
小白scrapy爬虫之爬取简书网页并下载对应链接内容
*准备工作:
爬取的网址:https://www.jianshu.com/p/7353375213ab
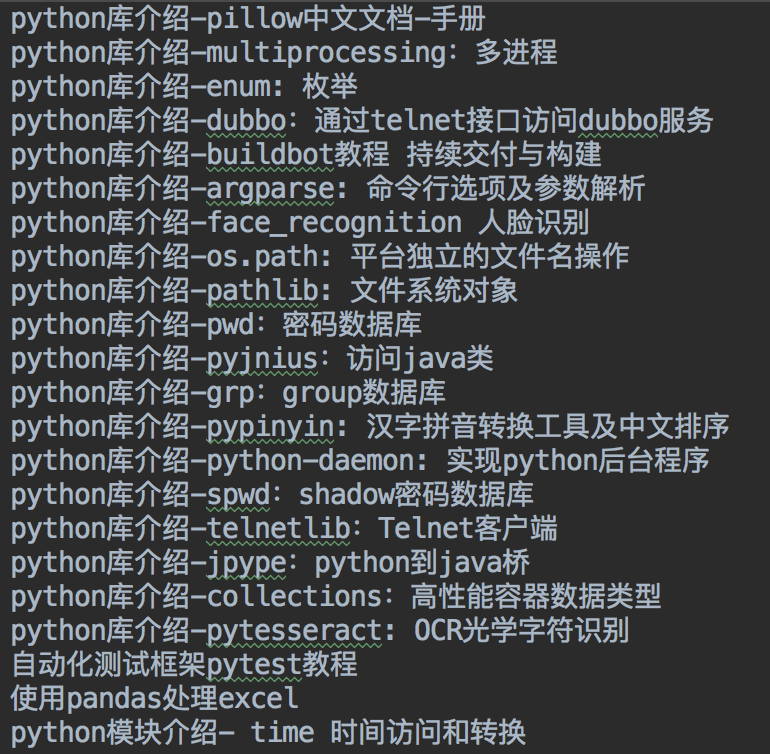
爬取的内容:下图中python库介绍的内容列表,并将其链接的文章内容写进文本文件中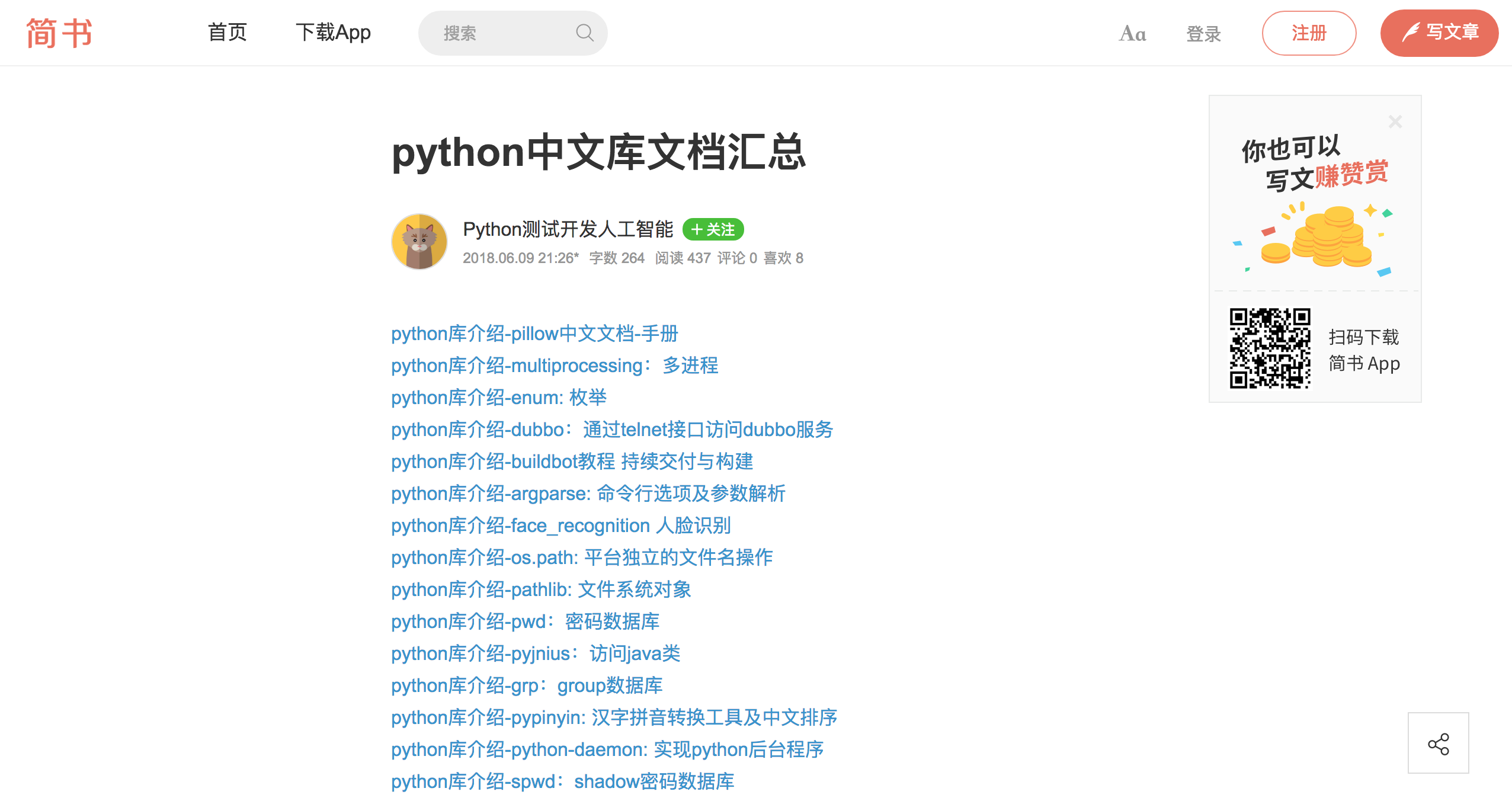
