DP动态规划进阶
摘自其他小组的总结
Part 0 引言
dp(Dynamic Programming,动态规划),如何理解?
动态规划是一种通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。
——OI-Wiki
感性理解,你有一个问题,输入一个数 \(n\),定义 \(f(1) = f(2) = 1\),\(f(x) = f(x - 1) + f(x - 2)\)(\(x\in[3, \infty)\)),求 \(f(n)\)(斐波那契数列),你的数学是祖先教的所以你不会发明一个公式 \(\mathcal O(1)\) 做出来颠覆数学界,于是你把这道题扔了出去。
dp 把这道题捡了回来并开导你,\(f(1)\) 和 \(f(2)\) 的答案是已知的,所以你可以计算 \(f(3)\),然后你就可以用 \(f(2)\) 和 \(f(3)\) 算出来 \(f(4)\)......
于是你一个一个地循环递推,从 \(f(3)\) 慢慢地拱到了 \(f(n)\),你发现你居然会 dp 了(实则并非)。
这是 dp 中最基础的线性 dp 中最简单的斐波那契第 \(n\) 项问题。可以看到,我们在解决问题的过程中,首先我们定义状态 \(f(x)\) 为斐波那契第 \(x\) 项,把 \(f(n)\) 这个复杂问题分解成了 \(f(n - 1) + f(n - 2)\) 两个相对简单的子问题,找到了 \(f(1) = f(2) = 1\) 这个初始状态,并通过 \(f(x) = f(x - 1) + f(x - 2)\) 这个式子来进行状态转移,又通过递推解决了问题。
以上就是我们使用动态规划解决问题的大体思路,分为以下几个步骤:
- imp 设计状态
- 分解为子任务
- 寻找初始状态
- imp 设计状态转移方程
重点就在于第一步和第四步,dp 的不同种类也体现在这两步上,这里不展开讲了不然后面没东西讲了。
总之,dp 动态规划就是采用分而治之,由小至大,层层递进的思想,使用看似暴力实则确实暴力巧妙的方法来得到答案。
动态,体现于转移方程;规划,表现在设计状态。
优秀的转移方程可以减少大量思维含量以及提高单次转移效率;优秀的状态可以削去不必要的维度直接指数级地优化时间复杂度。
下面我们将分板块来对不同类型的动态规划进行讲解。
Part 1 背包 dp
背包问题是 dp 中的经典问题,也是最基础的问题,是我们理解 dp 的起点。它的基本形式是:给定一组物品,每种物品有自身的重量和价值,在限定的总重量内,如何选择物品使得总价值最大。
假设我们背包里需要装的物体不是固体,而是液体,那我们首先应该把包丢了拿个缸,然后计算选取每种液体每 1kg 可以赚得多少利润,选择利润最大的一直装,直到没有了,然后再选取利润第二大的液体......直到把缸装满。
显然,以上是一个贪心思想,但是我们在处理背包问题时不能用同样的方法,举个例子,我们现在有体积 \(v_1 = 9\) 价值 \(w_1 = 12\) 的 1 号物品一个,体积 \(v_2 = 7\) 价值 \(w_2 = 9\) 的 2 号物品 2 个,背包容量 15,如果按照贪心策略,我们发现 \(\frac{w_1}{v_1} > \frac{w_2}{v_2}\),于是把 1 号物品装了进来,发现装不下 2 物品了,于是最终价值为 12。但事实上,我们会直接选择 2 个 2 号物品,最终价值为18,优于贪心策略。
出现这种问题的原因就是贪心策略不能在背包问题中保证完全利用已有空间,可能造成空间浪费,甚至不如选更多利润不高但能够更少浪费空间的方案。
理解了为什么会有背包问题,接下来就开始学习如何解决各类背包问题吧。
1.1 0-1 背包
给出 \(n\) 个物品拥有两个信息,体积 \(v_i\) 和价值 \(w_i\),背包容量为 \(m\),选择放入物品以最大化获得的总价值。
我们定义状态:\(dp_{i, j}\) 代表我们考虑了前 \(i\) 个物品在容量为 \(j\) 时能得到的最大容量。
如何更新?0-1 背包之所以被称为 0-1 背包,就是因为每个物品只有选和不选两种状态,我们在更新时根据此便也只需要考虑这两种状态。
如果选,那么应该会将获得价值增加 \(w_i\),但是相应地我们需要付出 \(v_i\) 的代价,所以此时:
如果不选,那么显然:
我们希望能得到的价值最大化,所以有转移方程:
于是我们解决了 0-1 背包问题。0-1 背包是所有背包问题的基础,其它背包问题多为 0-1 背包的变式。
for (int i = 1; i <= n; ++ i) {
for (int j = 1; j <= m; ++ j) {
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - v[i]] + w[i]);
}
}
1.2 完全背包
与 0-1 背包大体相同,不同点是每种物体都存在无数个,你可以无限地选择。
回想我们是如何做到控制只选择一个物体的,我们在转移方程中忽略第二维,那么 \(dp_i\) 永远都是从 \(dp_{i - 1}\) 转移来的。那么如果我们放开控制选择多个同物体,只需要将 \(i - 1\) 改为 \(i\),我们在考虑此物体时就可以重复地在 \(i, j + v[i] * x\) 位置递推地选多次了。在考虑不选此物体时也考虑复制过来 \(dp_{i - 1, j}\) 代表此物品选 0 个。
for (int i = 1; i <= n; ++ i) {
for (int j = 1; j <= m; ++ j) {
dp[i][j] = max({dp[i - 1][j], dp[i][j - 1], dp[i][j - v[i]] + w[i]});
}
}
1.3 多重背包
同样与 0-1 背包大体相同,不同点在于每种物体有若干个,在解决多重背包时我们考虑使用二进制优化。
这时候最暴力的做法就是直接将一个物品拆成 \(k_i\) 个,然后用 0-1 背包做。但是在某些题目中,这种做法肯定过不了。
我们尝试将“选多少个”的判断转换为“选不选”,只需要把同一种物体的数量先转为二进制,再根据二进制上 1 位进行捆绑即可。
举个例子,现在一种物体有 \(19\) 个,我们可以将物体拆分成 \(2^1,2^2,2^3,2^4,3\),这时候,我们对于 \(16\) 以内的数可以用 \(2^a+2^b+\cdots\) 组合,然后对于 \(16\) 以外的数可以 \(3+2^a+2^b+\cdots\)。
最后所有物体拆分结束后,跑 0-1 背包即可。
1.4 分组背包
与 0-1 背包的不同点在于,物品提前分好了组,组内物品互斥或限制选取数量。
很好想到,我们只需要在组内先进行 0-1 背包,再把组看作物品进行 0-1 背包,就可以得到答案。
也就是遍历每一个组,然后每一个组限制只能选一个,枚举容量从大到小,让每一个 \(dp_i\) 都最多选择一个做贡献。
1.5 依赖背包
与 0-1 背包的不同点在于选择某些物体时需要先选择其它物品。
复杂多变,没有固定模板吧,一般会转换为后文将会讲到的树形 dp 或者使用附件机制处理转换为带一些其它奇怪限制的分组背包。
1.6 优化技巧
- 滚动数组优化:
像比如 0-1 背包,第一维只会从 \(i - 1\) 转移到 \(i\),完全没有必要开 \(n\) 维,只需要开两维反复横跳更新,可以优化掉一维空间复杂度,是常用的空间优化方法。 - 排序处理:
根据题目要求或特性调整顺序,可以以玄学优化时间复杂度。 - 单调队列优化:
下文讲到的单调队列优化也能应用于背包问题。
Part 2 区间 dp
区间 dp 主要用于处理含有区间操作的或涉及区间最优值计算的问题,特点是能把大的区间问题转移为相互联系的子区间问题。
常见的状态设计方法是定义一个 \(dp[i][j]\) 代表处理好区间 i -> j 的最小代价。
通常来讲,区间 dp 想要转移长度为 \(len\) 的块时,需要已经有长度为 \(len-1\) 的块,这里举一个典型的式子为例:
此时,我们必须优先枚举 \(len\),再得到左右端点,否则就会遍历到没有值的点。
因此常见模板如下:
for(int len=2;len<=n;len++)
for(int i=1,j=len;j<=n;i++,j++)
for(int k=i;k<j;k++) 转移;
这里引用一道经典例题:
:::info[luogu P1775 石子合并(弱化版)]
设有 \(N\) 堆石子排成一排,其编号为 \(1,2,\cdots,N\)。每堆石子有一定的质量 \(m_i\)。现在要将这 \(N\) 堆石子合并成为一堆。每次只能合并相邻的两堆,合并的代价为这两堆石子的质量之和,合并后与这两堆石子相邻的石子将和新堆相邻。合并时由于选择的顺序不同,合并的总代价也不相同。试找出一种合理的方法,使总的代价最小,并输出最小代价。
:::
显然,如果我们考虑将 1 堆石子合并,答案为 0。如果将两堆石子合并,很显然是重量之和,但如果更多呢?我们还是从小处做起,不妨记 \(dp_{i, j}\) 为合并 \(i\sim j\) 堆石子的代价,我们知道这个结果肯定是从更小的两堆合并过来的,只需要枚举分割点 \(mid\),\(dp_{i, j} = \max_{mid = l}^{r -1}dp_{i, mid} + dp_{mid + 1, r}\),由于我们从更小的区间向更大区间转移,所以需要从小到大枚举 \(len = r - l + 1\),然后枚举 \(l, r, mid\)。
#include <iostream>
#include <cstring>
using namespace std;
constexpr int N = 3e2 + 5;
int n, m[N];
int dp[N][N];
int main () {
cin >> n;
memset(dp, 0x3F, sizeof(dp));
for (int i = 1; i <= n; ++ i) dp[i][i] = 0;
for (int i = 1; i <= n; ++ i) cin >> m[i];
for (int len = 2; len <= n; ++ len) {
for (int l = 1, r = l + len - 1; r <= n; ++ l, ++ r) {
int sum = 0;
for (int k = l; k <= r; ++ k) sum += m[k];
for (int mid = l; mid < r; ++ mid) {
dp[l][r] = min(dp[l][r], dp[l][mid] + dp[mid + 1][r] + sum);
}
}
}
cout << dp[1][n];
return 0;
}
这道题很清楚地显示出了区间 dp 的做法和本质,就是将区间拆为更小的区间来转移,区间长度从小至大,最终即可得到整个区间的答案。
事实上,有时区间 dp 有一些别的转移方法。
比如说这道题:调整队形。
我们定义 \(dp[i][j]\) 代表处理好原序列的 i -> j的最小代价。
