
juiceFS培训
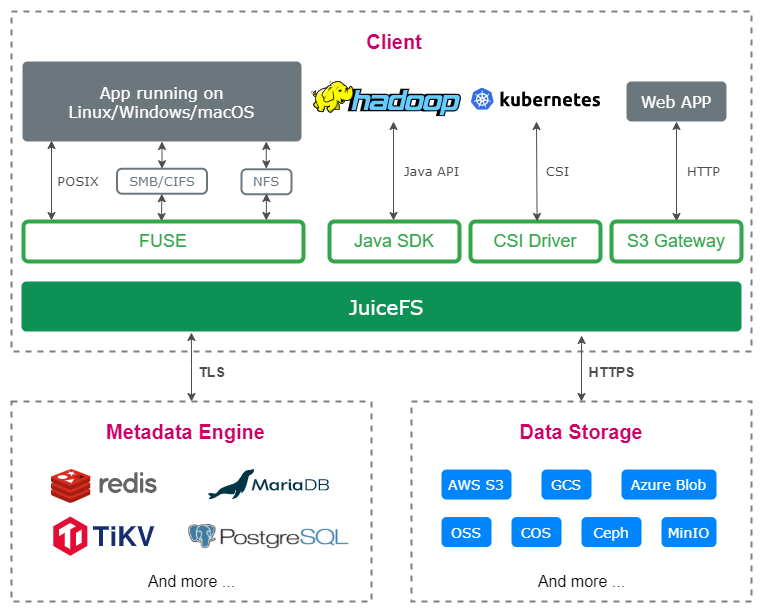
- fuse-client
JuiceFS 挂载客户端:即下图的 jfsmount, 它负责跟元数据服务和对象存储通信,并通过 FUSE 实现 POSIX API
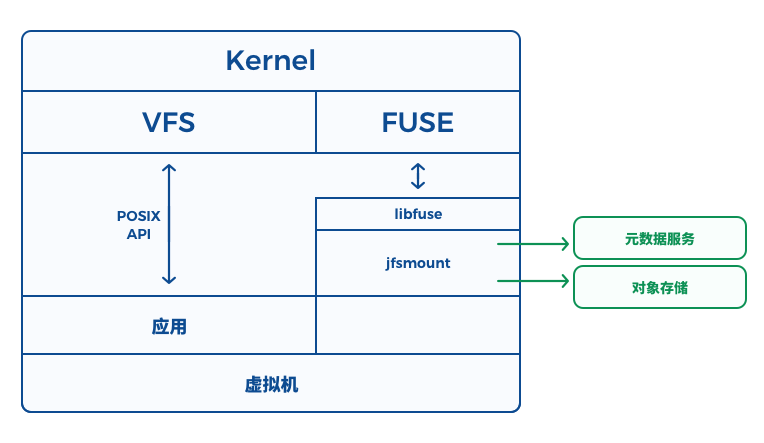
- vfs 模块:
负责 POSIX 语义实现
- 数据操作会进行chunk粒度的拆分,调用chunk模块接口;
- 元数据操作调用meta模块接口
- chunk 模块
负责数据上传下载,同时通过 object 模块适配不同厂商
- meta-client 模块
负责与 meta-server 交互
- meta-server
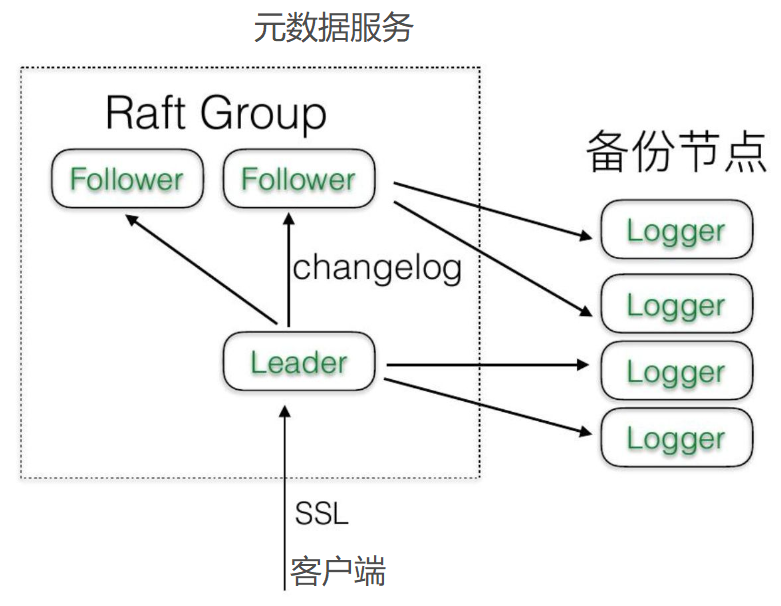
元数据服务是一个 Raft 集群,实现高可用时保证数据的强一致性。
支持多shared:meta 可拆分 zone (即shard), inode 数太多的子树根据策略移到一个合适的 zone-root下
- zone-0 是所有inode(64bit)的入口
- 后台可为每个zone集群规划leader-follow-logonly(配置优先级),故障恢复后leader切回原位
- zone之间子树分布可能不连续,后台会定期根据策略把小子树迁移回parent。
- 每个节点上的SSD盘是所有shard共享的,扩盘后台也会自己均衡
- 如果扩meta节点比较麻烦,需要人工介入,因为client配置了DNS
需要client配合调整,并保证切换原子性
- 工具 move src_sub_tree dst_sub_tree 通过CAS 保证一致性
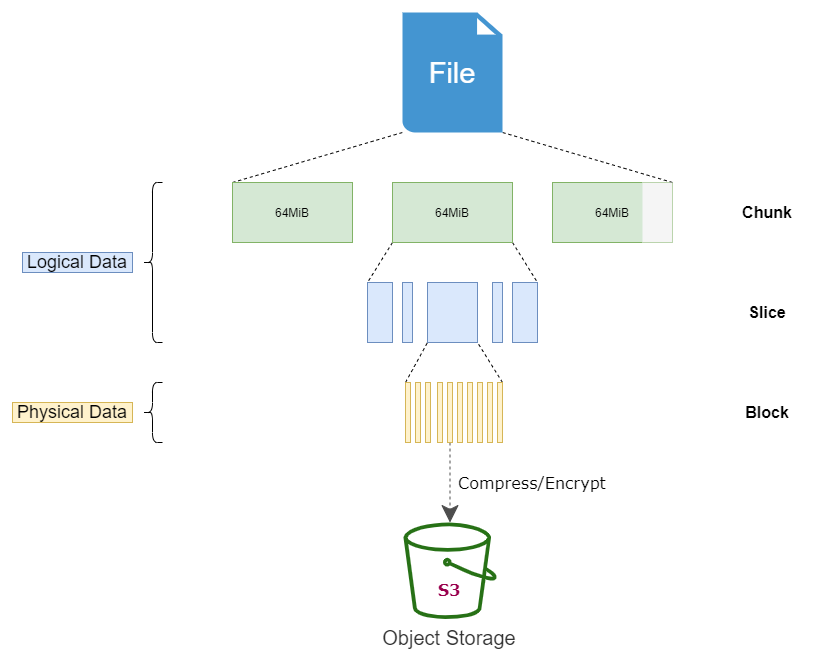
文件格式:
- chunk:一个文件首先被拆分成固定大小的 "Chunk",默认 64 MiB
- slice:每个 Chunk 可以由一个或者多个变长的 "Slice" 组成,考虑到覆盖写的支持,slice之间是可以有数据逻辑地址重叠的情况.