1.同上一篇的步骤:
通过'scrapy startproject jianshu_python'命令创建scrapy工程
通过'scrapy genspider jianshu_doc_list jianshu.com'命令创建一个爬虫
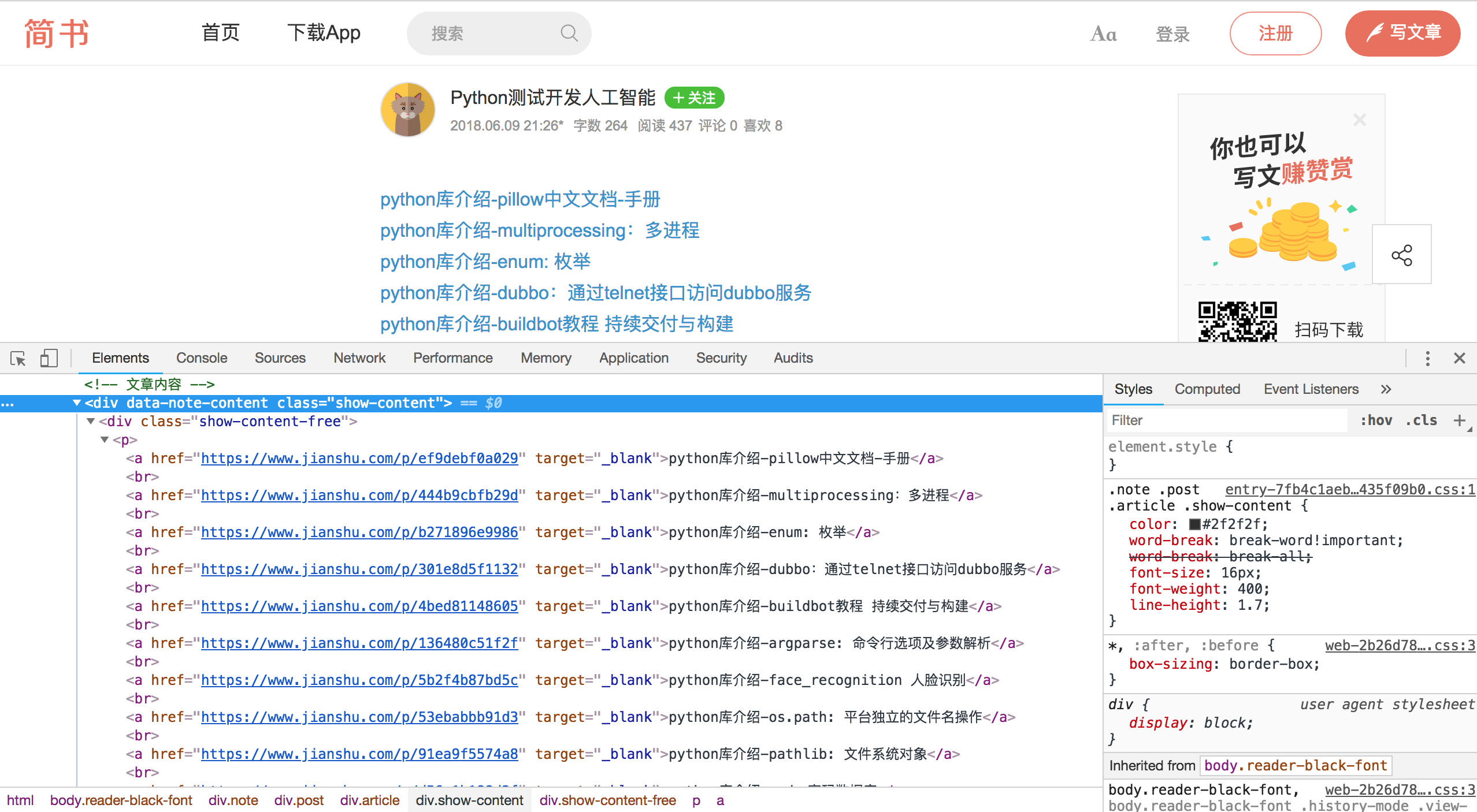
通过'scrapy shell