Kafka 控制器Controller
Kafka 控制器Controller
Broker 在启动时,会尝试去 ZooKeeper 中创建 /controller 节点。Kafka 当前选举控制器的规则是:第一个成功创建 /controller 节点的 Broker 会被指定为控制器。
Controller Broker的主要职责有很多,主要是一些管理行为,主要包括以下几个方面:
- 创建、删除主题,增加分区并分配leader分区
- 集群Broker管理(新增 Broker、Broker 主动关闭、Broker 故障)
- preferred leader选举
- 分区重分配
为什么需要Controller
在Kafka早期版本,对于分区和副本的状态的管理依赖于zookeeper的Watcher和队列:每一个broker都会在zookeeper注册Watcher,所以zookeeper就会出现大量的Watcher, 如果宕机的broker上的partition很多比较多,会造成多个Watcher触发,造成集群内大规模调整;每一个replica都要去再次zookeeper上注册监视器,当集群规模很大的时候,zookeeper负担很重。这种设计很容易出现脑裂和羊群效应以及zookeeper集群过载。
新的版本中该变了这种设计,使用KafkaController,只有KafkaController,Leader会向zookeeper上注册Watcher,其他broker几乎不用监听zookeeper的状态变化。
Kafka集群中多个broker,有一个会被选举为controller leader,负责管理整个集群中分区和副本的状态,比如partition的leader 副本故障,由controller 负责为该partition重新选举新的leader 副本;当检测到ISR列表发生变化,有controller通知集群中所有broker更新其MetadataCache信息;或者增加某个topic分区的时候也会由controller管理分区的重新分配工作。
具体职责
具备控制器身份的broker需要比其他普通的broker多一份职责,具体细节如下:
- 监听partition相关的变化。为Zookeeper中的/admin/reassign_partitions节点注册PartitionReassignmentListener,用来处理分区重分配的动作。为Zookeeper中的/isr_change_notification节点注册IsrChangeNotificetionListener,用来处理ISR集合变更的动作。为Zookeeper中的/admin/preferred-replica-election节点添加PreferredReplicaElectionListener,用来处理优先副本的选举动作。
- 监听topic相关的变化。为Zookeeper中的/brokers/topics节点添加TopicChangeListener,用来处理topic增减的变化;为Zookeeper中的/admin/delete_topics节点添加TopicDeletionListener,用来处理删除topic的动作。
