

爬取百度贴吧
这个爬虫代码结构已经比较清晰了,以后的爬虫都可以套用这个模板
from urllib import request,parse import time import random from useragents import ua_list class BaiduSpider(object): def __init__(self): self.url = 'http://tieba.baidu.com/f?kw={}&pn={}' # 获取响应内容 def get_html(self,url): headers = { 'User-Agent': random.choice(ua_list) } req = request.Request(url=url,headers=headers) res = request.urlopen(req) html = res.read().decode('utf-8') return html # 提取所需数据 def parse_html(self): pass # 保存 def write_html(self,filename,html): with open(filename,'w',encoding='utf-8') as f: f.write(html) # 主函数 def main(self): name = input('请输入贴吧名:') begin = int(input('请输入起始页:')) end = int(input('请输入终止页:')) # url缺2个数据: 贴吧名 pn params = parse.quote(name) for page in range(begin,end+1): pn = (page-1)*50 url = self.url.format(params,pn) filename = '{}-第{}页.html'.format(name,page) # 调用类内函数 html = self.get_html(url) self.write_html(filename,html) # 每爬取1个页面随机休眠1-3秒钟 time.sleep(random.randint(1,3)) print('第%d页爬取完成' % page) if __name__ == '__main__': start = time.time() spider = BaiduSpider() spider.main() end = time.time() print('执行时间:%.2f' % (end-start))
ua_list里的User-Agent只写了几个,如果常用可以再加:

ua_list = [ 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)', ]
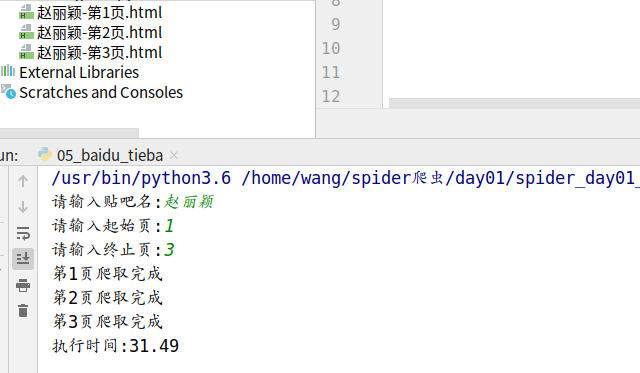
效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号