https://www.jianshu.com/p/7353375213ab'命令在命令行窗口里调试得出所需信息的表达式(注意要先设置settings.py里的USER_AGENT值)
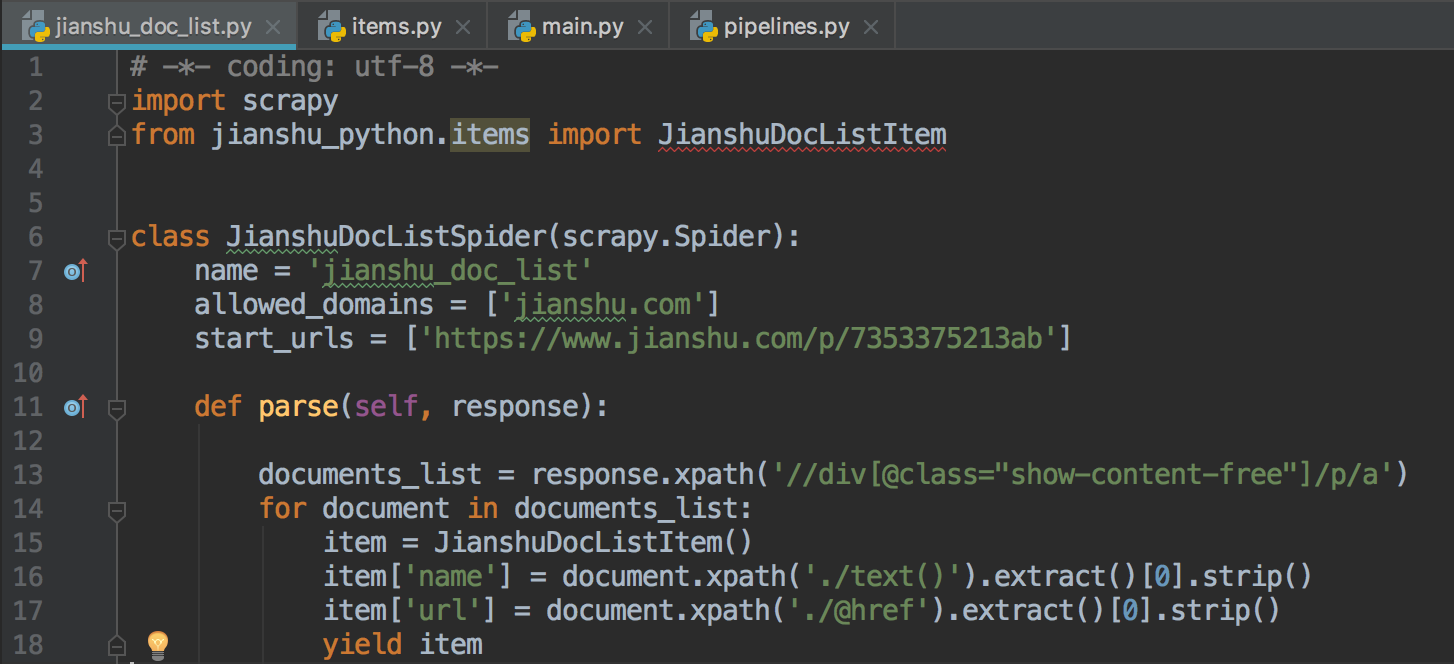
2.调试出xpath表达式,写入爬虫脚本jianshu_doc_list.py中

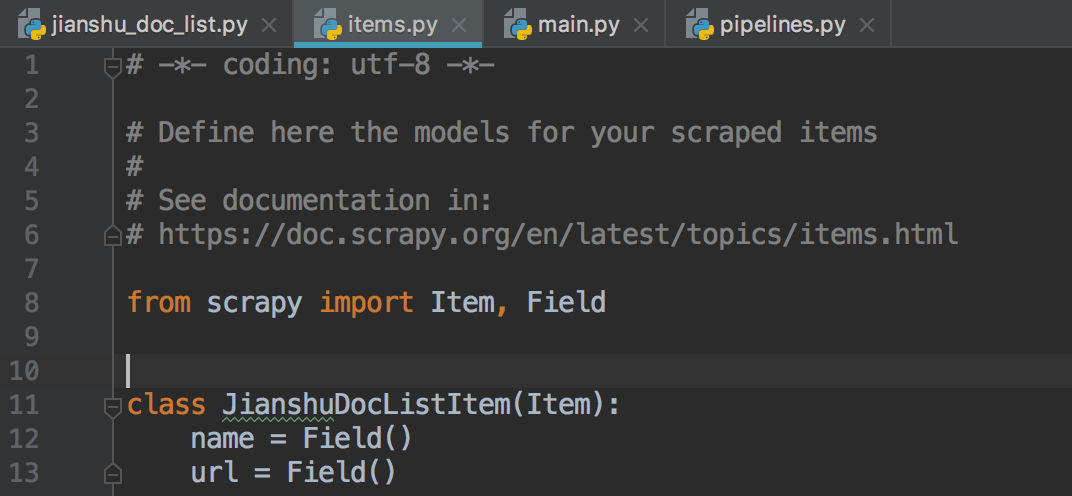
3.同样item的对象声明来自于items.py文件中
