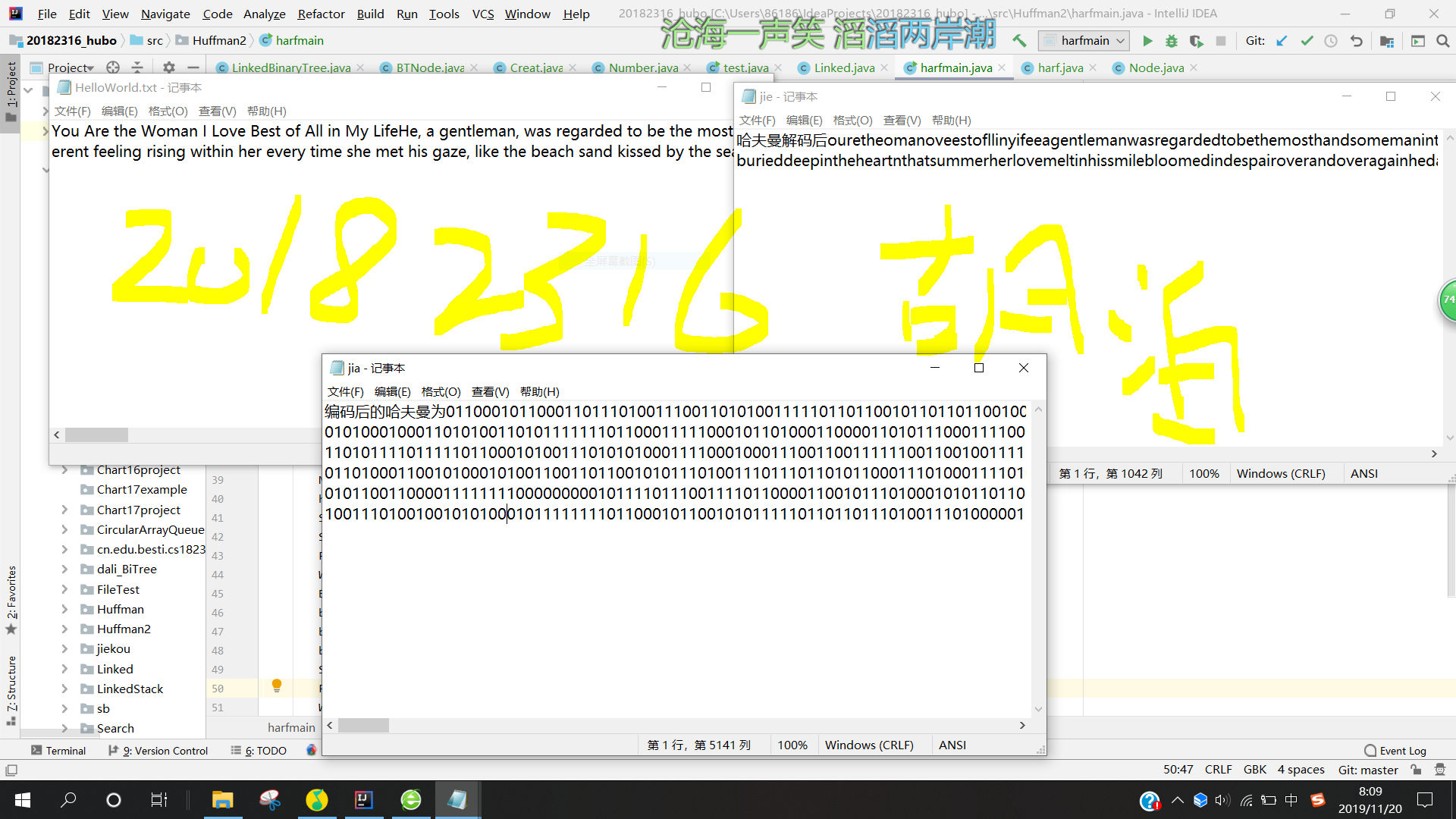
4.对编码文件进行解码,输出一个解码后的文件。
- 解码其实就是编码的反过程,将每个01码对应的字母打印到文件中,这就是解码的过程。
- 但是,在解码的过程中,如果编码不是用的哈夫曼编码,而是用的普通的二进制编码,那么就会出现解码错误,混乱的情况。

- 而哈夫曼的特点就是任意字符编码都不是其他编码的前缀,这也就决定了它解码时不可能出现不明确的情况。
private void matchCode(Node root, String code){
if (root.leftChild == null && root.rightChild == null) {
if (code.equals(root.code)) {
