kubernetes基于kubeadm搭建集群
服务器资源:
192.168.2.10 master01
192.168.2.11 master02
192.168.2.12 master03
192.168.2.20 node01
192.168.2.21 node02
192.168.2.16 k8svip
一、基础环境准备
1、修改服务器主机名、设置hosts本地解析主机名
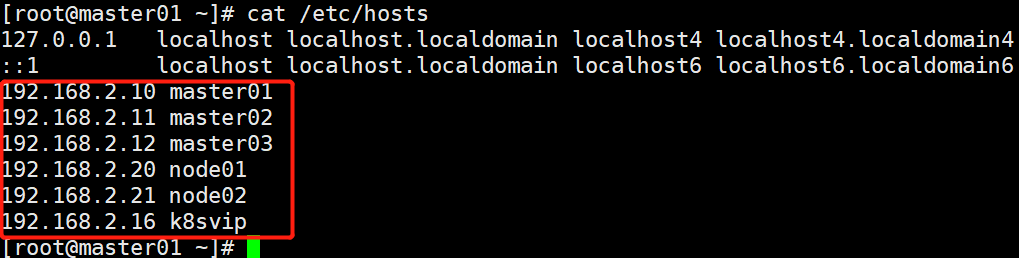
分别修改5台服务器的/etc/hosts文件,内容如下:
2、关闭防火墙、修改selinux
在5台服务器上进行如下操纵:
systemctl stop firewalld && systemctl disable firewalld
setenforce 0 ; sed -i 's/SELINUX=.*/SELINUX=disabled/g' /etc/selinux/config #很重要,不然后续keeaplived会出现vip脑裂的现象
3、关闭swap分区
在5台服务器上进行如下操纵:
swapoff -a ; sed -i '/swap/ s/^/#/' /etc/fstab
4、服务器时间同步
在master01上搭建ntpd服务,作为时间同步服务器。其他服务器向master01进行时间同步
在5台服务器上,均执行:yum install ntp -y
修改master01服务器上ntp.conf文件,配置如下:
driftfile /var/lib/ntp/drift
restrict 127.0.0.1
restrict ::1
restrict 192.168.2.0 mask 255.255.255.0 modify notrap #允许192.168.2.0网段的服务器向自己进行时间同步
server 127.127.1.0 #当外部时间服务器不可用时,使用本地时间
fudge 127.127.1.0 stratum 11
includefile /etc/ntp/crypto/pw
keys /etc/ntp/keys
disable monitor
在master01上启动时间服务器,systemctl start ntpd
启动后查询:

分别在master02、master03、node01、node02上执行ntpdate master01。结果如下:

二、haproxy+keepalived高可用搭建
1、安装haproxy、keepalived
在master01、master02、master03上,安装keepalived、haproxy,执行命令:yum install keepalived haproxy -y
安装完毕后,修改keepalived的配置文件如下:
[root@master02 ~]# cat /etc/keepalived/keepalived.conf
vrrp_script check_haproxy {
script "/etc/keepalived/check.sh" #执行检测haproxy健康状态的脚本,需要有x权限
interval 5
}
vrrp_instance VI_1 {
state BACKUP #master01上是MASTER,master02、master03上是BACKUP
interface ens33 #vip绑定的网卡名称,需保证master01、master02、master03网卡名称一致
virtual_router_id 51
priority 90 #master01上写成100,master02和master03上写成90。 这个值没有强制性要求,值越小vip调度到该服务器上的概率越小
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
check_haproxy
}
virtual_ipaddress {
192.168.2.16 #绑定的vip地址
}
}
将下面check.sh脚本分别放入到master01、master02、master03的/etc/keepalived/目录下,并执行chmod +x /etc/keepalived/check.sh
[root@master02 ~]# cat /etc/keepalived/check.sh
#!/bin/bash
vip="192.168.2.16"
ip_n=$(ip a|grep glo|grep ${vip}|wc -l)
###########################################
if [ ${ip_n} -eq 1 ];then
if [ $(ps -ef|grep haproxy|grep -v grep|wc -l) -eq 0 ];then
systemctl start haproxy
fi
else
if [ $(ps -ef|grep haproxy|grep -v grep|wc -l) -ge 1 ];then
systemctl stop haproxy
fi
fi
2、启动并验证
分别在master01、master02、master03上启动keepalived服务,执行:systemctl start keepalived
启动后,可以查看vip绑定情况。按照上述配置,应该优先绑定在master01上,并启动master01上的haproxy服务,实现负载均衡。可停止master上的keepalived服务,查看vip漂移及haproxy服务变动情况,此处略...
三、k8s安装
1、yum配置(5台服务器上均操作)
备份repo:
cd /etc/yum.repos.d/ ; rename *.repo *.repo.bak
配置阿里云yum源:
wget https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg #若无wget命令,可用原来的源安装下wget,或者是通过curl下载
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
rpm --import rpm-package-key.gpg
yum install -y yum-utils device-mapper-persistent-data lvm2
配置阿里云docker源:
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
配置阿里云k8s源:
tee /etc/yum.repos.d/kubernetes.repo <<-'EOF'
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
2、安装docker-ce、kubelet、kubeadm服务(5台服务器上均操作)
yum install docker-ce kubelet kubeadm -y #默认是安装最新版本的,也可以选择需要的版本进行安装
systemctl start docker && systemctl enable docker
这个时候不要去启动kubelet,启动不来的
3、初始化集群
先在master01上,初始化k8s集群,后面再将master02、master03、node01、node02加入到集群中
master01上执行:kubeadm init --control-plane-endpoint 192.168.2.10:6443 --pod-network-cidr 10.10.0.0/16 --service-cidr 20.20.0.0/16 --image-repository registry.aliyuncs.com/google_containers #pod和service的ip可自行定义,image-repository改成国内的,不然下载不了镜像。此操作会自动pull镜像
此处可能有各种报错,看着解决。一般无非是镜像下载失败、cpu资源不够、kubelet和docker的驱动不一致之类的

