
第11章 使用元组进行组合
第11章 使用元组进行组合
11.2 元组字面量和元组类型
元组看作 CLR 引入的一些新类型,然后提供了相应的语法糖,使得新类型更易用。
易用包括两个层面:声明和构建。
11.2.1 语法
C#7 引入了两点新语法:
-
元组字面量:每个元素都有一个 值 和一个可选名称
下图表示的是一个 元组实例

-
元组类型:每个元素都有一个 类型 和可选名称
下图表示的是一个 元组类型



在实际编码中,一般所有元素都有名称,或者所有元素都没有名称(也可以像上面的两幅图那样,部分有名称)。对于元素名称,有如下要求:
-
不能出现重名
-
若以
ItemN 的方式为元素命名,N 的值必须和元素位置完全吻合(编号从 1 开始)。以如下两句代码为例,第 一 句合法,第 二 句非法:
var value1 = (Number: 0, Item2: 0); var value2 = (Number: 0, Item1: 0);
对于元素值和元素类型,有如下要求:
- 元素值不能是 指针 值
- 元素类型不能是 指针 类型
11.2.2 元组字面量推断元素名称(C#7.1)
在 C#7.0 中,需要在代码中显式给出元组元素名称。自 C#7.1 开始,元组的元素值如果来自 变量 或 属性 ,可以推断出元素名称。推断过程和 匿名 类型名称推断完成一致。
试比较如下两段代码,通过名称推断代码更加简洁:
from emp in employees
join dept in departments on emp.DepartmentId equals dept.Id
select (name: emp.Name, title: emp.Title, departmentName: dept.Name);
from emp in employees
join dept in departments on emp.DepartmentId equals dept.Id
select (emp.Name, emp.Title, DepartmentName: dept.Name);
元素的名称推断和命名 也 可以混用:
List<int> list = new List<int> { 5, 1, -6, 2 };
var tuple = (list.Count, Min: list.Min(), Max: list.Max());
Console.WriteLine(tuple.Count);
Console.WriteLine(tuple.Min);
Console.WriteLine(tuple.Max);
当推断的名称出现了冲突,有:
- 如果两个推断名称重名,那么 两个推断都会被放弃
- 如果推断名称和显式名称发生冲突,那么优先选择 显式 名称,剩下的一个元素保持 无 名称
11.2.3 元组用作变量的容器
元组类型是 公共 的、具有 读写 权限的值类型。因此,元组与常见的类型不同,它有如下特点:
- 元组存储的数据对它来说没有内在含义,只是作为数据的简单 容器 。
由于元组可读写,因此它的实例可以作为 局部变量 在方法中使用:
static (int min, int max) MinMax(IEnumerable<int> source)
{
using (var iterator = source.GetEnumerator())
{
if (!iterator.MoveNext())
{
throw new InvalidOperationException("Cannot find min/max of an empty sequence");
}
var result = (min: iterator.Current, max: iterator.Current);
while (iterator.MoveNext())
{
result.min = Math.Min(result.min, iterator.Current);
result.max = Math.Max(result.max, iterator.Current);
}
return result;
}
}
11.2.3.1 通过名称和位置来访问元素
任何元组中的变量都可以通过其位置进行访问(即使它被显式命名了)。这也是为什么:
若以
ItemN 的方式为元素命名,N 的值必须和元素位置完全吻合(编号从 1 开始)。
因此如下代码 合 法:
var value = (num1: 1, num2: 2);
Console.WriteLine(value.num1);
Console.WriteLine(value.Item2);
11.2.3.2 把元素当作单个值
下面这段代码还可以进一步简化,可以把 result 当作单个值进行更新:
static (int min, int max) MinMax(IEnumerable<int> source) { using (var iterator = source.GetEnumerator()) { if (!iterator.MoveNext()) { throw new InvalidOperationException("Cannot find min/max of an empty sequence"); } var result = (min: iterator.Current, max: iterator.Current); while (iterator.MoveNext()) { result.min = Math.Min(result.min, iterator.Current); result.max = Math.Max(result.max, iterator.Current); } return result; } }
static (int min, int max) MinMax(IEnumerable<int> source)
{
using (var iterator = source.GetEnumerator())
{
if (!iterator.MoveNext())
{
throw new InvalidOperationException("Cannot find min/max of an empty sequence");
}
var result = (min: iterator.Current, max: iterator.Current);
while (iterator.MoveNext())
{
result = (Math.Min(result.min, iterator.Current), Math.Max(result.max, iterator.Current));
}
return result;
}
}
我们再看下面这个求斐波那契数列的例子,使用元组后非常优雅:
static IEnumerable<int> Fibonacci()
{
int current = 0;
int next = 1;
while (true)
{
yield return current;
int nextNext = current + next;
current = next;
next = nextNext;
}
}
static IEnumerable<int> Fibonacci()
{
var pair = (current: 0, next: 1);
while (true)
{
yield return pair.current;
pair = (pair.next, pair.current + pair.next);
}
}
11.3 元组类型及其转换
11.3.1 元组字面量的类型
我们常用 var(隐式变量)简化元组实例的赋值,例如:
var valid = (10, 20);
上述代码之所以可以编译成功,是因为编译器会将数值推断为 int 类型。而如下代码的 null 值 类型 不确定,因此是 非 法的:
var invalid = (10, null);
对此我们可以显式定义元组 类型 :
(int, string) invalid = (10, null);
对于没有元组类型的元组字面量,我们可以使用元组字面量到元组类型的转换。
11.3.2 从元组字面量到元组类型的转换
11.3.2.1 隐式类型转换
元组字面量隐式转换为元组类型需要满足如下两个条件:
- 字面量与类型的 度 相同;
- 每个元组元素都可以 隐 式转换为对应的元素
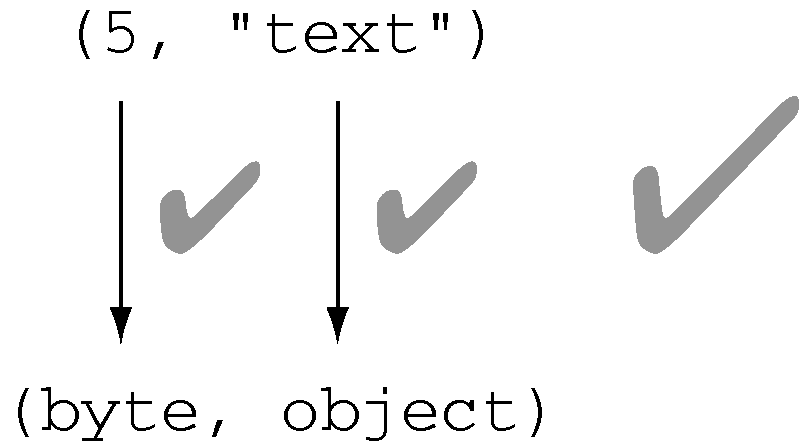
关于第二点,以如下代码为例,因数值 5 可以 隐式转换为 byte,因此如下代码 合 法:
(byte, object) tuple = (5, "text");
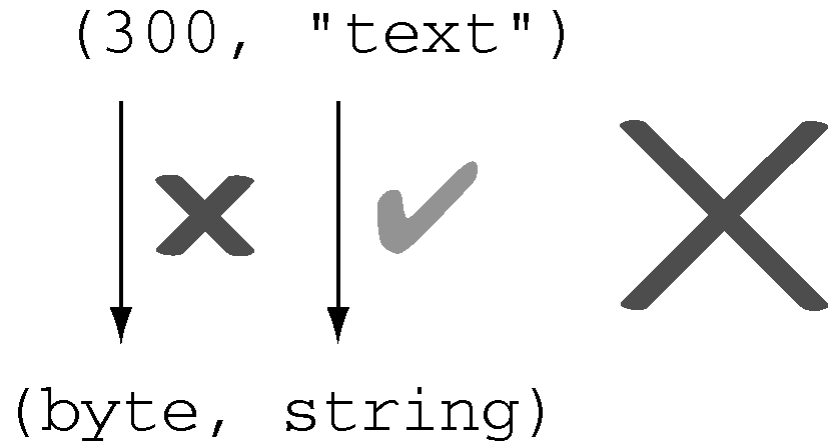
数值 300 无法 隐式转换为 byte,因此如下代码 非 法:
(byte, string) tuple = (300, "text");
Tips
元组字面量或者元组类型中元素的 个数 称为元组的度,例如
(int, long) 的度是 2 ,("a", "b", "c") 的度是 3 。元素的类型与元组的度无关。关于“度”,我们在泛型中也曾有介绍:2.1.2.2 泛型类型和泛型方法的度
11.3.2.2 显式类型转换
元组字面量显式转换为元组类型需要满足如下两个条件:
- 字面量与类型的 度 相同;
- 每个元组元素都可以 显 式转换为对应的元素
现在我们对如下代码进行改造,使其合法:
(byte, string) tuple = (300, "text");
改造的方式有二:
int x = 300;
var tuple = ((byte, string)) (x, "text");
int x = 300;
var tuple = ((byte) x, "text");
很显然第 二 种方式更为优雅。它的写法更易读,表意更清晰。
这里我们引入了一个局部变量 x,这是为了避免检查的上下文。我们使用 unchekced 将其包裹也可以通过编译:
unchecked
{
var tuple = ((byte, string))(300, "text");
}
11.3.1.3 元组字面量转换中元素名称的作用