result += root.data; // 找到对应的字符,拼接到解码字符穿后
target = true; // 标志置为true
}
}
if (root.leftChild != null) {
matchCode(root.leftChild, code);
}
if (root.rightChild != null) {
matchCode(root.rightChild, code);
}
}
上传码云
实验过程中遇到的问题和解决过程
- 问题:我开始的思路有问题:
- 我的第一份程序,前面读取文件并统计数据的过程都很顺利,但是当构建树时,出现了很多问题,其实主要就是我的储存方式有问题。
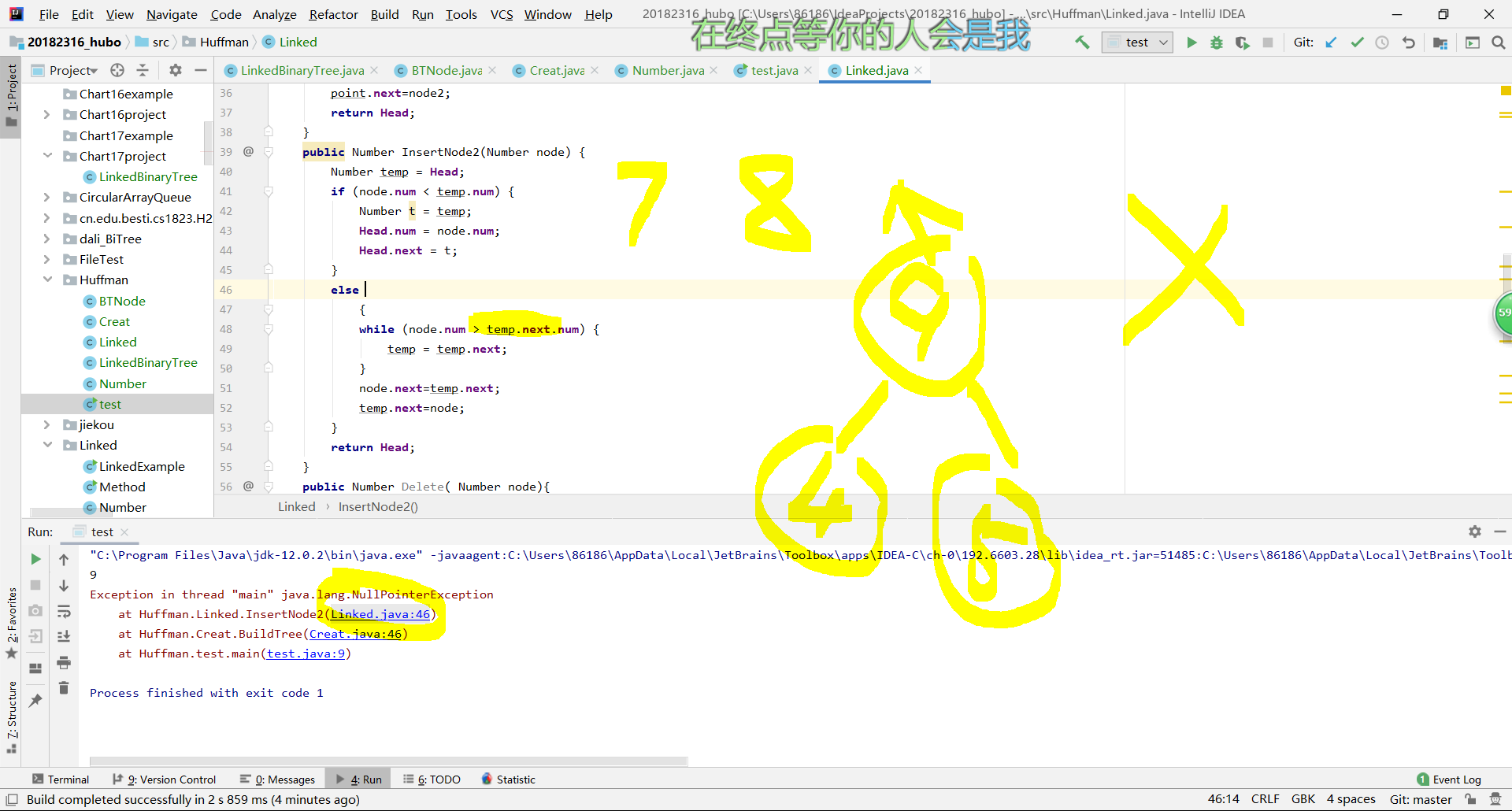
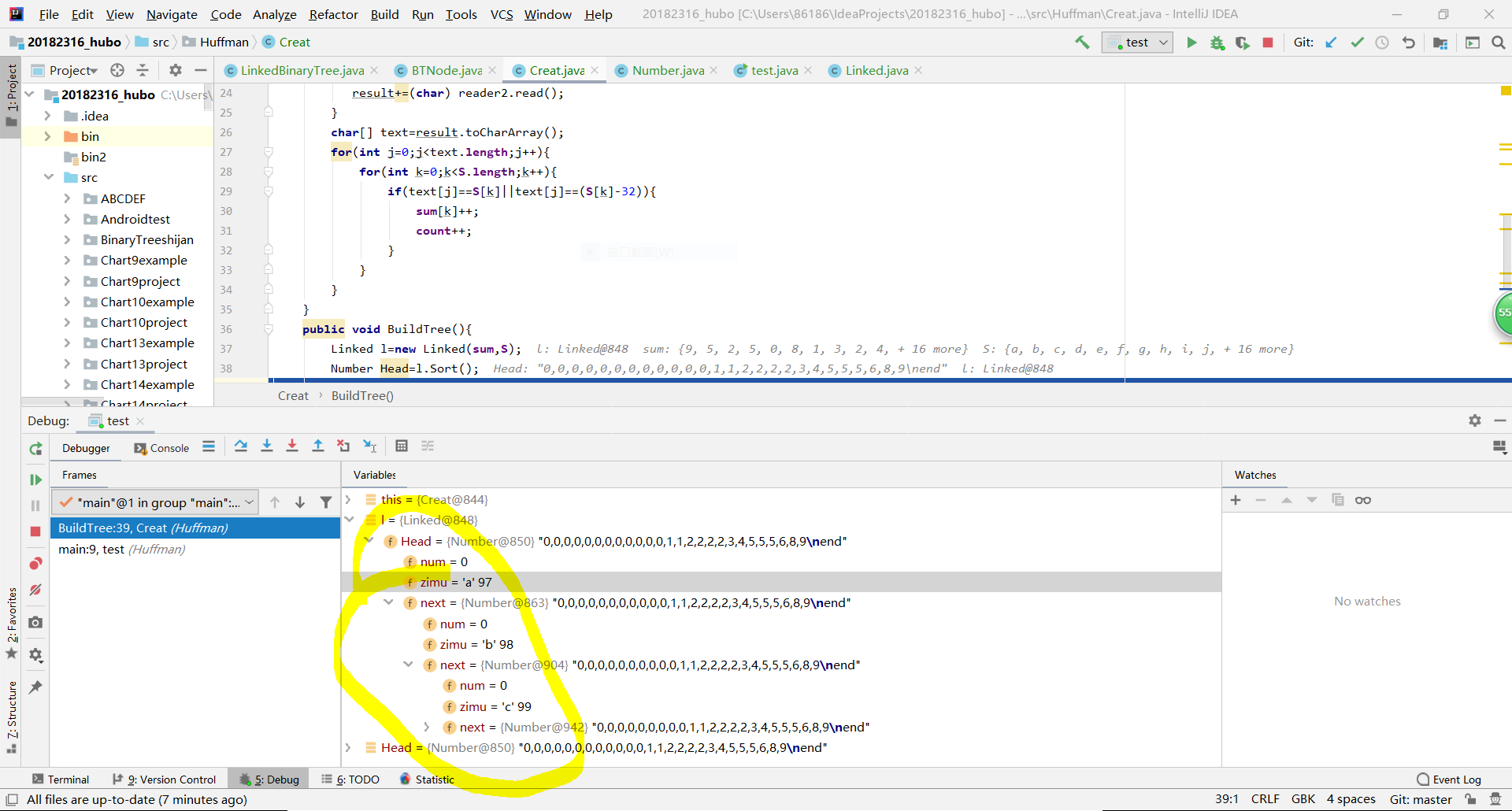