那么,这里的转移只有另外两端。
所以,\(k\) 不一定是需要循环枚举的,不要总觉得区间 dp 是 \(O(n^3)\) 的哦。
Part 3 DAG 上的 dp
对于一部分题目的转移关系,呈现出 DAG(Directed Acyclic Graph,有向无环图)的关系。
转移关系如何呈现出 DAG?不妨引用一道例题来理解:
:::info[UVa 437 The Tower of Babylon]
有
\(n (n\leq 30)\) 种砖块,已知三条边长,每种都有无穷多个。要求选一些立方体摞成一根尽量高的柱子(每个砖块可以自行选择一条边作为高),使得每个砖块的底面长宽分别严格小于它下方砖块的底面长宽,求塔的最大高度。
:::
由于每个砖块的长宽严格小于下面砖块的长宽,所以可以以此作为建图依据。对于一种砖块可以从 \(3\) 种方向来放置,所以我们可以视作三种砖块,当砖块以一种方向放置时,此时的高就是贡献(权值)。
在图上,我们以一条边从一个砖块 \(A\) 连到另一砖块 \(B\),边权 \(w\) 为砖块 \(B\) 的高 \(h_B\),代表砖块 \(A\) 的上面可以放砖块 \(B\),会使塔的高度提升 \(w = h_B\),设根节点为大地,长宽为 \([\infty, \infty]\),最后跑一遍 topsort / dfs 就可以得到答案。
为什么建出来的图一定是 DAG?显然,建边 \(u\to v\) 代表了砖块 \(u\) 的两边长是严格大于砖块 \(v\) 的两边的,那么一条路径上的砖块两边长严格递减,所以不会出现环。
可以结合一个例子更直观的理解:
有两个砖块,边长为 \([31,41,59]\) 和 \([33,83,27]\),可以得到如下 DAG,图中节点表示长宽:
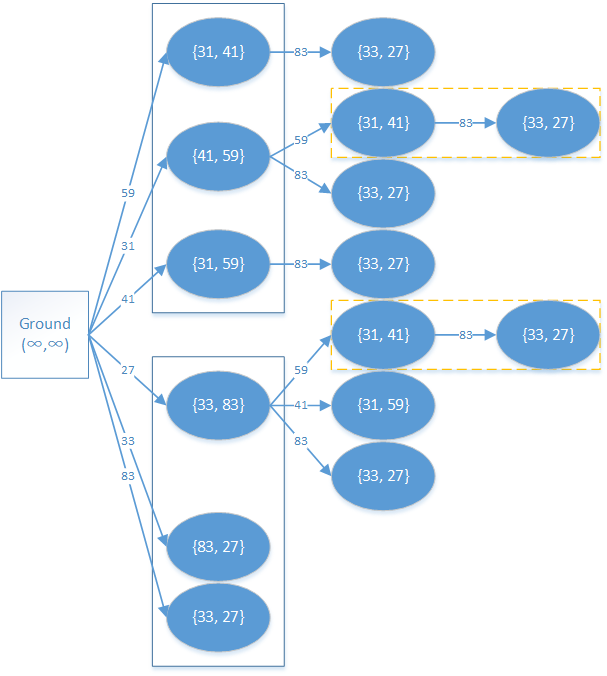
黄色虚线框是重复计算部分,记忆化吃掉就 ok。
关于建图,数据允许 \(\mathcal O(n^2)\) 暴力建,你也可以使用注意力观察到建图是一个二位偏序问题并使用充电器分治(CDQ 分治)优化到 \(\mathcal O(n\log n)\)。
最终时间复杂度 \(\mathcal O(n\log n + n)\),别忘了减玄学。
相似地,可以将部分题目的状态设计为路径累加价值,并找到转移关系建立 DAG,就可以以 topsort 代替转移方程来找到答案。这就是 DAG 上的 dp。
:::info[Solution for UVa 437]
wtcl,所以打的是 \(O(n ^ 2)\)。
#include <iostream>
#include <algorithm>
#include <cstring>
#include <cstdio>
using namespace std;
constexpr int N = 35;
constexpr int E = N * N * 18;
int n, cs;
struct item {
int a, b, h;
friend inline bool operator < \
(item A, item B) {
if (A.a != B.a) return A.a < B.a;
else return A.b < B.b;
}
} it[N << 2]; int cnt = 1;
int head[N << 2], nxt[E], ver[E], tot;
inline void add (int a, int b) {
ver[++ tot] = b;
nxt[tot] = head[a], head[a] = tot;
}
int mem[N << 2], fnl;
inline void dfs (int x, int val) {
if (val <= mem[x]) return;
mem[x] = val, fnl = max(fnl, val);
for (int i = head[x]; i; i = nxt[i]) {
int y = ver[i];
dfs(y, val + it[y].h);
}
}
inline void solve () {
int len[4];
cnt = 1;
for (int i = 1; i <= n; ++ i) {
cin >> len[1] >> len[2] >> len[3];
sort(len + 1, len + 4);
it[++ cnt] = {len[2], len[1], len[3]};
it[++ cnt] = {len[3], len[2], len[1]};
it[++ cnt] = {len[3], len[1], len[2]};
}
sort(it + 1, it + cnt + 1);
memset(head, 0, sizeof(head));
tot = 0;
for (int i = 2; i <= cnt; ++ i) {
add(1, i);
for (int j = i + 1; j <= cnt; ++ j) {
if (it[i].a < it[j].a and it[i].b < it[j].b) {
add(j, i);
}
}
}
memset(mem, -1, sizeof(mem));
fnl = 0;
dfs(1, 0);
printf("Case %d: maximum height = %d\n", ++ cs, fnl);
}
int main () {
while (cin >> n and n) solve();
return 0;
}
:::
Part 4 树形 dp
树形 dp 属于极为常见并且重要的一类 dp,主要用于解决在树上的求极值/方案数之类的问题。由于树固有的递归限制,一般树形 dp 采用递归实现。
下面就是一道著名的树形 dp 基础题,我们从这道例题来讲解树形 dp 的具体做法。
:::info[luogu P1352 没有上司的舞会]
某大学有 \(n\) 个职员,编号为 \(1\cdots n\)。
他们之间有从属关系,也就是说他们的关系就像一棵以校长为根的树,父结点就是子结点的直接上司。
现在有个周年庆宴会,宴会每邀请来一个职员都会增加一定的快乐指数 \(r_i\),但是呢,如果某个职员的直接上司来参加舞会了,那么这个职员就无论如何也不肯来参加舞会了。
所以,请你编程计算,邀请哪些职员可以使快乐指数最大,求最大的快乐指数。
:::
显然,根据题目中的描述,我们知道从属关系形成树形结构。
设计子问题:求解 \(dp_u\) 为以节点 \(u\) 为根节点的子树上的最大快乐指数,以此递归求解。
我们发现这样不好进行状态转移。从设计状态转移方程的角度思考,发现我们转移时需要参考的一个重要参数就是上司和下属分别是否参加舞会,而对于一棵子树下的枝叶,我们不关心他们是否参加舞会。
于是设计状态:\(dp_{u, 0/1}\) 表示对于以 \(u\) 为根节点的子树,节点 \(u\) 是否参加舞会分别的最大快乐指数,则有转移方程:
最终答案 \(ans = \max(dp_{root, 0}, dp_{root, 1})\)。
:::info[Solution for luogu P1352]
#include <iostream>
#include <algorithm>
using namespace std;
constexpr int N = 6e3 + 5;
int n, r[N], root;
int head[N], nxt[N], ver[N], tot;
inline void add (int a, int b) {
ver[++ tot] = b;
nxt[tot] = head[a], head[a] = tot;
}
int dp[N][2];
bool nrt[N];
void dfs (int x) {
dp[x][0] = 0, dp[x][1] = r[x];
for (int i = head[x]; i; i = nxt[i]) {
int y = ver[i];
dfs(y);
dp[x][0] += max(dp[y][0], dp[y][1]);
dp[x][1] += dp[y][0];
}
}
int main () {
cin >> n;
for (int i = 1; i <= n; ++ i) cin >> r[i];
for (int i = 1; i < n; ++ i) {
int l, k;
cin >> l >> k;
add(k, l);
nrt[l] = true;
}
for (int i = 1; i <= n; ++ i) {
if (!nrt[i]) {
root = i;
break;
}
}
dfs(root);
cout << max(dp[root][0], dp[root][1]);
return 0;
}
:::
树形 dp 拥有两个重要的分支问题,树上背包和换根 dp,树上背包已经归类到背包 dp 一类中的依赖背包,这里详细讲一讲换根 dp。
换根 dp,闻其名而知其意,以替换树的根节点为转移方式,一般用于求解找最优根的问题。在换根时动态地高效维护答案。
还是先来一道例题,这道例题对我来说意义重大,因为这是我第 1 道也是最后 1 道从看题到做出来完全独立思考且耗时小于 1h 的紫题。
翻译一下:水紫。
好吧它原来在 luogu 评的是蓝
:::info[luogu P10974 Accumulation Degree]
有一个树形的水系,由 \(N−1\) 条河道和 \(N\) 个交叉点组成。我们可以把交叉点看作树中的节点,编号为 \(1\sim N\),河道则看作树中的无向边。每条河道都有一个容量,连接 \(x\) 与 \(y\) 的河道的容量记为 \(c(x,y)\)。河道中单位时间流过的水量不能超过河道的容量。
有一个节点是整个水系的发源地,可以源源不断地流出水,我们称之为源点。除了源点之外,树中所有度数为 \(1\) 的节点都是入海口,可以吸收无限多的水,我们称之为汇点。也就是说,水系中的水从源点出发,沿着每条河道,最终流向各个汇点。
在整个水系稳定时,每条河道中的水都以单位时间固定的水量流向固定的方向。除源点和汇点之外,其余各点不贮存水,也就是流入该点的河道水量之和等于从该点流出的河道水量之和。整个水系的流量就定义为源点单位时间发出的水量。
在流量不超过河道容量的前提下,求哪个点作为源点时,整个水系的流量最大,输出这个最大值。
:::
很标准的换根 dp,显然我们可以先得到一个 \(\mathcal O(n^2)\) 的暴力,枚举每一个节点为根并搜索得到答案。
这一步可以通过树形 dp 来解决,我们怎么求解从根节点到部分叶子节点(终端节点)的最大容量?结合下面的例子来理解一下:
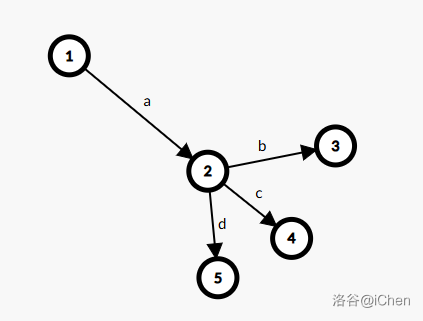
我们设节点 \(1\) 为原点,节点 \(3, 4, 5\) 为叶子节点,那么从 \(1\) 流向 \(3, 4, 5\) 的流量会受到什么限制?