元素名称在元组字面量转换中几乎不起任何作用,但也不是完全没用:当元组字面量中显式给出某个元素名称时,若目标元组类型中没有对应的元素名称,或元素名称不匹配,编译器会发出警告。例如:
(int a, int b, int c, int, int) tuple =
(a: 10, wrong: 20, 30, pointless: 40, 50);
其中第 2 、 4 个位置的元素编译器会给出警告。
我们可以利用这一特性让编译器帮我们进行参数检查,以如下代码为例,因搞错了 min、max 值的位置,编译器会进行警告:
static (int min, int max) MinMax(IEnumerable<int> source)
{
// 如下代码因名称和方法返回值名称不同,编译器会进行警告
return (max: max, min: min);
}
11.3.3 元组类型之间的转换
在前两节我们已知元组间进行显式/隐式转换要遵循如下条件:
- 字面量与类型的 度 相同;
- 每个元组元素都可以 隐 式转换为对应的元素
- 字面量与类型的 度 相同;
- 每个元组元素都可以 显 式转换为对应的元素
按照上述规则,如下代码中第 3 、 6 行的转换非法:
var t1 = (300, "text");
(long, string) t2 = t1;
(byte, string) t3 = t1;
(byte, string) t4 = ((byte, string)) t1;
(object, object) t5 = t1;
(string, string) t6 = ((string, string)) t1;
与元组字面量转换不同,类型转换不会检查元素名称是否匹配。比较如下代码,第 二 段代码不会收到警告:
(int a, int b, int c, int, int) tuple = (a: 10, wrong: 20, 30, pointless: 40, 50);
var source = (a: 10, wrong: 20, 30, pointless: 40, 50);
(int a, int b, int c, int, int) tuple = source;
11.3.3.1 元组类型一致性转换
C# 自诞生起就有一致性转换的概念,在 C#7 之前,一致性转换的规则如下:
- 同类型之间的转换是一致性转换。
-
object 类型和 dynamic 类型之间存在一致性转换。 - 如果两个数组的元素类型之间存在一致性转换,那么这两个数组之间存在一致性转换,例如
object[] 和 dynamic[] 之间存在一致性转换。 - 如果泛型的类型实参之间存在对应的一致性转换,那么泛型构建后类型也存在一致性转换,例如
List<object> 和 List<dynamic> 之间存在一致性转换。
Notice
一致性转换≠型变
元组自 C#7 引入,也支持一致性转换:两个 度 相同的元组类型,当每对元素类型都存在 一致性 转换时,这两个元组类型间存在一致性转换(不考虑元素名称)。
例如,以下几个类型存在一致性转换:
-
(int x, object y) -
(int a, dynamic d) -
(int, object)
一致性转换适用于 构建 后类型,因此如下两个类型存在一致性转换:
-
Dictionary<string, (int, List<object>)> -
Dictionary<string, (int index, List<dynamic> values)>
这种一致性转换对重载方法十分重要,以如下代码为例,因它们二者的参数支持一致性转换,编译时会进行 报错 :
// error CS0111: Type 'Program' already defines a member called 'Method' with the same parameter types
public void Method((int, int) tuple) {}
public void Method((int x, int y) tuple) {}
Summary
如果感觉一致性转换的官方定义难以理解,这里有一种简单的方式:如果在 执行 期两个类型无法区分,它们就属于一致性类型。
11.3.3.2 缺少泛型型变
泛型型变只能用于 引用 类型,而元组类型是值类型。因此如下代码 无法 通过编译:
IEnumerable<(string, string)> stringPairs = new (string, string)[10];
IEnumerable<(object, object)> objectPairs = stringPairs;
Eureka
“泛型型变不能用于值类型”其实很好理解:值类型存放在栈中,占用的空间不能随意改变,因此不适用于型变。
11.3.5 继承时的元素名称检查
元素名称在进行类型转换时并不重要,但是在涉及继承时编译器对名称有要求。如果某个子类或者接口实现类的成员中出现元组,那么:
-
元组中的元素名称必须和原始元组名称 完全一致
- 原始元组元素具名时,要保持名称 一致 ;
- 如果不具名,继承类或者实现类中的元组元素也必须 不具名 。
-
