
OO_Unit1_Summary
架构综述
... 如游巨浸,前临渺茫,浮游波际,游泳既已,神质悉移。而彼之大海,实仅波起涛飞,绝无情愫,未始以一教训一格言相授。顾游者之元气体力,则为之陡增也。 ——鲁迅
OO第一单元的代码作业于这一周已经落下帷幕,我想先在文章的开头谈谈这一单元的架构设计体验。开头迅哥儿的话生动地描述了我做作业的真实反应——三次作业中,对我而言困难最大的反而是第一次,那种对着指导书坐大牢的感觉正如前言中所描述的那样,“前临渺茫”。但好在周四实验课的实验代码救了我一命,从那次的代码出发,我确定了递归下降为作业的基本实验思路,并且像很多同学想到的那样,自然而然地将多项式(Polynomial)作为一个原子多项式的HashMap来进行托管,计算与化简的过程,就是不断地对程序入口类MainClass中构造的那一个多项式对象进行原子成员的更新,仅此而已。

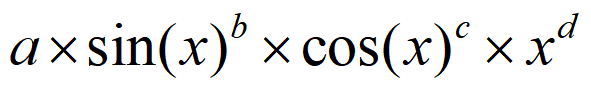
!--两张图分别为第一次作业和后两次作业的原子多项式的模板结构--
因为采用了递归下降思路,事实上第一次作业的代码就已经天然足以处理第三次作业的括号嵌套问题,并且处理速度尚可,被饲以大数据时也不至于出现互测时于别人代码中见到的超时情况。若想要再处理更深层次的化简(比如三角函数内的嵌套表达式,事实上,最后一次作业证明这个猜想是正确的)只需要将有效括号包裹的表达式提取出来,作为一个新的待处理表达式,调用整个化简程序进行一次化简,再将结果代回去即可。因此,吴佬,yyds……
为了处理原子多项式,在三次作业中我都首先对输入表达式做了化简预处理,预处理能够实现以下功能:
- 去空白符、将
**替换为^等基础处理; - 化简处理所有的连续符号、表达式开头的符号以及数字前导零,并把类似
(-的结构替换为(0-,类似^+的结构替换为^等,精简符号,便于后续的计算;
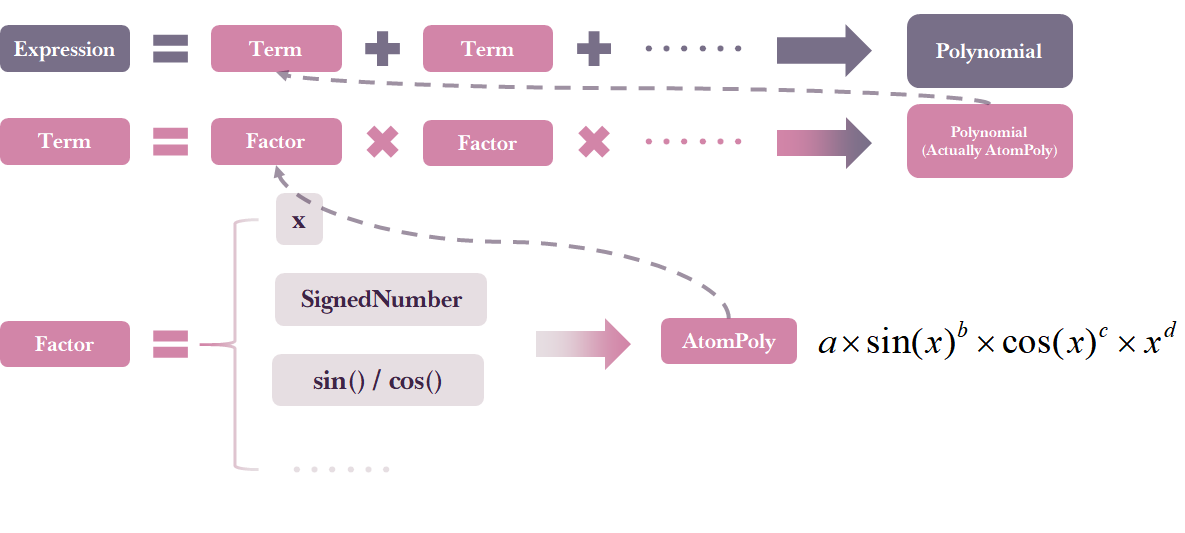
进行简单的预处理后,就是普通的递归下降处理表达式过程。递归下降的基本思路是:将表达式Expression(用+号链接,-号被当作原子表达式系数的符号而不是运算符考虑,已全被替换为+-)下降到Term(用*或^链接),Term再下降到Factor(据题意具体分析),而Factor则最终被解析为具体的原子(AtomPoly)。在最底层计算出原子的属性之后,这个原子会被层层向上返回运算,运算结束后,就通过一个toPoly()方法被加入到答案表达式(Polynomial)中,成为它的原子集合一员。
public class Parser {
//......