- 第一种情况,分支前被限制,即 \(a < b + c + d\),这会导致在经过边 \(1\to 2\) 后流量已经不够后面最大地分配,所以节点 \(3, 4, 5\) 的最大流量和为 \(a\)。
- 第二种情况,分支后被限制,即 \(a > b + c + d\),虽然边 \(1\to 2\) 可以贡献 \(a\) 的流量过来,但是后续 \(b + c + d\) 无法承受,导致节点 \(3, 4, 5\) 最多只能贡献 \(b + c + d\) 的流量。
同样地,从叶子节点网上递归,判断限制类型,最终就可以得到根节点最大流量。
我们看一下下面的这个树结构中的节选图:
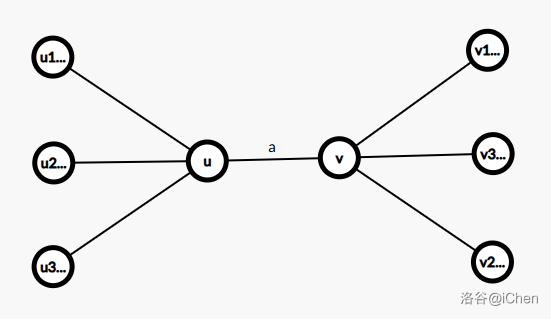
我们发现从 \(u\) 出发和从 \(v\) 出发,我们往两边的扩展有极大量的计算是重复的,从 \(u\) 出发到从 \(v\) 出发,相当于给左侧众多节点增加一个 \(a\) 的总体限制,给右侧众多节点撤去一个 \(a\) 的总体限制,这两个操作我们是可以在存储相关数据之后 \(\mathcal O(1)\) 地完成的。
所以根据以上方法,我们可以先以任意一个非叶子节点为根跑树形 dp 得到答案,然后再搜索一轮进行换根,时间复杂度为优越的 \(\mathcal O(n)\),即可 AC 此题。
请注意在换根时自动避雷叶子节点。
:::info[Solution for luogu P10974]
#include <cctype>
#include <cstdio>
#include <vector>
#include <cstring>
#include <algorithm>
using namespace std;
int num; char c;
inline int read () {
num = 0, c = getchar();
while (!isdigit(c)) c = getchar();
while (isdigit(c)) {
num = (num << 3) + (num << 1) + (c ^ 48);
c = getchar();
}
return num;
}
constexpr int N = 2e5 + 5;
int T, n, frt, fnl;
vector <pair <int, int>> go[N];
int ind[N];
int rof[N], ans[N];
void decom (int x, int fa) {
if (ind[x] == 1) return;
rof[x] = 0;
for (int i = 0; i < go[x].size(); ++ i) {
int y = go[x][i].first, w = go[x][i].second;
if (y == fa) continue;
decom(y, x);
rof[x] += min(rof[y], w);
}
}
void dfs (int x, int fa) {
fnl = max(fnl, ans[x]);
for (int i = 0; i < go[x].size(); ++ i) {
int y = go[x][i].first, w = go[x][i].second;
if (y == fa or ind[y] == 1) continue;
ans[y] = rof[y] + min(w, ans[x] - min(w, rof[y]));
dfs(y, x);
}
}
inline void init () {
memset(rof, 0x3F, sizeof(rof));
n = read();
for (int i = 1; i < n; ++ i) {
int u = read(), v = read(), w = read();
go[u].push_back({v, w});
go[v].push_back({u, w});
ind[u] ++, ind[v] ++;
}
for (int i = 1; i <= n; ++ i) {
if (ind[i] != 1) {
frt = i;
break;
}
}
}
inline void solve () {
decom(frt, 114514 - 1919810);
ans[frt] = rof[frt];
fnl = 0;
dfs(frt, 114514 - 1919810);
printf("%d\n", fnl);
for (int i = 1; i <= n; ++ i) go[i].clear();
memset(ind, 0, sizeof(ind));
memset(ans, 0, sizeof(ans));
}
int main () {
T = read();
while (T --) init(), solve();
return 0;
}
:::
对换根 dp 进行一下总结,我们会先以一个节点为根,得到此节点处的答案,然后寻找一个大概在 \(\mathcal O(\sqrt n)\) 以内一般为 \(\mathcal O(1)\) 的方法来在转移根节点的同时维护答案,最终结合成原问题的答案。
Part 5 状压 dp
状压 dp 顾名思义,就是状态压缩 dp ,相当于把 dp 的状态参数压缩了。例如,可以将某些物品选或不选表示为二进制的形式。这样不仅会使状态更好处理,还可以减少部分状态空间。
如果要使用状压 dp,通常来讲,dp 数组会开到 \(可能性^{数量}\) 这么大,所以一定要注意好数据范围,\(n\) 通常不会超过 \(18\)。
我们使用每一个进制位代表对应位数当前的情况,比如说,假如我们要定义当前的 \(n\) 个人在不在场,就是把一个 \(n\) 位的二进制位压缩成了一个数,这让我们可以使用进制位处理。
特殊的,在二进制位下,我们可以使用左移和右移。
注意:${\color{Red} 用左移的时候,小心爆 long long} $。
状压 dp 有的时候会和一些别样的东西加在一起,比如 T7_Daniel 曾经出的一道神秘题:平面直角坐标系。
首先,你需要先枚举四个节点,然后,你发现这个 \(a,b,c,d\) 的求解需要使用高斯消元。
你又发现连锁爆炸需要一个 bfs。
所以,状压 dp 是一个很容易和其他东西拼在一起的题,因为状压的思路出来之后就不会很难了,实际上看到 \(n\) 很小也差不多猜到了。
难点永远在于思考如何实现这个状压的转移。
例题:邦邦的大合唱站队
我们定义 dp[i] ,若 \(i\) 的二进制第 \(j\) 位为 \(1\) 则编号 \(j\) 已排好。
这样就可以用容斥原理进行 dp 转移了。
注:先预处理前缀中不同编号的人的数目,方便处理。
:::info[具体代码 :]
#include<bits/stdc++.h>
using namespace std;
constexpr int MAXSIZE=4e5;
char buf[MAXSIZE],*p1,*p2;
#define gc()(p1==p2&&(p2=(p1=buf)+fread(buf,1,MAXSIZE,stdin),p1==p2)?EOF:*p1++)
#define getchar gc
inline int read(){
int ret=0,op=1;char in=getchar();
while(!isdigit(in)){if(in=='-'){op*=-1;}in=getchar();}
while(isdigit(in)){ret=(ret<<3)+(ret<<1)+(in^48);in=getchar();}
return ret*op;
}int itemc,kindc,tot[100010][30],dp[1<<22];
int judge(int step,int kind){
return step&(1<<(kind-1));
}int get(int step,int kind){
return step^(1<<(kind-1));
}int main(){
itemc=read();kindc=read();
for(int i=1;i<=itemc;i+=1){
int item=read();
for(int j=1;j<=kindc;j+=1){
tot[i][j]=tot[i-1][j];
}tot[i][item]+=1;
}int limk=(1<<kindc);
for(int i=1;i<limk;i+=1){
dp[i]=itemc;int lim=0;
for(int j=1;j<=kindc;j+=1){
if(judge(i,j))lim+=tot[itemc][j];
}for(int j=1;j<=kindc;j+=1){
if(judge(i,j))dp[i]=min(dp[i],dp[get(i,j)]+tot[itemc][j]-tot[lim][j]+tot[lim-tot[itemc][j]][j]);
}
}printf("%d",dp[limk-1]);return 0;
}
:::
Part 6:数位dp
6.1 引入
顾名思义,数位dp就是解决数位相关问题的dp,通常以记忆化搜索的方式实现较为简单。
6.2 应用范围
数位dp的题目一般有以下特征:
1.给定数的区间[l,r],问满足条件的数有多少个。
2.转化后需要在数位上进行计数统计。
3.范围的上界很大,\(r\)通常在\(2^{31}-1\),甚至到\(1e18\)。
6.3 算法原理.
运用类似于前缀和的思想,将区间\([l,r]\)的答案转化为\([0,l-1]\)和\([0,r]\),用\(solve(r)-solve(l-1)\)得到答案。
统计答案可以选择记忆化搜索,也可以选择循环迭代递推。为了不重不漏地统计所有不超过上限的答案,要从高到低枚举每一位,再考虑每一位都可以填哪些数字,最后利用通用答案数组统计答案。
数位dp通常没有固定的转移方程模板(应为题目的约束条件一般都很奇怪),但用记忆化搜索实现的数位dp的代码框架长得都差不多,下面通过例题讲解。
6.4 例题讲解
形式化题意:
给定区间\([l,r](1e10 \le l\le r \le 1e11)\),求在\([l,r]\)中有多少个数满足:
要出现至少 3 个相邻的相同数字,数中不能同时出现 8 和 4。数必须同时包含两个特征才满足条件。
很明显,先利用前缀和的思想先转化为\([1,r]-[1,l-1]\),然后在将数进行数位的拆分,存在数组里方便后面dp时使用。在代码中表现为:
int solve(int x){
memset(dp,-1,sizeof dp);
while(x){
v.push_back(x%10);
x/=10;
}
reverse(v.begin(),v.end());
return dfs(0,0,1);
}
接着,开始考虑如何填数,从高位往低位填。
通常需要定义这两种变量,\(pos,lm\)
\(pos\)表示当前遍历到了第几位。
\(lm\)表示当前这位受不受限制,若\(lm=1\)表示这位最大只能填\(v[pos]\),若\(lm=0\)表示不受限制就可以填9。
在代码中表示为:k=lm?v[p]:9,代表了数字上界,为什么需要\(lm\)呢?因为统计的数必须小于等于\(x\),若\(pos-1\)填了\(v[pos-1]\),这以为就受到了限制不能填比\(v[pos]\)更大的。
易错点:在dfs中,递归时需写ans+=dfs(p+1,i==6,i==k&&lm) ,很容易忘记写上后面的\(lm\)为\(1\),因为如果上一位不受限制的话这一位还是可以随便填的。
上面的都是基本代码框架中带的变量,那根据题目要求的不同应该怎么变呢?
需要在dfs传参是带上约束条件的变量,如这道题中我就用了\(f1,f2,num1,num2,f1\)分别表示:是否出现8,是否出现4,上一个数字,上上个数字,是否出现过三个相等的情况。
dp的状态也很好描述,直接把这几个条件全写进dp里就行了,如\(dp[p][f1][f2][num1][num2][f3][lm]\)。
最后在枚举要填的数字时判断是否满足条件,如
dfs(p+1,f1||(i==8),f2||(i==4),i,num1,f3||(num1==num2&&num2==i),lm&&(i==k)
完整代码如下(注意这道题需要特判\(l==1e10\),因为\(l-1\)后数位会不同):
#include<bits/stdc++.h>
using namespace std;
#define int long long
vector<int> v;
int dp[60][2][2][10][10][2][2];
int dfs(int p,int f1,int f2,int num1,int num2,int f3,int lm){
if(p==v.size()) return f3&&!(f1&&f2);
if(dp[p][f1][f2][num1][num2][f3][lm]!=-1) return dp[p][f1][f2][num1][num2][f3][lm];
int ans=0,k=lm?v[p]:9;
for(int i=0;i<=k;i++){
ans+=dfs(p+1,f1||(i==8),f2||(i==4),i,num1,f3||(num1==num2&&num2==i),lm&&(i==k));
}
return dp[p][f1][f2][num1][num2][f3][lm]=ans;
}
int solve(int x){
v.clear();
memset(dp,-1,sizeof dp);
while(x){
v.push_back(x%10);
x/=10;
}
reverse(v.begin(),v.end());
return dfs(0,0,0,0,0,0,1);
}
signed main(){
int a,b;cin>>a>>b;
if(a==1e10) cout<<solve(b)-solve(a)+1;
else cout<<solve(b)-solve(a-1);
return 0;
}
有些题目中还会加上前导0的限制\(lead\),只有没有前导零的时候,才能计算的贡献。
那么前导零何时跟答案有关?