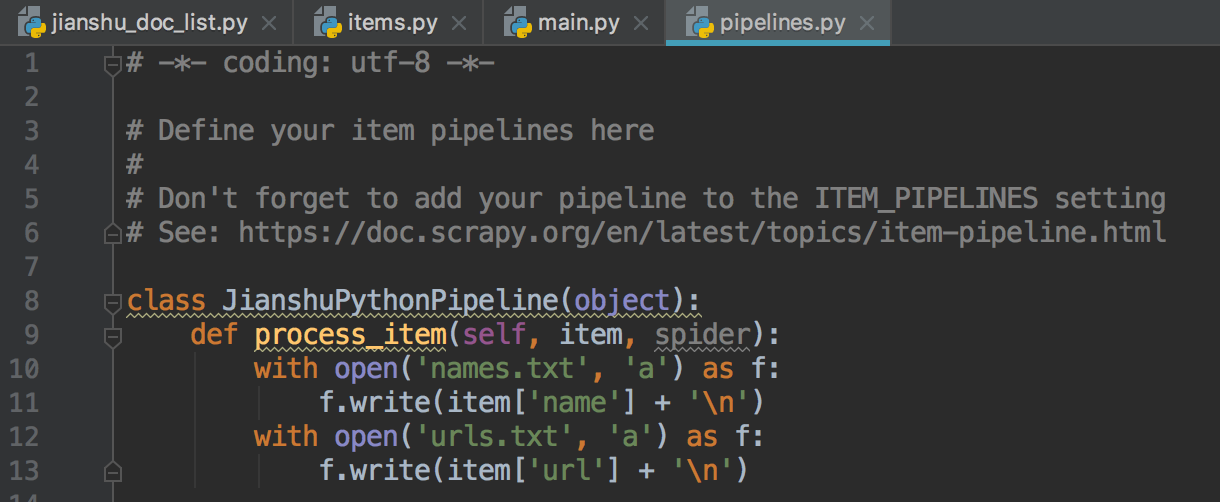
4.在pipelines.py文件里写文件名和链接的url名的数据去处
5.settings.py里的设置和运行方式同上一篇,选择一种即可,结果如下
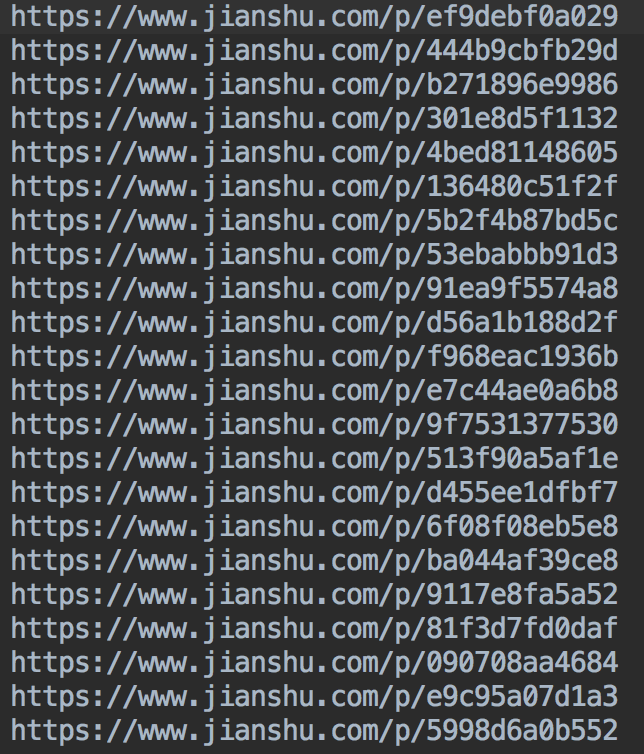
6.再次新建一个爬虫项目,用于读取url,并将对应的网页内容输出到不同的文本文件