public Polynomial parseExpr() {
//operations...
return expr.toPoly();
}
public Polynomial parseTerm() {
//operations...
return term.toPoly();
}
public Polynomial parseFactor() {
//operations...
}
public AtomPoly parsePower(String atomSign) {
//operations...
return atom;
}
public AtomPoly parseNumber(String atomSign) {
//operations...
return atom;
}
}
不同的是,在第二和第三次作业中,由于自定义函数和求和函数等的加入,我增加了几个函数类以处理函数信息的保存和函数参数的代入等问题,这些步骤都发生在“预处理”的部分。并且,在函数类中,我会将函数调用处理后的表达式结果 / 三角函数有效括号内的表达式 先进行一次递归下降解析,再将返回的表达式化简结果代入到原表达式中,这样就可以处理多余括号以及表达式嵌套调用的问题。事实证明,这样的循环解析并不会影响程序运行的速度;而这样的思路,也极大地减少了第三次作业的工作量(或者说几乎没有工作量)。
//......extracted from Lexer......//
//---------------Substitute the function--------------------//
if (n > 0) {
inputProcessed = selfDefinedFunc.substitute(inputProcessed, selfDefinedFunc, n);
}
SumFunc sumFunc = new SumFunc();
inputProcessed = sumFunc.substitute(inputProcessed, selfDefinedFunc, n);
TriFunc triFunc = new TriFunc();
inputProcessed = triFunc.substitute(inputProcessed, selfDefinedFunc, n);
//---------------deal with the +- ---------------//
//......//
//......extracted from sumFunction......//
@Override
public String substitute(String input, SelfDefinedFunc selfDefinedFunc, int n) {
//operations...
//get ans
Lexer lexer = new Lexer(ans.toString(), selfDefinedFunc, n);
Polynomial expr = new Parser(lexer).parseExpr();