1.统计0的出现次数
2.相邻数字的差值
3.以最高位为起点确定的奇偶位
最后一个问题,记忆化搜索和迭代形式的dp谁更好解决数位dp呢?反正我个人时强推记忆化搜索,原因如下:
预处理后的迭代写法,往往边界条件很多,状态转移方程容易写错或漏项,其边界容易漏判误判;且不同题目时,迭代写法的DP过程变化较大,而记搜的dfs框架则非常套路,容易举一反三。
附上[SCOI2009] windy 数的迭代写法以供对比(调了30min):
#include<bits/stdc++.h>
using namespace std;
#define int long long
int a,b,dp[109][124];
int solve(int x){
vector<int> v;
while(x){
v.push_back(x%10);
x/=10;
}
int pre=-1,ans=0;
for(int i=v.size()-1;i>=0;i--){
for(int j=0;j<v[i];j++){
if(abs(j-pre)>=2) ans+=dp[i][j];
}
if(abs(v[i]-pre)<2) break;
pre=v[i];
if(i==0) ans++;
}
for(int i=1;i<v.size();i++){
for(int j=1;j<=9;j++) ans+=dp[i-1][j];
}
return ans;
}
signed main(){
cin>>a>>b;
for(int i=0;i<=9;i++) dp[0][i]=1;
for(int i=1;i<=10;i++){
for(int j=0;j<=9;j++){
for(int k=0;k<=9;k++)
if(abs(j-k)>=2) dp[i][j]+=dp[i-1][k];
}
}
cout<<solve(b)-solve(a-1);
return 0;
}
Part 7 计数 dp
计数 dp 解决的问题框架一般是求满足某条件的方案数,计数 dp 一般不单独列出来因为它大多混杂在其它类型中,像比如说前文的 luogu P1352 没有上司的舞会 就也属于计数 dp,但是由于 OI-Wiki 把它单独列出来了所以我们也要单独说一下。
好吧事实上是部分计数 dp 题目过于计数 dp 了,导致我们需要用解决计数 dp 的特殊思想来分析。
计数问题一般指求一个集合 \(S\) 的大小,在 OI 中,\(S\) 的大小有时会达到 \(\Theta(n ^ n)\) 甚至 \(\Theta(2^{n!})\) 的级别(当然,一般会对某一个固定的数取模),其中 \(n\) 是问题规模,所以我们不能逐一求出 \(S\) 的元素。
如果我们能够将 \(S\) 分成若干无交的子集,那么 \(S\) 的元素个数就等于这些部分的元素个数的和。如果这些子集的计数恰好与原问题类似,那么我们就可以通过类似动态规划的方法来解决。
——OI-Wiki
由于 iChen 的集合学的不好,这里引用 OI-Wiki 的一道例题以及其做法来讲述。
:::info[例题]
给定一个正整数 \(n\),求有多少个把 \(n\) 划分成 \(k\) 个正整数的和的方案,位置调换视为不同的划分方案。
:::
定义集合 \(S_{n, k}\) 为形如 \((a_1, a_2, a_3, \cdots, a_k)\) 的由正整数组成的集合,其中 \(\sum^{k}_{i = 1}a_i = n\),则问题答案即为 \(S_{n, k}\)。
接下来有如下推导:
根据 \(S_{n, k}\) 的定义,有:
由于 \(a_x\) 为正整数,所以 \(a_k\in [1, n - k + 1]\cap\mathbb Z\),则 \(S_{n, k}\) 可以按 \(a_k\) 划分为 \(n - k + 1\) 个子集,当 \(a_k = i\),这个子集为:
这个子集元素个数显然是等于 \(S_{n - i, k - 1}\) 的,由于 \(i\) 不同(这些子集下表第一维不同),故这些子集间无交集,所以:
这时候就能直接二维 dp 求解了,设 \(dp_{n, k} = |S_{n, k}|\),则有状态转移方程:
之后就是极其简单的线性 dp 了。
根据例题总结我们做计数 dp 的方法以及思路:先设计集合的表示方式(?),类似设计了 dp 状态,然后尝试将问题集合拆分为互不相交的子集,相当于状态转移方程,总之就是很吃注意力吧(大概率是 wtcl)。
其实大部分计数问题不用特意带入集合思想去绕,按正常思路和积累的 Trick 做就 ok 啦。
Part 8:数据结构优化 dp
数据结构优化 dp,顾名思义,就是用数据结构来优化 dp
8.1 单调队列优化
单调队列指的就是元素单调的队列,为了维护这个性质,当插入一个点时就会把队尾不满足单调性质的点全部弹出,然后再把元素放到队尾。
『单调队列主要用于维护两端指针单调不减的区间最值』——OI Wiki。
这里举一个例子来帮助理解上面那句话,滑动窗口能用单调队列做的原因就是题目要求的是当前“窗口”的最值,这个"窗口"就是原序列上的一个区间,而且这个区间的左端点和右端点都是单调不减的,因此可以用单调队列优化。
那么单调队列怎么维护两端指针单调不减的区间最值呢?
对于当前要求的区间 \([l,r]\),我们让单调队列中维护的元素就相当于经过如下过程生成的一个单调队列:
- 创建一个空的单调队列
- 把 \([1,r]\) 中的所有元素入队
- 把编号在小于 \(l\) 的所有元素出队
如果根据题目要求来设置单调队列的单调性(求区间最小值就维护一个单调递增队列,求区间最大值就维护一个单调递减序列),那么此时队首元素就是答案。因为当我们插入一个元素时只会删除前面和它相比不合法的元素,而这个元素必定是会被插入的,因此当前的答案肯定不会被弹掉,否则它就不是当前的答案了,因为一个元素只能被它后面的元素弹掉。
如果从上一个区间 \([l',r']\) 转移到 \([l,r]\),满足 \(l'\le l,r'\le r\),那么只需要在上一个区间的单调队列的基础上只需要把 \([r'+1,r]\) 的元素入队,然后再弹掉编号小于 \(l\) 的就行了。因为每个元素只会入队和出队一次,所以总的时间复杂度是 \(\Theta(n)\) 的。
例题:P3957 跳房子
很明显分数具有单调性,于是直接二分 \(g\),求出此时的最大分数。显然有一种动态规划,设 \([l,r]\) 表示能跳的步数的区间,\(f_i\) 表示跳到第 \(i\) 个点的最大权值和,则有
最大分数即为
暴力转移 \(O(n^2)\),考虑优化。因为 \(x_i\) 单调递增,所以可以转移的 \(j\) 所在的区间的两个端点单调不降,因此可以使用单调队列进行优化。具体实现如下:
:::info[代码]
#include <iostream>
#define int long long
using namespace std;
constexpr int N = 5e5 + 10, inf = 0x3f3f3f3f3f3f3f3f;
int n, d, k, a[N], b[N], f[N], q[N], head, tail;
bool check(int mid) {
int l = max(1ll, d - mid), r = d + mid, res = -inf;
// [l,r] 表示当前能跳的步数区间
head = tail = 0, f[0] = 0; // 清空单调队列,初始化
for (int i = 1, ll = 0; i <= n; i++) {
// 这里用一个单指针 ll 维护插入
while (ll < i && a[i] - a[ll] >= l) {
// 单调队列核心代码,插入元素
while (head < tail && f[q[tail - 1]] <= f[ll]) tail--;
q[tail++] = ll;
ll++;
}
while (head < tail && a[q[head]] < a[i] - r) head++;
if (head == tail) f[i] = -inf;
else f[i] = f[q[head]] + b[i];
res = max(res, f[i]);
}
return res >= k;
}
signed main() {
ios::sync_with_stdio(false);
cin >> n >> d >> k;
for (int i = 1; i <= n; i++)
cin >> a[i] >> b[i];
int l = 0, r = a[n] + 1; // r 取理论极值 + 1
while (l < r) {
int mid = (l + r) >> 1;
if (check(mid)) r = mid;
else l = mid + 1;
}
if (l == a[n] + 1) cout << "-1" << endl;
else cout << l << endl;
return 0;
}
:::
例题 2
题目描述
回到这座小镇后,她的新工作是维修电线。
现在,有一根电线坏了。已知电线长度可能为 \(1,2,\cdots,n\) 中的一个数。现在,她需要知道电线的长度。
她可以花费 \(a_i\) 块钱购买长度为 \(i\) 的电线。购买这根电线后,她能知道所需要的电线长度是否 大于 \(i\)。
保证 \(a_1 \le a_2 \le \cdots \le a_n \le 10^9\)。
问她至少要花多少钱才能保证知道需要电线的长度。
$ 1 \le n,\sum n \leq 7100,T \leq 500 \(。\)\sum n$ 表示所有数据中 \(n\) 的和。
样例:
1
2
1 2
1
思路
首先,我们发现这道题问的是查询区间 \(1-n\),所以我们想到了区间 dp。
我们设 \(f_{i,j}\) 表示区间 \(i\) 到 \(j\) 至少要花多少钱。
转移方程式:
这一步应该没问题吧,就相当于在区间 \(i\) 到 \(j\) 中询问了 \(k\),选择其中的一部分。
然后分析时间复杂度:\(O(Tn^3)\),当然过不了。
我们想着优化。
然后,我们找到了 \(\min\) 这个关键的东西,然后又看到了形如 \(f+a\) 的式子,想到了单调队列优化。
但是,我们发现有一个 \(\max(f_{i,k},f_{k+1,j})\),貌似它不是单调的。
我们分析一下,发现随着 \(k\) 的增大,它先减小,再增大,因为 \(f_{i,k}\) 一直增大,\(f_{k+1,j}\) 一直减小。
但是这个 先减小再增大 没什么用,我们只能分类讨论 \(f_{i,k}\) 和 \(f_{k+1,j}\) 哪个大。
然后我们发现:要知道这两个那个大,只需要知道他们的差是否是正如,然后,我们发现他们的差是单调的!
所以我们只需要找到第一个使 \(f_{i,k}>f_{k+1,j}\) 的点,作为分界点,然后分类讨论。
先想想怎么找分界点。
找分界点
首先,因为这道题很像二分,所以我们想到了二分查找,但是它有一个 \(\log\),都到 \(6*10^8\) 级别了,还是要想想更优的方法。
然后我们发现,我们是在做 dp,是可以通过旁边的东西转移的。
我们令这个分界点为 \(d_{i,j}\),那么 \(d_{i,j}\le d_{i,j+1}\),这应该没问题吧。
这一步能理解,但是很难想到。
好的,然后我们找到了分界点,开始考虑怎么分类讨论。
当 \(f_{i,k}>f_{k+1,j}\) 时:
这时候,我们只需要找到 \(\min (f_{i,k}+a_k)\),但貌似不能维护。但瞪一下题目:保证 \(a_1 \le a_2 \le \cdots \le a_n \le 10^9\),再加上 \(f_{i,k}\) 也是单调递增的,所以最小值在第一个 \(k\)。
当 \(f_{i,k}\le f_{k+1,j}\) 时:
这时候,我们需要找到 \(\min (f_{k+1,j}+a_k)\),我们发现,\(f_{k+1,j}\) 是单调递减的,但是 \(a_k\) 又是单调递增的,所以很难找到最值。
我们想到可以用单调队列优化。
在单调队列中,我们只需要找到最小的 \(k\) 就行了。
总体来说,这道题思维量不小,但是代码还是很短的。
还想吐槽一下,不开 long long \(0\) 分,你猜我怎么知道的?
::::info[比过程还短的代码]
试问上面的过程短还是代码短?
