
手写数字识别的k-近邻算法实现
(本文为原创,请勿在未经允许的情况下转载)
前言
手写字符识别是机器学习的入门问题,k-近邻算法(kNN算法)是机器学习的入门算法。本文将介绍k-近邻算法的原理、手写字符识别问题分析、手写字符识别的kNN实现、测试。
kNN算法原理
kNN算法是一种分类算法,即如何判定一组输入数据属于哪一类别的算法。kNN属于监督学习算法,必须给定训练样本,样本包括输入样本和输出样本。而无监督学习则不需要训练样本。
那么最简单的分类方法就是将输入数据与样本一一比对,并将相似性最强的前k个样本选出,这k个样本中的大多数属于哪一类别,则判定输入数据属于该类别。
从图形上看,就是找出了样本空间中与输入数据最近的k个数据,这些数据中的大多数属于哪个类别,则输入数据也属于该类别。(当然,这是算法的原理,从逻辑上看问题不大,但是这个输入数据是否应该和它的k个近邻属于同一类却是不得而知的,但作为一个入门算法不考虑这种情况。)
手写数字识别分析
- 图像预处理:二值化、分割、统一标记。将这一过程成为预处理,是因为这一过程并不属于kNN算法的内容。
![]()
![]()
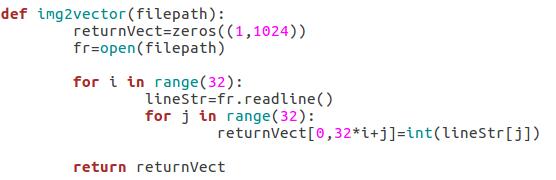
图1 样本输入(手写体“4”和“5”) - 输入数据格式化:由于是使用欧氏距离来寻找k-近邻的,因此最好将输入的图像转换为一个向量,以便于计算输入数据与样本数据的距离。
- 寻找k-近邻:核心过程。计算欧氏距离并排序,取排前k的训练样本。
- 分类决策:前k个训练样本中的标签统计,出现次数最多的标签即为结果。


算法实现
- 图像预处理:使用MATLAB对图像进行处理,不属于算法本身。
- 输入数据格式化:对于已做好标记的图片,输入之后将矩阵转换为向量。
![]()
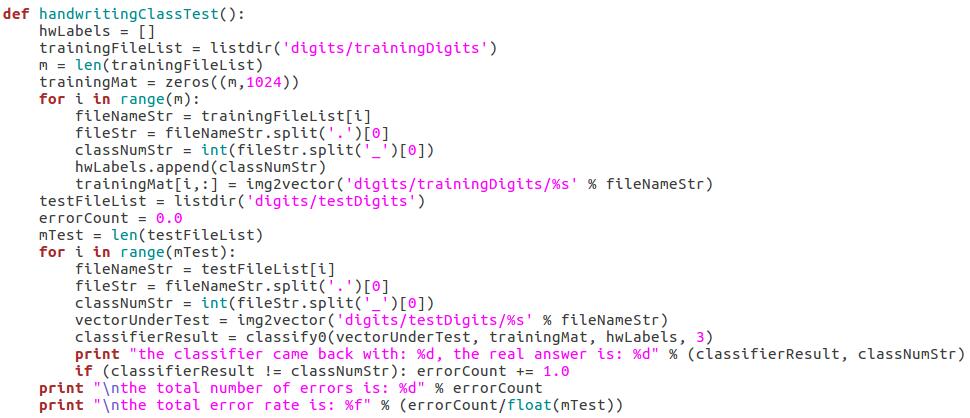
- 寻找k-近邻:
![]()
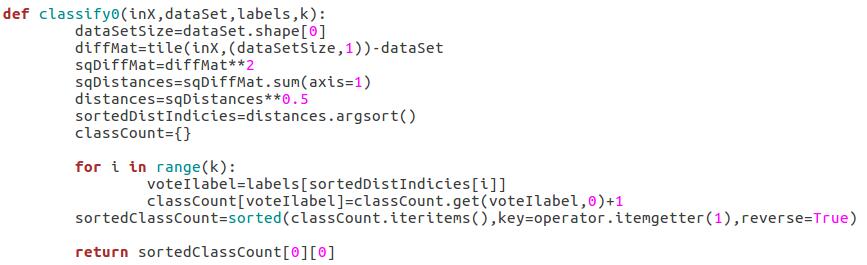
- 分类决策:
![]()
测试
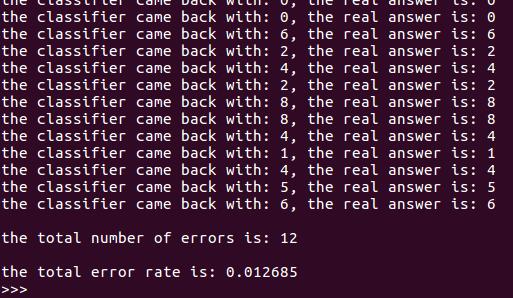
上图展示了程序运行结果,在测试时共产生了12个错误输出,错误率为1.27%。
结语
kNN算法是种简单、有效的算法,但是该算法必须保存训练数据集,如果训练数据集很大,则会占用很多存储空间。算法的时间复杂度和空间复杂度都并不令人满意,因此简单有效的算法往往会牺牲效率,程序员的自我牺牲换来高效的算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号