实现类中的元素类型必须和原始定义中的元素类型保持 一致性 可转换。
以如下代码为例,第 11 、 12 行的实现合法:
interface ISample
{
void Method((int x, object) tuple);
}
public void Method((string x, string) tuple) { }
public void Method((int, object) tuple) { }
public void Method((int x, object extra) tuple) { }
public void Method((int wrong, object) tuple) { }
public void Method((int x, object, int) tuple) { }
public void Method((int x, object) tuple) { }
public void Method((int x, dynamic) tuple) { }
该规则不仅限于方法的参数,还适用于返回值。
Warn
对于接口成员或者
virtual/abstract 类成员中元组元素类型名称的增加、删除和修改都属于破坏性更改。在对公共 API 做此类修改时一定要慎重考虑!
11.3.6 等价运算符与不等价运算符(C#7.3)
从 C#7.3 开始,编译器为存在一致性转换的元组类型提供了元组 == 和 != 的实现(比较时 不考虑 元素的名称)。
编译器将 == 运算符扩展到 元素 级别的 == 操作:它会对 每一对元素值 执行 == 操作(!= 运算符同理)。代码示例如下
var t1 = (x: "x", y: "y", z: 1); // 比较时不考虑
var t2 = ("x", "y", 1); // 元素名称不同
Console.WriteLine(t1 == t2);
Console.WriteLine(t1.Item1 == t2.Item1 && //
t1.Item2 == t2.Item2 && // 编译器生成的
t1.Item3 == t2.Item3); // 等价代码
Console.WriteLine(t1 != t2);
Console.WriteLine(t1.Item1 != t2.Item1 || //
t1.Item2 != t2.Item2 || // 编译器生成的
t1.Item3 != t2.Item3); // 等价代码
Eureka
如果比较的元素未实现
==、!= 的重载会怎样?答案是无法通过编译!以如下代码为例,它会报错 CS0019:
var tuple1 = (1, p1); var tuple2 = (1, p2); Console.WriteLine(tuple1 == tuple2); struct Person { public int Age; public string Name; }
11.4 CLR 中的元组
11.4.1 引入 System.ValueTuple<...>
C# 7 的元组类型是通过 System.ValueTuple 类型家族实现的,在使用 C# 元组类型时,它都会被映射为某个 ValueTuple<...> 类型。
ValueTuple 结构体共有 9 个定义,其泛型度从 0~8 分别为:
-
System.ValueTuple (非泛型) -
System.ValueTuple<T1> -
System.ValueTuple<T1, T2> -
System.ValueTuple<T1, T2, T3> -
System.ValueTuple<T1, T2, T3, T4> -
System.ValueTuple<T1, T2, T3, T4, T5> -
System.ValueTuple<T1, T2, T3, T4, T5, T6> -
System.ValueTuple<T1, T2, T3, T4, T5, T6, T7> -
System.ValueTuple<T1, T2, T3, T4, T5, T6, T7, TRest>
ValueTuple<...> 类型的字段名称为 Item1 、 Item2 、……、 Item7 。度为 8 的元组最后一个字段名为 Rest 。
11.4.2 处理元素名称
C# 的元组最终都会映射为 ValueTuple<...>,它们的名称也会映射至 ValueTuple<...> 形如 ItemN 的名称上:

可以看到编译后元组元素的名称都消失了!这种局部变量仅在编译时有效;而在执行期,只有 PDB 文件会跟踪这些名称用于调试。
11.4.2.1 元数据中的元素名称 & 11.4.2.2 执行期不存在元素名称
元组类型在执行期没有元素名称。在调试时可以看到元素名称是疑问调试器通过额外信息获取了原始的元素名称,而 CLR 无法直接知晓这些信息。
如果元组用作公共方法的返回值,只能使用形如 ItemN 的元素名称显然会让代码的可读性下降。为此编译器提供了名为 TupleElementNamesAttribute 的特性。该特性将元素名称编入程序集中。例如在 C#6 中,可以添加该特性将元素名称公开:
[return: TupleElementNames(new[] {"min", "max"})]
public static ValueTuple<int, int> MinMax(IEnumerable<int> numbers)
Tips
手动使用该特性时只能用于 C#6,C#7 会自动帮我们完成这些工作。
11.4.3 元组类型转换的实现
ValueTuple 之间的类型转换不是在 执行 期进行的,而是在 编译 期完成:C# 编译器会根据需要创建一个新值,然后对每个元素单独进行转换。
以下两段代码等价:
(int, string) t1 = (300, "text");
(long, string) t2 = t1;
(byte, string) t3 = ((byte, string)) t1;
var t1 = new ValueTuple<int, string>(300, "text");
var t2 = new ValueTuple<long, string>(t1.Item1, t1.Item2);
var t3 = new ValueTuple<byte, string>((byte) t1.Item1, t1.Item2));
11.4.4 元组的字符串表示
元组实例调用 ToString() 方法遵循如下规则:
- 对每个非 null 元素调用
ToString() 方法 - 对 null 元素返回 空字符串
- 得到的内容用 小括 号包围,由 逗 号分隔
- 元素名称 不进行 输出
以如下代码为例,它的输出内容为: (, text, 10)
var tuple = (x: (string) null, y: "text", z: 10);
Console.WriteLine(tuple.ToString());
11.4.5 一般等价比较和排序比较
ValueTuple<...> 类型的等价比较有:
-
实现了
IEquatable<T> 接口内部调用每个元素的相等比较器。
-
重写了
object.Equals(object) 方法如果实参类型不匹配,该方法会返回 false 。内部通过
IEquatable<T>.Equals() 方法判断是否相等 -
重写了
object.GetHashCode() 方法将每个元素的散列值结合成一个整体散列值
排序比较有:
-
实现了
IComparable<T> 接口排序按元素进行,排在 前面 的元素权重更大。例如
(1, 5) 小 于(3, 2) -
实现了
IComparable 接口如果实参类型不匹配,该方法会 抛出
ArgumentException 异常 。内部调用IComparable<T>.Comparer() 方法
如下代码演示了坐标点筛去重复点、并进行排序:
var points = new[]
{
(1, 2), (10, 3), (-1, 5), (2, 1),
(10, 3), (2, 1), (1, 1)
};
var distinctPoints = points.Distinct();
Console.WriteLine($"{distinctPoints.Count()} distinct points");
Console.WriteLine("Points in order:");
foreach (var point in distinctPoints.OrderBy(p => p))
{
Console.WriteLine(point);
}
11.4.6 结构化等价比较和排序比较
Info
关于
IStructuralEquatable 接口和IStructuralComparable 接口,另见7.7.4 IStructuralEquatable 和 IStructualComparable
ValueTuple 结构体显式实现了 IStructuralEquatable 接口和 IStructuralComparable 接口,它们接受外部传入的比较器(IEqualityComparer 和 IComparer):
public interface IStructuralEquatable
{
bool Equals(Object, IEqualityComparer);
int GetHashCode(IEqualityComparer);
}
public interface IStructuralComparable
{
int CompareTo(Object, IComparer);
}
上述接口用于自定义 ValueTuple 相等比较、排序比较的规则。以如下代码为例,它使用不区分大小写的相等比较和排序比较:
var Ab = ("A", "b");
var aB = ("a", "B");
var aa = ("a", "a");
var ba = ("b", "a");
Compare(Ab, aB);
Compare(aB, aa);
Compare(aB, ba);
static void Compare<T>(T x, T y)
where T : IStructuralEquatable, IStructuralComparable