#include<bits/stdc++.h>
#define int long long//不开 long long 过样例,有 0 分
using namespace std;
int n,a[7110];
int f[7110][7110];
int q[7110],l=1,r=0;
void solve() {
cin>>n;
for(int i=1; i<=n; i++)cin>>a[i];
/*这道题的枚举顺序也是别样的*/
for(int j=2; j<=n; j++) {
l=1,r=0;
q[++r]=j;
int d=j;//分界点
for(int i=j-1; i>=1; i--) {
if(j-i==1) {
f[i][j]=a[i];
continue;
}
while(d>i&&f[i][d-1]>f[d][j])d--;
/*找到分界点(注意,这不是单调队列的 while)*/
f[i][j]=f[i][d]+a[d];
while(q[l]>=d&&l<=r)l++;//判断是否在区间内
if(l<=r)f[i][j]=min(f[i][j],f[q[l]+1][j]+a[q[l]]);//不要把 j 打成 r
while(f[q[r]+1][j]+a[q[r]]>=f[i+1][j]+a[i]&&l<=r)r--;
q[++r]=i;
}
}
cout<<f[1][n]<<endl;
}
signed main() {
int T;
cin>>T;
while(T--) {
solve();
}
return 0;
}
::::
8.2 单调栈
单调栈类似单调队列,即满足单调性质的栈。插入元素时把不符合单调性质的栈顶弹出,再把元素放到栈顶就行了。
单调队列一般用于寻找左侧/右侧第一个更大/更小元素的问题,当然,它不仅仅局限于这些问题,事实上,和单调队列相比,它更加灵活(题也更毒瘤了),所以我这里通过一道例题来讲解单调栈优化 dp。
例题:CF1407D Discrete Centrifugal Jumps
状态设计十分显然,设 \(f_i\) 表示到第 \(i\) 座大楼的最少跳跃次数。转移按条件分三类:
- \(j+1=i\)
- \(\displaystyle{\max_{k\in[j+1,i-1]}h_k<\min(h_i,h_j)}\)
- \(\displaystyle{\min_{k\in[j+1,i-1]}h_k>\max(h_i,h_j)}\)
第一类转移十分显然,\(f_i\leftarrow f_{i-1}\)。
第二类转移不好处理,考虑把 \(\min\) 拆成两个条件:
- \(\displaystyle{\max_{k\in[j+1,i-1]}h_k<h_i}\)
- \(\displaystyle{\max_{k\in[j+1,i-1]}h_k<h_j}\)
对于第二个条件,我们维护一个依次插入了 \(h_1,\cdots,h_i-1\) 的由栈顶向栈底严格递增的单调栈,那么所有满足第二个条件的 \(j\) 必定在单调栈内,因为一个元素出栈的充要条件就是它的后面(栈顶方向)存在一个大于或等于它的 \(h_c\),那么此时 \(\displaystyle{\max_{k\in[j+1,i=1]}}\ge h_c\ge h_j\),就不满足条件了;反之就满足条件。
对于第一个条件,从栈顶(编号大的一方)的 \(j\) 向栈底(编号小的一方)的 \(j\) 遍历,则 \(\displaystyle{\max_{k\in[j+1,i-1]}}h_k\) 单调不降,所以当有一个时刻 \(\displaystyle{\max_{k\in[j+1,i-1]}h_k}\ge h_i\) 时,后面(再往栈底走)的 \(j\) 就必定不满足条件了。我们发现上面这个跳出条件和单调栈弹出的跳出条件(就是停止跳出的条件)\(\displaystyle{h_{top}=\max_{k\in[top,top_0]}h_k>h_i}\) 是一个包含关系(下面包含上面),所以我们可以在弹栈的时候进行更新,更新次数小于等于弹栈次数。
而第三类转移和第二类的唯一区别就是最大值和最小值和大于小于符号互换了,相对与第二类转移的解法只需要把栈改成由栈顶向栈底严格递减的单调栈就行了。
具体实现看代码,及其简短:
:::info[代码]
#include <iostream>
using namespace std;
constexpr int N = 3e5 + 10;
// sa+sat 是从顶到底单调递减的单调栈,用于维护第三类转移
// sb+sbt 是从顶到底单调递增的单调栈,用于维护第二类转移
int n, a[N], f[N], sa[N], sb[N], sat, sbt;
int main() {
ios::sync_with_stdio(false);
cin >> n;
for (int i = 1; i <= n; i++)
cin >> a[i];
f[1] = 0, f[0] = n;
// 这里注意要把 f[0] 初始化为无穷大
// 因为本题 f 理论上限为 n-1,所以无穷大取 n
sa[++sat] = sb[++sbt] = 1;
for (int i = 2; i <= n; i++) {
f[i] = f[i - 1] + 1;
while (sat && a[i] < a[sa[sat]])
f[i] = min(f[i], f[sa[(sat--) - 1]] + 1);
// 注意这里是 sat-1,下面也是一样的 sbt-1
// 因为合法的是这个区间,要从这个区间的左端点的左边转移过去
while (sat && a[i] == a[sa[sat]]) sat--;
while (sbt && a[i] > a[sb[sbt]])
f[i] = min(f[i], f[sb[(sbt--) - 1]] + 1);
while (sbt && a[i] == a[sb[sbt]]) sbt--;
sa[++sat] = sb[++sbt] = i;
}
cout << f[n] << endl;
return 0;
}
:::
8.3 其它数据结构优化
像线段树、树状数组、K-D Tree、树套树这种数据结构一般都只能根据具体的题目来确定用什么和怎么用,没有什么统一的原则,总之就是涉及到区间更新一个值或一个值更新一个区间时可以用。
首先有一个性质:如果要拔高,那拔高的区间的右端点一定是整排玉米最右边的一个,因为这样不会影响相对大小关系,拔高了还会更优。
根据题意就可以的到动态规划的状态:\(f_{i,j}\) 表示考虑前 \(i\) 个玉米,已经拔高了 \(j\) 次时的最大未拔除的玉米数量,转移方程:
下面的条件式子是一个三维偏序的结构,因为这里 \(f\) 有两维,所以 CDQ 分治不好用,考虑先用枚举顺序卡掉第一维 \(i\),然后用二维树状数组维护最大值(以你为这里左端点都是从最左边的 \(1\) 或 \(0\) 开始的,所以可以用树状数组)就行了。
实现如下:
:::info[代码]
#include <cstring>
#include <iostream>
using namespace std;
// K 为 a[i]+j 的最大值
constexpr int N = 1e4 + 10, M = 510, K = 5510;
int n, m, a[N], c[M][K], f[N][M], ans;
int query(int x, int y) {
int res = 0;
for (int i = x; i; i -= i & -i)
for (int j = y; j; j -= j & -j)
res = max(res, c[i][j]);
return res;
}
void update(int x, int y, int v) {
for (int i = x; i < M; i += i & -i)
for (int j = y; j < K; j += j & -j)
c[i][j] = max(c[i][j], v);
}
int main() {
ios::sync_with_stdio(false);
cin >> n >> m;
for (int i = 1; i <= n; i++) cin >> a[i];
for (int i = 1; i <= n; i++) {
for (int j = 0; j <= m; j++)
f[i][j] = query(j + 1, a[i] + j) + 1;
// j+1 是为了适应树状数组从 1 开始的要求,下同
for (int j = 0; j <= m; j++)
update(j + 1, a[i] + j, f[i][j]), ans = max(ans, f[i][j]);
}
cout << ans << endl;
return 0;
}
:::
8.4 CDQ 分治优化
这应该算在数据结构里面吧
CDQ 分治主要是用来处理转移点是一坨的线性动态规划(当然要处理不是线性的也行),这利用了它只用处理一部分对另一部分的贡献的特点,因此可以方便地进行转移,或者利用数据结构辅助转移。
思维很简单,但是应用中的变化很多,灵活性极高。
注:为了方便说明,下设
- \(\text{mxc}(l,r)=\displaystyle{\max_{l\le i\le r}c_i}\)
- \(\text{mnd}(l,r)=\displaystyle{\min_{l\le i\le r}d_i}\)
- \(\text{rng}(l,r)=[\text{mxc}(l,r),\text{mnd}(l,r)]\)
有一个非常显然的暴力动态规划:令 \(f_i\) 表示把前 \(i\) 个小朋友分组能分的最大组数和对应的方案数,那么有
(当 \(f_i\leftarrow f_j\) 时,如果 \(f_i\) 的最大值等于 \(f_j\) 的最大值,那么 \(f_i\) 的方案数加上 \(f_j\) 的方案数;如果 \(f_i\) 的最大值小于 \(f_j\) 的最大值,那么令 \(f_i=f_j\))
可以清晰地感觉到对于一个 \(i\) 来说,\(j\) 就是离散的一坨,没有任何规律可循。于是这个时候我们就可以利用 CDQ 分治只用处理一部分到另一部分的贡献的性质,使用 CDQ 分治来解决这道题。
具体来说,假设现在正在计算 \(f_{[l,m]}\) 对 \(f_{[m+1,r]}\) 的贡献。则 \(f_i,i\in[m+1,r]\) 会被 \(f_{j},j\in[l,m]\) 更新当且仅当 \(i-j\in\text{rng}(j+1,i)\)。为了方便计算,把 \(\text{rng}(j+1,i)\) 拆成 \(\text{rng}(j+1,m)\cap\text{rng}(m+1,i)\),那么条件可以拆分为
- \(i-j\in\text{rng}(j+1,m)\)
- \(i-j\in\text{rng}(m+1,i)\)
即
- \(\text{mxc}(j+1,m)\le i-j\le\text{mnd}(j+1,m)\)
- \(\text{mxc}(m+1,i)\le i-j\le\text{mnd}(m+1,i)\)
有
- \(j+\text{mxc}(j+1,m)\le i\le j+\text{mnd}(j+1,m)\)
- \(i-\text{mnd}(m+1,i)\le j\le i-\text{mxc}(m+1,j)\)
对于条件 \(1\),我们可以在对应区间 \([j+\text{mxc}(j+1,m),j+\text{mnd}(j+1,m)]\) 的左端点和右端点的右边一个分别打上加入和删除操作的标记,到遍历到对应的 \(i\) 时执行。对于条件 \(2\),这是一个区间的形式,因此可以使用线段树进行区间查询,至此条件 \(1\) 就可以转化为在线段树上的单点修改。
所以这里可以用线段树进行维护,把每个 \(i\) 应该做的事情(插入、删除)然后在对应的 \(i\) 执行,随后线段树区间查询即可,单次更新复杂度 \(\Theta(n\lg n)\)
处理完左对右的贡献,跑一遍 CDQ 分治就行了,总时间复杂度 \(\Theta(n\lg^2 n)\)。具体实现看代码:
:::info[代码]
#include <iostream>
#include <vector>
#define endl '\n'
using namespace std;
using pii = pair<int, int>;
using pib = pair<int, bool>;
using state = pii;
// state 用于表示 f 的一个状态:pair<int: 最大组数, int: 方案数>
constexpr int N = 1e6 + 10, mod = 1e9 + 7;
