
编程作业
GitHub -> 202121331011
| 工程概论 | 计算21级 |
|---|---|
| 作业要求 | 个人项目 |
| 作业目标 | 设计一个论文查重项目 |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 15 |
| ·Estimate | .估计这个任务需要多少时间 | 180 | 230 |
| Development | 开发 | 15 | 20 |
| .Analysis | .需求分析(包括学习新技术) | 60 | 60 |
| .Design Spec | .生成设计文档 | 30 | 30 |
| .Design Review | .设计复审 | 5 | 5 |
| .Coding Standard | .代码规范(为目前的开发指定合适的规范) | 5 | 5 |
| .Design | .具体设计 | 30 | 20 |
| .Coding | .具体编码 | 60 | 115 |
| .Code Review | .代码复审 | 30 | 20 |
| .Test | .测试(自我测试,修改代码,提交修改) | 20 | 20 |
| Reporting | 报告 | 60 | 50 |
| .Test Report | .测试报告 | 45 | 45 |
| .Size Measurement | .计算工作量 | 5 | 5 |
| .Postmortem & Process Improvement Plan | .事后总结,并提出改进计划 | 0 | 0 |
| .合计 | 550 | 620 | 640 |
源代码
点击查看代码
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.seg.common.Term;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class Main {
private static final int HASH_SIZE = 64; // Simhash值的长度
// 使用HanLP分词器分词并计算词频
public static Map<String, Integer> calculateWordFrequency(String text) {
List<Term> termList = HanLP.segment(text);
Map<String, Integer> wordFreqMap = new HashMap<>();
for (Term term : termList) {
String word = term.word;
wordFreqMap.put(word, wordFreqMap.getOrDefault(word, 0) + 1);
}
return wordFreqMap;
}
// 根据词频计算Simhash值
public static long calculateSimhash(Map<String, Integer> wordFreqMap) {
int[] hashBits = new int[HASH_SIZE];
for (Map.Entry<String, Integer> entry : wordFreqMap.entrySet()) {
String word = entry.getKey();
int freq = entry.getValue();
long hash = word.hashCode();
for (int i = 0; i < HASH_SIZE; i++) {
long bitmask = 1L << i;
if ((hash & bitmask) != 0) {
hashBits[i] += freq;
} else {
hashBits[i] -= freq;
}
}
}
long simhash = 0;
for (int i = 0; i < HASH_SIZE; i++) {
if (hashBits[i] >= 0) {
simhash |= 1L << i;
}
}
return simhash;
}
// 计算汉明距离
public static int calculateHammingDistance(long simhash1, long simhash2) {
long xor = simhash1 ^ simhash2;
int distance = 0;
while (xor != 0) {
distance++;
xor &= (xor - 1);
}
return distance;
}
// 使用余弦相似度算法计算相似度
public static double calculateSimilarity(long simhash1, long simhash2) {
int distance = calculateHammingDistance(simhash1, simhash2);
double similarity = (HASH_SIZE - distance) / (double) HASH_SIZE;
return similarity;
}
// 读取文件内容
public static String readFileContent(String filePath) throws IOException {
StringBuilder content = new StringBuilder();
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(filePath), StandardCharsets.UTF_8))) {
String line;
while ((line = reader.readLine()) != null) {
content.append(line).append("\n");
}
}
return content.toString();
}
// 将结果写入文件
public static void writeResultToFile(double similarity, String filePath) throws IOException {
try (BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(filePath), StandardCharsets.UTF_8))) {
writer.write(String.format("%.2f", similarity));
}
}
public static void main(String[] args) {
try {
// 读取orig.txt和orig_add.txt的内容
String origContent = readFileContent("orig.txt");
String origAddContent = readFileContent("orig_add.txt");
// 计算Simhash值
Map<String, Integer> origWordFreqMap = calculateWordFrequency(origContent);
Map<String, Integer> origAddWordFreqMap = calculateWordFrequency(origAddContent);
long origSimhash = calculateSimhash(origWordFreqMap);
long origAddSimhash = calculateSimhash(origAddWordFreqMap);
// 计算相似度
double similarity = calculateSimilarity(origSimhash, origAddSimhash);
// 将结果写入answer.txt
writeResultToFile(similarity, "answer.txt");
System.out.println("重复率为:" + String.format("%.2f", similarity));
} catch (IOException e) {
e.printStackTrace();
}
}
}
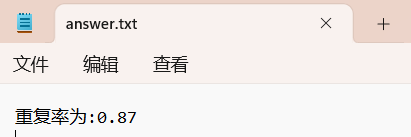
结果



 浙公网安备 33010602011771号
浙公网安备 33010602011771号