return "(" + expr.toString() + ")";
}
正式处理之外还有一个细节,就是第三次作业中Z同学在讨论区反映的不可变对象思想。这里不得不感谢IDEA的自动提醒和来自同学的讨论,正如助教所说,IDEA总是为了你好,基于它的建议,我基本上对三次作业都做了不可变对象处理,这样就避免了一些由于弱拷贝等产生的玄学问题(同时,我想到了C++课上提到的开闭原则)。说,谢谢IDEA。
总地来说,其实我对第一单元作业中自己的架构思路还是基本认可的,它在逻辑上尽量做到了面面俱到地负责。但是由于我自身的疏忽与线下种种旁事的耽搁影响,后两次作业中我严重缺少了全面的测试环节,导致没能及时发现其中的漏洞,补上一些由于低级手误导致的低级错误(修理所有的错误加起来都不用5行代码😅),使得它没能展现出自己真正的能力,是我辜负了它——这或许是一种现代语义上的“法本无过,循礼无邪”罢,应记之,改之。
Homework1.1
基于度量的程序结构分析
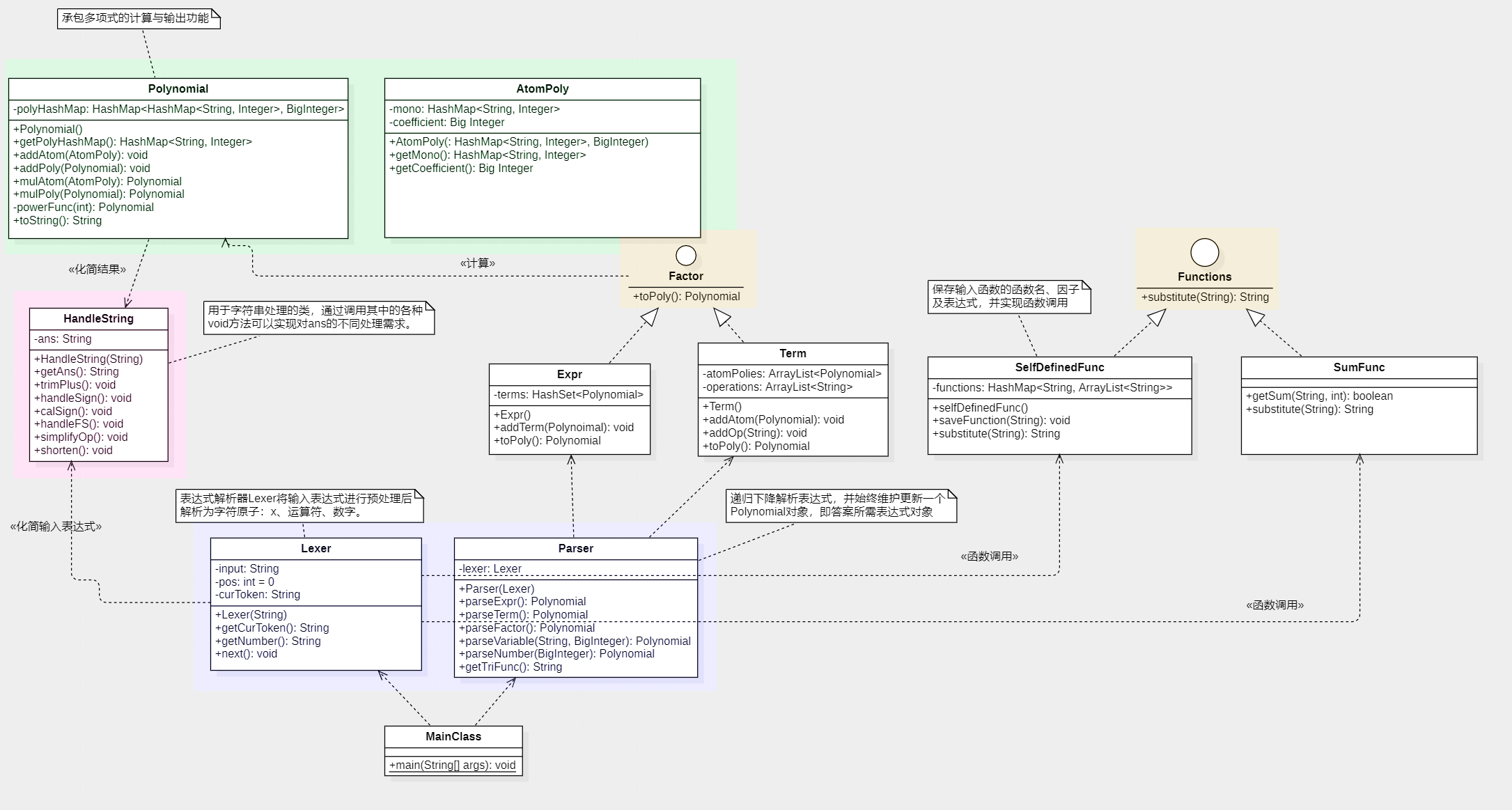
首先放上UML类图:(与原程序不完全相同)
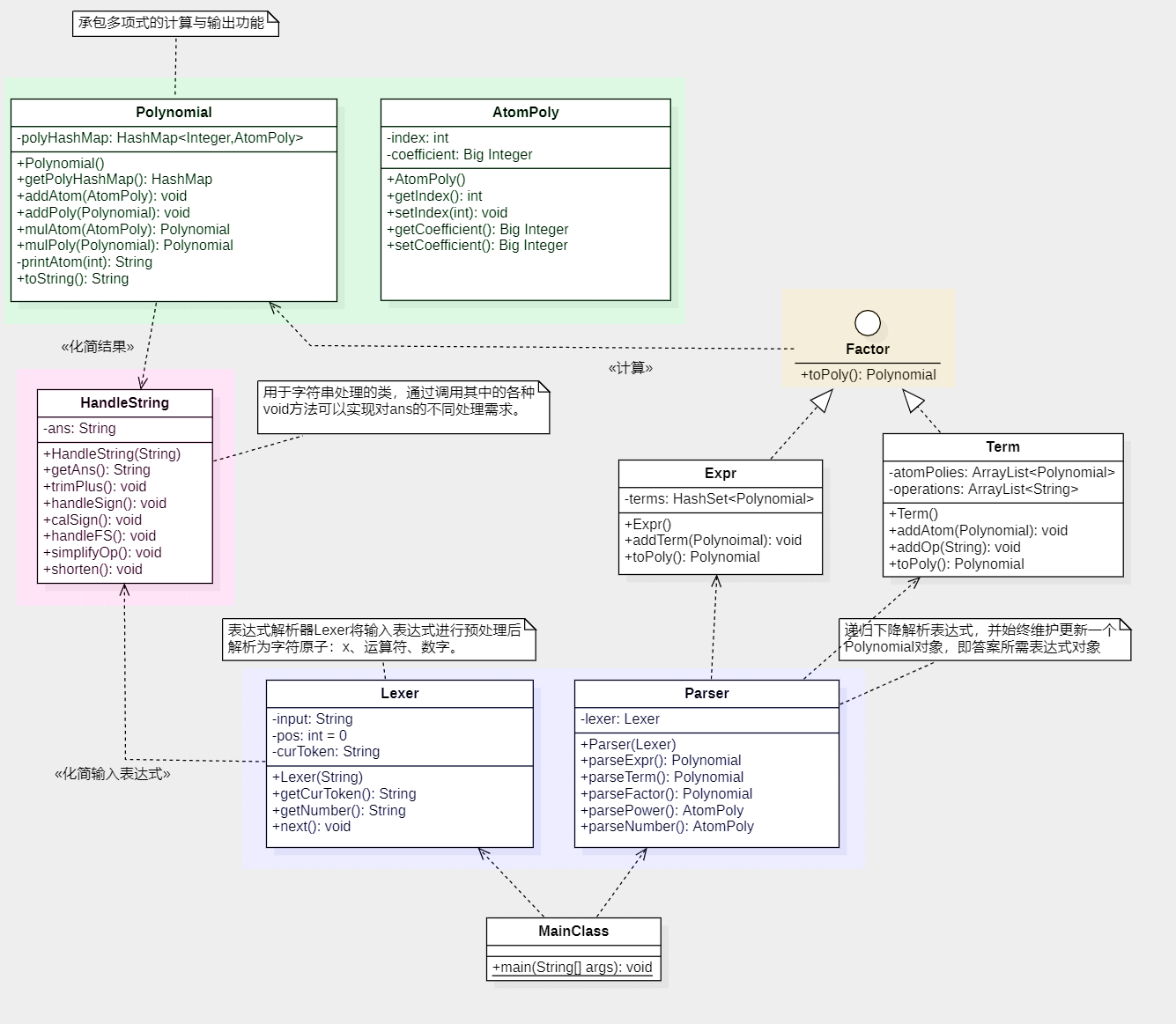
可以看到,第一次作业模仿实验课代码的痕迹很重,没有它给出递归下降的清晰思路,或许我根本无法完成这次作业。首先,在Lexer类中我们调用HandleString对输入表达式进行预处理化简,接着,Lexer类将输入表达式解析为原子结构,送入Parser类中进行递归计算,每一次解析计算,我都调用一次toPoly()方法将结果更新到一直维护着的答案表达式对象中。其中,Polynomial类掌管着多项式的计算与输出方法。最后,只需要调用答案表达式的toString()方法,就可以得到化简后的结果表达式了。
除了递归下降,另一个比较关键的思路就是原子表达式的概念了。在写出递归下降之前,我就想到了用原子表达式表示答案集合,结合类图可以发现,具体实现是使用AtomPoly表示一个原子表达式,然后在Polynomial类中为其赋予一个HashMap属性,以表示多项式就是原子表达式集合的这一观点——这样可以自然而然地处理表达式化简合并的问题,并且逻辑也很清晰。这两个关键思路我从第一次作业延用至第三次,收获很大。
代码中为了方便分类做了一些打包处理(后两次作业亦然),如下所示。
然后给出存储层次结构的复杂度如下:(安装了MetricsReloaded插件后,直接在项目里右键单击Analyze再选择Calculate Metrics即可召唤)
OCavg代表类的方法的平均循环复杂度,OCmax代表类的方法的最大循环复杂度,WMC代表类的总循环复杂度;
ev(G)即基本复杂度,用以衡量程序非结构化程度,基本复杂度高意味着非结构化程度高,难以模块化和维护;
iv(G)即模块设计复杂度,用以衡量模块判定结构,即模块和其他模块的调用关系;模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用;