'scrapy startproject python_documents'
'scrapy genspider documents_spider jianshu.com'
'scrapy shell https://www.jianshu.com/p/ef9debf0a029' # 选取其中一个url作为访问地址(注意先设置USER_AGENT值)
7.documents_spider.py脚本内容 (注意如果是命令行scrapy crawl documents_spider执行爬虫方式,urls.txt应放在与scrapy.cfg同级的目录下;如果是main.py脚本方式执行方式,urls.txt放置位置随main.py位置改变)

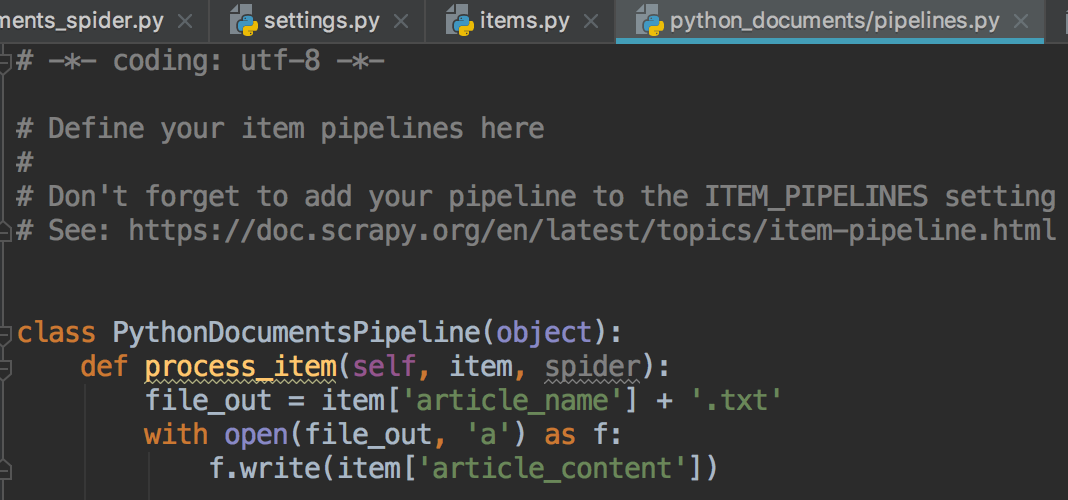
8.pipelines.py脚本内容(setting.py里要设置ITEM_PIPELINES值,否则数据无法输出到指定文本中)