constexpr state basic_state(-1919810, 0);
// 合并两个状态
state operator+(const state& a, const state& b) {
if (a.first == b.first)
return state(a.first, (a.second + b.second) % mod);
return a.first > b.first ? a : b;
}
// 合并两个区间(求交集)
pii operator&(const pii& a, const pii& b) {
return pii(max(a.first, b.first), min(a.second, b.second));
}
int n;
pii a[N];
state f[N];
struct {
state e[N << 2];
void pushup(int u) {
e[u] = e[u << 1] + e[u << 1 | 1];
}
void build(int u = 1, int l = 0, int r = n) {
e[u] = basic_state;
if (l == r) return;
int mid = (l + r) >> 1;
build(u << 1, l, mid);
build(u << 1, mid + 1, r);
}
void update(int pos, const state& val, int u = 1, int l = 0, int r = n) {
if (l == r) return void(e[u] = val);
int mid = (l + r) >> 1;
if (pos <= mid) update(pos, val, u << 1, l, mid);
else update(pos, val, u << 1 | 1, mid + 1, r);
pushup(u);
}
state query(int ql, int qr, int u = 1, int l = 0, int r = n) {
if (ql <= l && r <= qr) return e[u];
int mid = (l + r) >> 1;
if (qr <= mid) return query(ql, qr, u << 1, l, mid);
if (ql > mid) return query(ql, qr, u << 1 | 1, mid + 1, r);
return query(ql, qr, u << 1, l, mid) + query(ql, qr, u << 1 | 1, mid + 1, r);
}
} seg; // 单点修改,区间查询的线段树
struct {
// 一个操作是一个 pair<int:要操作的 j, bool: 插入(1)/删除(0)>
pib e[N];
int h[N], ne[N], idx;
void push(int u, const pib& dat) {
++idx;
e[idx] = dat;
ne[idx] = h[u];
h[u] = idx;
}
} lis; // 使用模拟链表来存每个 i 对应的操作
void cdq(int l, int r) {
if (l == r) return;
int mid = (l + r) >> 1;
cdq(l, mid);
lis.idx = 0;
for (int i = mid + 1; i <= r + 1; i++)
lis.h[i] = 0;
pii cur(0, n);
for (int i = mid; i >= l; i--) {
int ll = max(i + cur.first, mid + 1), rr = min(i + cur.second, r);
cur = cur & a[i];
if (ll > rr) continue;
lis.push(ll, pib(i, true)), lis.push(rr + 1, pib(i, false));
}
cur = pii(0, n);
for (int i = mid + 1; i <= r + 1; i++) {
for (int j = lis.h[i]; j; j = lis.ne[j]) {
if (lis.e[j].second)
seg.update(lis.e[j].first, f[lis.e[j].first]);
else
seg.update(lis.e[j].first, basic_state);
}
if (i == r + 1) break;
cur = cur & a[i];
int ll = max(i - cur.second, l), rr = min(i - cur.first, r);
if (ll > rr) continue;
pii t = seg.query(ll, rr);
if (t.second)
f[i] = f[i] + pii(t.first + 1, t.second);
}
cdq(mid + 1, r);
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n;
for (int i = 1; i <= n; i++)
cin >> a[i].first >> a[i].second;
f[0] = state(0, 1);
for (int i = 1; i <= n; i++)
f[i] = basic_state;
seg.build();
cdq(0, n);
if (f[n].second)
cout << f[n].first << ' ' << f[n].second << endl;
else cout << "NIE" << endl;
return 0;
}
:::
8.5 数据结构特有的dp=记忆化搜索
Tips:数据结构优化 dp 出题人通常为了防止数据结构的一些神秘常数问题,会将时间开到标程的 \(3\) 倍左右。
但先前有人说过:一道可以使用 dp 过掉且跑得飞快的题,记忆化搜索也很有机会。
首先设计状态,先考虑设 \(dfs(t,i,j)\) 表示 t 时刻,在第 i 行第 j 列的位置走过的最长路径长。
故而有,\(dfs(t,i,j)=max(dfs(t-1,i,j),dfs(t-1,x,y))\)
其中,\((x,y)\) 为上一个合法的转移位置,即取决于方向下的上一个非家具位置
这个时候我们可以暴力转移,从 \(t\) 转移 \(t+1\),不难写出一个从 \(dfs(1,x,y)\) 开始的 \(O(Tnm)\) 的暴力转移。
此时你发现这些节点可以使用单调队列优化,于是你使用少量大脑就通过了这道题。
link,最大的点只跑了 \(339\)ms,也没有慢多少,出题人很良心,没有卡栈空间。
#include<bits/stdc++.h>
using namespace std;
const int N=205;
int dp[N][N][N];//代表第k个时间段在i,j的最大路径长
char mp[N][N];//mp[i][j]是对应地图
int n,m,x,y,k;
int s[N],t[N],d[N];
int dx[5]={0,-1,1,0,0};
int dy[5]={0,0,0,-1,1};
inline int read(){
int s=0,f=1;char ch=getchar();
while(!isdigit(ch)){
if(ch=='-') f=-1;
ch=getchar();
}
while(isdigit(ch))
s=(s<<3)+(s<<1)+(ch^48),ch=getchar();
return s*f;
}
inline int dfs(int pos,int x,int y){//(pos,x,y)代表在第pos个时间段跑到(x,y)
if(pos==k+1) return 0;//落幕
if(dp[pos][x][y]!=-1) return dp[pos][x][y];//已经有了答案直接返回
int len=t[pos]-s[pos]+1;
int res=dfs(pos+1,x,y);//原地不动也是一种可能,初始化答案
for(int i=1;i<=len;i++){//移动几步
int nx=x+i*dx[d[pos]],ny=y+i*dy[d[pos]];//新的地方是(nx,ny)
if(nx<1 || nx>n || ny<1 || ny>m) continue;//不合法
if(mp[nx][ny]=='x') break;//不能去,全部爆炸
res=max(res,i+dfs(pos+1,nx,ny));//i是目前移动次数,dfs(pos+1,nx,ny)是新的移动次数
}
return dp[pos][x][y]=res;
}
signed main(){
cin>>n>>m>>x>>y>>k;
for(int i=1;i<=n;i++)
for(int j=1;j<=m;j++) cin>>mp[i][j];
memset(dp,-1,sizeof dp);
for(int i=1;i<=k;i++)
s[i]=read(),t[i]=read(),d[i]=read();
cout<<dfs(1,x,y)<<"\n";
return 0;
}
8.6 \({\color{Red} 数据结构优化 dp 的 Tricks 和警示 }\)
因为 T7_Daniel 太 naive 了,他决定把自己当唐氏儿的经历分享出来。
1.如果你发现一个节点是从某方向的某节点转移过来的,考虑单调队列优化。
2.如果你发现一个节点是从某方向的一串节点转移过来的,考虑前缀和,切记不要过度迷恋数据结构。
3.如果你发现一个节点是从一个大矩阵转移的,且矩阵长度固定,通常来讲,正确的做法是定义一个 \(f[i][j]\) 代表从 \((i,j)\) 开始沿其中一个方向的对应信息,然后使用单调队列就可以实现另外一个方向。
4.切记,能用树状数组就不要用线段树,线段树常数太大了,以至于一个二维线段树,理论 \(O(nm \log n\log m)\) 过不掉 \(n=m=500\)。
Part 9:斜率优化 dp
9.1 引入
注:以下用 \(\text{slope}(P_1,P_2)\) 表示直线 \(P_1P_2\) 的斜率。
让我们先看一道例题:玩具装箱。
现在有 \(n\) 个玩具,长度分别为 \(C_i\),我们可以把连续的玩具 \([l,r]\) 装进一个容器内,制造容器的代价为
其中 \(L\) 是常数,\(n\le5\times 10^4,1\le C_i,L\le10^7\)。
求把所有玩具都装入容器内的最小总代价。
很容易就可以列出动态规划方程:设 \(f_{i}\) 表示前 \(i\) 个玩具装入任意个容器所需的最小费用,转移方程是
其中
边界条件为 \(f_0=0\)。
这样我们就得到了一个 \(O(n^2)\) 的算法,很难通过本题吗,我们需要尝试优化
首先把和 \(j\) 无关的项拆出去,为了方便计算,我们设 \(B_i=S_i+i,L'=L+1\),则有
我们发现这个转移方程中 \(B_j\) 的系数与 \(i\) 有关,所以我们不能使用单调队列来优化它。像这种我们就只能使用斜率优化。
9.2 斜率优化
对于两个可能的决策点(可能用于更新 \(f_i\) 的 \(j\) 为当前的决策点,而使上式取到 \(\min\) 的就是最优决策点) \(j_1\) 和 \(j_2\) 满足 \(1\le j_1<j_2<i\),若选择 \(j_2\) 要比选择 \(j_1\) 更优,那么有
令
则上式可以表示为
如果让 \(P_j=(X_j,Y_j)\),并把它视为一个点,那么 \(\frac{Y_{j_2}-Y_{j_1}}{X_{j_2}-X_{j_1}}\) 就是直线 \(P_{j_1}P_{j_2}\) 两点的斜率 \(\text{slope}(P_{j_1},P_{j_2})\),\(j_2\) 更优的条件就变成了
如果有这样的三个点 \(A,B,C\),对应的 \(j\) 分别为 \(j_1,j_2,j_3\):
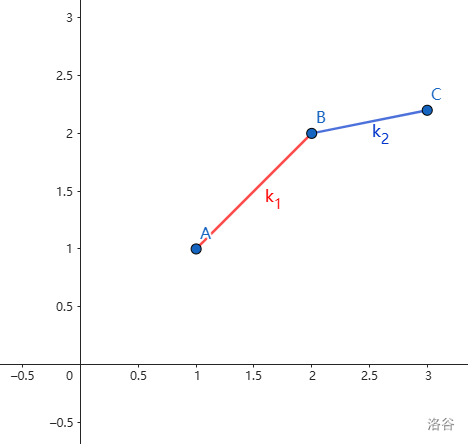
满足 \(k_1>k_2\)。设 \(k_0=2B_i\),根据上面推出来的式子,有
- 若 \(k_1<k_0\),则 \(j_2\) 优于 \(j_1\);反之若 \(k_0<k_1\),则 \(j_1\) 优于 \(j_2\)。
- 若 \(k_2<k_0\),则 \(j_3\) 优于 \(j_2\);反之若 \(k_0<k_2\),则 \(j_2\) 优于 \(j_3\)。
分类讨论 \(k_0\) 和 \(k_1,k_2\) 之间的大小关系,通过上面两条,得
- 若 \(k_2<k_1<k_0\),则 \(j_3\) 优于 \(j_2\) 优于 \(j_1\)。