如果slice 写完chunksize或创建超过5s就会flush到对象存储
当一个chunk的slice过多的时候,会进行compactChunk操作
- block:每一个 Slice,又会拆分成固定大小的 "Block",默认为 4 MiB(格式化后就不可以修改)。最后 Block 会被压缩和加密保存到对象存储中。压缩和加密都是可选的。
- 文件锁:支持 BSD 锁(flock)及 POSIX 锁(fcntl)
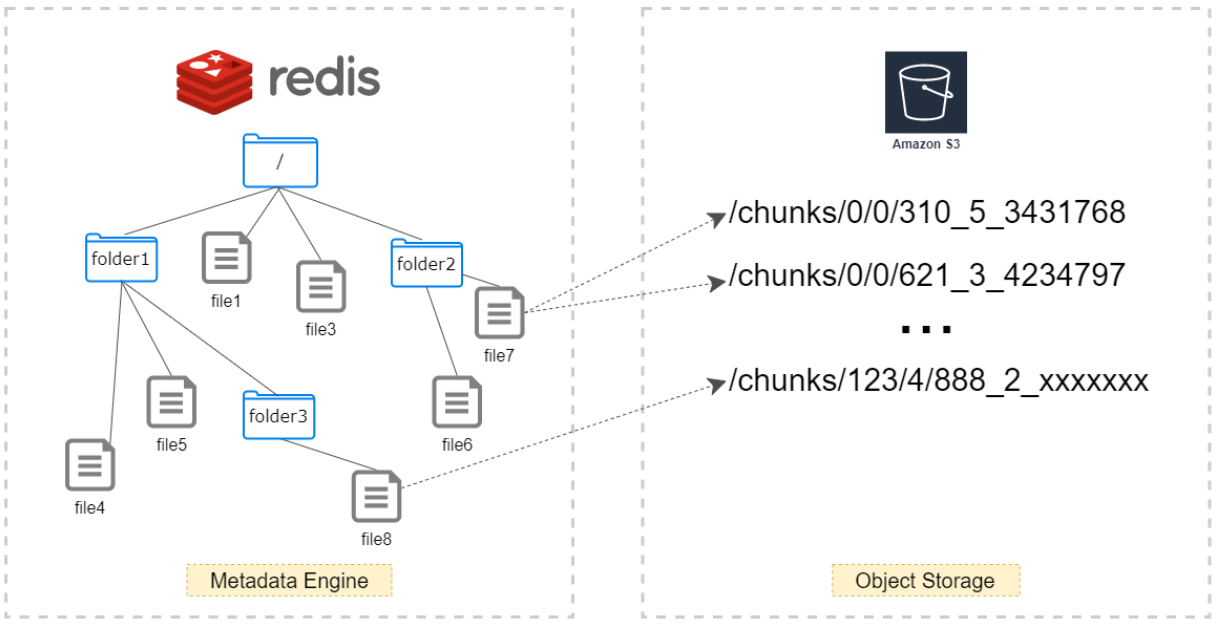
对象名构成
chunks / (chunkID/1000/1000) / (chunkID/1000) / chunkID_blockIndex_blockSize
多分区对象名
chunks / (chunkID%256) /(chunkID/1000/1000) / (chunkID/1000) / chunkID_blockIndex_blockSize
chunkID:chunk 的全局 id
blockIndex:chunk 内 block 的 index
blockSize:block的大小,最大4M,可能小于4M
元数据数据结构:
d + inodeHSet/Map存放目录属性信息
i + inodeRaw/String 存放文件的基本属性
c + inode + chunk_indexList 存放 chunk 相关的 block 信息
posix 流程详解
- create流程
主要调用 meta 模块的 create 接口,流程中封装了一个事务,包含以下操作:
- 获取父目录的属性,即目录 key = d+parent_inode 的值
- 获取父目录中是否有该文件,即 d+inode 的 name 作为 key 去查询
- 在父目录中写入该文件name,即d+inode中插入一个key-value,
key为文件name,value为文件类型+文件inode number
- 修改父目录属性,更新父目录信息,即插入i+parent_inode key的值。
- 新增文件元数据,即插入一个i+inode的key。
- lookup流程
主要调用 meta 模块的Lookup接口,先在父目录中查找该文件name是否存在,即d+parent inode中查找name,通过value解析出inode;如果存在获取到inode,然后根据inode在获取文件key,拿到文件属性。
- 写流程
写流程主要是根据offset,len等计算当前io落在哪个chunk index, 以及是否有缓存slice。如果没有则创建新的chunk或slice,如果slice已经用完,也会创建新的chunk,写入slice之前,要确保前面的slice已经刷盘以保证IO顺序。
数据只写到slice中的page字段缓存中就返回了,之后写入缓存,可能是内存或者磁盘缓存,写满一个chunk就flush到后端S3,否则就先放到缓存里面等待被动flush。
数据下刷主要依赖 commitThread和flushData 两个协程的配合:
在write流程中,一个chunk的slice会在被第一次生成的时候产生一个协程commitThread,用于清理已经done的slice,将slice的信息记录到meta中。如果当前的slice没有done,则创建flushData协程。
flushData携程通过 meta 获取一个chunk id,并将slice中的数据flush到s3中,然后标记为done。所以每个slice会对应有一个唯一的chunkid。
当数据flush到s3后commitThread会对 meta 中c+inode number + index的key插入一条slice的信息,进行元数据更新。
对于可能存在的读缓存使失效。对于覆盖写每次都会新启用一个chunk id来进行写,而对于追加写按照上面的逻辑,如果slice已落盘则会新启用一个chunk,而slice没落盘则会复用老的slice进行写。
查找chunk和slice都是根据offset和length来确定的,offset可以确认要写入的chunk和slice,length则可以确认要写入多少个slice
内核里 fuse writeback 参数,太小的写入会作合并,writeback 帮助小文件更快
多个 4MB 滚动窗口往对象写入,
小文件 < 4MB, 不会马上落 oss,要显式flush或close
buffer-size (5s 自动flush) 尽量保障可见
内核pagecache
meta跟踪哪些client打开哪些文件 有没有变化
从meta拿到chunk信息,meta会告诉client 是不是可以从cache取
(你上次取过且没有变更)cache如果没找着就重新取。
举例说明:
- 场景1 :追加写 dd=/dev/uradom of=/mnt/test/test1 bs=1M count=9
数据:63_0_4194304,63_1_4194304,63_2_1048576
元数据:slice1{chunkid:63;offset:0;len:9M}
- 场景2: 在上面的基础上覆盖写0~1M。
数据:63_0_4194304,63_1_4194304,63_2_1048576 64_0_1048576
元数据:slice1{chunkid:63;offset:0,;len:9M};
slice2{chunkid:64;offset:0;len:1M}
- 读流程
根据offset,len和缓存slice(offset,len,data)将原有的offset len划分为多个block。
划分后的block,必然有的在缓存中,有的不在缓存中。不在缓存中的blcok在重新生成slice。
新的slice调用run协程去s3读取对应的数据。这里有一个问题,对于覆盖写场景,如写流程里的例子,0~1M是有新老2份数据,如何知道哪份是新的数据?由于chunkId是递增的,所以chunkid越大的肯定是最新的,同时元数据的slice采用list的管理,在读取chunk所有的slice的时候,会对将overlap的slice进行切分,并且用后面的元数据覆盖前面的。
等待所有slice数据都获取到(这里通过slice的一个状态来判断是否从s3中已读取到数据,如果没有读取到则一直等待),进行数据拼接,并返回给client。
读性能,粒度不要太小,
预读窗口大小与oss性能有关系,如果oss快就窗口小一些
单文件预读窗口 32M 和 buffersize 是共用的
缓存盘 只有一块 可能性能还不如 oss 快,可以配置缓存只用来缓存随机读
顺序直接去oss 读
随机读多就把压缩关闭
JFS 客户端需要额外使用 300~500 MB 内存用来预读数据,提高性能。所以在使用 Spark 的时候,建议每个 executor 配置多个 cpu 的方式去使用。 因为每个 executor 使用一个 JFS 客户端,一个 executor 内多个 task 可以共享这部分内存。
元数据更新
所有客户端随机连接meta,如果连接的是follower会返回当前leader的IP地址,客户端永远连接的是leader
对其他客户端立即可见(open after close)
从节点可以配置同步落盘(由SSD来保证性能),当前默认异步落盘,因为是公有云多AZ保障
所有元数据都会加载到内存,修改会不停的append changelog
内存数据会定期快照 48h 做 rotate
需要长期保存可以rsync到外部廉价的hdd盘
数据恢复:meta.py 最新快照+changelog
历史snapshot和changelog 建议长时保留,可 rsync 放到廉价 hdd 上
一种部署方式 leader+follow(热备)+logonly(冷备)
logonly不长驻内存
监护进程meta.py,需要开机自动启动
对象数据
通过 write() 新写入的数据会缓存在内核和客户端中,可以被当前机器的其他进程看到,其他机器暂时看不到。
调用 fsync(), fdatasync() 或 close() 来强制将数据上传到对象存储并更新元数据,或者 5 秒钟自动刷新后, 其他客户端才能看到更新,这也是绝大多数分布式文件系统采取的策略。
所有被删除的文件将会在其中保存一段时间。用户可以登录 控制中心,通过其中的回收站标签页删除或恢复其中的文件
什么情况下会进行后台数据重整
- meta发现文件的block碎片多 会发任务给client去重整
- 如何控制进展: 暂停、client通过token来定位client的角色
可以不接受meta的任务 就不会参与重整
- 不重整的话 meta内存消耗太大。
- 哪些参数会影响数据重整
- 哪些写入模型会影响数据重整
- 文件删除
- 重整开关
- 重整时段
- 重整流量控制
暂时没有调整入口
特别说明
1. 该⽂档中列出的 shell 命令, # 开头表示需要 root 账号执⾏, $ 符号表示可以不⽤ root 账号运⾏。
2. uiceFS 相关的命令,通过公⽹安装的 meta.py 和 juicefs 脚本是直接下载到 /root ⽬录。离线安装的 juicefs-console 、 meta 、 mount 都是直接安装在 /opt/juicedata/ ⽬录下,如果想安装到其它⽬录 ⽐如 /data/apps/ 下,请注意替换掉命令中的⽬录信息。
3. 镜像归档⽂件或者安装包中的⽇期仅代表特定的镜像版本或者⽂件⽣成⽇期,在实际操作中也需要根据具体的 时间变动。
4. ⽂件系统挂载的路径都是 /jfs ,实际环境中可以设置成其它⽬录
有外网,去官方控制台认证
- 注册账号
JFS管理员将您的账号添加 Enterprise Trial 试用权限
- 准备好您的存储桶
S3-Bucket
S3-AK
S3-SH