- 监听broker相关的变化。为Zookeeper中的/brokers/ids/节点添加BrokerChangeListener,用来处理broker增减的变化。
- 从Zookeeper中读取获取当前所有与topic、partition以及broker有关的信息并进行相应的管理。对于所有topic所对应的Zookeeper中的/brokers/topics/[topic]节点添加PartitionModificationsListener,用来监听topic中的分区分配变化。
- 启动并管理分区状态机和副本状态机。
- 更新集群的元数据信息。
- 如果参数auto.leader.rebalance.enable设置为true,则还会开启一个名为“auto-leader-rebalance-task”的定时任务来负责维护分区的优先副本的均衡。
Kafka leader选举
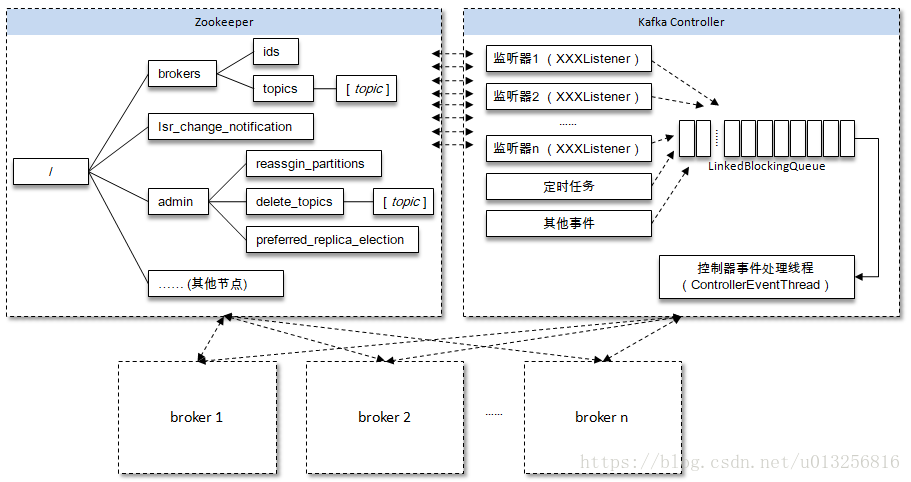
Kafka 使用 Zookeeper 来维护集群成员 (brokers) 的信息。每个 broker 都有一个唯一标识 broker.id,用于标识自己在集群中的身份,可以在配置文件 server.properties 中进行配置,或者由程序自动生成。
选举流程
其选举leader成为controller的过程如下:
- 在kafka集群中,每一个 broker 启动的时候,它会在zk 的 /brokers/ids 路径下创建一个 临时节点(例如:{“version”:1,”brokerid”:1,”timestamp”:”1512018424988”}),并将自己的 broker.id 写入,从而将自身注册到集群;
- 第一个启动的broker会在zk中创建一个临时节点 /controller 让自己成为控制器。其他broker启动时也会试着创建这个节点当然他们会失败,因为已经有人创建过了。那么这些节点会在控制器节点上创建zk watch对象,这样他们就可以收到这个节点变更的通知。任何时刻都确保集群中只有一个leader的存在。
- 如果控制器被关闭或者与zk断开连接,zk上的controller节点马上就会消失。那么其他订阅了leader节点的broker也会收到通知随后他们会尝试让自己成为新的leader,重复第一步的操作。
- 如果leader完好但是别的broker离开了集群,那么leader会去确定离开的broker的分区并确认新的分区领导者(即分区副本列表里的下一个副本)。然后向所有包含该副本的follower或者observer发送请求。随后新的分区首领开始处理请求。
利用Zookeeper的强一致性特性,一个节点只能被一个客户端创建成功,创建成功的broker即为leader,即先到先得原则,leader也就是集群中的controller,负责集群中所有大小事务。
参考Zookeeper的Leader Election如下:
抢注Leader节点——非公平模式
- 创建Leader父节点,如/chroot,并将其设置为persist节点
- 各客户端通过在/chroot下创建Leader节点,如/chroot/leader,来竞争Leader。该节点应被设置为ephemeral
- 若某创建Leader节点成功,则该客户端成功竞选为Leader