- 若 \(k_2<k_0<k_1\),则 \(j_1\) 和 \(j_3\) 都优于 \(j_2\)。
- 若 \(k_0<k_2<k_1\),则 \(j_1\) 优于 \(j_2\) 优于 \(j_3\)。
从上面所有情况可以发现,无论如何 \(j_2\) 都不可能成为最优决策点,所以可以把 \(j_2\) 从候选的最优决策点中移出,只保留 \(j_1\) 和 \(j_3\),之后变为这样:
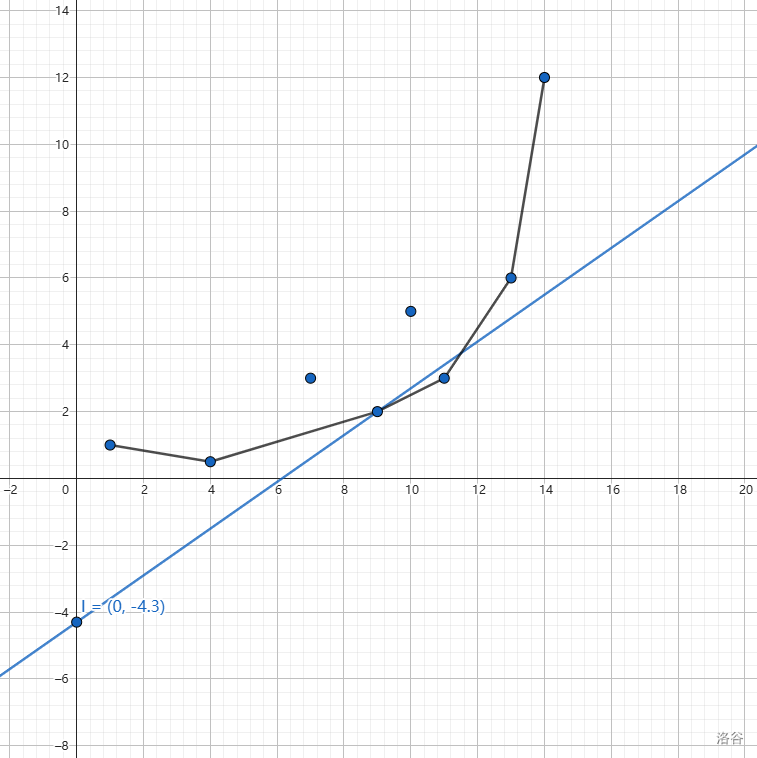
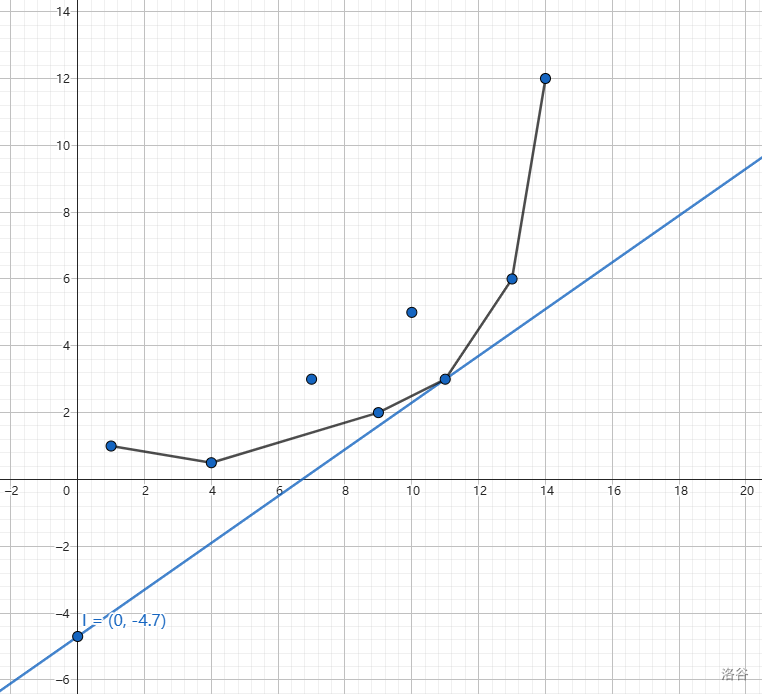
对于每个决策点都可以这样操作,于是最后两两决策点之间的斜率是单调上升的,换句话说,这就形成了一个下凸包:
那么我们维护这样一个下凸包有什么用呢?让我们考虑一下最优决策点在这个凸包上的位置。假设这个最优决策点为 \(j_k\),那么和它前面的 \(j_{k-1}\) 和 \(j_{k+1}\) 相比,它肯定都要更优,根据上面斜率推出来的式子,可以得到
同时因为斜率是单调上升的,那么在 \(j_k\) 之前(包括 \(j_k\))的决策点对应的 \(P\) 两两相邻点的斜率一定是小于等于 \(2B_i\) 的,在 \(j_k\) 之后(包括 \(j_k\))的决策点对应的 \(P\) 两两相邻点的斜率一定是大于 \(2B_i\) 的。这就保证了这个 \(j_k\) 是最优决策点。
也就是对一个决策点来说,只要它和它前面的点的斜率小于等于 \(2B_i\),并且它和它后面的点的斜率大于 \(2B_i\),我们就能推出这个决策点一定是最优决策点。
考虑边界情况,如果这个决策点是第一个决策点呢?那么我们就只需要计算它和它后面的决策点的斜率是否大于 \(2B_i\) 了;反之如果是最后一个决策点,那么我们就只需要计算它和它前面的斜率是否小于等于 \(2B_i\) 了。
到这里,我们已经可以通过维护一个下凸包,并且对于每个 \(i\) 在它前面所有 \(j\) 组成的下凸包中二分最优决策点,从而实现 \(O(n\lg n)\) 的复杂度,在本题 \(n\le5\times10^4\) 的数据范围下已经能通过本题。
在这里再补充一些具体实现,因为我们维护的是凸包,所以如果不想在凸包里面再多维护一个 \(j\) 的话,我们可以通过 \(X\) 和 \(Y\) 推出 \(f_i\)。具体地说,设 \(j\) 为最优决策点,有
9.3 另一种理解方式
事实上如果这里令 \(y=Y_j,x=X_j,k=2B_i,b=f_i-(B_i-L')^2\) 的话,就变成了
移一下项,得到
因为 \(y\) 和 \(x\) 是随当前决策点 \(j\) 的变化而变化的,所以当选定一个决策点时 \(y=kx+b\) 就是一条过点 \((x,y)\) 的斜率为 \(k\) 的直线(有点抽象),而直线的截距 \(b\) 就是我们要最小化的东西。放在坐标系中长这样:
(这是一个任意决策点)
(这是最优决策点)
我们称这条直线为目标直线。
当我们选择一个决策点时,事实上就是把目标直线平移直到过决策点对应的二维坐标系上的点,然后它和 \(y\) 轴的交点(图中是 \(I\))的纵坐标就是 \(f_i-(B_i-L')^2\),从而实现了最小化。
比较上图中两个决策点,设 \(P_1\) 表示一个决策点,\(P_2\) 表示 \(P_1\) 右边的决策点。
若 \(\text{slope}(P_1,P_2)<2B_i\),根据代数推出的式子,我们知道这样会让 \(P_2\) 代表的决策点优于 \(P_1\),换句话说就是从 \(P_1\) 走到 \(P_2\) 会让答案(截距)更优,在坐标系中表示为从 \(P_1\) 走到 \(P_2\) 在目标直线向下的法线方向上移动了距离。图中表示为这样:
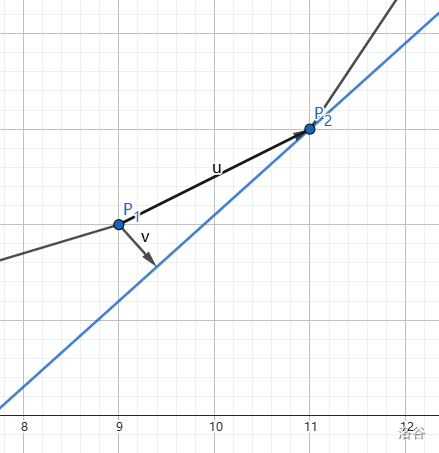
其中 \(\vec u\) 表示从 \(P_1\) 到 \(P_2\) 的位移,\(\vec v\) 表示目标直线在其法线方向上向下的位移。而 \(\vec v\) 又会带来与 \(y\) 轴交点的下移,最终使截距 \(b\) 最小,得到答案。因此一条线段斜率小于目标直线的斜率会让从它左端点到它右端点时使答案更优。
反之如果斜率小于目标直线斜率,就要从右端点到左端点才能更优了。
于是这样无论 \(b\) 是什么,可能的最优决策点就一定在下凸包中。
因此在斜率优化的时候可以把方程变成 \(b=y-kx\) 的形式,让 \(b\) 表示要最优化的值(一般是 \(f_i\) 和一些和 \(i\) 相关的常量),让 \(y\) 表示只和 \(j\) 相关的项,然后让 \(kx\) 来表示既有 \(i\) 又有 \(j\) 的项,变形成 \(f(i)\times g(j)\) 的形式。
:::info[\(\Theta(n\lg n)\) 的代码]
#include <iostream>
#define int long long
using namespace std;
using pii = pair<int, int>; // 充当点用
double slope(pii a, pii b) { // 计算斜率
// 因为题目保证了 B_i-B_j>=2,所以不用考虑两个点横坐标相等的情况
// 在其它题里面可能需要特判这种情况
// 然后根据纵坐标的大小关系返回 +oo 或 -oo
return 1. * (b.second - a.second) / (b.first - a.first);
}
constexpr int N = 5e4 + 10;
constexpr double EPS = 1e-6;
pii q[N];
int n, L, b[N], f[N], tail;
signed main() {
ios::sync_with_stdio(false);
cin >> n >> L; L++; // 计算 L'
for (int i = 1; i <= n; i++) {
cin >> b[i];
b[i] += b[i - 1];
}
for (int i = 1; i <= n; i++) b[i] += i;
q[tail++] = {0, 0}; // 把基本情况 f_0=0 放进去
for (int i = 1; i <= n; i++) {
// 二分最优决策点
// 最优决策点就是和前面的点的斜率小于等于 2 * b[i] 的最靠右的点
int l = 0, r = tail - 1;
while (l < r) {
int mid = (l + r + 1) >> 1;
// 注意特判第一个点
if (mid == 0 || slope(q[mid - 1], q[mid]) - EPS <= 2. * b[i]) l = mid;
else r = mid - 1;
}
// 根据上面说的计算 f[i]
f[i] = q[l].second - 2 * b[i] * q[l].first + (b[i] - L) * (b[i] - L);
pii p = {b[i], f[i] + b[i] * b[i] + 2 * L * b[i]};
// 维护下凸包
while (tail >= 2 && slope(q[tail - 2], q[tail - 1]) > slope(q[tail - 1], p)) tail--;
q[tail++] = p;
}
cout << f[n] << endl;
return 0;
}
:::
9.4 决策单调性优化
让我们再观察一下题目,我们发现 \(B_i\) 是单调增加的,那么 \(2B_i\) 也是单调增加的。
对于每次的最优决策点 \(j\) 来说,因为 \(\text{slope}(P_{j-1},P_j)<2B_i\),所以随着 \(2B_i\) 的单调增加,又因为我们维护的是下凸包,斜率单调上升,所以这意味着最优决策点可能往右移动;因为 \(\text{slope}(P_j,P_{j+1})>2B_i\),所以随着 \(B_i\) 的单调增加,又因为下凸包斜率单调上升,所以最优决策点可能需要右移来保证这条性质的成立。
感性理解一下,随着 \(i\) 的增加,\(B_i\) 单调增加,于是最优决策点 \(j\) 也随之要么不动要么往右边移动。这就是所谓的决策单调性,即每次更新 \(f_i\) 的最优决策点是在单调往右边移动的(也可能不移动)。
更严谨的证明需要四边形不等式,太过于复杂,这里就不展开了。
总之,在证明了这道题的决策单调性后,可以发现如果一个决策点在当前的最优决策点的左边,那么它永远也不可能成为之后决策中的最优决策点。那么我们根本没有必要维护最优决策点前斜率小于等于 \(2B_i\) 的所有决策,可以直接把这一部分全部抛弃掉,并永远也不会使用它。
于是可以用单调队列维护它,我们要保证现在在队列中的点中第一个点就是最优决策点,并且每两个点之间的斜率随着点的编号增加单调增加,即在下凸包中新加进来一个队首为最优决策点的条件。
这样我们就不必进行二分查找了,复杂度从 \(\Theta(n\lg n)\) 优化到了 \(\Theta(n)\)。
放一下 \(\Theta(n)\) 的代码(我使用的队列是用 head 指向队列头元素,tail 指向队列末元素的下一个位置,所以初始化时 head=tail=0,可以选择自己认为合适的队列写法):
:::info[\(\Theta(n)\) 的代码]
#include <iostream>
#define int long long
using namespace std;
using pii = pair<int, int>; // 充当点用
constexpr int N = 5e4 + 10;
constexpr double EPS = 1e-6;
pii q[N];
int n, L, b[N], f[N], head, tail; // 因为是队列,所以有 head 也有 tail
// 计算斜率,和 O(n lg n) 的一样
double slope(pii a, pii b) {
return 1. * (b.second - a.second) / (b.first - a.first);
}
signed main() {
ios::sync_with_stdio(false);
cin >> n >> L; L++; // 计算 L'
for (int i = 1; i <= n; i++) {
cin >> b[i];
b[i] += b[i - 1];
}
for (int i = 1; i <= n; i++) b[i] += i;
head = tail = f[0] = 0;
q[tail++] = {0, 0};
for (int i = 1; i <= n; i++) {
// 最重要的一行
// 保证 q[head] 就是最优决策点
while (tail - head >= 2 && slope(q[head], q[head + 1]) - EPS <= 2 * b[i]) head++;
f[i] = q[head].second - 2 * b[i] * q[head].first + (b[i] - L) * (b[i] - L);
pii p = {b[i], f[i] + b[i] * b[i] + 2 * L * b[i]};
// 维护下凸包
while (tail - head >= 2 && slope(q[tail - 2], q[tail - 1]) > slope(q[tail - 1], p)) tail--;
q[tail++] = p;
}
cout << f[n] << endl;
return 0;
}
:::
总结一下,斜率优化可以优化动态规划转移方程中有既有决策点 \(j\) 又有当前更新点 \(i\) 的问题,然后用二分或者数据结构来维护凸包。如果转移方程还有决策单调性就更好了,可以进一步使用决策单调性优化甚至优化到线性复杂度。
在做斜率优化题的时候有一些需要注意的点:
- 要确定好是维护上凸包还是下凸包再做题,不然全是水的样例过了交上去就炸了。
- 在计算斜率的时候如果题目没有特殊性要记得特判 \(+\infty\) 和 \(-\infty\),具体选哪一个建议判断纵坐标的大小关系,避免通过凸包的方向来判断导致坠机。
- 在一些卡精度的题
slope函数可以用long double卡精度,然后EPS也相应取小一点。但是都不如变除为乘(下面会讲)。 - 不要盲目使用单调队列,使用单调队列的前提是具有决策单调性,即目标直线的斜率要有单调性悲惨经历,要确认自己确实感性理解到了或干脆直接用四边形不等式证。
9.5 斜率优化的一些变式
9.5.1 每次插入的点的横坐标单调,目标直线斜率不单调
如果直线斜率 \(k\) 不单调,那么就不能保证决策的单调性,就需要维护整个凸包,然后在上面二分答案。