- 我的思路是:因为数组存储有容量限制,因此我想用无线延伸的链表来存储数据,下面是我的示意图和代码(忽略这辣鸡画工)
public void BuildTree(){
Linked l=new Linked(sum,S);
Number Head=l.Sort();
Number temp=Head;
LinkedBinaryTree branch = null;
while (temp.next!=null){
int he=temp.num+temp.next.num;
LinkedBinaryTree a=new LinkedBinaryTree(temp);
LinkedBinaryTree b=new LinkedBinaryTree(temp.next);
branch=new LinkedBinaryTree(temp.num+temp.next.num,a,b);
temp=l.Delete2();
Number node=new Number(he,'1');
temp=l.InsertNode2(node);
}
root=branch;
}
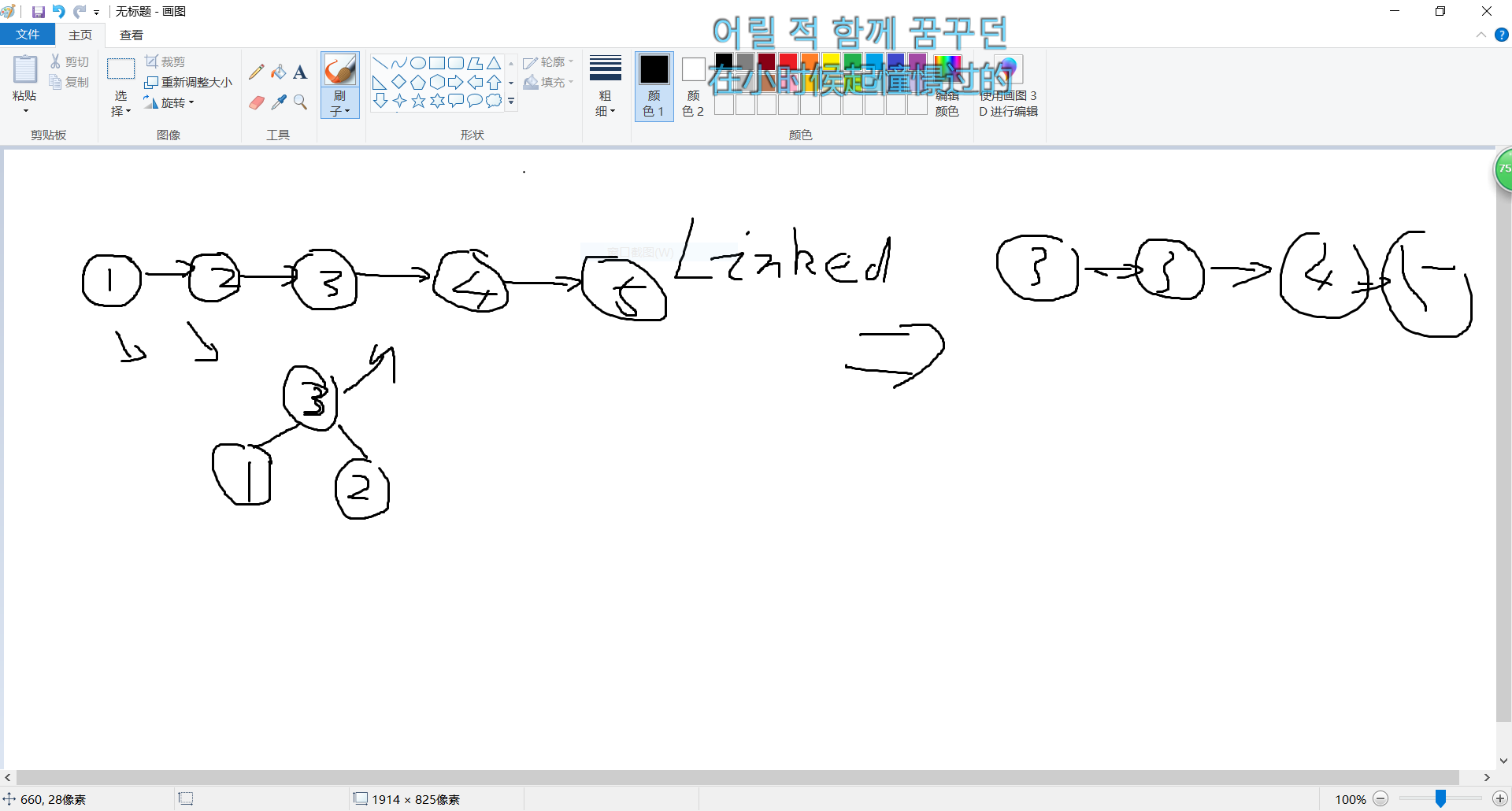
- 但是当我把加起来的结点重新放回数组里时,我发现我的每个数组元素只存储了一个结点,并且没有左右子树。于是,我改用数组存放树的结点,然后将其排序,将两个最小的组成一个三节点的二叉树,再将其放回数组中,删除两个最小的,重复上述步骤,直到数组里只剩下一个元素,循环结束,哈夫曼树就构造好了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号