- 若创建Leader节点失败,则竞选Leader失败,在/chroot/leader节点上注册exist的watch,一旦该节点被删除则获得通知
- Leader可通过删除Leader节点来放弃Leader
- 如果Leader宕机,由于Leader节点被设置为ephemeral,Leader节点会自行删除。而其它节点由于在Leader节点上注册了watch,故可得到通知,参与下一轮竞选,从而保证总有客户端以Leader角色工作。
先到先得,后者监视前者——公平模式
- 创建Leader父节点,如/chroot,并将其设置为persist节点
- 各客户端通过在/chroot下创建Leader节点,如/chroot/leader,来竞争Leader。该节点应被设置为ephemeral_sequential
- 客户端通过getChildren方法获取/chroot/下所有子节点,如果其注册的节点的id在所有子节点中最小,则当前客户端竞选Leader成功
- 否则,在前面一个节点上注册watch,一旦前者被删除,则它得到通知,返回step 3(并不能直接认为自己成为新Leader,因为可能前面的节点只是宕机了)
- Leader节点可通过自行删除自己创建的节点以放弃Leader
选举方式
新增Controller机制后,减轻Zookeeper负载,Controller与Leader及Follower间通过RPC通信,高效且实时,但是由于引入Controller增加了复杂度,同时需要考虑Controller的Failover(容错)
Kafka通过leaderSelector完成leader的选举。
可能触发为partition选举leader的场景有: 新创建topic,broker启动,broker停止,controller选举,客户端触发,reblance等等 场景。在不同的场景下选举方法不尽相同。Kafka提供了五种leader选举方式,继承PartitionLeaderSelector,实现selectLeader方法完成leader的选举,
选举器用PartitionLeaderSelector表示,有5个实现类:
1、OfflinePartitionLeaderSelector:
2、ReassignedPartitionLeaderSelector:
3、PreferredReplicaPartitionLeaderSelector:
4、ControlledShutdownLeaderSelector:
5、NoOpLeaderSelector:
Controller发送broker的请求
Controller从ZooKeeper那儿得到变更通知之后,需要告知集群中的Broker(包括它自身)做相应的处理。
Controller只会给集群的Broker发送三种请求:分别是 LeaderAndIsrRequest、StopReplicaRequest和 UpdateMetadataRequest
LeaderAndIsrRequest
告知Broker主题相关分区Leader和ISR副本都在哪些 Broker上。
StopReplicaRequest
告知Broker停止相关副本操作,用于删除主题场景或分区副本迁移场景。
