node抓取网页数据乱码
一、起因
抓取网页数据学习,使用node利用axios发起网络请求抓取数据时,出现以下乱码:

可以看到英文格式正确显示,中文格式乱码,这个问题感觉很是常见,无非是编码问题。
二、开始着手解决
初步:
首先查看了一下我要抓取的网页的源代码:

再查看了一下axios的官方文档:

其默认解码是utf8,那么改一下这个解码的类型变为gbk总行了吧,但是试了一下,发现无果,还是乱码:
async function get_test(id) { return await new Promise(async(resolve)=>{ let res = await axios.request( url='https://www.szxuexiao.com/Examination/html/' + id + '.html', headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763"}, responseType= 'text', // `responseEncoding` indicates encoding to use for decoding responses // Note: Ignored for `responseType` of 'stream' or client-side requests responseEncoding='gbk', // 修改解码类型为gbk ); resolve(res.data) }) }

自己的理解:
猜想1:网上说nodejs是解析不了gbk编码的,且nodejs原本就是默认utf8解析的,所以我直接返回了gbk编码,nodejs还是使用utf8解析,所以乱码;
猜想2:可能让axios指定了gbk编码,但是可能axios也不认识gbk,所以返回的还是乱码。
当然以上都是我的猜想。
为了进一步验证我的猜想,我在nodejs使用了request来代替axios发起请求:
async function getSome(){ return await new Promise((resolve)=>{ Request.get({url,headers},(err,status,resData)=>{ resolve(resData) // console.log(resData) return resData; }) }) } Request.encoding = 'gbk';//设置以gbk方式解码 let a = getSome() a.then((html)=>{ console.log(html) })
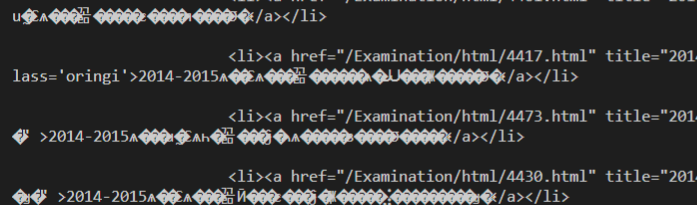
对比了我使用了request与axios指定编码格式,但是输出的还是乱码!但是我请求的页面的确是以gbk方式编码的,所以用gbk方式解码应该没有问题才对!
对比axios与request输出同一个文档的title看看有没有差异!
axios设置了以gbk编码方式解码输出:
�˽̰�2014-2015ѧ��Сѧ���꼶������ѧ�����п����Ծ�������ҳ��
axios设置了以UTF-8编码方式解码输出:
�˽̰�2014-2015ѧ��Сѧ���꼶������ѧ�����п����Ծ�������ҳ��
request设置了gbk编码方式解码输出:
�˽̰�2014-2015ѧ��Сѧ���꼶������ѧ�����п����Ծ�������ҳ��
request设置了UTF-8编码方式解码输出:
�˽̰�2014-2015ѧ��Сѧ���꼶������ѧ�����п����Ծ�������ҳ��
总结:
对比以上两个不同的库,无论以gbk解码还是UTF-8解码,都一样的结果!所以说axios与request的gbk,UTF-8编码方式解码的结论是一样的,所以问题不出在这些解码工具包身上,那么会不会出现在nodejs平台这个语言身上呢
然后看了网上给的资料:

所以我的进一步猜想是:axios与request的包是符合nodejs平台规定的,所以他们在这个平台上面其实也是 不能用gbk编码方式解码的,他们的解码方式应该和nodejs原生方式一样。
接着进行这个猜想,我进一步实验,我换个平台,使用Python下的request库,试试:
我首先使用的是 UTF-8格式看看我的解码情况。
为什么要首先使用UTF-8呢,原因如下:
(1)试试看在Python平台下用UTF-8解码的结果和用nodejs平台下的UTF-8的解码结果是否一致?
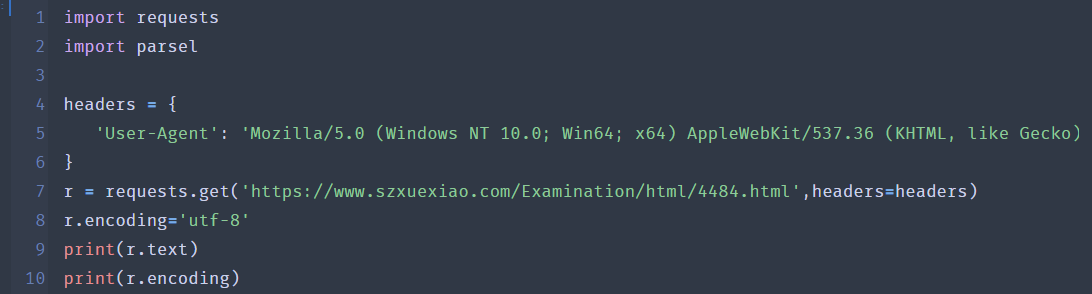
同样的title输出
�˽̰�2014-2015ѧ��Сѧ���꼶������ѧ�����п����Ծ�������ҳ��_Сѧ�Ծ�
发现结果与上面的输出结果一致!
然后在试试GBK格式解码:
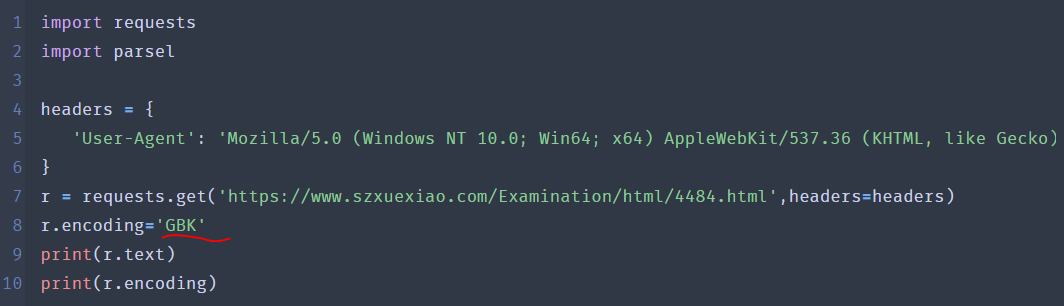
输出结果:真爽!

所以我的结论应该是:nodejs使用这些axios与request库的编码方式解码与原生nodejs是一样的,我还以为这些库有所提高,赋予了nodejs解码gbk的能力,事实证明这些网络请求并没与赋予nodejs解码以gbk方式编码的内容!
后话:
本来我想试一下axios在Python下的表现如何,但是Python好像没有这个库
----这段话是后来我写完写下的,你可以提取看------
PS:写这篇文章花了我一天,因为我用了一天的时间去了解:编码解码这个知识点,只是这点我以前不在意,
最开始接触乱码是在我大一,学校在教JSP技术,也就是大一的时候,当时只认识乱码问题是因为不同编码方式,并没与想太多,后来没有继续学习JSP,
因为总觉得这东西写个网页太慢了,偏题了,回到正题。
首先乱码问题是促使我去解决的,从而我认识到了编码解码,但是我一开始的理解是,服务端设置了编码方式,发给浏览器,通过<meta http-equiv="content-type" content="text/html; charset=gbk">
告知浏览器进行解析方式为:html,且它的编码方式是gbk,告诉浏览器以gbk方式解码,这个理解是没错的。
但是当我使用get请求时,我发现竟然使用这些网络请求模块默认都会使用encoding,也就是对我们请求到的数据再encoding,可以看看官方文档:

当时只看到了个responseEncoding:‘utf8’//default,没有认真仔细看这些注释,认为encoding就是继续编码
因为encoding的英语含义是编码,为什么还要对请求到的数据编码呢?服务器已经编码一次了,
我们此时编码,不是造成了二次编码吗,这样还解码个屁啊,当时越想越不爽,什么傻逼逻辑,就感觉好气。但是我继续顺着他的意思,觉得要编码就再编码
一次吧,到时候再解码。为什么存在这个思路呢,你等下看到我介绍的两个模块就知道了,有一个叫iconv的模块,里面有个decode方法,用来解码的,
看起来见名知意,decode嘛,那就是解码,我刚才encoding了现在就decode;
所以我又开始了我的猜想,觉得服务器端发给我们数据时,已经encoding了,当我们使用网络请求的时候,他会默认再encoding一遍,那现在我有个模块(下面会介绍),
并且这模块有个decode的方法属性,那么我就可以decode了,也就是decode两次不就好了吗,后来实验多次,都是乱码,并且后来直接全都变成问号了。
现在解释我的思路为什么会这样,因为encoding与decode本来就是反义词,但是它们再干的都是一件事,那就是根局请求到的数据,对请求数据解码,
并没有编码之说,这两个东西都在解码,为什么要用意义相反的名称,现在还是会觉得不爽,因为我觉得这个是导致我用了一天宝贵时间铺在它身上的原因,
现在画一下图,记录一下我当时的错误思维:
图1:思维较正确:

图2:所以我觉得我抓取数据,那么首先都知道要假装自己是浏览器,所以在请求体加上user-Agent:模拟浏览器的信息,企图骗过网页。所以有了以下思维:

所以一直试错了一整天:
试错的错误思维原因:
(1)认为encoding和decode是两个不同的东西,执行不同的操作;
(2)没有认真理解nodejs本身的可解码范围;
(3)没有好好看文档
(4)英语语义上的相反误导了我
然而仔细看看上面提到的request与axios都可以看到注释清晰的语义:
request:
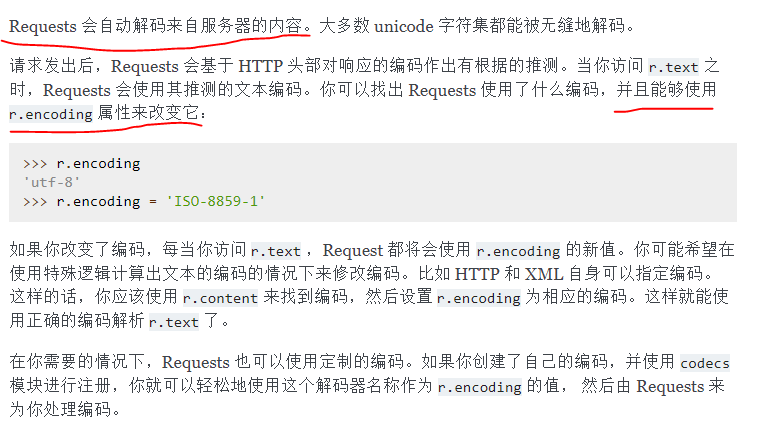
axios:

responEncoding:表示用于解码响应体的编码
注意:它会忽略stream和客户端原本的请求(的编码)。这个stream意思是流,但是什么是流的请求体,我还不懂><!
也就是官方文档都说了encoding是用来解码的,但是我根据它的意思,以为它是用来编码的。
----上面这段话是后来我写完写下的,------
接着下一步:
既然我返回的编码格式只要不是utf-8,那么nodejs就不认识,那么我返回二进制呢,不是说所有机器都认识二进制吗,返回二进制总行了吧,然后再使用其他包将二进制转码行了吧?但是原生js设计的时候根本没有想到二进制;而nodejs有个buffer的概念,专门来处理二进制的,但是如果把它转成二进制,由于gbk编码的二进制与utf8编码的二进制是不一样的,也就是:比如 "中国" 这两个字,gb2312码是 D6 D0 B9 FA,GBK码是4E 2D 56 FD,utf-8是 E4 B8 AD E5 9;所以说解析成了二进制也没办法获取想要的内容,因为nodejs本身就不认识gbk编码格式,转换成了二进制,它能对应的还是utf-8的编码表,翻译后还是错误的结果!
所以根据网上提示,推荐了两个node模块(这两个东西认识很多编码,那么gbk编码当然不在话下):
var iconv = require('iconv-lite') var encodingConvert = require('encoding');
npm install iconv-lite
iconv.decode('数据', 'gb2312');//将数据编码为gb23312格式
例子:

至于为什么上面的乱码解码后还是乱码,原因是我的字符串本身是GBK格式,然后通过nodejs的UTF-8编码格式解码的帮助下,帮我转换成这个鬼样子,所以当然用GBK解码不回来了,
因为它现在既不是UTF-8,也不是GBK.
虽然运行结果可以看到,直接传入字符串这种方法是被遗弃的,虽然它还是输出了结果,但是官方并不推荐我们使用这个格式:下面是官方的话:

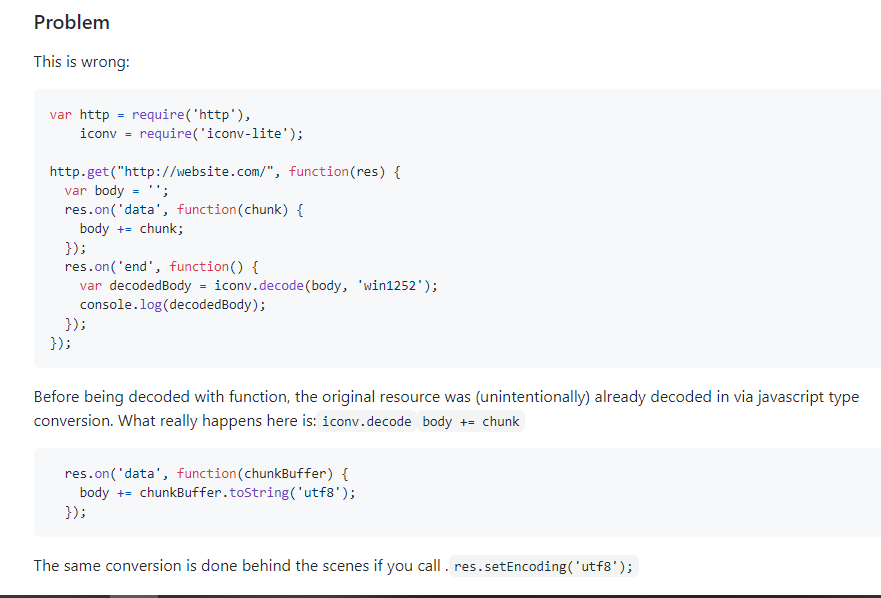
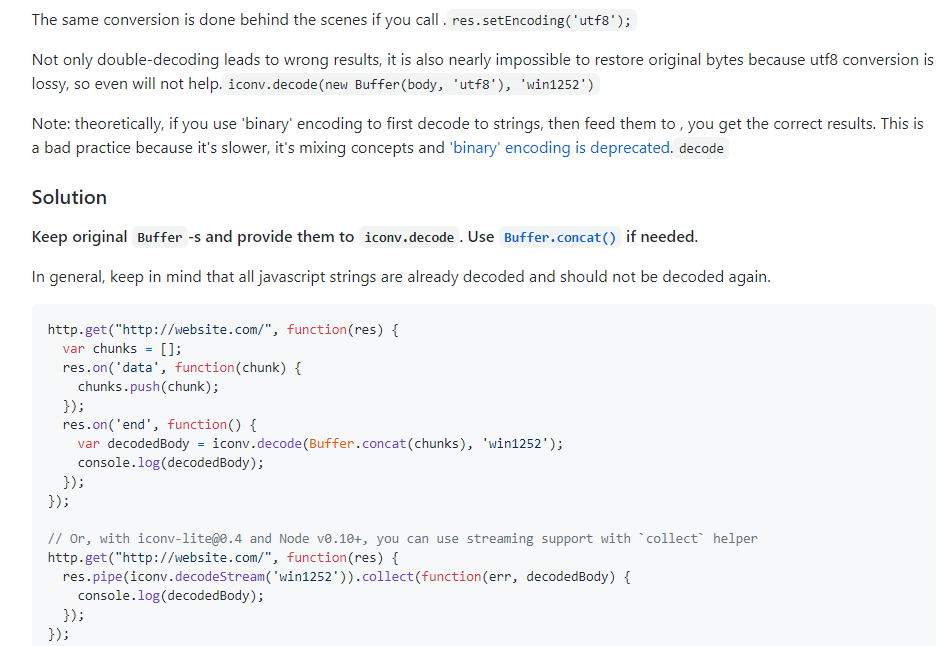

翻译一下(网页翻译有时候表达的不太准确,一切以官网为准):
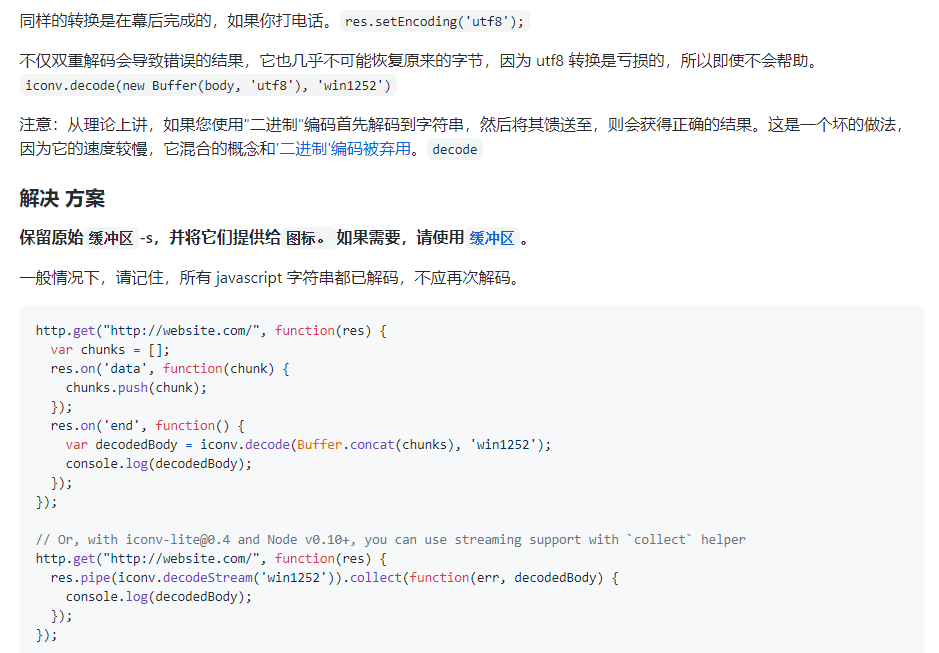
上面方法我自己的理解是,首先使用了一个http模块,然后使用里面的res.on方法监听数据,监听到数据就把它push进数组,chunk其实是一个数据块,计算机原理可以搜一下chunk的概念,数据监听完毕后使用concat把字符数组连接为字符串,并转成buffer类型,然后开始编码成win1252格式。
全文通读下来,作者告诉我们两件事:
第一:使用iconv时,推荐传入buffer数据类型,因为使用buffer数据解码效率高,因为有buffer缓冲区;
第二:使用iconv时,直接传入数据就好,然后指定解码的格式就好(此处我觉得他的decode方法并不是在解码,而是在转换编码,尽管它称为解码,但是应该叫转换编码更为贴切),
传入decode的参数buffer不需要再传入编码格式:
例子:
iconv.decode(new Buffer(body, 'utf8'), 'win1252')//这种是错误的,它指定把body数据字符串编码为utf8的buffer格式,然后在转换成win1252;想法是对的,但是内部
nodejs已经帮助我们进行这个编码操作了,不需要再指定buffer编码格式了;
iconv.decode(Buffer.concat(chunks), 'win1252');//这个为正确操作
let body = Buffer.concat(chunks)//这个为正确操作
iconv.decode(body, 'win1252');
encoding 安装使用
1. 安装
npm install encoding
2.使用
encoding 模块就一个方法 convert(),使用方法为:encoding.convert(text, toCharset, fromCharset)。
text: 需要转换的对象,可以为 Buffer 或者 String 对象。
toCharset: 转换后的编码。
fromCharset: 转换前的编码,缺省为 uft8。
例子:

输出:buffer(nodejs不认识二进制,它认识buffer,因为这个是他定义来代替二进制的)

Buffer 介绍
在客户端javascript脚本代码中,对于二进制数据并没有提供一个很好的支持。然后在nodejs中需要处理像TCP流或文件流时,必须要处理二进制数据。因此在node.js中,定义了一个Buffer类,该类用来创建一个专门存放二进制数据的缓存区。
一句话概括: Buffer 类是一个全局变量,用于直接处理二进制数据,提供工具类方法。
官网上关于 Buffer 解释的非常清楚。可以去nodejs官网查看更加详细的介绍。
三、解决方案
首先:本来是不用这些字符编码模块的,直接在网络请求时设置解码格式,我们就能得到正确数据,但是偏偏原生nodejs不认识GBK编码,导致axios与request设置了GBK编码方式解码还是无效,大概示意图如下:

所以接下来使用上面两个模块中的iconv模块解决问题:
方案1:
request+iconv(request可以指定不对服务器返回的数据进行解码,所以我们不设置解码,因为即使他解码了,nodejs也看不懂)
(1)使用request不解码,直接把数据发出去交给iconv处理
async function get_test(id) { return await new Promise(async (resolve) => { await request({ url: "https://www.szxuexiao.com/Examination/html/"+id+'.html', headers:headers, encoding: null // 关键代码,设置请求数据不编码 },(err,status,resData)=>{ resolve(resData) return resData; }); }) }
(2)iconv处理buffer流,并且把buffer流翻译成gbk,再转换成字符串输出:
a.then(html=>{ console.log(html) var html = iconv.decode(html, 'gbk')//将请求数据编码为gbk })

示意图:

本来想给一下axios的处理方案,但是它官方并没有给出可以设置编码格式为null,即不编码,大概是它认为它可以处理大部分的编码,而忽略了nodejs这种只能处理少量编码的特性了吧。所以axios请求的数据返回给我们一定是经过解码处理的的,所以不管我们对axios返回的数据再进行任何解码都会造成二次解码,数据乱码,所以此处无法给出axios的解决方案。
方案2:和官网一样使用http,不过我爬的是htpps的网页,所以使用https
首先下载直接 npm install http --save 或者 npm install https --save
let https = require('https')
var iconv = require('iconv-lite')
let url = 'https://www.szxuexiao.com/Examination/html/4484.html'
https.get(url, function(res) {
var chunks = [];
res.on('data', function(chunk) {
chunks.push(chunk);
});
res.on('end', function(res) {
// 将二进制数据解码成 gb2312 编码数据
var data = iconv.decode(Buffer.concat(chunks), 'gb2312');
console.log(data)
});
});
此处不用encoding模块是因为其如果接受的数据为buffer或字符串,但是输出的仍然是buffer不是字符串,不是我们要的数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号