- 创建私有区域(Region)
- 代号名称(字母,数据,连接符-)与公有云保持体验一致
- 选择 S3
- 填写可识别的唯一性的描述,创建文件系统的时候显示在可用区列表里
- 添加meta集群ip,参考集群的
/etc/hosts
- 规划meta端口,不要与集群中其它应用冲突
- 生成
meta.py和执行脚本,记录您的 JFS-Token 令牌
- meta 部署
- 在对应ip上执行上一步生成的脚本
meta.py --token xxx --ip x.x.x.x
如果meta集群没公网还可以创建离线安装包离线安装
-
ps -ef |grep meta可查看/root/.juicefs/meta进程
meta.py status 查看meta运行情况
- meta配置及日志目录
/var/lib/jfs/xxx-x/
- 在区域上创建“文件系统”
- 填写文件系统名称
- 选择区域“亚马逊”+“您创建的私有区域描述”
- 桶名称格式:
http://{bucket-name}.{s3-endpoint}
例如 http://mybucket.s3.xsky.com:7480
其中s3.xsky.com:7480 是对象路由/存储网关, 支持 ip:port 形式
- 压缩:当大数据场景需要存储 parquet、orc等文件时,选择
Uncompressed
所有 client 都需要配置
1. /etc/hosts 配置 S3网关IP和域名映射
2. 配置 jfs client cache-dir 目录
3. 配置 jfs client max-uploads 数目
4. 配置 jfs client buffer-size
默认情况下 CentOS 6 不会在启动后自动挂载网络文件系统,
需要运行 sudo chkconfig --add netfs 来使能
上述命令可以封装成 shell 文件 setup-juicefs.sh
然后使用以下命令一次挂载:
./setup-juicefs.sh $JFS_NAME $JFS_TOKEN $ACCESSKEY $SECRETKEY $JFS_MOUNTPONT
手动安装 JuiceFS Java 客户端
- 下载最新的 juicefs-hadoop.jar, 加入到应用的 classpath 中,
可通过 hadoop classpath 命令查看 classpath 路径
P.S. 很多应用有默认放置 JAR 文件的目录,放在那些目录中会被自动加入到 classpath 中。
- 配置 core-site.xmsl 添加配置参数
- 将 mount/conf ⽬录下的 *.conf ⽂件分发到集群各个机器上,
放置地址是 core-site.xml 中 juicefs.conf-dir 所配置的⽬录下的 .juicefs 目录
例如: juicefs.conf-dir=/etc/juicefs ,则 conf ⽂件需要放到 /etc/juicefs/.juicefs ⽬录下,注意需要 所有⽤户有可读权限
- 激活 parcel: CM首页 > 主机 > parcel > 分配|激活
- 配置 core-site.xml
群集范围高级配置代码段(安全阀)以xml编辑,粘贴以下内容, 然后切回视图编辑检查
juicefs.memory-size 使用堆外内存,
要根据物理内存和大数据组件内存分配情况规划
Hadoop 修改默认文件系统,
修改这个配置不能重启,只能在cdh集群范围内 “部署客户端配置”
- 下载 hdp 安装文件
下载文件解压后放到 /var/lib/ambari-server/resources/stacks/HDP/{YOUR-HDP-VERSION}/services
- 重启 ambari
- 添加 JuiceFS 服务
打开 Ambari 管理界面 -> Services -> Add Service -> JuiceFS -> 选择安装机器 -> 配置 -> deploy
在配置步骤,主要是配置缓存目录(cache_dirs)和下载版本(download_url)
如果 Ambari 没有外网,可以直接将下载好的 jar 包收到放到 share_download_dir 下,默认为 HDFS 的 /tmp 目录
- 升级 JuiceFS
修改 download_url 的版本号,保存并 Refresh configs
- 通过 Ambari 修改配置
- Hadoop
通过 HDFS 服务界面修改 core-site.xml
- MapReduce2
通过 MapReduce2 服务界面修改配置 mapreduce.application.classpath,
- 在末尾增加
:/usr/hdp/${hdp.version}/hadoop/lib/juicefs-hadoop.jar(变量无需替换)。
通过 Ambari 修改配置
通过 HDFS 服务界面修改 core-site.xml,具体配置见详细配置表。
通过 MapReduce2 服务界面修改配置 mapreduce.application.classpath,
在末尾增加 :/usr/hdp/${hdp.version}/hadoop/lib/juicefs-hadoop.jar (变量无需替换)
通过 Hive 服务界面修改 hive-env, 在下图位置添加如下配置:
通过 Hive 服务界面修改 hive.metastore.warehouse.dir,可修改 hive 建表默认位置(非必须):
如果启用 LLAP ,还需要修改 hive-interactive-env:
如果配置了 Ranger 服务,则需要配置 HIVE 服务 ranger.plugin.hive.urlauth.filesystem.schemes,追加 jfs 支持
通过 Druid 界面修改目录地址(如无权限,需手动创建目录):
使用 Sqoop 将数据导入 Hive 时,Sqoop 会首先把数据导入 target-dir , 然后在通过 hive load 命令将数据 加载到 Hive 表,所以使用 Sqoop 时,需要修改 target-dir。
使用 1.4.6版本 Sqoop 时还需要修改 fs, 此参数修改默认文件系统,所以需要将 HDFS 上面的 mapreduce.tar.gz 复制到 JuiceFS 上的相同路径,默认目录在 HDFS /hdp/apps/${hdp.version}/mapreduce/mapreduce.tar.gz
1.4.6版本 Sqoop
最后,重启相应服务让配置修改生效。
无外网,无法去JFS官网校验Tocken,需要在“私有区域”下载离线安装包
cp 到 /opt/juicedata/ 下,填上控制台创建时的IP和文件系统NAME
- meta目录 在元数据服务器上执行
- mount目录 在客户端服务器上执行
通过 JuiceFS 控制台私有区域详情⻚,离线安装栏⽣成并下载最新的离线安装包
- 仅更新配置
如果只需要更新配置, 如在控制台新增⽂件系统 Volume ,或者某些⽂件系统增加了配额或者 ACL 规 则,⽆需重启元数据服务的进程。
将安装包解压后的 meta/conf/{{IP}}/meta.conf ⽂件复制到相应元数据服务器节点的 /root/.juicefs/meta.conf 替换原来的 meta.conf ⽂件,
执⾏如下命令加载新配置:
- 升级⼆进制
如果需要升级新版本,有新的功能增强或 bug 修复,需要使⽤新的可执⾏⽂件启动元数据服务。 将安装包解压后的 meta ⼦⽬录复制到所有元数据服务器节点,替换原来的 meta ⼦⽬录,重新执⾏⼀遍安装命 令完成升级。
其中 {{juicefs-pkg}} 表示从 JuiceFS 官⽹下载的离线安装包, {{IP}} 表示当前元数据服务器节点的 IP。
将安装包解压后的 mount ⼦⽬录复制到所有客户端节点,替换原来的 mount ⽬录,进⼊ mount ⽬录,执⾏如下命令升级:
无外网,需要多部署一个控制台,含集群监控,维护和升级功能, 部署 JuiceFS 控制台的服务器需要能够访问部署元数据服务的节点
环境要求:
1. 需要提前安装 docker & docker-compose
2. p8s (prometheus) & grafana 均使用官方 latest 版本
无官方用户需要 docker image save 和 docker image load 提前准备容器镜像
## 在有外⽹的机器上导出 Prometheus 和 Grafana 镜像的离线版本
$ docker pull prom/prometheus
$ docker pull grafana/grafana
$ docker image save --output=p8s-grafana.tar prom/prometheus:latest grafana/grafana:latest
$ gzip p8s-grafana.tar
## 上述命令都执⾏成功后会在当前⽬录⽣成⼀个 p8s-grafana.tar.gz 的⽂件,将这个⽂件传输到要部署 JuiceFS 控制台的服务器上
## 下列命令是在要部署 JuiceFS 的服务器上执⾏
$ gunzip p8s-grafana.tar.gz
$ docker image load --input=p8s-grafana.tar
$ docker image ls | awk '{print $1":"$2}' | grep -E '(prom/prometheus|grafana/grafana):latest'
## 上述最后⼀条命令输出如下信息则说明导⼊成功 grafana/grafana:latest prom/prometheus:latest
- 获取 juicefs-console-2021.04.22.tar.gz 的 docker 镜像