9.同样items.py里变量的声明与documents_spider.py里保持一致
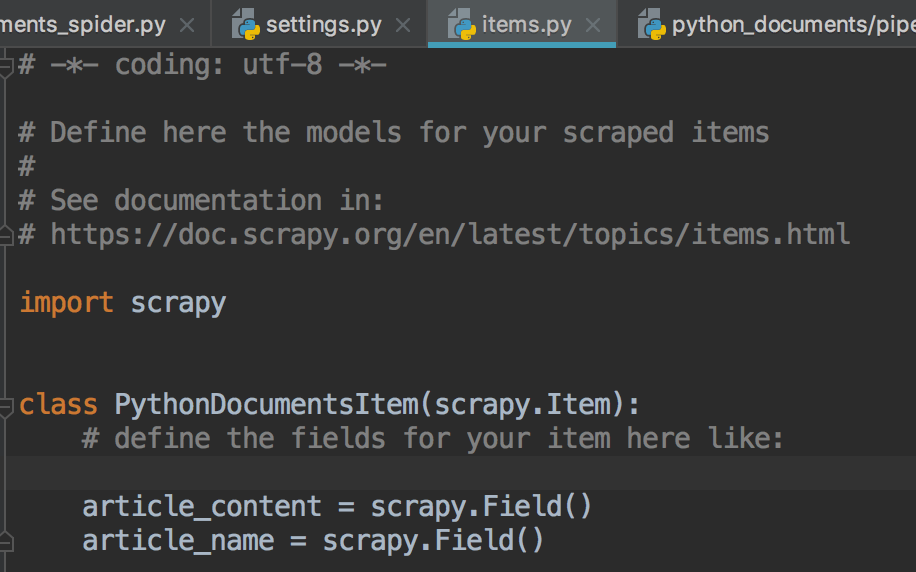
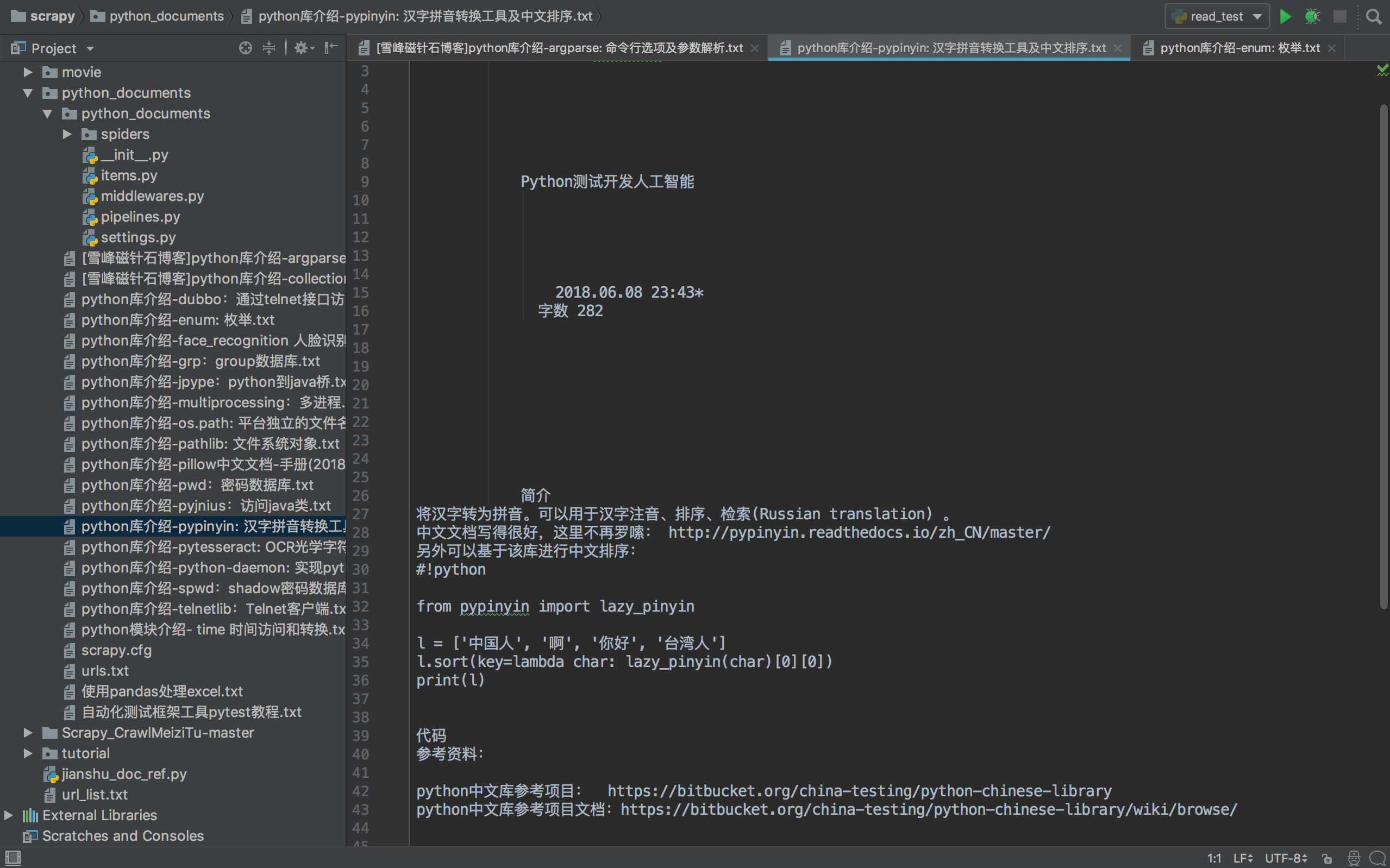
10.执行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号