9.5.2 每次插入的点横坐标和目标直线的斜率都不单调
这样直线的斜率就可能出现负数,但是分情况讨论的话最终还是会发现目标直线的 \(k\) 和两点间斜率的大小关系和在这两点间转移时的优劣关系。
如果插入的点横坐标不单调的话,单调队列就根本无法维护凸包了,这个时候只能用其它的数据结构来维护,例如说是平衡树。或者也可以用 CDQ 分治离线处理,这个后面会讲。
9.5.3 每次插入的点的横坐标不单调,目标直线斜率单调
和上面一种情况一样,也可以用平衡树维护,如果使用 CDQ 的话还可以少维护一维。
具体来说,和下面的玩具装箱改相比,我们不再需要用二分查询了,直接单调队列就可以(可以做到 \(n\lg n\))。
例题选讲
1.玩具装箱改
题目链接(完全不保证不保证完全没有锅)
这道题中唯一实质上变了的就是玩具的长度——可以是负的,转移方程并没有改变,于是还按照玩具装箱的处理方式,但这一次 \(B_i\) 并不是单调增加的了,因此目标直线的斜率也不是单调增加的了,这符合变式中的第二种情况。
让我们再来分析一下这个 dp 方程
抽象为
那么对于两个 \(j_1\) 和 \(j_2\),若满足 \(x_{j_1}<x_{j_2}\),且 \(j_2\) 比 \(j_1\) 要优,有
也就是说,即使可能 \(j_1>j_2\) 但 \(x_{j_1}<x_{j_2}\),但当我们按 \(x_j\) 而不是 \(j\) 排序时,斜率优化的结论仍然存在。
(计算斜率的时候注意特判横坐标相等的情况)
那么我们最终仍然是要维护一个下凸包,因为决策单调性的消失,我们只能使用二分;但更大的问题是我们完全无法使用无头单调队列(单调栈)来维护它了。动态维护凸包一般使用平衡树,但如果只是为了 dp 的话可以使用 CDQ。
平衡树做法
在平衡树中以 \(x\) 坐标为下标把凸包上的点存进去。在我们插入一个点的时候,可以二分需要删的点的极限位置,也可以暴力找出它的前驱和后继删除。因为每个点最多被加入和删除一次,所以总时间复杂度是 \(O(n\lg n)\) 的。查询最优决策点事实上就是找第一个斜率大于目标函数斜率的线段的左端点,所以可以再开一个平衡树来存线段。这种方法可以直接用 set 实现,就不需要手写了。
这个事实上就是计算几何中标准的计算凸包的方法,但是太复杂了,而且我不会,所以不给代码了。
CDQ分治做法
不难发现每个 \(f_i\) 都需要前面的 \(j\) 来更新,并且另一个限制是需要有序地插入单调队列,这就像是一个二维偏序,因此可以用 CDQ 分治来做。具体做法和 CDQ 分治优化 1D/1D 动态规划(TATT)差不多,就是先计算左边的 dp 值,然后用左边的更新右边的,再计算右边的 dp 值。
:::warning[浮点数的精度误差]
因为无论如何浮点数都有误差,因此我们很有可能因为数据太大而挂掉,于是我们就可以省去计算斜率的这一步,直接计算两条直线斜率的大小关系。这可以用向量叉积来做,也可以简单地两边同乘变为乘法(但是会爆 long long,得开 __int128)。注意还有一大堆特判就是了。
// Pos={__int128,__int128}
// 比较直线 a (过 a1 和 a2) 的斜率 k1 和直线 b (过 b1 和 b2) 的斜率 k2
// 相等返回 0,k1<k2 返回 -1,k1>k2 返回 1
int comp(const Pos& a1, const Pos& a2, const Pos& b1, const Pos& b2) {
if (a1.x == a2.x) { // 直线 a 垂直于 x 轴
if (b1.x == b2.x) { // 直线 b 垂直于 x 轴
// k1=-oo,k2=+oo
if (a1.y > a2.y && b1.y < b2.y) return -1;
// k1=+oo,k2=-oo
else if (a1.y < a2.y && b1.y > b2.y) return 1;
// k1=k2=+oo/-oo
return 0;
} else { // 直线 b 不垂直于 x 轴
if (a1.y > a2.y) return -1; // k1=-oo<k2
return 1; // k1=+oo<k2
}
} else if (b1.x == b2.x) { // 直线 a 不垂直于 x 轴而直线 b 垂直
// 和上面差不多
if (b1.y > b2.y) return -1;
return 1;
}
// 判断斜率相等
if (((a2.x - a1.x) * (b2.y - b1.y) == (a2.y - a1.y) * (b2.x - b1.x))) return 0;
// 注意不等式同乘一个数时要记得观察是否需要变方向
if (((a2.x - a1.x) * (b2.y - b1.y) > (a2.y - a1.y) * (b2.x - b1.x)) ^ ((a1.x < a2.x) ^ (b1.x < b2.x))) return -1;
return 1;
}
:::
:::info[完整代码]
#include <algorithm>
#include <iostream>
#define int __int128 // 防爆 long long
char wbuf[(1 << 21) + 1], *p3 = wbuf;
#define flush (fwrite(wbuf, 1, p3 - wbuf, stdout), p3 = wbuf)
#define putchar(__x__) (p3 == wbuf + (1 << 21) ? flush : p3, (*p3++) = (__x__))
#define endl putchar('\n')
#define space putchar(' ')
void write(int x) {
static int stk[100], top;
if (!x) return void(putchar('0'));
if (x < 0) putchar('-'), x = -x;
top = 0;
while (x) stk[++top] = x % 10, x /= 10;
while (top) putchar(stk[top--] + '0');
}
void write(const char* str) {
for (int i = 0; str[i]; i++) putchar(str[i]);
}
char buf[1 << 21], *p1, *p2;
#define getchar() (p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 1 << 21, stdin), p1 == p2) ? EOF : *p1++)
int read() {
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9') f = (ch == '-' ? -1 : f), ch = getchar();
while (ch >= '0' && ch <= '9') x = (x << 1) + (x << 3) + (ch ^ 48), ch = getchar();
return x * f;
}
using namespace std;
constexpr int N = 2e5 + 10;
struct Pos {
int x, y;
};
// 斜率比较
int comp(const Pos& a1, const Pos& a2, const Pos& b1, const Pos& b2) {
if (a1.x == a2.x) {
if (b1.x == b2.x) {
if (a1.y > a2.y && b1.y < b2.y) return -1;
else if (a1.y < a2.y && b1.y > b2.y) return 1;
return 0;
} else {
if (a1.y > a2.y) return -1;
return 1;
}
} else if (b1.x == b2.x) {
if (b1.y > b2.y) return -1;
return 1;
}
if (((a2.x - a1.x) * (b2.y - b1.y) == (a2.y - a1.y) * (b2.x - b1.x))) return 0;
if (((a2.x - a1.x) * (b2.y - b1.y) > (a2.y - a1.y) * (b2.x - b1.x)) ^ ((a1.x < a2.x) ^ (b1.x < b2.x))) return -1;
return 1;
}
Pos q[N]; // 无头单调队列,貌似就是单调栈了
int n, L, b[N], f[N], id[N], tail;
void cdq(int l, int r) {
if (l == r) return;
int mid = (l + r) >> 1;
cdq(l, mid); // 先处理左边的
// 把两边分别按 x 坐标 (B) 排序
sort(id + l, id + mid + 1, [&](int i, int j) { return b[i] < b[j]; });
sort(id + mid + 1, id + r + 1, [&](int i, int j) { return b[i] < b[j]; });
// 把 [l,mid] 全部扔进单调队列
tail = 0;
for (int i = l; i <= mid; i++) {
Pos p = {b[id[i]], f[id[i]] + b[id[i]] * b[id[i]] + 2 * L * b[id[i]]};
while (tail >= 2 && comp(q[tail - 1], q[tail], q[tail], p) != -1) tail--;
q[++tail] = p;
}
for (int i = mid + 1; i <= r; i++) {
// 二分答案
int ll = 1, rr = tail;
while (ll < rr) {
int mid = (ll + rr + 1) >> 1;
if (mid == 1 || comp(q[mid - 1], q[mid], {0, 0}, {1, 2 * b[id[i]]}) != 1) ll = mid;
else rr = mid - 1;
}
f[id[i]] = min(f[id[i]], q[ll].y - 2 * b[id[i]] * q[ll].x + (b[id[i]] - L) * (b[id[i]] - L));
}
// 恢复原状
for (int i = l; i <= r; i++) id[i] = i;
// 继续处理右边的
cdq(mid + 1, r);
}
signed main() {
n = read(), L = read(); ++L; // 计算 L'
for (int i = 1; i <= n; i++) b[i] = b[i - 1] + read();
for (int i = 1; i <= n; i++) b[i] += i;
for (int i = 0; i <= n; i++) id[i] = i;
// 答案不会爆 long long,只是运算过程可能会炸
for (int i = 1; i <= n; i++) f[i] = 0x7fffffffffffffffll;
cdq(0, n); // 注意 f[0] 会对后面的产生更新
write(f[n]), endl;
flush;
return 0;
}
:::
2.任务安排
让我们先试着列出状态和转移方程。首先很明显设 \(f_i\) 表示完成前 \(i\) 项任务所需的最小总费用。设
但是这里有一个不好解决的问题就是每批任务开始前都需要 \(s\) 的时间来初始化机器,在后面的计算中还得加上,这样就会让我们再开一维。但是这 \(s\) 的时间带来的额外费用我们是可以提前计算的。具体细节看下面的转移方程:
我们把这 \(s\) 的启动时间的贡献提前到每次任务中计算。这种优化还是算比较常见的。
很明显这个式子不能单调队列或者单调栈,直接上斜率优化。我们尝试把它化简为 \(b=y-kx\) 的形式,满足 \(b,k\) 只与 \(i\) 有关,\(y,x\) 只与 \(j\) 有关:
令
则有
观察单调性。因为题目中 \(T_i\) 可能为负,所以 \(t_i\),即目标函数斜率,不具有单调性;而 \(C_i\ge0\),所以 \(c_i\) 单调不降,即决策点对应的二维平面上的点的横坐标 \(x\) 单调不降。符合变式中的第一个,所以维护单调队列,在单调队列上二分即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号