UpdateMetadataRequest
更新Broker上的元数据。
Controller事件处理线程会把事件封装成对应的请求,然后将请求写入对应的Broker的请求阻塞队列,然后RequestSendThread不断从阻塞队列中获取待发送的请求。
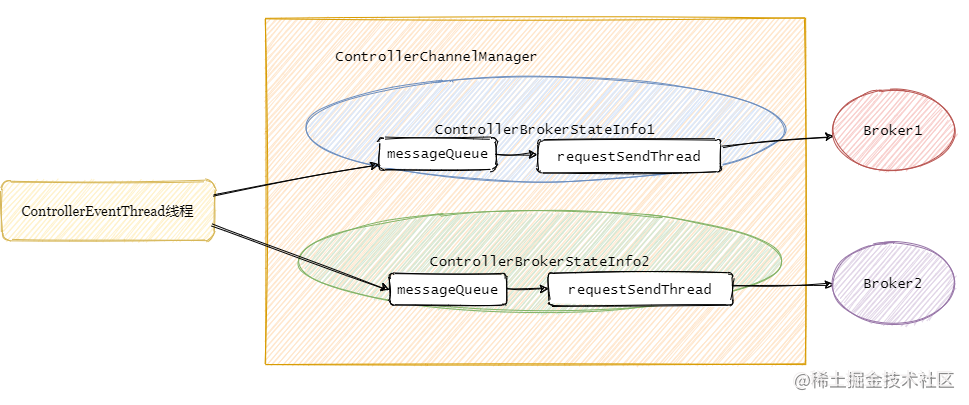
处理下线Broker场景
每个 Broker 启动后,会在zookeeper的 /Brokers/ids 下创建一个临时 znode。当 Broker 宕机或主动关闭后,该 Broker 与 ZooKeeper 的会话结束,这个 znode 会被自动删除。同理,ZooKeeper 的 Watch 机制将这一变更推送给控制器,这样控制器就能知道有 Broker 关闭或宕机了,从而进行后续的协调操作。
Controller将收到通知并对此采取行动,决定哪些Broker上的分区成为leader分区,然后,它会通知每个相关的Broker,将Broker上的主题分区变成leader,通过LeaderAndIsr请求从新的leader分区中复制数据。
Controller中存储的数据存储
Kafka 是离不开 ZooKeeper的,所缓存的数据信息在 ZooKeeper 中也保存了一份。每当控制器初始化时,它都会从 ZooKeeper 上读取对应的元数据并填充到自己的缓存中。
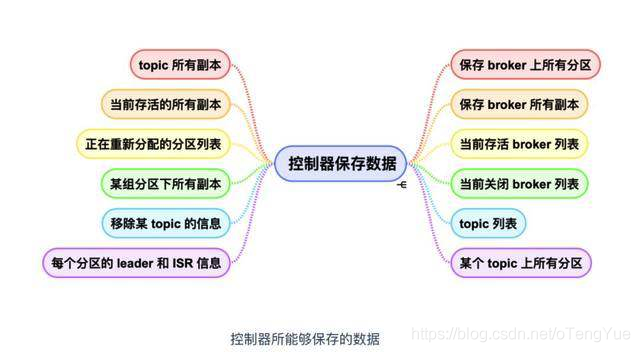
归纳主要包含三类:
- broker 上的所有信息。包括 broker 中的所有分区,broker 所有分区副本,当前都有哪些运行中的 broker,哪些正在关闭中的 broker 。
- 所有主题信息。包括具体的分区信息,比如领导者副本是谁,ISR 集合中有哪些副本等。
- 所有涉及运维任务的分区。包括当前正在进行 Preferred 领导者选举以及分区重分配的分区列表。
Broker Controller 初始化
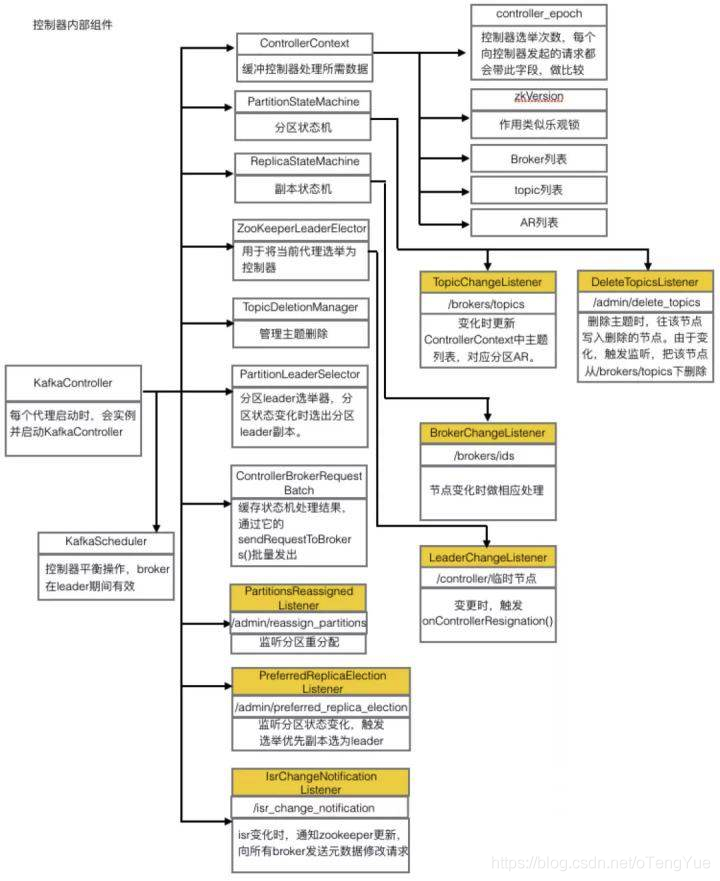
Controller选举成功在启动后,首先进行一些缓存的清理,并在zk上注册监听事件,监听那些Broker变化,Topic变化等事件,用于行使Controller的具体职责。同时通过发送UpdateMetadataRequest,用于各个Broker更新metadata。在启动过程中,Controller还会启动副本状态机和分区状态机,这两个状态机用于记录副本和分区的状态,并且预设了状态转换的处理方法。在Controller启动时会分别调用两个状态机的startup()方法,在该方法中初始化副本和分区的状态,并且主要地触发LeaderAndIsrRequest请求到Broker。
Broker之间元数据缓存一致性
Kafka在设计时一个愿景:每台Kafka broker都要维护相同的缓存,这样客户端程序(clients)随意地给任何一个broker发送请求都能够获取相同的数据,这也是为什么任何一个broker都能处理clients发来的Metadata请求的原因。这种用空间去换时间的做法可以缩短请求被处理的延时从而提高整体clients端的吞吐。
目前Kafka是怎么更新cache的?