- 下载离线安装包
- init-data 含控制台启动的初始 化数据
- meta
- mount
- 准备运行目录
运⾏⽬录位置可以根据实际情况⾃由设定,为了便于⽂档的描述,假定 juicefs-console 安装到 /opt/juicedata/juicefs-console ⽬录。
将离线安装包解压,并将 JuiceFS 控制台镜像⽂件放置在该⽬录下:
在 /opt/juicedata/juicefs-console ⽬录下会出现⼀个 {{region-code}}-{{region-ID}} 的⼦⽬录,类 似如下结构:
在当前⽬录下新建 .env ⽂件,将当前节点的 IP 地址填在 WEB_SERVER 变量中,如果当前节点有多个 IP 地址, ⽤逗号分隔,⽐如当前节点的 IP 地址有 2 个,分别为 192.168.64.1 和 10.223.5.8
运⾏ JuiceFS 控制台会启动 3 个容器,要占⽤ 3 个端⼝,控制台默认使⽤ 8000 端⼝,Prometheus 默认使⽤ 9090 端⼝, Grafana 默认使⽤ 3000 端⼝,如果要更改这些默认值,分别在 .env ⽂件中设置 CONSOLE_PORT , P8S_PORT , GRAFANA_PORT 变量即可。⽐如要将控制台端⼝变为 8001 ,将以下内容添加到 .env ⽂件。
JuiceFS 控制台默认使⽤的 SQLite 数据库,如果需要使⽤ MySQL 数据库,需要在 .env ⽂件中设置 MySQL 的连 接信息
如果需要使⽤ MongoDB 数据库,需要在 .env ⽂件中设置 MongoDB 的连接信息:
.env ⽂件会被 bash 执⾏,变量赋值的等号 = 两侧不能有空格
- 安装并启动
如果执⾏成功,最后会显示通过 Grafana API 创建两个 Grafana 的 dashboard 成功的 Response,后续可以通过 这两个 URL /d/jfsvolume/juicefs-volumes 和 /d/jfsvolume/juicefs-volumes 访问 JuiceFS 的监控⾯板 。
./bootstrap.sh 执⾏成功后会启动 3 个容器,通过 docker-complse ps 查看
这是⼀个 docker-compose 管理的应⽤,可以使⽤ docker-compose 的各种命令,⽐如查看控制台的⽇志:
如果上述⽇志没有任何异常,通过以下命令验证 JuiceFS 控制台是否正常⼯作:
正常情况会返回纯⽂本: JuiceFS API
假设控制台对外访问的 URL 是 {{JFS_CONSOLE}} ,后续⽂档中访问私有控制台都使⽤这个表示。
在 JuiceFS 官⽅控制台 的 私有区域 选择新建的私有区域,进⼊私有区域详情⻚,参考 「部署⽅法」 部分(如前 ⽂ 创建私有区域 第 4 步截图所示),将各节点部署命令中的 https://juicefs.com/static/meta.py 换成 {{JFS_CONSOLE}}/static/meta.py ,其它保持不变,在各节点执⾏即可完成元数据服务的部署。
对于已经创建在当前私有区域的 JuiceFS ⽂件系统,在 JuiceFS 官⽅控制台 的 ⽂件系统 列表选择该⽂件系统,进⼊ ⽂件系统详情⻚,参考 「挂载⽅法」 部分(如前⽂ 创建⽂件系统 中的⽂件系统详情图⽚),将挂载命令中的 https://juicefs.com/static/juicefs 替换成 {{JFS_CONSOLE}}/static/juicefs ,其它保持不变,在客 户端执⾏即可完成⽂件系统的挂载。
私有化部署环境可能不能解析元数据服务的 DNS 域名,需要将离线安装包中的 mount/conf/hosts 的内容加到 挂载节点的 /etc/hosts 中,否则客户端会报⽆法解析域名的⽇志。由于客户端配置⽂件中已经有元数据服务的 IP 列表,客户端的正常使⽤不受影响。 设置开机⾃动挂载请参考「开机⾃动挂载」。 命令⾏更多使⽤⽅式参考官⽅⽂档
- 控制台升级
需要和Juice沟通具体升级方案
- meta或client升级
找私有控制台挂载的本地volume
从JFS官网下载最新版本替换该目录下的静态文件,⽆需重启 JuiceFS 控制台
chmod a+rx xxx
- 升级元数据服务
- 升级客户端
当前运⾏的元数据服务是通过离线部署的⽅式启动的,启动类似命令为:
{{IP}} 为当前节点的 IP 地址。假设假设新控制台访问地址为 http://juicefs.example.com ,逐节点依次执 ⾏如下命令,确认当前节点进程 启动成功 了再开始下⼀个节点
{{IP}} 为当前节点的 IP 地址, {{TOKEN}} 为当前私有化部署的 token,所有的节点都⽤这个 token ,这个值是 /root/.juicefs/meta.conf (配置⽂件内容是⼀个 JSON 数组)第⼀个数组元素的 token 属性的值。
当前挂载⽂件系统是通过使⽤离线配置⽂件的⽅式挂载的,启动类似命令为:
{{VOLUME}} 为挂载的 JuiceFS ⽂件系统名称。假设假设新控制台访问地址为 http://juicefs.example.com
{{VOLUME}} 为挂载的 JuiceFS ⽂件系统名称。
CDH > hbase > hbase-site 过滤
添加以下高级配置,覆盖默认的 rootdir
JFS 的 hflush 默认是 writeback 模式
有丢失数据的风险,建议把 hbase 的 wal 配置在 hdfs 上
在HDFS上,WAL的默认路径是 /hbase/WALs/,
用户可以通过添加 hbase-site 高级配置 hbase.wal.dir 进行配置覆盖
JFS ⽀持设置⽬录的数据容量和 inode 个数限制。进⼊官⽅控制台的⽂件系统的 quota 配置⻚ ⾯: https://juicefs.com/console/vol/{volume}/quota ,其中 替换成实际的⽂件系统名称, 增加或者删除 quota 记录。
⼀条 quota 规则需要提供 路径、Inodes、容量 3 个值
- 路径:⽬录绝对路径,可以使⽤ * 通配
- Inodes:⽬录下总 inodes 个数限制,达到这个限制后将不能在⽬录及其⼦⽬录下新增⽂件
- 容量:⽬录及⼦⽬录下总数据容量限制,达到限制后将⽆法再写⼊数据
注意
- 路径需要以 / 开头的绝对路径,⽐如 /subdir1 匹配该⽂件系统下第⼀级⽬录 subdir1 的的配 置, /subdir2/* 匹配该⽂件系统下 subdir2 下的所有⽬录如 /subdir2/aaa 、 /subdir2/bbb ,不包含 再下⼀级⽬录如 /subdir2/aaa/ccc 。
- Inodes 后缀可以是 K, M, G, T, P 等,⽐如 10K, 20M, 5G 等。
- 容量后缀可以是 KB, MB, GB, TB, KiB, MiB, GiB, TiB ,⽐如 50GB , 100GiB , 1TiB 等。
配置好后在 私有区域 详情⻚⾯,下载离线安装包,其中 meta ⼦⽬录包含了新增的 quota 配置,按升级元数据服 务步骤执⾏更新元数据配置即可。
meta 多 shard 版本
使⽤ ls -il 可以看到⽂件的 inode, 它的 100亿以上的部分表示分区号,100 亿以内的部分是它在该分区内所使⽤的内部 inode(32位)。通过查看⽂件和⽬录的 Inode 可以知道它所在的分区。 通过 cat /jfs/.zonemap 可以看到所有⼦树在各个分区中的分配情况,以及它的⼤⼩
shard 负载均衡策略:
多个分区之间主要关注⽂件数量的均衡,⽽⾮访问压⼒的均衡。在适当调整数据分配策略,也可以实现访问负载的均衡。
基于CAS(compare and swap)乐观锁
- 创建⽂件时,都会使⽤⽗⽬录所在的分区,不会迁移。
- 创建新⽬录时,会有以下3 中策略。
如果⽗⽬录所在的分区的 inodes 数量⽐最少分区的 inode 数据量多 minBalanceDiff (默认 值: 1048576 ),并且⽗⽬录⾥所有的 inodes 数量多于 minDirInodes (默认值: 1048576 ),会将新建 的⽬录迁移到 inodes 最少的分区以实现⻓期的负载均衡
随机选择⼀个区存储新⽬录(先⽗⽬录所在分区创建,然后迁移)
百分⽐:100 是完全随机
挂载时设置环境变量 JFS_AUTOPART=N 在⽗⽬录所在分区创建⽬录后,把它拆分成 N 个虚拟⼦⽬录,并且将不同的虚拟⼦⽬录迁移到不同的分区。
- N 为 0 不拆分
- 1 表示按照集群分区数进⾏拆分
- ⼤于 1 表示拆分的个数
当⼀个迁移后的⼦树的 inodes 数据少于 10000 个时,且改⽬录的创建时间超过 1 天,会将它迁移到 它的⽗⽬录所在的分区,这样可以避免⼦树过于碎⽚化。
当⼀个⽬录中的⽂件数过多时,会影响内存中的数据压缩,也会影响 ls 的性能,也可能导致某个分区过载。服务器会⾃动对⽂件数超过 100000 的⽬录进⾏拆分成默认 17 个虚拟⼦⽬录,这些⽂件会按照哈希规则分配到某个虚拟⼦⽬录去
使⽤ .jfs#X 可以查看虚拟⼦⽬录⾥的内容:
这些虚拟⼦⽬录也可以进⼀步拆分,或者迁移到其他的分区去,进⼀步实现负载均衡。
也可以⼿动对某个⽬录做拆分:
如果需要迁移的⽬录太⼤,它会尝试把它分成多棵⼩的⼦树来迁移。 ⽬前迁移的⽂件有⼀些限制(不能处于打开状态,不能包含碎⽚,不能是硬链接,单个⽂件不能太⼤),如果存在 不能被迁移的⽂件,会导致该操作部分失败,不影响使⽤。
当想要把某棵⼦树迁移到 某个分区时,使⽤下⾯的命令:
私有控制台集成了 Prometheus 和 Grafana,并且导⼊了两个 Grafana 监控 Dashboard 模板,只需要更改实际部署的元数据 DNS 和⽂件系统名字就可以使⽤。
