

2020软工第二次作业
| 这个作业属于哪个课程 | 软件工程2020秋 |
|---|---|
| 这个作业要求在哪里 | 第二次作业(个人编程作业) |
| 这个作业的目标 | 热身+练手,锻炼现学现用的能力 |
| 学号 | 031804103 |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 15 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 300 | 420 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 150 |
| Design Spec | 生成设计文档 | 60 | 75 |
| Design Review | 设计复审 | 30 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 120 | 120 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 150 |
| Reporting | 报告 | 90 | 120 |
| Test Report | 测试报告 | 60 | 60 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 25 |
| 合计 | 1100 | 1305 |
解题思路
初见
说实话,这次出作业之前,我属实被隔壁K班的作业吓到了,所以第一眼看到这次作业我是往复杂的方向想的。第一次看题的时候比较仓促,下载了数据,大概看了知道是大数据统计题(作为大数据专业的,这次作业如此挣扎,惭愧...),以为要做的是GitHub各种commit变化情况,因为这个数据包含的信息实在是太多了。但是仔细看题后,发现其实关注的信息类型只有PushEvent、IssueCommentEvent、IssuesEvent、PullRequestEvent四种,这倒是很符合大数据5V特性(Volume、Variety、Value、Velocity、Veracity)里面的价值密度低。
把题目完整读完以后,发现还有python的示例代码,对这次作业产生了一种:代码不难,主要是熟悉git、PSP、code style的感觉。后来证明我只对了一半,低估了代码难度。
沉思
这个小标题正好是我很喜欢的一个曲子,曾经苦练过几个月,也是我高三时期的起床铃声,顺便分享一个我最喜欢的版本:
-
idea one:Sketch
大数据量的统计,首先想到了之前看过的一些paper,比如 An Improved Data Stream Summary:The Count-Min Sketch and Its Applications,用来做一些有损统计能很有效降低数据量和加速查询,还可以在精度和空间开销之间做权衡,我也实现/跑过几个类似的demo,所以想到这个idea我还是很兴奋的。
但是后来再读了一遍题目并重读了paper以后,发现本题的主要问题在于大数据量的读取,处理后的数据本身就是比较小的,查询的优化空间也不大,最重要的是本题似乎不允许有损统计。
-
idea two:Hadoop
回到大数据统计的问题上,,想到了本题少次大量读入的特点,我就想到了之前玩过的HDFS(Hadoop Distance File System)和MapReduce。分布式的存储和计算对大数据量的处理任务还是很有效的,无奈并不很精通Hadoop,这个作业也不是简单的word count,测试平台有没有这种特殊的环境也是个问题。
-
idea three:Python
前两个idea被pass以后,似乎也想不到什么有创意的idea了,所以只好选择比较中规中矩的思路,一方面是自己比较熟悉py,另一方面是时间比较紧,就直接参考(xiu gai)样例代码了。
看了看样例代码,发现已经是功能完整的版本了,只是没有注释,看起来比较费工夫。那问题就变成了,如何提速样例代码的速度
设计实现过程
额,其实不能说是设计实现过程,而是找漏洞&加速的过程。下面涉及到的测试截图的数据量都是大概300MB。
下面是大致的流程图

前期准备
涉及到了json的读写、命令行的解析,所以初步找了些资料学习一下
分段测试时间,寻找瓶颈
这个小部分的主要思路是大致把样例代码的初始化部分分块,分别测试耗时。稍微测试了一下样例代码,发现读取文件和处理文件耗时明显很高。

所以接下来的主要优化工作在于这两部分的改良(mo gai)。
处理数据
在这部分发现了参考代码的一个破绽(不知道是不是故意的嗷),在阅读代码的过程中发现了这样两个函数:
def __parseDict(self, d: dict, prefix: str):
_d = {}
for k in d.keys():
if str(type(d[k]))[-6:-2] == 'dict':
_d.update(self.__parseDict(d[k], k))
else:
_k = f'{prefix}__{k}' if prefix != '' else k
_d[_k] = d[k]
return _d
def __listOfNestedDict2ListOfDict(self, a: list):
records = []
for d in a:
_d = self.__parseDict(d, '')
records.append(_d)
return records
仔细阅读可以发现,这两个函数其实是嵌套的,相当于一个二重循环。其主要作用是把一个嵌套的字典传进来,返回一个整理过的非嵌套的字典,比较便于访问。但是这样做的代价是对于整个数据二重循环了一遍,应该是处理文件阶段的一个比较大的瓶颈,为了考证这个猜想,进一步对处理数据部分再次拆分测试时间。将处理数据进一步拆分为重构数据和统计数据阶段。

