Rancher中基于Kubernetes的CRD实现
前言
2017年Kubernetes在容器编排领域一统江湖,伴随着Kubernetes的发展壮大,及其CNCF基金会的生态发展,对整个云计算领域的发展必将产生深远的影响。有了Kubernetes的强力加持,云计算中长期不被看好和重视的PAAS层,也正逐渐发挥威力。很多厂商开始基于Kubernetes开发自己的PAAS平台,这其中感觉比较有代表性的有Openshift和Rancher。本文主要针对Rancher进行介绍和相应的源码分析,了解和学习Rancher是如何基于Kubernetes进行PAAS平台的开发。
在Rancher的1.x.x版本中,主打自家的cattle容器编排引擎,同时还支持kubernetes、mesos和swarm,而到了如今的2.0.0-beta版,则只剩下了kubernetes,可以说是顺应时势。Kubernetes在1.7版本后增加了CustomResourceDefinition(CRD),即用户自定义资源类型,使得开发人员可以不修改Kubernetes的原有代码,而是通过扩展形式,来管理自定义资源对象。Rancher 2.0版本正是利用这一特性,来完成对Kubernetes的扩展及业务逻辑的实现。
代码分析
接下来分析代码,Rancher在2.0版本应用golang进行开发,首先从main.go开始。main.go中主要是应用"github.com/urfave/cli"创建一个cli应用,然后运行run()方法:
func run(cfg app.Config) error { dump.GoroutineDumpOn(syscall.SIGUSR1, syscall.SIGILL) ctx := signal.SigTermCancelContext(context.Background()) embedded, ctx, kubeConfig, err := k8s.GetConfig(ctx, cfg.K8sMode, cfg.KubeConfig) if err != nil { return err } cfg.Embedded = embedded os.Unsetenv("KUBECONFIG") kubeConfig.Timeout = 30 * time.Second return app.Run(ctx, *kubeConfig, &cfg) }
在run()方法中,会创建一个內建的kubernetes集群(这部分内容不在文中进行具体分析),创建这个集群需要先生成一个plan,定义了集群运行在哪些节点,启动哪些进程,应用哪些参数等,在代码中对plan进行打印输出如下:
nodes: - address: 127.0.0.1 processes: etcd: name: etcd command: [] args: - /usr/local/bin/etcd - --peer-client-cert-auth - --client-cert-auth - --data-dir=/var/lib/rancher/etcd - --initial-cluster-token=etcd-cluster-1 - --advertise-client-urls=https://127.0.0.1:2379,https://127.0.0.1:4001 - --initial-cluster-state=new - --peer-trusted-ca-file=/etc/kubernetes/ssl/kube-ca.pem - --name=etcd-master - --peer-cert-file=/etc/kubernetes/ssl/kube-etcd-127-0-0-1.pem - --peer-key-file=/etc/kubernetes/ssl/kube-etcd-127-0-0-1-key.pem - --listen-client-urls=https://0.0.0.0:2379 - --initial-advertise-peer-urls=https://127.0.0.1:2380 - --trusted-ca-file=/etc/kubernetes/ssl/kube-ca.pem - --cert-file=/etc/kubernetes/ssl/kube-etcd-127-0-0-1.pem - --key-file=/etc/kubernetes/ssl/kube-etcd-127-0-0-1-key.pem - --listen-peer-urls=https://0.0.0.0:2380 - --initial-cluster=etcd-master=https://127.0.0.1:2380 env: [] image: rancher/coreos-etcd:v3.0.17 imageregistryauthconfig: "" volumesfrom: [] binds: - /var/lib/etcd:/var/lib/rancher/etcd:z - /etc/kubernetes:/etc/kubernetes:z networkmode: host restartpolicy: always pidmode: "" privileged: false healthcheck: url: https://127.0.0.1:2379/health kube-apiserver: name: kube-apiserver command: - /opt/rke/entrypoint.sh - kube-apiserver - --insecure-port=0 - --kubelet-client-key=/etc/kubernetes/ssl/kube-apiserver-key.pem - --insecure-bind-address=127.0.0.1 - --bind-address=127.0.0.1 - --secure-port=6443 - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname - --service-account-key-file=/etc/kubernetes/ssl/kube-apiserver-key.pem - --cloud-provider= - --service-cluster-ip-range=10.43.0.0/16 - --tls-cert-file=/etc/kubernetes/ssl/kube-apiserver.pem - --tls-private-key-file=/etc/kubernetes/ssl/kube-apiserver-key.pem - --kubelet-client-certificate=/etc/kubernetes/ssl/kube-apiserver.pem - --authorization-mode=Node,RBAC - --allow-privileged=true - --admission-control=ServiceAccount,NamespaceLifecycle,LimitRanger,PersistentVolumeLabel,DefaultStorageClass,ResourceQuota,DefaultTolerationSeconds - --storage-backend=etcd3 - --client-ca-file=/etc/kubernetes/ssl/kube-ca.pem - --advertise-address=10.43.0.1 args: - --etcd-cafile=/etc/kubernetes/ssl/kube-ca.pem - --etcd-certfile=/etc/kubernetes/ssl/kube-node.pem - --etcd-keyfile=/etc/kubernetes/ssl/kube-node-key.pem - --etcd-servers=https://127.0.0.1:2379 - --etcd-prefix=/registry env: [] image: rancher/server:dev imageregistryauthconfig: "" volumesfrom: - service-sidekick binds: - /etc/kubernetes:/etc/kubernetes:z networkmode: host restartpolicy: always pidmode: "" privileged: false healthcheck: url: https://localhost:6443/healthz kube-controller-manager: name: kube-controller-manager command: - /opt/rke/entrypoint.sh - kube-controller-manager - --allow-untagged-cloud=true - --v=2 - --allocate-node-cidrs=true - --kubeconfig=/etc/kubernetes/ssl/kubecfg-kube-controller-manager.yaml - --service-account-private-key-file=/etc/kubernetes/ssl/kube-apiserver-key.pem - --address=0.0.0.0 - --leader-elect=true - --cloud-provider= - --node-monitor-grace-period=40s - --pod-eviction-timeout=5m0s - --service-cluster-ip-range=10.43.0.0/16 - --root-ca-file=/etc/kubernetes/ssl/kube-ca.pem - --configure-cloud-routes=false - --enable-hostpath-provisioner=false - --cluster-cidr=10.42.0.0/16 args: - --use-service-account-credentials=true env: [] image: rancher/server:dev imageregistryauthconfig: "" volumesfrom: - service-sidekick binds: - /etc/kubernetes:/etc/kubernetes:z networkmode: host restartpolicy: always pidmode: "" privileged: false healthcheck: url: http://localhost:10252/healthz kube-proxy: name: kube-proxy command: - /opt/rke/entrypoint.sh - kube-proxy - --kubeconfig=/etc/kubernetes/ssl/kubecfg-kube-proxy.yaml - --v=2 - --healthz-bind-address=0.0.0.0 args: [] env: [] image: rancher/server:dev imageregistryauthconfig: "" volumesfrom: - service-sidekick binds: - /etc/kubernetes:/etc/kubernetes:z networkmode: host restartpolicy: always pidmode: host privileged: true healthcheck: url: http://localhost:10256/healthz kube-scheduler: name: kube-scheduler command: - /opt/rke/entrypoint.sh - kube-scheduler - --kubeconfig=/etc/kubernetes/ssl/kubecfg-kube-scheduler.yaml - --leader-elect=true - --v=2 - --address=0.0.0.0 args: [] env: [] image: rancher/server:dev imageregistryauthconfig: "" volumesfrom: - service-sidekick binds: - /etc/kubernetes:/etc/kubernetes:z networkmode: host restartpolicy: always pidmode: "" privileged: false healthcheck: url: http://localhost:10251/healthz kubelet: name: kubelet command: - /opt/rke/entrypoint.sh - kubelet - --address=0.0.0.0 - --cadvisor-port=0 - --enforce-node-allocatable= - --network-plugin=cni - --cluster-dns=10.43.0.10 - --kubeconfig=/etc/kubernetes/ssl/kubecfg-kube-node.yaml - --v=2 - --cni-conf-dir=/etc/cni/net.d - --resolv-conf=/etc/resolv.conf - --volume-plugin-dir=/var/lib/kubelet/volumeplugins - --read-only-port=0 - --cni-bin-dir=/opt/cni/bin - --allow-privileged=true - --pod-infra-container-image=rancher/pause-amd64:3.0 - --client-ca-file=/etc/kubernetes/ssl/kube-ca.pem - --fail-swap-on=false - --cgroups-per-qos=True - --anonymous-auth=false - --cluster-domain=cluster.local - --hostname-override=master - --cloud-provider= args: [] env: [] image: rancher/server:dev imageregistryauthconfig: "" volumesfrom: - service-sidekick binds: - /etc/kubernetes:/etc/kubernetes:z - /etc/cni:/etc/cni:ro,z - /opt/cni:/opt/cni:ro,z - /var/lib/cni:/var/lib/cni:z - /etc/resolv.conf:/etc/resolv.conf - /sys:/sys:rprivate - /var/lib/docker:/var/lib/docker:rw,rprivate,z - /var/lib/kubelet:/var/lib/kubelet:shared,z - /var/run:/var/run:rw,rprivate - /run:/run:rprivate - /etc/ceph:/etc/ceph - /dev:/host/dev:rprivate - /var/log/containers:/var/log/containers:z - /var/log/pods:/var/log/pods:z networkmode: host restartpolicy: always pidmode: host privileged: true healthcheck: url: https://localhost:10250/healthz service-sidekick: name: service-sidekick command: [] args: [] env: [] image: rancher/rke-service-sidekick:v0.1.2 imageregistryauthconfig: "" volumesfrom: [] binds: [] networkmode: none restartpolicy: "" pidmode: "" privileged: false healthcheck: url: "" portchecks: - address: 127.0.0.1 port: 10250 protocol: TCP - address: 127.0.0.1 port: 6443 protocol: TCP - address: 127.0.0.1 port: 2379 protocol: TCP - address: 127.0.0.1 port: 2380 protocol: TCP files: - name: /etc/kubernetes/cloud-config.json contents: "" annotations: rke.io/external-ip: 127.0.0.1 rke.io/internal-ip: 127.0.0.1 labels: node-role.kubernetes.io/controlplane: "true" node-role.kubernetes.io/etcd: "true"
创建好这个內建的kubernetes集群后,就要进行app.Run()方法了,也就是真正启动rancher server了,这里只关注CRD资源的创建和使用。先看一下都有哪些自定义资源,首先需要有访问集群的config文件,这个文件位于rancher源代码路径下,即github.com/rancher/rancher/kube_config_cluster.yml文件,有了这个文件就可以通过kubectl访问集群获取相应信息,内容如下:
[root@localhost rancher]# kubectl get crd NAME AGE apps.project.cattle.io 34d authconfigs.management.cattle.io 34d catalogs.management.cattle.io 34d clusteralerts.management.cattle.io 34d clustercomposeconfigs.management.cattle.io 34d clusterevents.management.cattle.io 34d clusterloggings.management.cattle.io 34d clusterpipelines.management.cattle.io 34d clusterregistrationtokens.management.cattle.io 34d clusterroletemplatebindings.management.cattle.io 34d clusters.management.cattle.io 34d dynamicschemas.management.cattle.io 34d globalcomposeconfigs.management.cattle.io 34d globalrolebindings.management.cattle.io 34d globalroles.management.cattle.io 34d groupmembers.management.cattle.io 34d groups.management.cattle.io 34d listenconfigs.management.cattle.io 34d namespacecomposeconfigs.project.cattle.io 34d nodedrivers.management.cattle.io 34d nodepools.management.cattle.io 34d nodes.management.cattle.io 34d nodetemplates.management.cattle.io 34d notifiers.management.cattle.io 34d pipelineexecutionlogs.management.cattle.io 34d pipelineexecutions.management.cattle.io 34d pipelines.management.cattle.io 34d podsecuritypolicytemplateprojectbindings.management.cattle.io 15d podsecuritypolicytemplates.management.cattle.io 34d preferences.management.cattle.io 34d projectalerts.management.cattle.io 34d projectloggings.management.cattle.io 34d projectnetworkpolicies.management.cattle.io 34d projectroletemplatebindings.management.cattle.io 34d projects.management.cattle.io 34d roletemplates.management.cattle.io 34d settings.management.cattle.io 34d sourcecodecredentials.management.cattle.io 34d sourcecoderepositories.management.cattle.io 34d templates.management.cattle.io 34d templateversions.management.cattle.io 34d tokens.management.cattle.io 34d users.management.cattle.io 34d
可以看到定义了很多CRD资源,这些资源再结合自定义的controller即实现了相应的业务逻辑。这里再介绍一下kubernetes自定义controller的编程范式,如下图所示:
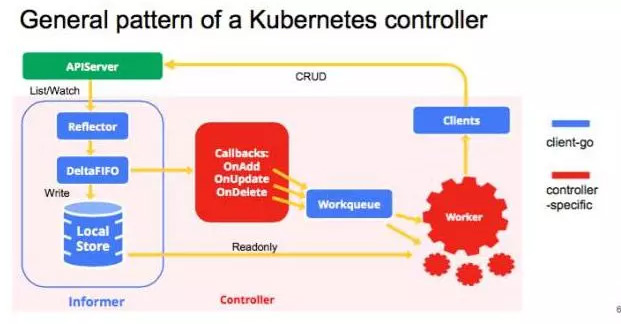
在自定义controller的时候,需要使用client-go工具。图中蓝色的部分是client-go中内容,即已经为用户提供的,不需要重新开发可以直接使用,红色的部分就是用户需要完成的业务逻辑。informer会跟踪CRD资源的变化,一旦触发就会调用Callbacks,并把关心的变更的object放到Workqueue中,Worker会get到Workqueue中的内容进行相应的业务处理。
接下来看Rancher中这些CRD资源的controller是如何创建的,在main.go中调用的Run()方法中会先构建一个scaledContext,由scaledContext.Start()方法进行controller的创建启动,代码如下:
func Run(ctx context.Context, kubeConfig rest.Config, cfg *Config) error { if err := service.Start(); err != nil { return err } scaledContext, clusterManager, err := buildScaledContext(ctx, kubeConfig, cfg) if err != nil { return err } if err := server.Start(ctx, cfg.HTTPListenPort, cfg.HTTPSListenPort, scaledContext, clusterManager); err != nil { return err } if err := scaledContext.Start(ctx); err != nil { return err } ......