Grafana 默认监听 3000 端口,默认账号和密码都是 admin ,这两个监控⾯板分别是监控元数据服务状态和⽂件系统访问情况, 访问地址为:
- http://{{CONSOLE_IP}}:3000/d/jfsmeta/juicefs-meta-info
- http://{{CONSOLE_IP}}:3000/d/jfsvolume/juicefs-volumes
配置两个变量(点击右上角设置图标,修改变量)
- datasouce 使用控制台默认的 promethues
- dns 改面实际的 meta-server 地址
将dns配置成实际元数据集群的访问域名(不需要加监听端⼝),如果使⽤的是多shard分区版本( JuiceFS 内部将分区称作 Zone ),会有多个元数据集群,每个元数据集群会有⼀个访问域名,用逗号( , )分隔。更改后点击 Update 更新配置值,然后点击 Save dashboard 保存到 ⾯板。返回到监控⾯板,就可以通过选择 dns 的值查看元数据服务的监控
配置两个变量
- datasouce 使用控制台默认的 promethues
- name 设置成实际的文件系统名称
每个⽂件系统名加⼀个前缀字符 / ,⽐如当前部署创建了 两个⽂件系统 db-backup 和 www-logs ,改成 /db-backup,/www-logs 。更改后点击 Update 更新配置值, 然后点击 Save dashboard 保存到⾯板。返回到监控⾯板,就可以通过选择 name 的值查看相应⽂件系统的监控
当 JuiceFS 通过 -d 选项在后台运行时,日志会输出到 syslog。取决于你使用的操作系统,你可以通过不同的命令获取日志:
日志等级有 4 种。你可以使用 grep 命令过滤显示不同等级的日志信息,从而进行性能统计和故障追踪。
- hadoop
日志等级设置:JUICEFS_DEBUG=1 输出chunk block(4MB)IO时间
- 挂载点
每个挂载点的根目录提供文件名为 .oplog 和 .ophistory 的纯文本虚拟文件,记录实时的文件系统访问日志
- .oplog 输出实时的操作日志
- .ophistory 还包含从启动日志服务以来的全部历史日志信息
直接分析该日志文件会比较困难,可以使用我们提供的 juicefs profile 工具(详细的用法请参考 命令参考中的详细介绍 )。
tail -nl 10000 /tmp/juice.access.log > jfs.log
分析日志 cat /var/log/juicefs.log
挂载时,可用 --log=<log_path> 修改日志储存路径
- 访问日志
JuiceFS 的根目录中有一个名为.accesslog 的虚拟文件,它记录了文件系统上的所有操作及其花费的时间,例如:
每行的最后一个数字是当前操作花费的时间(以秒为单位)。 您可以用它调试和分析性能问题,或者尝试使用 juicefs profile /jfs 查看实时统计信息。运行 juicefs profile -h 或点此了解该命令的更多信息。
/var/lib/jfs/{my-region-no}
目前有两种诊断模式:实时模式 和 回放模式。
通过执行以下命令,您可以观察挂载点上的实时操作:
提示:输出结果按总时间降序排列。
在现有的日志文件上运行 profile 命令将启用「回放模式」:
在调试或分析性能问题时,更实用的做法通常是先记录访问日志,然后重放(多次)。例如:
提示:可以随时按键盘上的 Enter/Return 暂停/继续回放。
有时我们只对某个用户或进程感兴趣,可以通过指定其 ID 来过滤掉其他用户或进程。例如:
更多信息,请运行 juicefs profile -h 命令查看。
在用户组管理方面,JFS 和 HDFS 略有不同。
Hadoop 户组信息是可配置的(hadoop.security.group.mapping),默认使用系统用户组信息(ShellBasedUnixGroupsMapping),此时使用的是 NameNode 所在节点的用户组信息,可通过命令(hdfs dfsadmin -refreshUserToGroupsMappings)刷新缓存
JFS 默认使用每个客户端在创建时所在节点的用户组信息,无法刷新。修改用户组信息时,需要同步到所有部署 JFS 的节点并重启 JuiceFS 的服务。
JuiceFS 还可以通过指定 group 文件来配置用户组信息,可以将 group 文件放置在 JuiceFS 上。 这样每个节点就都读取同一份 group 信息,需要向用户组添加用户时,只需修改此 group 文件,各个 JuiceFS 客户端会在 2 分钟内自动更新信息,无需重启服务。具体操作如下:
修改 core-site.xml,添加 juicefs.grouping = jfs://your-jfs-name/etc/group
在 JuiceFS 上创建 juicefs.grouping 所配置的文件
修改此文件,添加用户组信息,格式如下:
重启元数据服务时,逐节点依次重新启动 meta 进程,要确保当前节点 meta 进程 启动成功 之后再操作下⼀个节点。
- ps -ef | grep meta 会显示⼀个 meta.py 进程和 1 个或者多个 /root/.juicefs/meta 进程,这些 /root/.juicefs/meta 进程的⽗进程是 meta.py 进程
- 查看 /var/log/meta.log 确认没有错误⽇志,并且当前节点的各 meta 进程出现 become LEADER 或者 become FOLLOWER ⽇志
- /root/meta.py status 显示集群各个 meta 进程的状态,找到当前节点,⽐如当前节点 IP 为 172.16.255.163,出现类似如下数据
第 4 列表示当前进程的 metaversion ,如果有对⽂件系统进⾏读写,这个版本是会逐渐增加的,这个版本 号和同⼀个 Raft 组中其它 2 个进程都⼀样或者相差很⼩(获取进程状态时间有先后)并且同步增加时,说明 这个 Raft 组事务正常
默认保存2天数据(metadata+changelog),为了应用更长的数据恢复和问题排查,需要定期将数据备份到对象存储。将最新的 juicesync 命令⾏安装在 /usr/local/bin ⽬录
将上述脚本放置在 /etc/cron.hourly/ ⽬录下,并设置 可执⾏。 对象存储相应的备份路径可以设置⽣命周期策略删除 7 天前的数据
推荐定期对 JuiceFS 控制台数据库备份,备份后可以使⽤ juicesync 将备份归档⽂件保存到对象存储或者专⻔⽤ 于归档的其它存储。 JuiceFS 数据库会搜集元数据服务和客户端的监控数据(字段更新,不新增记录),其它数据变动不频繁,整体数据量⽐较⼩,建议每天全量备份,保存 30 天
在元数据服务器上,将下列⽂本保存到 /etc/logrotate.d/juicefs-meta
在客户端服务器上,将下列⽂本保存到 /etc/logrotate.d/juicefs-mount
对元数据服务的⽇志 /var/log/meta.log 进程异常关键字 ERROR (不区分⼤⼩写)报警,需要结合环境中已有 的报警通知⽅案
可以监控 HTTP 接⼝ /api/v1/clouds ,返回⻓度为 1 的 JSON 数组。
私有化部署集群的回收站时间以 Region 的 trashtime 为准。对应控制台数据库的 jfs_region 表的 trashtime 列。默认为 1 表示回收站时间是 1 天,
如果想改成 7 天,可以将 trashtime 这列改成 7 。
想关闭回收站功能,设置成 0 即可 更改完成后 1 分钟左右,查看元数据集群服务器的 /var/lib/jfs/{{metadata}}/meta.cfg 查看 TRASH_TIME 配置项(单位:秒)也相应更新表示配置⽣效。
基于内存和节点树修改规划配置,metapy自动调整
多路径,每个zone都共用所有ssd
JFS 在内核中缓存元数据以提高性能
内核中可以缓存三种元数据:属性、条目(文件)和目录(目录)。
在 juicefs mount ... 时可通过以下选项配置:
属性、条目和目录默认缓存 1 秒,以加快查找和 getattr 操作
一致性:
- 仅一个客户端,缓存的元数据会在修改时自动失效。对一致性无影响。
- 多个客户端时,使内核中的元数据缓存无效的唯一方法是等待超时。在极端情况下,客户端 A 中所做的修改可能在短时间内对客户端 B 不可见。
客户端会将应用程序写入的数据缓存在内存中。它被刷新到对象存储,直到一个块被填满或被应用程序使用 close 或 fsync 强制。当应用程序调用fsync()或时close(),客户端将不会返回,直到将数据上传到对象存储并通知元数据服务器,以确保数据完整性。如果本地存储可靠,异步上传可能有助于提高性能。在这种情况下,close()在数据上传到对象存储时不会被阻塞,而是在数据写入本地缓存目录时立即返回。
挂载时使用以下参数启用异步上传:
当需要在短时间内写入大量小文件时,--writeback建议提高写入性能。作业完成后,删除此选项并重新安装以禁用它。对于大量随机写入的场景(例如MySQL增量备份期间),--writeback也推荐使用。
警告:--writeback启用时,永远不要删除<cache-dir>/rawstaging. 否则数据会丢失。
请注意,--writeback启用时,数据写入的可靠性在某种程度上取决于缓存可靠性。当可靠性很重要时,应谨慎使用。
--writeback 默认情况下是禁用的。