v(G)即圈复杂度,用以衡量一个模块判定结构的复杂程度,根据程序从开始到结束的线性独立路径数量计算得到,圈复杂度越高,代码越复杂越难维护。
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| expression.AtomPoly.getCoefficient() | 0.0 | 1.0 | 1.0 | 1.0 |
| ...... | ||||
| expression.Polynomial.printAtom(int) | 15.0 | 1.0 | 8.0 | 8.0 |
| ...... | ||||
| handle.HandleString.handleSign() | 13.0 | 1.0 | 8.0 | 8.0 |
| handle.HandleString.HandleString(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| handle.HandleString.shorten() | 9.0 | 1.0 | 7.0 | 9.0 |
| ...... | ||||
| Parser.parseFactor() | 8.0 | 2.0 | 4.0 | 4.0 |
| ...... | ||||
| Total | 93.0 | 47.0 | 88.0 | 101.0 |
| Average | 2.268292682926829 | 1.146341463414634 | 2.1463414634146343 | 2.4634146341463414 |
可以看到,在打印结果等部分,由于特殊的化简需求导致控制流比较复杂,if-else连天飞舞(但托管于新方法似乎又显得太过于多此一举),复杂度明显高于其他方法,但总体水平尚在能够接受的范围之内。
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| expression.AtomPoly | 1.0 | 1.0 | 5.0 |
| expression.Expr | 1.6666666666666667 | 3.0 | 5.0 |
| expression.Polynomial | 2.5555555555555554 | 8.0 | 23.0 |
| expression.Term | 1.75 | 4.0 | 7.0 |
| handle.HandleString | 3.25 | 6.0 | 26.0 |
| Lexer | 1.6 | 3.0 | 8.0 |
| MainClass | 1.0 | 1.0 | 1.0 |
| Parser | 2.1666666666666665 | 4.0 | 13.0 |
| Total | 88.0 | ||
| Average | 2.1463414634146343 | 3.75 | 11.0 |
在类复杂度上也有一样的问题——用于打印或处理字符串的部分,过于臃肿。
基于bug情况的程序分析
