221801232_hjq_软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/FZUSESPR21 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/FZUSESPR21/homework/11672 |
| 这个作业的目标 | 能写出自己的思考,学习基础Git命令、Github Desktop使用 |
| 其他参考文献 |
part1:阅读《构建之法》并提问
(由于编程经验不多,我看的是16章“创新”)
1.我看了这一段文字:


我的问题是:教材中给的解释是说在这些科学巨人顿悟之前已经有坚实的基础了,但是顿悟和这些知识具体的联系是什么呢?
事例资料:我试图去查了对于牛顿这个故事,也看了有的资料去讲顿悟、渐悟的关系。
但是我还是不太懂,我的想法大概是,牛顿这样的一个思想的来源是不是由于他本身有对力的知识,就是知道世界上有力的存在,力能改变物体的状态,能让物体“动起来”之类的知识,现在发现没人动苹果,苹果却能动,说明也有一个力在牵引着它,作用于它。但我感觉这样的过程好像更像一种延申,它真的是顿悟吗?还是说所谓的“顿悟”其实就是这样延申出一个新的东西呢?
2.我看了这一段文字:

我的问题是:我感觉创新面临的更多问题是在于不够创新,没有吸引力,而不是这些问题。如果是真的非常建设性的东西,是不是不太会受到这些问题呢?
事例资料:不知道该往哪个方向找资料,搜索相关关键词基本只能看到非常笼统地说“我们要创新”“创新才有未来”之类的话。于实验室,利用先进的技术和设备在实验室中还原
我的困惑是:好像现在更多的创新都非常容易和过去的相撞或者和别人的想法很类似,那如果真的很有意义的创新的想法是不是会获得更多人的支持呢?在编辑这段文字的时候我又想到是不是这个“创新者”除了创新的想法之外,还需要其他大量的工作去证明这个创新是有意义的,那这样究竟是一件好事还是坏事呢?
3.我看了这一段文字:

我的问题是:如果一类产物是具有别样意义的东西,那么这样的产业化真的会动摇原产业吗?
事例资料:钻石类比于水晶。现在市面上已经有大量的人造水晶,像著名品牌施华洛世奇作为轻奢的一员使用的就是人造水晶。目前为止出现在市面的有培育钻石。钻石的化学成分是碳,这在宝石中是唯一由单一元素组成的,属等轴晶系。常含有0.05%-0.2%的杂质元素,其中最重要的是N和B,他们的存在关系到钻石的类型和性质。晶体形态多呈八面体、菱形十二面体、四面体及它们的聚形。
问题:那钻石是不是也和水晶一样,会包含不一样的矿物质,世界上没有两颗一模一样的钻石。那么人造和天然的意义是不是还是有区别。像水晶,在人造水晶越来越漂亮高阶的今天,天然水晶的市场中依旧有很多人趋之若鹜。珠宝市场的规则是不是是和批发市场有所不同呢?这样的创新是不是并不会影响这类的市场或者影响不大呢?
4.我看了这一段文字:

我的问题是:这样的一个决断,是值得参考的还是只是当一个故事看看呢?
事例:像京东当年想要转战线上,关掉了在北京的12家实体店。如今看来当然是个正确的决算,但如果这一条路错了呢?
问题:卖掉所有的生产线,看上去是一个非常伟大而漂亮的决断,让后来的诺基亚坐到了行业头部的为止。但是如果这一战失败是不是直接死亡。所以这一部分的内容是要希望我们能坚持决断地做一件事是这个意思吗?还是一定要能选择到正确的方向。
5.我看了这一段文字:

我的问题是:这个举了两个选择,一个是利润50%,一个是利润10%,那如果创新的产品没有利润,甚至一开始就倒贴,后面有可能有更高的利润,人又会去怎么选呢?
6.我看了这一段文字:

我的问题是:目前为止看到“价值观坚定”而成功的栗子好像基本都是坚定站在用户的角度上考虑问题的,那有没有其他价值观成功的呢?
事例资料:例如,为什么微信不能多任务同步操作?——就是说你看微信文章的时候来了一条消息,就必须要退出文章界面,很多人会觉得非常没有效率。而这个就是微信的产品经理在向用户传达一个小小的价值观:生活已经这么累了,那就专心做好一件事吧。
但是我还是不太懂,我的困惑是:这好像是这个软件本身成功了这个事才无所谓。就像我同样吐槽微信为什么不能三个平台同时登陆,平板一上线电脑就会掉线。那如果这个软件改掉会不会更贴合用户,更受欢迎呢?
7.我看了这一段文字:

我的问题是:现在真的效能过剩了吗?有的效能是不是必要的呢?
事例资料:比如现在的手机的性能越来越好,按一些人的形容是已经超过了很多人的需求。比如很多父母辈的要求就只是要能顺利发消息,发文章新闻,发消息之类,现在的手机的性能很多是针对有重度游戏需要的人。
但是好像实际上会发现这些多余的性能是有用的。除了跟内存空间相关之外,更强的性能是不是在使用时间较久之后仍不滞后,仍能使用户有与开始一样好的使用体验呢?现在的手机都在不断地提升刷新率,不也是为了用户体验的提升吗?很多肉眼不可见的地方,所谓“多余的性能”,或许并不多余呢?
8.我看了这一段文字:

我的问题是:假如真的有这样的梦想,这真的应该是我们要考虑的事吗?
事例资料:认为作坊式开发的集中体现是有组织的管理难以落地,有以下几个主要问题:
(一)对“师傅”的依赖严重
师傅就是骨干工程师,很多东西都是装在开发人员的脑子里面的,往往会因为一两个开发骨干走了,就造成整个团队的瘫痪,如果研发骨干一个人另谋高就,公司投资就将全部付之流水。我们看到很多团队里的“技术权威”使得老板也不敢对其“指手画脚”,否则他会“撂挑子”,事情成败取决于师傅的能力,实际上说明工作缺乏组织的有效管理,在这样的情形下,生产过程基本上是无序的、无约束的,老板作为“管理者”角色的职能几乎谈不到,甚至受师傅的摆布,除非老板是一个非常高水平的技术大牛。
(二)老板对软件开发的过程无法介入,各层级之间也是以人为纽带的弱管理
老板大概知道要开发个什么东西,需要什么时候交付,但具体开发过程、产品工期、产品质量老板只能问技术总监,有趣的是技术总监也是个大概齐,更多的只能问项目的负责人,虽然越接近开发工程师,越了解实际情况,但项目负责人甚至都不知道手下的工程师今天倒底是写代码了还是打游戏了,这种粗放的管理水平在今天的其他行业是很难想像的。
(三)无文档式开发,设计都在师傅的大脑里,开发项目可持续的风险很大
问题:那是不是其实除了文中提到的自身的很多条件和想法之外,作坊本身也是非常非常重要的呢?而在外部的人根本无法窥得内部的真实情况,应不应该冒这样的风险呢?其二,现在的年轻人比起梦想,其实更多需要的是能够生活下去,有稳定的工作和工资,是不是不应该去试错呢?
part2:WordCount编程
github项目地址
https://github.com/HuangJunQian/PersonalProject-C/tree/221801232
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 360 | 360 |
| • Estimate | • 估计这个任务需要多少时间 | 360 | 360 |
| Development | 开发 | 585 | 775 |
| • Analysis | • 需求分析(包括学习新技术) | 120 | 150 |
| • Design Spec | • 生成设计文档 | 30 | 45 |
| • Design Review | • 设计复审 | 30 | 60 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| • Design | • 具体设计 | 45 | 40 |
| • Coding | • 具体编码 | 180 | 180 |
| • Code Review | • 代码复审 | 30 | 120 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 150 |
| Reporting | 报告 | 120 | 65 |
| • Test Repor | • 测试报告 | 30 | 30 |
| • Size Measurement | • 计算工作量 | 30 | 15 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 60 | |
| 合计 | 1065 | 1200 |
解题思路描述
看到题目的感觉是按照分别四个要求实现四个不同的函数功能。
1.由于只需要考虑Ascii码,汉字不需考虑,且Q&A问答说Ascii里面出现可打印字符和三种控制字符。
空格,水平制表符,换行符均算字符,所以不用特意处理。使用python的len()可以去逐行计算每一行字符的长度,即字符的数量。
2.先使用readlines()函数获取文本的全部,然后用列表存储每一行的文本。先规定单词是至少以4个英文字母开头,跟上字母数字符号,分隔符分割,不区分大小写的。再使用正则表达式匹配符合单词表达式的单词,并对其计数。
3.使用strip()函数,按照换行符分割每一行后,计算列表中所有长度大于0的个数就是非空白行的总行数。
4.对每一行的文本进行分割,其中符合题目要求的单词都转为小写以后存入字典,每存入一次键值+1。最后按照键值排序。对于键值相同的键则按键排序。
代码规范制定链接
https://github.com/HuangJunQian/PersonalProject-C/blob/221801232/221801232/codestyle.md
设计与实现过程
1.统计文件的字符数
def count_chars(str):
chars_num = 0
for line in str:
chars_num += len(line)
return chars_num
在针对Windows系统下python处理\r\n时会将其直接转换为\n的问题时的处理方法是在打开文件时,将open函数的newline参数设置为\n。
