
spark原理
参考:
G:\文档\大数据\第十天_spark
spark在目前的大数据体系内,已经成为主力成员,主
要的应用场景包括:
实时计算
机器学习
图计算
数据挖掘
Ad-hoc
原理:
RDD:
使用内存--基本处理单位RDD:弹性分布式数据集
spark处理的时候,处理的是RDD数据(相当于是将块数据加载到内存中)
类似:
[1,2,3,4,5,...] 1个节点处理 [1,2] 1个节点处理[3,4,5] ......
stage:
一个 Job 会被分成一个或多个Stage, 类似airflow的DAG
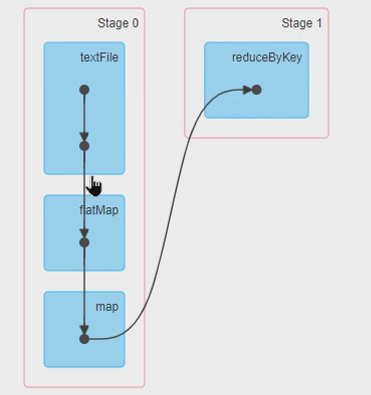
spark,和MR同样为分布式编程框架,不同之处在于MR在计算过程中(map,shuffle,reduce)数据的交换、缓冲是存储在磁盘上的,而spark在计算过程中数据的交换、共享是基于内存的,spark将各个作业依赖形成DAG(DAG把一个作业拆分成多个task,在满足条件的情况下可以并行调度),可以理解为spark是基于内存的迭代计算模式,相比较而言,spark提供了更丰富的算子操作,提供更简单的编程接口。
和hadoop相比,spark不包括文件系统,所以spark往往需要基于其它分布式文件系统,比如hdfs,s3等.但可以不依赖于yarn.
除了数据仓库用hive,相对来说最成熟,最稳定。
但实时很多各种计算都是用spark.比如hive比较慢,用sparksql几乎兼容hive的所有语法。而且可以直接用py调用sparkSQL
也可选择impala,presta. 很多公司把impala用在即时查询上。
RDD,DataFrame,DataSet的区别和联系
Java和scala写效率偏高的
1.6之后PY用DF和DSET效率是一样的
区别:
1)RDD不支持SQL
2)DF每一行都是Row类型,不能直接访问字段,必须解析才行
3)DS每一行是什么类型是不一定的,在自定义了case class之后可以很自由的获 得每一行的信息
4)DataFrame与Dataset均支持spark sql的操作,比如select,group by之类,还 能注册临时表/视窗,进行sql语句操作
partition:
把RDD分成多个分区运行在分布式的节点上,一个分区对应一个task
相关概念:

spark生态圈:
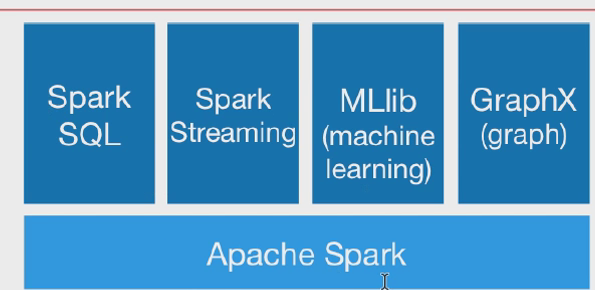
Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的 (就是上面的Apache Spark)
Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。即用spark操作hive,和上面的用hive操作spark引擎正好相反。
Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据。 在kafka的基础上进行一些算子运算。
MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。GraphX:控制图、并行图操作和计算的一组算法和工具的集合。
GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作
集群组件说明:
Cluster Manager:集群管理器。在Standalone模式中即为Master主节点,控制整个集群,监控Worker。在YARN模式中为Resourcemanager
- Worker节点:从节点,负责控制计算节点,启动Executor或者Driver。在Standalone模式中指的是通过slave文件配置的Worker节点,在Spark on Yarn模式下就是NoteManager节点
- Driver:运行Application的主函数, java的入口函数main,如上面例子中的org.apache.spark.examples.JavaSparkPi
- Executor:执行器,是为某个Application运行在worker node上的一个进程。其进程名称为CoarseGrainedExecutorBackend。一个CoarseGrainedExecutorBackend有且仅有一个Executor对象, 负责将Task包装成taskRunner,并从线程池中抽取一个空闲线程运行Task, 这个每一个CoarseGrainedExecutorBackend能并行运行Task的数量取决于分配给它的cpu个数
三种模式对比:
1/ spark standalone模式
standalone模式是通过spark的master和worker进程进行作业和资源的调度。不依赖于yarn,kill掉driver那台机器,任务没法通讯了。