本次在中测、强测及互测中均未被发现bug,但事实上,它在预处理字符串方面为后面的作业埋下了炸弹——不应该在Lexer类中进行去空白、换符号等预处理,而要把它放在MainClass中提前执行,使得整个处理流程中流转的都是已被处理过的正确格式。因为后面的作业存在递归调用化简程序的操作,一旦不这么做,就会导致一些没有被处理好的格式(比如一些式子没去空白)流入到化简程序中,造成报错。
互测中发现了1个bug,即有一位同学的代码不能处理连续0(比如000000),一试验即报错。
测试策略
本次的测试策略比较朴素,直接按照指导书中给出的格式递归生成测试样例,然后再使用sympy验证正确性。尤其感谢讨论区同学的无私分享。
博客写到这里,我不禁想:是不是因为第一次作业对我来说过于“硬核”,所以研究指导书时格外仔细,因此构造的测试数据才如此全面呢?后两次作业,因为感受到了递归下降思路的运行模式,再加上其余事情挤占了OO的学习时间,我在测试上下的功夫明显减弱了,阅读指导书时更出了许多纰漏,才导致测试的不全面与bug的产生。苏子有言:“言之于无事之时,足以为名,而恒苦于不信;言之于有事之时,足以见信,而已苦于无及。”如今回首,才感其言信哉。
Homework1.2
基于度量的程序结构分析
仍先放上UML类图:(与原程序不完全相同)
本次作业的要求在上一次的基础上加入了求和函数、三角函数和自定义函数,看似复杂,但它们不过是新的因子,与x可等量齐观。可以看到,与第一次作业的区别只是加入了Functions接口以及与其相关的两个函数类用于处理函数,还有Parser类中新增的用于捕获三角函数的getTriFunc()方法,最重要的是,更新了原子表达式的模板,在Polynomial类中以嵌套的HashMap来管理新的原子表达式(因为需要将三角函数字符串纳入考虑)。其他地方,基本未变。
这里好像说得我尝到了层次化设计的甜头,但事实上我深知它只是看起来徒有OOP之表(或者说也没有多少表),却没有得OOP之神——基于上一次作业改吧改吧的结果是没有很好地体现出老师在课上讲解的工厂模式等设计原则,似乎只是照猫画虎地抽取出了几个接口,就认为自己完成了存储层次的整理与分离。这一点做得不太好,希望在以后的实践中能够有所改变。
然后给出存储层次结构的复杂度如下:(安装了MetricsReloaded插件后,直接在项目里右键单击Analyze再选择Calculate Metrics即可召唤)
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| expression.AtomPoly.AtomPoly(HashMap, BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.AtomPoly.equals(Object) | 2.0 | 3.0 | 1.0 | 3.0 |
| ...... | ||||
| expression.Polynomial.toString() | 19.0 | 6.0 | 9.0 | 9.0 |
| ...... | ||||
| handle.HandleString.handleFS() | 3.0 | 1.0 | 3.0 | 4.0 |