简单来说,有集群中的controller监听Zookeeper上元数据节点,由controller和ZK元数据保持一致,具体的更新操作实际上是由controller来完成的。controller会在一定场景下向各broker发送UpdateMetadata请求令这些broker去更新它们各自的cache,这些broker一旦接收到请求便开始全量更新——即清空当前所有cache信息,使用UpdateMetadata请求中的数据来重新填充cache。
由于是异步更新的,所以在某一个时间点集群上所有broker的cache信息就未必是严格相同的。只不过在实际使用场景中,这种弱一致性似乎并没有太大的问题。
原因如下:
- clients并不是时刻都需要去请求元数据的,且会缓存到本地;
- 即使获取的元数据无效或者过期了,clients通常都有重试机制,可以去其他broker上再次获取元数据;
- cache更新是很轻量级的,仅仅是更新一些内存中的数据结构,不会有太大的成本。因此我们还是可以安全地认为每台broker上都有相同的cache信息。
Broker Controller 故障转移
由于broker controller 只有一个,那么必然会存在单点失效问题。kafka 为考虑到这种情况提供了故障转移功能,也就是 Fail Over。如下图:

当新的controller开始工作后,旧的controller可能还在工作,这时就会有两个自认为是的controller,那么broker该听哪个的呢?
Kafka leader 分区自动平衡机制
broker配置auto.leader.rebalance.enable=true,开启分区自动平衡
当 partition 1 的 leader,就是 broker.id = 1 的节点挂掉后,那么 leader 0 或 leader 2 成为 partition 1 的 leader,那么 leader 0 或 leader 2 会管理两个 partition 的读写,性能会下 降,当 leader 1 重新启动后,如果开启了 leader 均衡机制,那么 leader 1 会重新成为 partition 1 的 leader,降低 leader 0 或 leader 2 的负载
上面提到的选Leader分区,严格意义上是换Leader分区,为了达到负载均衡,可能会造成原来正常的Leader分区被强行变为follower分区。换一次 Leader 代价是很高的,原本向 Leader分区A(原Leader分区) 发送请求的所有客户端都要切换成向 B (新的Leader分区)发送请求,建议在生产环境中把这个参数设置成 false
Kafka 首选领导者Preferred Leader
Kafka认为leader分区副本最初的分配(每个节点都处于活跃状态)是均衡的。这些被最初选中的分区副本就是所谓的首选领导者(preferred leaders)。
在 broker 挂掉之后,分区 leader 会变更,久而久之就会变得不均衡,Kafka 默认序号最小的副本为 Preferred leader,在 broker 重启回来后,Kafka 会重新调整分区的 Preferred leader 成为 leader,Preferred leader 选举分为手动选举和自动选举,涉及参数 auto.leader.rebalance.enable,还有个默认允许 10% 不均衡策略等等。
同步副本(in-sync replica ,ISR)列表
选择一个同步副本列表中的分区作为leader 分区的过程称为clean leader election。注意,这里要与在非同步副本中选一个分区作为leader分区的过程区分开,在非同步副本中选一个分区作为leader的过程称之为unclean leader election。
由于ISR是动态调整的,所以会存在ISR列表为空的情况,通常来说,非同步副本落后 Leader 太多,因此,如果选择这些副本作为新 Leader,就可能出现数据的丢失。毕竟,这些副本中保存的消息远远落后于老 Leader 中的消息。在 Kafka 中,选举这种副本的过程可以通过Broker 端参数 **unclean.leader.election.enable **控制是否允许 Unclean 领导者选举。开启 Unclean 领导者选举可能会造成数据丢失,但好处是,它使得分区 Leader 副本一直存在,不至于停止对外提供服务,因此提升了高可用性。反之,禁止 Unclean Leader 选举的好处在于维护了数据的一致性,避免了消息丢失,但牺牲了高可用性。分布式系统的CAP理论说的就是这种情况。
Controller 脑裂
什么原因会造成脑裂
- controller所在broker网络故障
- controller 进行full gc,STW时间过长,超过zookeeper session timeout 出现假死
造成现象
- 创建topic成功,但是produce的时候,却报unknown partition的错误,但zk上却显示了每个partition的leader信息;
- 给某个topic增加分区,zk显示已有增加的分区信息,但是依旧报找不到新增加的分区信息错误
现有的topic读写不受影响,因为读写时获取partition的元数据信息在任意broker上都可以获取到
解决办法 controller_epoch
每当新的controller产生的时候就会在zk中生成一个全新的、数值更大的controller epoch的标识,并同步给其他的broker进行保存,这样当另一个controller发送指令时,较小的epoch number请求就会被忽略。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号