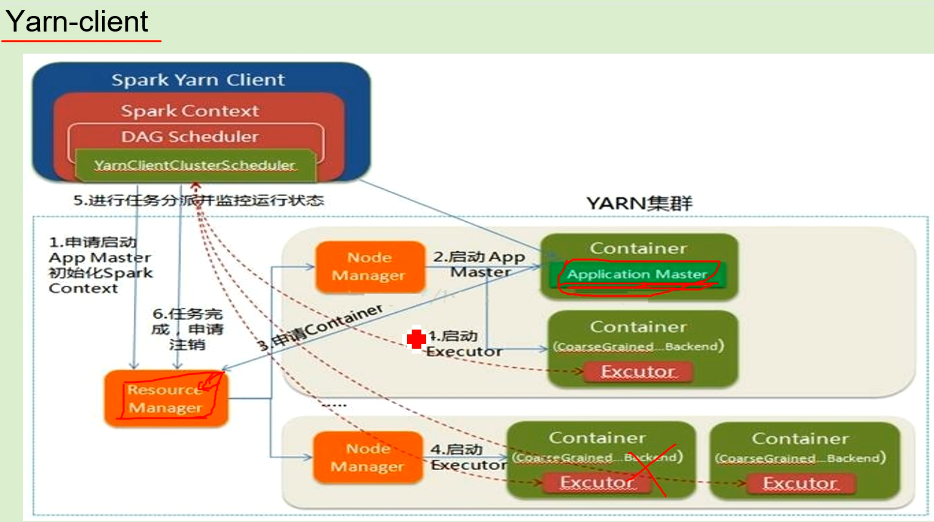
2/ spark yarn-client模式
yarn-client模式是通过yarn的ResourceManager和NodeManager进程进行作业和资源的调度。只不过Driver,即主函数不是通过Yarn调度执行,而是在客户端本地,driver就在你提交job的那台机器上运行,kill掉driver那台机器,任务没法通讯了,会挂掉。并且因为Driver在客户端,所以程序的运行结果可以在客户端显示,交互式,适合pyspark
3/ yarn-cluster模式是通过yarn的ResourceManager和NodeManager进程进行作业和资源的调度。原理基本上和Mapreduce的Yarn调度流程一致。不同于Yarn-Client的是cluster客户端的任务只是提交作业给Yarn,不做Driver程序的执行。YarnCluster的Driver是在集群的某一台NM上,即在application master的container上,所以kill掉你提交job的那台机器,任务不影响,会继续运行。但由于是集群模式,程序的运行结果无法在客户端显示.官方是建议生产中用.
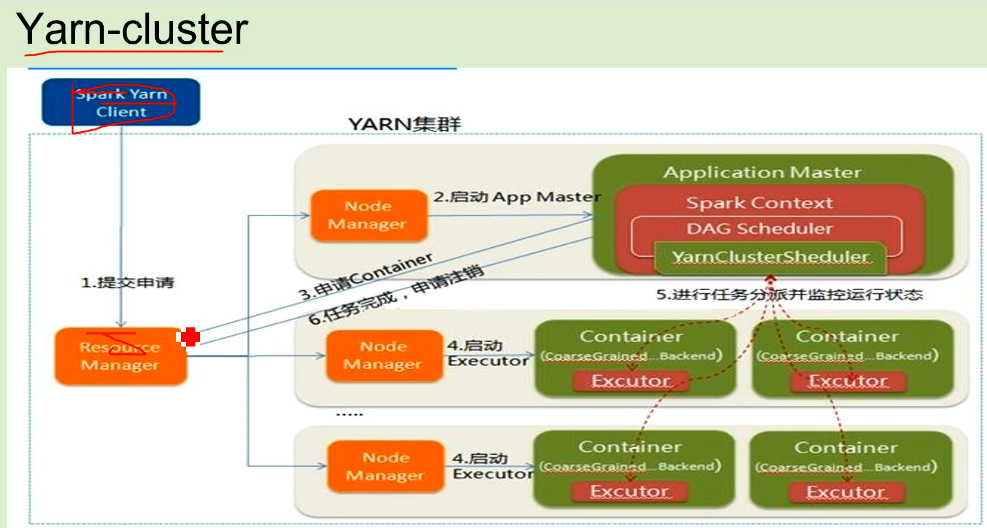
最后再来说应用场景,Yarn-Cluster适合生产环境,Yarn-Client适合交互和调试。

spark早期会有内存溢出的情况,现在已经比较稳定,与其说是稳定性不如说是成本问题。所以现在用spark做ETL也是没有问题的。
Spark Streaming将接收到的实时流数据,按照一定时间间隔,对数据进行拆分,交给Spark Engine引擎,最终得到一批批的结果
spark SQL 用得是DataFrame的分布式SQL查询引擎。可以用java,scala,python来操作:
https://blog.csdn.net/u013305783/article/details/86220909
python操作例子:
from pyspark.sql import SparkSession
from os.path import abspath
warehouse_location = abspath('spark-warehouse')
spark = SparkSession.builder.appName("python sparksql").config("spark.sql.warehouse.dir", warehouse_location).enableHiveSupport().getOrCreate()
spark.sql("SELECT * FROM t limit 10").show()
生产例子:
spark SQL: G:\文档\大数据\第十天_spark\sparksql
pyspark: G:\文档\大数据\第十天_spark\pyspark


 浙公网安备 33010602011771号
浙公网安备 33010602011771号