| handle.HandleString.handleSign() | 13.0 | 1.0 | 8.0 | 8.0 |
| handle.HandleString.HandleString(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| handle.HandleString.matchBracket(int) | 10.0 | 3.0 | 6.0 | 7.0 |
| handle.HandleString.shorten() | 7.0 | 1.0 | 5.0 | 6.0 |
| ...... | ||||
| handle.SumFunc.substitute(String) | 25.0 | 2.0 | 7.0 | 8.0 |
| ...... | ||||
| Parser.parseFactor() | 22.0 | 4.0 | 9.0 | 9.0 |
| Parser.parseNumber(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| ...... | ||||
| Total | 183.0 | 72.0 | 132.0 | 148.0 |
| Average | 3.66 | 1.44 | 2.64 | 2.96 |
跟第一次作业几乎一样的问题——一涉及到字符串处理部分,控制流就开始变得极端复杂,但我尚未想到什么好的解决方法(难道真的只有托管新类这一个出路?),还望读者不吝赐教。
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| expression.AtomPoly | 1.2857142857142858 | 3.0 | 9.0 |
| expression.Expr | 1.6666666666666667 | 3.0 | 5.0 |
| expression.Polynomial | 3.5 | 8.0 | 28.0 |
| expression.Term | 1.75 | 4.0 | 7.0 |
| handle.HandleString | 3.2222222222222223 | 6.0 | 29.0 |
| handle.SelfDefinedFunc | 2.25 | 4.0 | 9.0 |
| handle.SumFunc | 5.0 | 8.0 | 10.0 |
| Lexer | 1.8 | 3.0 | 9.0 |
| MainClass | 2.0 | 2.0 | 2.0 |
| Parser | 3.0 | 8.0 | 21.0 |
| Total | 129.0 | ||
| Average | 2.58 | 4.9 | 12.9 |
在类复杂度上,分析工具也开始报警了,除表头外加粗的三个类无非是同一个问题——耦合度超高,严重违反了高内聚低耦合的设计原则,这一点直接从代码处也可以看出其臃肿——比如HandleString,为了图方便,我一股脑地把所有涉及字符串化简、替换的方法都塞在里面,而不管其用地。现在想来,其实亦有更简洁的分类方法,只好留待后续引以为戒了。