with open(inputfile, 'r', newline="\n") as f:
text = f.readlines()
2.统计文件的单词总数
每一行的文本使用正则表达式匹配符合单词表达式的单词。
for line in list_f:
if len(line) > 0:
for word in re.split(r'[^A-Za-z0-9]', line):
if re.match(r"^[A-Za-z]{4}[A-Za-z0-9]{0,}", word):
words_num += 1
计算单词数目可以作为寻找出现最多单词的前置任务。
3.统计文件的有效行数。由于任何包含非空白字符的行都需要统计。
list_f = [line.strip() for line in str]
for line in list_f:
if len(line) > 0:
lines_num += 1
4.统计文件中各单词的出现次数),最终只输出频率最高的10个。
for line in list_f:
if len(line) > 0:
for word in re.split(r'[^A-Za-z0-9]', line):
if re.match(r"^[A-Za-z]{4}[A-Za-z0-9]{0,}", word):
word = word.lower()
word_dic[word] = word_dic.get(word, 0)+1
word_dic = sorted(word_dic.items(), key=lambda x: (-x[1], x[0]))
性能改进
10000个字符时:Running time: 0.09780130000000004 Seconds
100000个字符时:Running time: 0.20291759999999998 Seconds
11000000个字符时:Running time: 11.9040462 Seconds
测试中发现没有考虑单词在十个以下的可能,导致单词少时没有单词出现次数排序的输出,另外改成使用循环输出
if len(count_num)>=10:
for i in range(10):
wf.write(count_num[i][0]+':'+str(count_num[i][1])+'\n')
else:
for i in range(len(count_num)):
wf.write(count_num[i][0]+':'+str(count_num[i][1])+'\n')
单元测试
使用unittest进行测试,展示部分单元测试函数
1.空格,水平制表符,换行符字符的测试
def test_char(self):
filename = "test_char.txt"
str = "\t111111\n2222\r\n333\t444\a\a555\f"
with open(filename, "w", encoding="utf-8") as f:
f.write(str)
WordCount.main(filename, "test_char1.txt")
2.统计文件的单词总数,单词不区分大小写的测试。
def test_words(self):
filename = "test_words.txt"
with open(filename, "w", encoding="utf-8") as f:
str = "FILE,FILE123,File,file,file123\n"
i = 0
while i < 100:
f.write(str)
i += 1
WordCount.main(filename, "test_words1.txt")
3.统计文件的有效行数:任何包含非空白字符的行的测试。
def test_rows1(self):
str = "12345n\t\n \n0987654\n"
filename = "test_rows.txt"
with open(filename, "w", encoding="utf-8") as f:
f.write(str)
WordCount.main(filename, "test_rows1.txt")
4.统计文件中各单词的出现次数,最终只输出频率最高的10个的测试
def test_huge_data(self):
filename = "test_huge_data.txt"
dir = os.getcwd() + "/" + filename
with open(filename, "w", encoding="utf-8") as f:
i = 0
str = "file,file\n"
while i < 1000000:
f.write(str)
i += 1
WordCount.main(filename, "test_huge_data1.txt")
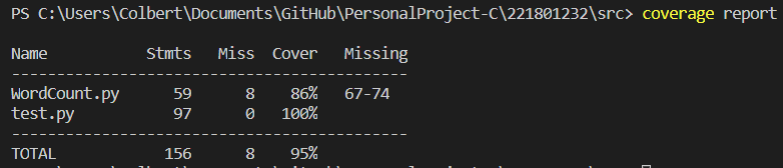
coverage查看代码测试覆盖率
异常处理说明
暂时没有对异常的特殊处理。
心路历程与收获
通过这次作业,我感受到要真正学到东西,只有不断的学习、实践,再学习、再实践。这对于我的将来也有很大的帮助。我学习了python读取文件的方式,学习了正则表达式,学习了python关于字典的排序。一开始我对这个作业很恐慌,希望以后我在面对需要面对的事情,以及遇到问题的时候,要学会不急不慌,慢慢解决它。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号