Write-through(直写模式)在数据更新时,同时写入缓存Cache和后端存储。此模式的优点是操作简单;缺点是因为数据修改需要同时写入存储,数据写入速度较慢。
Write-back(回写模式)在数据更新时只写入缓存Cache。只在数据被替换出缓存时,被修改的缓存数据才会被写到后端存储。此模式的优点是数据写入速度快,因为不需要写存储;缺点是一旦更新后的数据未被写入存储时出现系统掉电的情况,数据将无法找回。
Write-misses写缺失的处理方式
对于写操作,存在写入缓存缺失数据的情况,这时有两种处理方式:
Write allocate方式将写入位置读入缓存,然后采用write-hit(缓存命中写入)操作。写缺失操作与读缺失操作类似。
No-write allocate方式并不将写入位置读入缓存,而是直接将数据写入存储。这种方式下,只有读操作会被缓存。
通常Write-back采用Write allocate方式,
而Write-through采用No-write allocate方式;
因为多次写入同一缓存时,Write allocate配合Write-back可以提升性能;而对于Write-through则没有帮助
JFS 中提供了数据缓存以提高性能,包括内核中的 page cache和客户端主机中的本地缓存。
- 内核 page cache
内核会自动缓存最近访问的文件内容。重新打开时可以直接从内核缓存中获取内容以获得最佳性能。
在 JFS 中重复读取同一文件将非常快,具有毫秒级延迟和千兆字节吞吐量。
默认不启用内核中写入缓存。从Linux 内核 3.15开始,FUSE 支持“回写缓存模式”,这意味着write()系统调用通常可以非常快地完成。您可以-o writeback_cache在运行juicefs mount命令时通过选项启用回写缓存模式。建议在频繁写入非常小的数据(例如 100 字节)时启用它。
- client 本地缓存
客户端会根据应用中的读取方式自动进行预取和缓存,以提高序列读取性能。
默认情况下,JuiceFS 客户端在读取数据时会并行预取 3 个块。您可以通过--prefetch选项进行配置。一些数据将缓存在内存中(默认为 300MiB),可以通过--buffer-size选项进行配置。更多数据将缓存在本地文件系统中。任何基于 HDD、SSD 或内存的本地文件系统都可以。
可以在 `juicefs-mount ...` 命令中使用以下选项配置本地缓存:
JuiceFS 客户端将从对象存储下载的数据(也包括新上传的数据)写入缓存目录,未压缩且未加密。由于 JuiceFS 会为所有写入对象存储的数据生成唯一的键,并且所有对象都是不可变的,因此缓存数据永远不会过期。当缓存增长超过大小限制(或磁盘已满)时,它将被自动清理。当前规则是比较访问时间,不经常访问的文件将首先被清理。
本地缓存将有效地提高随机读取性能。建议使用更快的存储速度和更大的缓存大小来加速随机读取需要高性能的应用程序,例如 MySQL、Elasticsearch、ClickHouse 等。
将以下配置参数加入到 Hadoop 配置文件 core-site.xml 中。
当使用多个 JuiceFS 文件系统时,上述所有配置项均可对单个文件系统指定,需要将文件系统名字 JFS_NAME 放在配置项的中间,比如:
性能测试前一定要确认 memory-size 和 full-block 两个 jfs-client 配置项
- memory-size 是 jfs 开辟堆外内存的依据,设置太大内存也会被放大,导致 OOM
- full-block 会把预读落盘,在性能测试前务必 disable,因为落盘容易有瓶颈,导致内存缓存数据无法及时落盘,引起 OOM
- 元数据访问的延时取决于挂载点到服务端之间 1 到 2 个网络来回(通常 1-3ms)
- 数据访问的延时取决于对象存储的延时 (通常 20-100ms)。
- 顺序读写的吞吐量,可达 50MB/s 到 400MB/s 取决于网络带宽以及数据是否容易被压缩
- 内置多级缓存(主动失效)一旦缓存预热好,访问的延时和吞吐量非常接近单机文件系统的性能(FUSE 会带来少量的开销)
- 随机读写,包括通过 mmap 等进行的随机读写。目前 JuiceFS 主要是对顺序读写进行了大量优化,对随机读写的优化也在进行中。
随机写很多,会直接往下刷不管多大
随机写也是随机位置上的连续写,按4MB切,不足也会独立占用一个block
测试方法
执行上JuiceFS,顺序读/写基准EFS和S3FS通过FIO。
测试工具
以下测试由 fio 3.1 执行。
顺序读取测试(数量:1):
顺序写入测试(数量:1):
顺序读取测试(数量:16):
顺序写入测试(数量:16):
测试环境
以下测试结果中,所有fio测试基于c5d.18xlarge EC2实例(72 CPU,144G RAM),Ubuntu 18.04 LTS(Kernel 5.4.0)系统,JuiceFS使用本地Redis实例(4.0.9版本)存储元数据。
JuiceFS 挂载命令:
EFS挂载命令(同配置页):
S3FS(版本 1.82)挂载命令:
测试结果

result
如果需要增加集群的容量或者延⻓有效期,需要联系 JuiceFS 团队获取新的 License,JuiceFS 团队会给出具体更新 License 操作步骤和脚本
为什么我设置缓存大小为50GiB,却占用了60GiB的磁盘空间?
很难计算本地文件系统中缓存数据使用的确切磁盘空间。目前,JuiceFS 通过以固定开销 (4 KiB) 累积所有大小的缓存对象来估计它。它可能与du命令的结果不同。
当文件系统的可用空间不足时,JuiceFS 会移除缓存的对象以避免填充。
挂载时报错 ./juicefs mount -v -f 前台挂载⽂件系统并输出详细⽇志,⽅便确认挂载问题,并搜集⽇志
- 尝试 Ctrl+C 退出
- 查看 /var/log/juicefs.log ,是否有明显的客户端连接 meta 或者对象存储报错
- 使⽤ ./juicefs profile -x {{mountpoint}} 查看当前访问统计
- 获取 oplog 并通过 JuiceFS 控制台进⾏分析,可以参考 官⽅博客 进⾏分析
在执⾏ ./juicefs mount {{VOLUME}} {{mountpoint}} 操作时会⾃动执⾏ umount {{mountpoint}} -l , 如果这时还有⽂件处于打开状态,旧进程暂时不会退出,⼀旦打开的⽂件关闭了,进程是会正常退出。 如果旧进程没有退出,可以⽤下⾯步骤分析进程正在使⽤的⽂件:
- 在 /sys/fs/fuse/connections/ 下,每个 FUSE 连接是⼀个⼦⽬录,⽬录名是 Device Number。
- 然后可以通过 lsof | grep 0,N ( N 表示第 1 步中的 Device Number) 来过滤出这个 FUSE 连接上打开的⽂件。⼀旦这些⽂件都关闭了, mount 进程会退出。
- 如果还不退出,是可以通过 echo 1 > /sys/fs/fuse/connections/xxx/abort 来强制关闭这个连接,然 后 mount 进程会退出
⼀个 meta 集群的 3 个进程间的 metaversion 不⼀致。使⽤ ./meta.py status 查看结果类似如下
节点 2 (192.168.10.2) 上 metaversion 落后很多,查看节点 2 上的 /var/log/meta.log ⼀般会不断输出 WARNING 或者 ERROR ⽇志
- 在 LEADER 节点 ,也就是节点 1 上,通过 ps -ef | grep /var/lib/jfs/test-region-7 查看 LEADER 的进程号
上述进程号为 13357 ,向该进程发送 USR1 信号
查看 /var/log/meta.log 看到如下⽇志:
- 在 metaversion 落后 的 节点 2 上,删除 /var/lib/jfs/{{region}} 路径下的 metadata ⽂件
然后强制终⽌该节点上的 meta 进程。先找到该进程的进程号,然后 kill -KILL 强制终⽌该进程
这地⽅需要 强制终⽌ 也就是发送 SIGKILL 信号。 这时候会⾃动启动⼀个新 meta 进程,本地没有可⽤的 metadata ⽂件(前⾯使⽤ rm -f metadata.*.jfs 删除了),会向 LEADER 下载最新的 metadata ⽂件,就会下载到 LEADER 节点⽣成的最新的 metadata ⽂ 件了
Jfs client会开辟堆外内存,memory-size,max-uploads,不能配置太大。
每个client使用一个buffer size,多个client并发的时候就会有多份,导致内存超出。
container会直接kill使用超过分配的实例。
JUICEFS_DEBUG=1 YARN JAR ...
获取4MB的IO时长,定位是clien侧还是S3侧问题
底层存储负载高的时候,jfs-client超时重试次数后,业务会失败
参数调整策略:
juicefs.object-timeout 默认:5s
重试次数默认 30:
重现条件:> 500*4GB, 把底层负载压满
在作read测试之前没有先write,所以文件不存在
bond 策略
- 统一命名空间
- 缓存
- 小文件元数据管理
命令参考
juicefs 客户端所有的命令与参数。
注:如果没有把 juicefs 放入到 PATH 环境变量中的某个目录,则需要使用完整路径来运行 juicefs. 如果 juicefs 是在当前目录下,则用 ./juicefs。以下文档假定 juicefs 在 PATH 环境变量中的某个目录(比如 /usr/local/bin), 可以直接用 juicefs 运行。
初始化 file system volume 的第一步:格式化.