对比发现,导致出了bug的部分刚好就是圈复杂度过高的部分,这一点的启发性是很大的——代码复杂度大,理解性就低,因而更难维护或者说发现其中的缺陷(有的时候我们往往对自己的逻辑过于自信)。这种做法的可拓展性也很差,通俗地说,就是面向过程思想的恶果。
基于bug情况的程序分析
本次在强测中被发现1个bug:如Homework1.1的测试部分所言,上一次作业埋下的地雷终于爆炸了,自定义函数传入时,其中的空白符未能被正确处理,导致惨烈报错;
本次在互测中被发现1个bug:同样是上次作业的历史遗留bug,当时很方便的将(-处理为(0-引发了错误——因为三角函数中也含有括号。在这里我发现,把这个处理删了后对结果根本不会造成任何影响,因为parseFactor的时候我就已经提取了负号作为后面因子的系数符号了。
本次在互测中发现2个bug:
- 未能正确处理连续0,将
x**00处理为了0; - 未能正确处理三角函数内的有符号因子,将
sin(-1)**2处理为了-sin(-1)。
未能提交互测但从他人代码中发现的bug:喂入稍长数据,运行时长便严重超时甚至不出结果。使用通用的递归下降写法似乎不应该出现这样的问题,我疑心是“优化”或者某些循环体出错的缘故。
测试策略
在上次作业评测机的基础上丑陋地堆叠了两个函数部分(之所以说丑陋,是因为这是基于过于冗杂的字符串正则表达式构造而得的,而不是正常的按格式递归思路)。但由于阅读指导书时不仔细,再加上为了赶工(当时本小区正在组织转移隔离,加上物资匮乏,简直是一片兵荒马乱)偷工减料,构造出的测试数据是非常不完备的,因此没能检查出如此低级的bug,这样的我,纯度,太低了……

Homework1.3
基于度量的程序结构分析
仍先放上UML类图:(与原程序不完全相同)
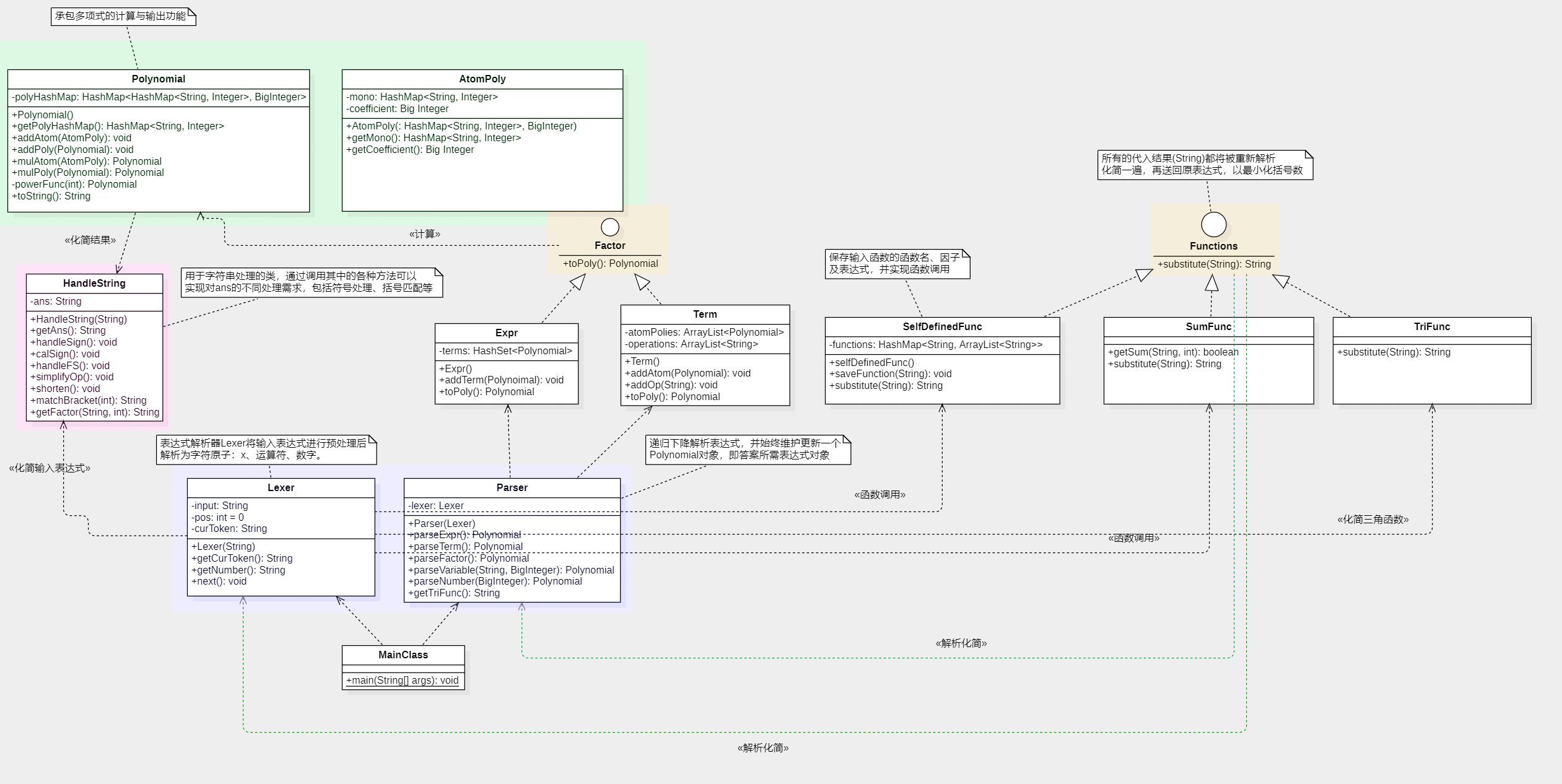

为了方便括号的化简加入了一个三角函数类处理三角函数有效括号内的内容化简问题,思路依然是递归调用化简程序。其他部分跟第二次作业没什么不同,功能也基本实现了,自定义函数、sum函数和三角函数的混合多层套用都基本没有问题。(呵呵,正是因为这种盲目自信,又埋下了一颗定时炸弹呀……)注意绿线反映的是递归化简的过程。
复杂度情况与Homework1.2几无不同,故不在此赘述。
基于bug情况的程序分析
本次强测被发现1个bug:在处理函数代入时,为了提取参数因子,我在HandleString类中创建了一个getFactor()方法以捕获因子,因为这个过程与parseFactor()中各个控制流的操作几乎一模一样,因此它就是一个parseFactor()的套皮——然而,这就导致了bug。套皮parseFactor()时,我没能发现原方法预先处理了有符号数的符号,因此这就是一个没法提取有符号数符号的方法,然后就导致了强测的出错。
本次互测被发现1个bug:处理sum函数的上下界时没用BigInteger存储的历史遗留问题,似乎也有挺多人犯了这个错误。