{
var comparison = x.CompareTo(y, StringComparer.OrdinalIgnoreCase);
var equal = x.Equals(y, StringComparer.OrdinalIgnoreCase);
Console.WriteLine($"{x} and {y} - comparison: {comparison}; equal: {equal}");
}
11.4.7 独素元组和巨型元组
- 独素元组:只有 一个元素 的元组(
ValueTuple<T1>) - 巨型元组:元素数量达到 8 个及以上的元组
独素元组看起来毫无作用,实际上它主要用于配合巨型元组使用。当元素数量达到 7 个以上时,多出来的元素将构成 新元组 实例嵌入。对于一个度为 8 的 int 类型元组,其相关类型如下:
ValueTuple<int, int, int, int, int, int, int, ValueTuple<int>>
访问元素时新元组的元素 仍 能使用 ItemX 名称进行访问,C# 内部帮我们进行了处理。例如:
var tuple = (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16);
Console.WriteLine(tuple.Item16);
这段代码完全合法,但编译器会把 tuple.Item16 表达式转换为 tuple.Rest.Rest.Item2。
11.4.8 非泛型 ValueTuple 结构体
- 无素元组:nuple,非泛型、无元素的元组
该类型内含各种 Create() 方法,用于 创建其他有元素的元组 。
11.4.9 扩展方法
System.TupleExtensions 静态类包含了 Tuple 和 ValueTuple 类型的一些扩展方法,分为三类:
-
Deconstruct 负责Tuple 类型的扩展见12.1 分解元组
-
ToValueTuple 负责Tuple 类型的扩展:将 Tuple 转为 ValueTuple -
ToTuple 负责ValueTuple 类型的扩展:将 ValueTuple 转为 Tuple
11.5 元组的替代品
11.5.1 System.Tuple<...>
System.Tuple<...> 类型是 不可 变的引用类型(浅不可变,毕竟它不能限制引用类型的自身成员不可变),有如下缺点:
- 缺少语言集成
- 只能通过形如 ItemX 的名称访问成员
- 不支持与
ValueTuple 类似的 类型转换 方法
作为引用类型,它也有引用类型带来的优点:
- 大型对象之间的引用复制,其效率较
ValueTuple 更 高 - 引用复制是 原子 操作(元组值复制不是),线程安全
11.5.2 匿名类型
元组具备匿名类型的大部分优点,它还能用作方法的返回值。
作者认为匿名类型相较元组主要有如下优势:
-
匿名类型的
ToString() 方法会输出 成员名称 ,有助于问题诊断; -
可以用于各种 LINQ 提供器,而元组字面量不能用于 表达式树 ;
-
在传递过程中使用的是 引用 值,某些情况下效率更高。
不过大多数情况下没有明显优势,且元组无需创建对象,减少了 GC 压力
11.5.3 命名类型
元组只是变量的简单集合,不提供封装,不预设变量的任何含义。
如果只需要临时的值组合,或者目前处于原型设计阶段,还不确定需要什么数据类型,那么 元组 是很好的选择;但如果要在代码的多处使用同一个组合数据形态,采用 具名的类型 会更好。
11.6 元组的使用建议
因元组尚未探索出最佳实践(时隔本书发布多年,最佳实践应该已经有了),元组作者仅建议在如下场景中使用:
-
非公共 API 以及易变的代码
因元组尚未摸索出最佳实现,通过公共 API 中暴漏可能造成后期 维护 问题
-
局部变量
有些局部变量 紧密关联 :二者同时初始化、同时发生变化。此时可以考虑使用元组变量。
-
字段
与局部变量类似,有时字段也有聚集效应。
作者不建议在如下场景使用元组:
- 通过动态类型访问元组成员
主要有两个原因:
- 动态绑定器不知道元组 名称
- 动态绑定器无法知道 7 以上的元素 序号
以如下代码为例,运行时会抛出异常:
dynamic tuple = (x: 10, y: 20);
Console.WriteLine(tuple.x);
var tuple = (1, 2, 3, 4, 5, 6, 7, 8, 9);
Console.WriteLine(tuple.Item9);
dynamic d = tuple;
Console.WriteLine(d.Item9);
Eureka
第二段代码改成这样可以正常运行:
var tuple = (1, 2, 3, 4, 5, 6, 7, 8, 9); Console.WriteLine(tuple.Item9); dynamic d = tuple; Console.WriteLine(d.Rest.Item2);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号