matrix(矩阵)与tensor(张量)有什么区别
原文:https://medium.com/@quantumsteinke/whats-the-difference-between-a-matrix-and-a-tensor-4505fbdc576c
这个问题有一个简短的答案,让我们从这里开始。然后我们可以看看具体例子以获得更多的内涵。
矩阵是一个由括号包围的数字组成的格子。只要尺寸相容((n× m)×(m × p)= n × p),我们可以加减相同尺寸的矩阵,将一个矩阵与另一个矩阵相乘,然后将整个矩阵乘以常数。向量是只有一行或一列的矩阵(但请参见下文)。所以我们可以对任何矩阵做大量的数学运算。
但基本思想是,矩阵只是一个二维数字网格。
张量通常被认为是作为一个广义矩阵。也就是说,它可能是一维矩阵(一个向量实际上就是这样的张量),一个三维矩阵(类似于数字组成的立方体),甚至是一个没有维度的矩阵(单个数字),或者更高三维结构而难以形象化。张量的维度称为它的等级(rank)。
但是这种描述忽略了张量最重要的性质!
张量是一个数学实体,它存在于一个结构中并与其他数学实体相互作用。如果有规则地转换结构中的其他实体,则张量必须遵守相关的转换规则。
张量的这种“动态”性质是将它与纯粹的矩阵区分开来的关键。相当于一个团队球员,当引入影响所有球员的转换时,他们的数值会与队友的数值一起转移。
任何2阶张量都可以表示为矩阵,但并不是每个矩阵都是2阶张量。用以表示张量的矩阵中的数值取决于对整个系统应用了哪些转换规则。
这个答案可能足以满足你的目的,但我们可以通过一个小例子来说明这是如何工作的。这个问题在一次深度学习的研讨会上提出,让我们来看一下该领域的一个简单例子。
假设我在神经网络中有3个节点的隐藏层。数据流入他们,通过他们的ReLU功能,并输出一些值。比方说,为了定性,我们分别得到2.5,4和1.2。我们可以将这些节点的输出表示为一个向量,

假设有另一层3个节点。来自第一层的3个节点中的每一个都具有与接下来的3个节点中的每一个输入相关联的权重。那么将这些权重写成3×3的条目矩阵将是非常简单。假设我们已经多次更新了网络并且得到了权重(这个例子是半随机选择的),

这里,一行中的权重全部到达下一层中的同一节点,而特定列中的权重全部来自第一层中的同一节点。例如,输入节点1贡献给输出节点3的权重为0.2(第3行,第1列)。我们可以通过将权重矩阵乘以输入向量来计算送到下一层节点的值,

不喜欢矩阵?这是一张图。数据从左到右流动。

不错,到目前为止,我们所看到的只是对矩阵和向量的一些简单操作。
但是!
假设我想人工介入并为每个神经元使用自定义激活函数。愚蠢的做法是从第一层单独重新调整每个ReLU函数。这个例子中,我们假设我将第一个节点向上扩展2倍,第二个节点保持原状,并将第三个节点缩小1/5。这将改变这些函数的图形,如下图所示:

这种修改的效果是分别改变由第一层值的2,1和1/5。这相当于将L1乘以矩阵A,
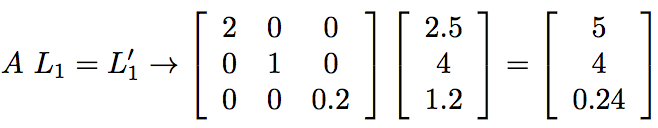
现在,如果这些新值通过原始权重网络,我们会得到完全不同的输出值,如图所示:
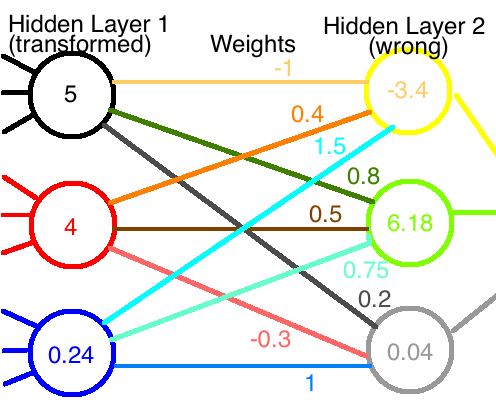
如果神经网络之前运行正常,现在我们已经破坏了它。我们必须重新训练才能获得正确的权重。
或者我们有必要这样吗?
第一个节点的值是以前的两倍。如果我们将该节点的所有权重减半,则其对下一层的输出保持不变。我们不对第二个节点做任何改动,所以我们可以保留它的权重。最后,我们需要将最后一组权重乘以5来补偿该节点上的1/5因子。在数学上,这相当于使用我们通过将原始权重矩阵乘以A的逆矩阵而获得的一组新的权重:
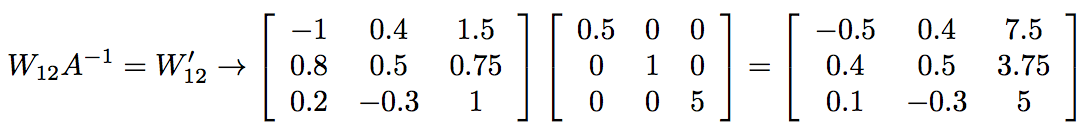
如果我们将第一层的修改后的输出与修改后的权重组合在一起,那么我们最终会得到到达第二层的正确值:
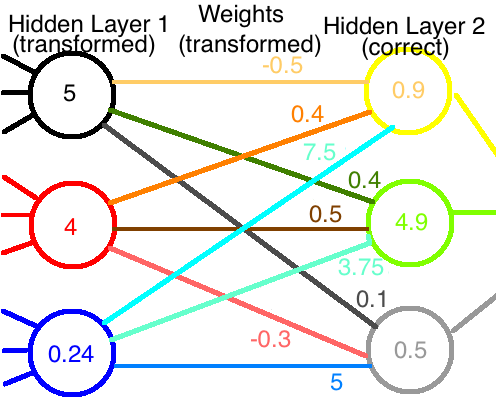
尽管我们做了一些反方向的工作,神经网络仍在可以继续工作!
好吧,这里有很多数学,所以让我们坐下来休息一下,然后回顾一下。
当我们将节点输入,输出和权重看作固定量时,我们将它们称为向量和矩阵就可以了。
但是,一旦我们开始与一个向量发生作用,使用一种方法将他转换,我们必须通过以相反的方式权重转换进行补偿。这个新增的、集成的结构将纯粹的数字矩阵提升为一个真正的张量对象。
事实上,我们可以更进一步表征它的张量性质。如果我们称节点的变化为协变(即随着节点变化并乘以A),这使得权重为逆变张量(相对于节点变化,具体地,乘以A的逆矩阵而不是A本身)。张量可以在一个维度上是协变的,在另一个维度上是相反的。
现在你应该知道矩阵和张量之间的区别了。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号