本次互测发现2个bug:
- 同本人的互测bug,不过是天涯沦落人罢了;
- sum函数上界大于下界时没有自动处理为0,没认真读指导书的锅。
未能提交互测但从他人代码中发现的bug:
- 递归调用自定义函数时,超过两层便报错;
- 一位同学不能处理sum套sum,自定义函数套sum或者更复杂的套用情况(数据来源为测评数据生成工具),基本上一试必报错。
测试策略
同第二次作业,再次痛之。这个单元给我的最大教训就是——一定要重视测试,一定要重视测试,一定要重视测试。
感悟
有关具体代码内容的部分,我已经顷数写在了文中,收获很大,教训也很惨痛。因此,这部分的心得体会更偏向于一个全局的视角。请注意,我的感悟可能是废话最多的。
如果没有实验课代码,我根本写不出这三次作业的基本架构;如果没有讨论区同学的倾囊相授,我也根本做不出一个勉强能用的测评工具。除了前面连篇累牍的对“测试”重要性的强调以外,我体会得最多的或许还是同学间互帮互助与分享的重要性。毕竟,之前在6系学习的我还是更倾向于单独完成课业问题。
写下这段话的时候,我已经被隔离37天了,独居一隅,面对新闻绝不会报道的一堵蓝墙和每天两位数的稳定新增,我无时无刻不在想念着鲜活的课堂和与好友的激烈讨论。第二次作业正火热时又恰逢小区集体转移隔离,在众人为了物资缺乏而争吵、为了解封无期而乱作一团时,我隔着隔离衣抱着还发热的电脑包,想到了《红笑》中的句段:
这世界犹如一颗被揭去皮肤的头颅,鲜红的大脑像血一样的稀粥,它在喊叫和狂笑,这是红色的笑。
但我最终没有感受到自己被放弃。不论是在讨论区的大方分享也好,在小群或者小窗的无私相助也罢,来自同学、助教的种种帮助都向我伸出了有力的手,助我度过学业与心理上的难关(即使,我做得还不够好)。感谢H给我提出了一次架构的改进建议:第一次作业时,由于原子表达式的结构过于简单,我并未在Term类中管理符号集合,而是直接将指数与变量合并处理,但第二次作业时这种做法就行不通了,我原本尝试提取新因子,再合并处理指数,但后来发现不如H同学建议的管理符号集合好,历史也证明了他是正确的;感谢J、Y1、C和助教为我更新课堂动态、解答小疑难(比如递归下降的理解问题),也感谢来自他们的心理安慰;感谢Y2和X的测试数据分享;更感谢整个讨论区里的“百家争鸣”,让我在没有思路时豁然开朗(尤其是第一次作业)。
最后回看这份经历,其中也还有许多不足,除了测试的教训外,还比如处理字符串的控制流过于复杂(bug也出在它们之中),应拆解为更细的类或者用其他更好的方法处理,增强程序的可扩展性和鲁棒性,发挥面向对象的真正优势;没有很好地反映高内聚低耦合的理念,在一些部分,仍然过于面向对象;想尝试理解一些同学构建AST树的思路;如何高效构建测评机……等等。还有一点是,我们似乎过分把高光放在递归下降上了(一些同学形容的“编译味儿太重”),但也许第一单元的真正意图是让我们领略一个好的面向对象的架构在管理复杂工程上的重要性,并实践工厂类、抽象类、接口类等机制的使用,而非照猫画虎,骨子里依旧面向过程。
我不胜感激,即使我做得还不够好。第二单元,请多指教吧:)