参数
--block-size value
size of block in KiB (default: 4096)
--compress value
compression algorithm (lz4, zstd, none) (default: "none")
--shards value
store the blocks into N buckets by hash of key (default: 0)
--storage value
Object storage type (e.g. s3, gcs, oss, cos) (default: "file")
--bucket value
A bucket URL to store data (default: "$HOME/.juicefs/local" or "/var/jfs")
--access-key value
Access key for object storage (env ACCESS_KEY)
--secret-key value
Secret key for object storage (env SECRET_KEY)
--encrypt-rsa-key value
A path to RSA private key (PEM)
--force
overwrite existing format (default: false)
--no-update
don't update existing volume (default: false)
S3 兼容网关
参数
--get-timeout value
下载对象的最大秒数(默认值:60)
--put-timeout value
上传对象的最大秒数(默认值:60)
--io-retries value
网络故障后的重试次数(默认值:30)
--max-uploads value
要上传的连接数(默认值:20)
--buffer-size value
以 MiB 为单位的总读/写缓冲(默认值:300)
--prefetch value
并行预取 N 个块(默认值:3)
--writeback
在后台上传对象(默认值:false)
--cache-dir value
本地缓存的目录路径,使用冒号分隔多个路径
(默认:"$HOME/.juicefs/cache"或/var/jfsCache)
--cache-size value
以 MiB 为单位的缓存对象的大小(默认值:1024)
--free-space-ratio value
最小可用空间(比率)(默认值:0.1)
--cache-partial-only
仅缓存随机/小读(默认值:false)
--access-log value
JuiceFS 访问日志的路径
--no-usage-report
不发送使用报告(默认:false)
--no-banner
禁用 MinIO 启动信息(默认:false)
Sync between two storage.
参数
--start KEY, -s KEY
the first KEY to sync
--end KEY, -e KEY
the last KEY to sync
--threads value, -p value
number of concurrent threads (default: 10)
--http-port PORT
HTTP PORT to listen to (default: 6070)
--update, -u
update existing file if the source is newer (default: false)
--force-update, -f
always update existing file (default: false)
--perms
preserve permissions (default: false)
--dirs
Sync directories or holders (default: false)
--dry
don't copy file (default: false)
--delete-src, --deleteSrc
delete objects from source after synced (default: false)
--delete-dst, --deleteDst
delete extraneous objects from destination (default: false)
--exclude PATTERN
exclude keys containing PATTERN (POSIX regular expressions)
--include PATTERN
only include keys containing PATTERN (POSIX regular expressions)
--manager value
manager address
--worker value
hosts (seperated by comma) to launch worker
--bwlimit value
limit bandwidth in Mbps (0 means unlimited) (default: 0)
--no-https
do not use HTTPS (default: false)
Run benchmark, include read/write/stat big and small files.
Options
--block-size value
block size in MiB (default: 1)
--big-file-size value
size of big file in MiB (default: 1024)
--small-file-size value
size of small file in MiB (default: 0.1)
--small-file-count value
number of small files (default: 100)
Check consistency of file system.
Collect any leaked objects.
参数
--delete
deleted leaked objects (default: false)
--compact
compact all chunks with more than 1 slices (default: false).
--threads value
number threads to delete leaked objects (default: 10)
功能: 文件系统的认证授权。
语法
juicefs auth <name> --token=<token> [--accesskey=<access_key>] [--secretkey=<secret_key>]
[--accesskey2=<access_key_2>] [--secretkey2=<secret_key_2>]
参数
挂载文件系统时需要两个密钥信息,一个是文件系统的 Token(在网站控制台的 文件系统设置 中查看),另一个是云提供商对象存储的密钥对(获取方式可以参考文档 如何获取对象存储的 API 密钥)。
你可以在挂载时以命令行交互方式或者参数方式输入认证信息,也可以用 auth 命令将认证信息保存在本地(位置是 $HOME/.juicefs/[NAME].conf),以后挂载时无需再次输入,这样更方便做自动化的运维配置。
<name>
文件系统的名字。
--token=<token>
文件系统的 Token,在网站控制台的 文件系统设置 中查看。
--accesskey=<access_key>
你使用的对象存储的密钥,获取方式参见 文档。
--secretkey=<secret_key>
你使用的对象存储的密钥,获取方式参见 文档。
--accesskey2=<access_key_2>
用于复制的对象存储密钥(可选)。
--secretkey2=<secret_key_2>
用于复制的对象存储密钥(可选)。
备注
如果以 sudo 方式运行 ./juicefs,认证信息保存在 /root/.juicefs/[NAME].conf 中。
当 --accesskey 和 --secretkey 没有以参数方式指定时,会以交互方式输入。
如果你的云提供商支持 IAM,accesskey 为空字符串即可。可以是 --accessk ey "", 或者交互输入时直接按回车键。
JuiceFS 的复制功能在网站的 控制中心 中设置,进入你文件系统的 设置 面板,勾选 启动复制 后选择要复制到的云平台和服务区。之后在挂载时使用 --accesskey2 和 --secretkey2 设置复制 Bucket 的密钥。
功能: 挂载文件系统。
语法
juicefs mount <name> <mountpoint> [-f] [-b] [-v]
[--log=<log_path>] [--http=ADDR]
[--external | --internal] [--max-uploads=<max_uploads>]
[--cache-dir=<cache_dir>] [--cache-size=<cache_size>]
[--writeback] [--metacache]
[--allow-other] [--allow-root] [--enable-xattr]
...
参数
<name>
文件系统的名字。
<mountpoint>
在自己主机上的挂载路径,比如:/jfs。
-f
前台运行。
-b
在 Docker 中后台运行。
--subdir=<subdir>
挂载子目录。
-v
显示更多日志。
--log=<log_path>
指定日志存储路径,默认为 /var/log/juicefs.log。
--http=ADDR
指定通过 HTTP 提供文件访问的监听地址,比如 localhost:8080。
对象存储相关参数
--external
客户端会自动检查当前环境是否可以用内网域名来访问对象存储,用户可以通过此参数显式指定通过外网访问。
--internal
显式指定通过内网域名访问对象存储(适用于部分区分内外网域名的对象存储,比如:阿里云 OSS, UCloud UFile 等)。
--max-uploads=<max_uploads>
最大并发上传请求数,默认为 50。
--upload-limit=<upload_limit>
上传数据所用带宽的上限(Mbps),默认无限制.
--delete-limit=<delete_limit>
对象存储 Delete API 调用上限(QPS),默认无限制.
--get-timeout=<get_timeout>
下载单个对象的最长时间(秒)。
--put-timeout=<put_timeout>
上传单个对象的最长时间(秒)。
缓存相关参数
--cache-dir=<cache_dir>
本地缓存的存储路径,默认是 /var/jfsCache。
多盘缓存用 : 分割不同目录,目录可包含通配符 * (需要添加引号)。
例如 --cache-dir '/data*/jfsCache:/mydata*/jfsCache'。
--cache-size=<cache_size>
本地缓存容量,默认是 1024 MiB。
在多盘缓存下是指多个目录一起的总容量,会平均分配到各个目录。
--free-space-ratio=<free_space_ratio>
缓存盘的最少剩余空间,默认是 0.2。
--cache-mode=<cache_mode>
磁盘上缓存文件的权限模式,默认是 0600。
--buffer-size=<buffer_size>
用来缓存读写数据的总内存大小,默认 300 MiB。
--writeback
写数据时优先写到本地磁盘,然后在后台异步上传到对象存储。
--metacache
将元数据缓存在运行客户端的主机的内存里,默认启用,请用 –metacacheto=0 来关闭。
--metacacheto=<metacacheto>
元数据的缓存过期时间(单位是秒),默认为 300(5 分钟)。
--entrycacheto=<entrycacheto>
文件项在内核中的缓存时间,默认 1 秒。
--direntrycacheto=<direntrycacheto>
目录项在内核中的缓存时间,默认 1 秒。
--attrcacheto=<attrcacheto>
文件/目录的属性在内核中的缓存时间,默认 1 秒。
--opencache
是否使用缓存的元数据来打开文件,默认不使用。
FUSE 相关参数
--allow-other
允许其他用户访问(当用 root 挂载时默认开启,否则需要在 /etc/fuse.conf 里面设定 user-allow-other)。
--enable-xattr
开启 扩展文件属性 xattr 的支持。
--enable-acl
开启 POSIX ACL 的支持。
--no-posix-lock
禁用 POSIX lock。
--no-bsd-lock
禁用 BSD lock。
-o writeback_cache
在 3.15+ 的内核中启用写入缓存,极大提高随机写入和碎片写入的性能。
挂载文件系统的方法可以参考 上手指南中的说明。
功能
卸载 JuiceFS 文件系统。
语法
juicefs umount <mountpoint> [options]
参数
-f --force
强制卸载
功能
显示 JuiceFS 文件系统中文件或目录的信息。
语法
juicefs info <path> [-n | --plain]
参数
<path>
要查询的路径。
-n --plain
把文件大小显示为字节数。
例子
显示一个目录的信息
# juicefs info /jfs/logs
/jfs/logs:
inodes: 4 # 当前目录包含的 inode 总数
directories: 2 # 其中目录的数量
files: 2 # 其中文件的数量
chunks: 44 # 所有文件包含的 chunk 数量
length: 2.91G # 所有文件的实际大小总和
size: 2.91G # 计费大小,所有文件和目录大小会对齐到 4KB,为最小计费单位
显示一个文件的信息
# juicefs info --plain /jfs/daily-log.tar
/jfs/daily-log.tar:
inode: 2955 # 文件的 inode id
length: 3128903680 # 文件实际大小
size: 3128950784 # 文件计费大小
chunks: 47 # 数据块总数和清单,每块最大 64MB
0: 58597 67108864 0 67108864 # 格式为:在文件中的位置,块ID,块长度,实际使用的起始位置,长度
1: 58598 67108864 0 67108864
...