scaledContext.Start()方法的代码如下:
func (c *ScaledContext) Start(ctx context.Context) error { logrus.Info("Starting API controllers") return controller.SyncThenStart(ctx, 5, c.controllers()...) }
这里的c.controllers()会进行接口赋值,即将ScaledContext结构体中的Management、Project、RBAC和Core接口赋值给controller包中Starter接口,代码如下:
type ScaledContext struct { ClientGetter proxy.ClientGetter LocalConfig *rest.Config RESTConfig rest.Config UnversionedClient rest.Interface K8sClient kubernetes.Interface APIExtClient clientset.Interface Schemas *types.Schemas AccessControl types.AccessControl Dialer dialer.Factory UserManager user.Manager Leader bool Management managementv3.Interface Project projectv3.Interface RBAC rbacv1.Interface Core corev1.Interface } func (c *ScaledContext) controllers() []controller.Starter { return []controller.Starter{ c.Management, c.Project, c.RBAC, c.Core, } }
通过调用controller包中Starter接口的Sync和Start方法来完成自定义controller的创建和启动。代码如下:
type Starter interface { Sync(ctx context.Context) error Start(ctx context.Context, threadiness int) error } func SyncThenStart(ctx context.Context, threadiness int, starters ...Starter) error { if err := Sync(ctx, starters...); err != nil { return err } return Start(ctx, threadiness, starters...) } func Sync(ctx context.Context, starters ...Starter) error { eg, _ := errgroup.WithContext(ctx) for _, starter := range starters { func(starter Starter) { eg.Go(func() error { return starter.Sync(ctx) }) }(starter) } return eg.Wait() } func Start(ctx context.Context, threadiness int, starters ...Starter) error { for _, starter := range starters { if err := starter.Start(ctx, threadiness); err != nil { return err } } return nil }
在此前的buildScaledContext()方法中,赋值了Management、Project等接口的实现,而这些接口中又包含各自所需要的controller的实现,这里不再详述了。以Management中的cluster controller为例,其创建的过程如下图所示:
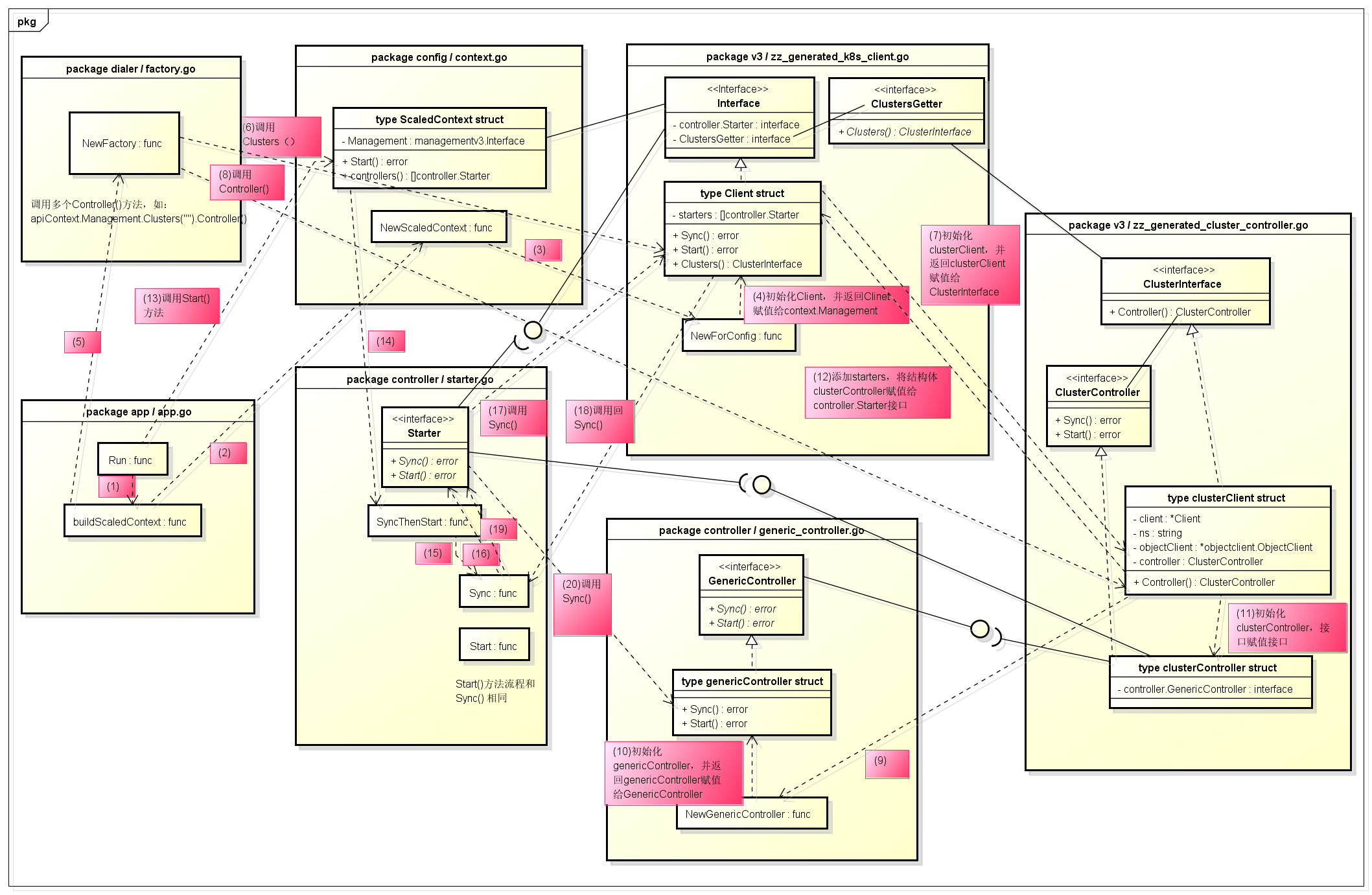
最终,由controller包中generic_controller.go的genericController结构体实现了Sync和Start方法,另外,在NewGenericController实现了此前提到的informer和workqueue,代码如下:
func NewGenericController(name string, genericClient Backend) GenericController { informer := cache.NewSharedIndexInformer( &cache.ListWatch{ ListFunc: genericClient.List, WatchFunc: genericClient.Watch, }, genericClient.ObjectFactory().Object(), resyncPeriod, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc}) rl := workqueue.NewMaxOfRateLimiter( workqueue.NewItemExponentialFailureRateLimiter(500*time.Millisecond, 1000*time.Second), // 10 qps, 100 bucket size. This is only for retry speed and its only the overall factor (not per item) &workqueue.BucketRateLimiter{Bucket: ratelimit.NewBucketWithRate(float64(10), int64(100))}, ) return &genericController{ informer: informer, queue: workqueue.NewNamedRateLimitingQueue(rl, name), name: name, } }
Sync方法中定义了informer中的Callbacks,如下所示:
func (g *genericController) Sync(ctx context.Context) error { g.Lock() defer g.Unlock() return g.sync(ctx) } func (g *genericController) sync(ctx context.Context) error { if g.synced { return nil } defer utilruntime.HandleCrash() g.informer.AddEventHandler(cache.ResourceEventHandlerFuncs{ AddFunc: g.queueObject, UpdateFunc: func(_, obj interface{}) { g.queueObject(obj) }, DeleteFunc: g.queueObject, }) logrus.Infof("Syncing %s Controller", g.name) go g.informer.Run(ctx.Done()) if !cache.WaitForCacheSync(ctx.Done(), g.informer.HasSynced) { return fmt.Errorf("failed to sync controller %s", g.name) } logrus.Infof("Syncing %s Controller Done", g.name) g.synced = true return nil }
Start方法中,包含了worker的内容,即调用了controller所需要的处理逻辑,代码片段展示如下:
...... func (g *genericController) processNextWorkItem() bool { key, quit := g.queue.Get() if quit { return false } defer g.queue.Done(key) // do your work on the key. This method will contains your "do stuff" logic err := g.syncHandler(key.(string)) checkErr := err if handlerErr, ok := checkErr.(*handlerError); ok { checkErr = handlerErr.err } if _, ok := checkErr.(*ForgetError); err == nil || ok { if ok { logrus.Infof("%v %v completed with dropped err: %v", g.name, key, err) } g.queue.Forget(key) return true } if err := filterConflictsError(err); err != nil { utilruntime.HandleError(fmt.Errorf("%v %v %v", g.name, key, err)) } g.queue.AddRateLimited(key) return true } ......
小结
Kubernetes已经成为了容器编排的事实标准,但还不足以构成一个PAAS平台,需要在其之上进行多方面的的扩展,Rancher正是一种很好的实现,其包含了多cluster和project的统一管理,CI/CD,及基于Helm的应用商店,另外还有权限、监控、日志等的管理。本文主要是从代码层面简要学习和分析Rancher是如何基于Kubernetes进行扩展的,并结合Kubernetes controller的编程范式介绍其实现机制。
posted on 2018-05-02 17:05 Hindsight_Tan 阅读(5366) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号