可以看到,rebuild data的阶段占据了处理数据的绝大部分时间。
其实这两个函数并不是必须的,完全可以在统计阶段直接访问嵌套字典,而不需要重构数据。
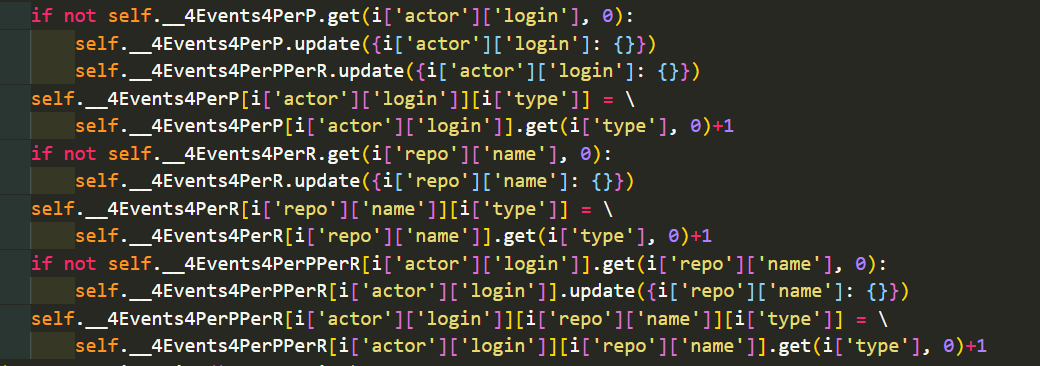
对处理数据的代码进行修改,并free掉上述两个函数和调用这两个函数的语句,再次进行实验:

速度提升很明显,把总用时缩短到了原来的一半,处理数据的耗时大幅缩短。
读取文件
读取文件部分没有发现什么大问题,所以就是提速的问题了。
-
idea one:mmap
久闻mmap大名,据说加速的效果很可观。于是找了个blog学习了一下。
mmap参考blog
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。
摸索了一段时候以后尝试着实现了一下,代替了读文件后的一些解析操作的操作,效果还不错,总时间大概缩短了1s。

-
idea two:多线程
在这之前,修改数据量都是直接批量复制多个文件,也就是目录下存在多个json文件,那么可不可以让他并行读取呢?之前在Java上做过多线程读取文件,所以也想把多线程用到读文件的部分去。这个idea其实很早就想到了,但是觉得不太好实现,事实上经过了一段曲折后,费了很大劲并没有多少提高,后来才知道python的多线程,并不是真正的并发。所以也就引出了下一个idea。
-
idea three:多进程
既然多线程不可以,那就试试多进程咯,这个总可以了吧。而且,这边并不知道有多少个文件,所以并不能用单纯的多进程,而需要进程池(multiprocessing pool)。这部分比多线程的实现更加曲折和费劲,最后代码也被我大量魔改,所以难以(lan de)复现多线程的代码和结果了。折腾了很久,重构了很多代码。这边为了解决线程调用函数返回的问题,干脆在线程中用写文件的形式保存结果,因为写文件的开销很小,进程池处理结束后再去文件读处理后的结果,这一步也顺便在写文件的过程中实现了前面提到了嵌套函数二重循环的功能,在写入循环中实现了相同功能。最后得到了一个比较理想的结果:

代码说明
读取文件,主要通过进程池调用
def readFile(self, f, dict_address):
json_list = []
if f[-5:] == '.json':
json_path = f
x = open(dict_address + '\\' + json_path, 'r', encoding='utf-8')
with mmap.mmap(x.fileno(), 0, access=mmap.ACCESS_READ) as m:
m.seek(0, 0)
obj = m.read()
obj = str(obj, encoding="utf-8")
str_list = [_x for _x in obj.split('\n') if len(_x) > 0]
for _str in str_list:
try:
json_list.append(json.loads(_str))
except:
pass
self.saveJson(json_list, f)
读文件后对进程的处理结果保存在文件中
def saveJson(self, json_list, filename):
batch_message = []
for item in json_list:
if item['type'] not in ["PushEvent", "IssueCommentEvent", \
"IssuesEvent", "PullRequestEvent"]:
continue
batch_message.append({'actor__login': item['actor']['login'],\
'type': item['type'], 'repo__name': item['repo']['name']})
with open('json_temp\\' + filename, 'w', encoding='utf-8') as F:
json.dump(batch_message, F)
单元测试
安装coverage:pip install coverage
然后找了个测试教程
测试了一下初始化函数
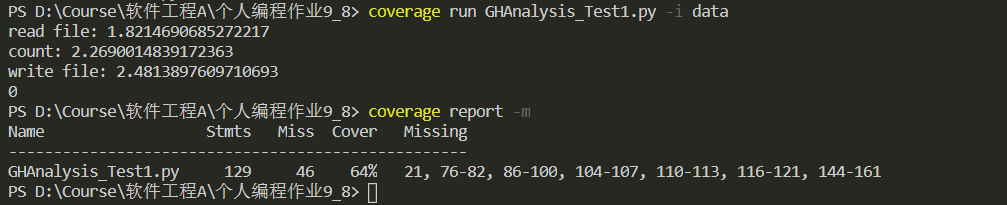
覆盖率为64%,但是我在查看具体的报告时发现,覆盖率测试把进程池调用的函数模块认定为missing.....所以实际上的覆盖率要高一点。
测试:


代码规范
my code style
总结
相当曲折和艰难的一次作业,时间比较赶,所以各方面都比较仓促和粗糙。不过也接触了很多之前没用过的工具,提高了我的专注程度,感觉就像延续了几天的建模比赛的节奏。之前的coding都没有代码规范的概念,也不会去关注性能(除了之前打oj)。总的来说收获还是蛮大的,过程中学到的东西和积累的快速学习能力都是宝贵财富。
同时也深刻理解到了python的缺点:性能。虽然打起来很快很舒服,但是终究是比不过C++和Java的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号