45: 58661 67108864 0 67108864
46: 58662 41895936 0 41895936
功能
从已有的对象存储中导入文件。
语法
juicefs import <uri> <dst> [-v] [--name=<name>] [--mode=<mode>]
参数
<uri>
要导入文件的 URI,格式为 <bucket_name>[.<domain>][/<prefix>].
<dst>
导入文件的存放目录。
--name=<name>
文件系统的名字,Linux 下是可选的。
--mode=<mode>
导入文件的权限(Unix 格式)。
-v
显示详细日志。
参数
导入的文件数据是只读的。但是文件和目录的其他属性(名字和权限等)可以修改,改动不会同步到对象存储中。
可以在 JuiceFS 中删除导入的文件,但并不会实际删除对象存储中的对象。
功能
快速删除目录里的所有文件和子目录,类似于 rm -rf, 但速度非常快。
语法
juicefs rmr <dir> [-h]
该命令会尝试以当前用户的身份去递归删除指定目录里面的所有文件和子目录,跳过无权限删除的部分,返回被删除的文件和目录数量以及剩余的文件和目录数。
如果文件系统启用了回收站功能,被删除的文件会进入回收站。
功能
创建或删除快照。
快照是在某个时间点(拷贝开始的时间点)对指定数据的完整映像,这是数据备份时经常用到的技术。JuiceFS 的快照在建立快照时不会实际拷贝文件数据,而且创建一套完整的引用,在源数据发生修改时才拷贝数据(Copy-on-Write 技术)到快照中。
语法
juicefs snapshot <src> <dst> [-f | --force] [-c | --copy] # 创建快照
juicefs snapshot -d <dst> [-f | --force] # 删除快照
参数
<src>
要做快照的目录。
<dst>
快照存放的目录。
-d --delete
删除快照。
-f --force
强行覆盖或删除文件。
-c --copy
用当前用户的 uid,gid,umask 来创建新快照,默认使用源文件的 uid,gid 和 mode。
功能
Linux grep 的并行版本,使用方法一样,搜索性能更高。
语法
juicefs grep [PATTERN] PATH ... [options]
参数
[PATTERN]
要搜索的内容,支持正则表达式。
PATH
搜索路径。
-j JOBS --jobs=JOBS
并行任务数量(默认为 CPU 核数)。
-e PATTERNS --regexp PATTERNS
多用于连接多个 PATTERNS 或者 PATTERN 以 “-” 开头。
-E extended-regexp
指定 PATTERN 是扩展正则表达式。
-H
每行开始都打印文件名。
-n --line-number
输出搜索结果所在的行号。
-i --ignore-case
忽略英文字母大小写,默认是区分大小写的。
-v --invert-match
搜索不包含 PATTERN 的行。
功能
列出 JuiceFS 最近(10 分钟内)被打开过的文件。
语法
juicefs lsof <path>
功能
收集和分析文件系统的 oplog (operation log)。
语法
juicefs profile [options]
参数
-x PATH --path=PATH
日志文件目录(默认为 /jfs)。
-f FILE --file=FILE
日志文件名(默认为 .ophistory)。
日志文件区别请参考 挂载目录下的 .oplog 虚拟文件。
-g GROUP_BY --group-by=GROUP_BY
根据指定属性对输出结果进行分组(默认为 cmd),可选值为 [uid, pid, cmd]。
-s SORT_BY --sort-by=SORT_BY
根据指定列对输出结果进行排序(默认为 total_time),可选值为 [group, number, avg_time, total_time]。
-u FILTER_BY_UID --filter-by-uid=FILTER_BY_UID
根据 UID 对输出结果进行过滤,多个关键词使用半角逗号(,)分隔。
-p FILTER_BY_PID --filter-by-pid=FILTER_BY_PID
根据 PID 对输出结果进行过滤,多个关键词使用半角逗号(,)分隔。
-w WINDOW_SIZE --window-size=WINDOW_SIZE
收集 oplog 的时间窗口大小,参数为浮点数,单位为秒(默认值为 60)。
-i FLUSH_INTERVAL --flush-interval=FLUSH_INTERVAL
输出的刷新间隔,参数为浮点数,单位为秒(默认值为 2)。
功能
显示客户端版本,在 版本更新页 可以查看每个版本的更新详情。
语法
juicefs version [options]
参数
-u --upgrade
升级客户端到最新版。
show status of JuiceFS
build cache for target directories/files
Options
--file value, -f value
file containing a list of paths
--threads value, -p value
number of concurrent workers (default: 50)
--background, -b
run in background (default: false)
请在挂载时加上 --writeback 选项,它会先把数据写入本机的缓存,然后再异步上传到对象存储,会比直接上传到对象存储快很多倍。
如果使用已有的对象存储来创建 JuiceFS,它里面已有的文件不会自动出现在 JuiceFS 里,需要使用 juicefs import 来快速导入。
使用量是文件系统中所有对象的大小之和,每个文件和目录有一个 4KB 最小计费单位 (参考自微软的 Azure Data Lake Store 的计费方法),推荐尽量使用大文件来存储数据以节省成本,同时也能提高访问性能。JuiceFS 会实时更新文件系统和目录的大小,可以在我们的 Web 控制台或者命令行中查看。
/əˈlʌksio/
- JuiceFS 中一个文件的存储格式包括三个级别:chunk、slice 和 block。一个文件将被分成多个块,并被压缩和加密(可选)存储到对象存储中。
- Alluxio 将文件作为对象存储到 UFS。该文件不像 JuiceFS 那样被拆分信息块。
JuiceFS的默认块大小为4MiB,与Alluxio的64MiB相比,粒度更小。较小的块大小更适合随机读取(例如 Parquet 和 ORC)工作负载,即缓存管理将更有效率。
JuiceFS 不仅兼容 Hadoop 2.x 和 Hadoop 3.x,还兼容 Hadoop 生态系统中的各种组件。
- JuiceFS 提供了Kubernetes CSI 驱动程序
- Alluxio也提供了Kubernetes CSI驱动程序,但项目没有得到积极维护,也没有得到Alluxio的官方支持
JuiceFS完全兼容 POSIX。
京东的一份pjdfstest显示Alluxio没有通过POSIX兼容性测试,
Alluxio 不支持 symbolic link、truncate、fallocate、append、xattr、mkfifo、mknod和utimes。
除了 pjdfstest 涵盖的东西外,JuiceFS 还提供了 close-to-open 一致性、原子元数据操作、mmap、 fallocate with punch hole、xattr、BSD 锁(flock)和 POSIX 记录锁(fcntl)。
Alluxio中的元数据操作有两个步骤:
- 第一步是修改Alluxio master的状态,
- 第二步是向UFS发送请求。
如您所见,元数据操作不是原子的,当操作正在执行或发生任何故障时,其状态是不可预测的。
Alluxio依赖UFS来实现元数据操作,比如重命名文件操作会变成复制和删除操作。
JuiceFS 的大部分元数据操作都是原子的,例如重命名文件、删除文件、重命名目录。您不必担心一致性和性能。
Alluxio 根据需要从 UFS 加载元数据,并且它在启动时没有关于 UFS 的信息。
默认情况下,Alluxio 期望对 UFS 的所有修改都通过 Alluxio 进行。如果直接对 UFS 进行更改,则需要手动或定期在 Alluxio 和 UFS 之间同步元数据。元数据操作的两个步骤可能会导致不一致。
JuiceFS 提供元数据和数据的强一致性。JuiceFS 的元数据服务是唯一的真实来源,而不是 UFS 的镜像。元数据服务不依赖对象存储来获取元数据。对象存储只是被视为无限制的块存储。JuiceFS 和对象存储之间没有任何不一致之处。
JuiceFS 支持使用LZ4或Zstandard来压缩您的所有数据。
Alluxio 没有这个功能。
JuiceFS 支持传输和静态数据加密。
Alluxio 社区版没有这个功能,但是企业版有。
Alluxio 的架构可以分为 3 个组件:master、worker 和 client。
一个典型的集群由 a single leading master, standby masters, a job master, standby job masters, workers, and job workers 组成。
您需要自己操作这些 master 和 worker

 浙公网安备 33010602011771号
浙公网安备 33010602011771号