在master01上执行:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
在node01、node02上执行以下命令,加入到集群中
kubeadm join 192.168.2.10:6443 --token h6hj6m.hx8casg7ew97gfxb --discovery-token-ca-cert-hash sha256:62a0e82cbdd856a3764453399e772d609112cb4c6823511cd24c2b6306415a2b
在master01上查看节点信息如下(此时网络插件未安装,coredns处于pending状态或者ImagePullBackOff,STATUS显示的是NotReady。):

4、安装网络插件flannel
可以在gitlab上下载:https://github.com/flannel-io/flannel/blob/master/Documentation/kube-flannel.yml
将kube-flannel-aliyun.yml上传到master01上,修改128行,将Network网段修改成之前kubeadm时候设置的网段,我设置的是10.10.0.0/16 并执行:kubectl apply -f kube-flannel.yml
5、coredns镜像处理
在master01上kubectl get pods -A,状态显示为ImagePullBackOff。通过describe查看信息,发现coredns的镜像下载失败。
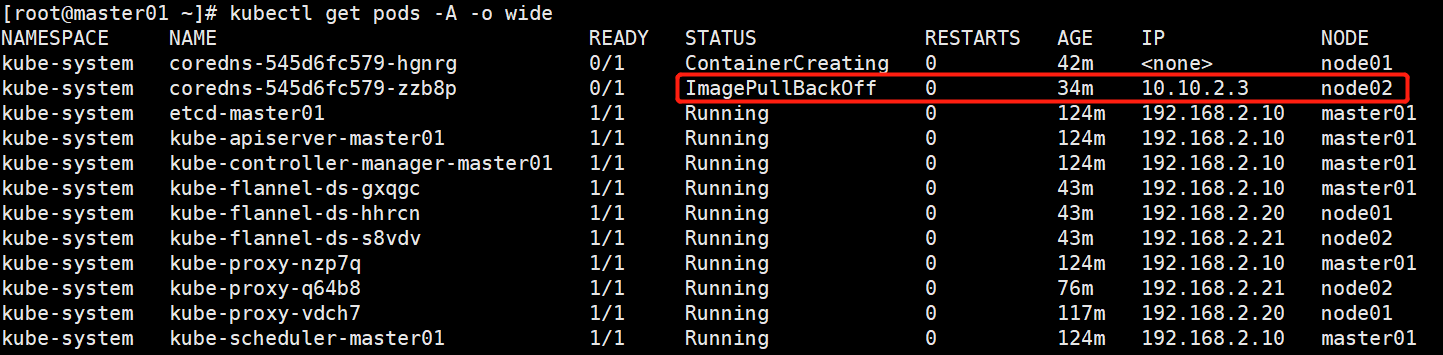
查看k8s组件需要的镜像信息:
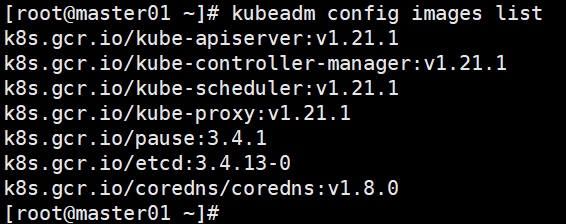
通过上面信息可以看出,coredns需要的镜像是v1.8.0,而这个镜像在阿里云镜像仓库没有。可以在dockerhub中搜索coredns,下载1.8.0的,然后改下镜像名称(此操作建议在5台服务器上均操作)

此时再看pod信息,显示成功

6、master集群加入
在master02、master03上执行:mkdir /etc/kubernetes/pki/etcd -p
将master01上的证书信息发送到master02、master03
在master01上执行:
scp -r /etc/kubernetes/pki/{ca.*,front-*,sa*} master02:/etc/kubernetes/pki/ && scp -r /etc/kubernetes/pki/etcd/ca.* master02:/etc/kubernetes/pki/etcd/
scp -r /etc/kubernetes/pki/{ca.*,front-*,sa*} master03:/etc/kubernetes/pki/ && scp -r /etc/kubernetes/pki/etcd/ca.* master03:/etc/kubernetes/pki/etcd/
然后再master02、master03上执行join操作,加入到控制平面中
kubeadm join 192.168.2.10:6443 --token h6hj6m.hx8casg7ew97gfxb --discovery-token-ca-cert-hash sha256:62a0e82cbdd856a3764453399e772d609112cb4c6823511cd24c2b6306415a2b --control-plane
成功加入后,分别再master02、master03上执行:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
分别在master01、master02、master03上执行kubectl get nodes、kubectl get pods -A,验证集群
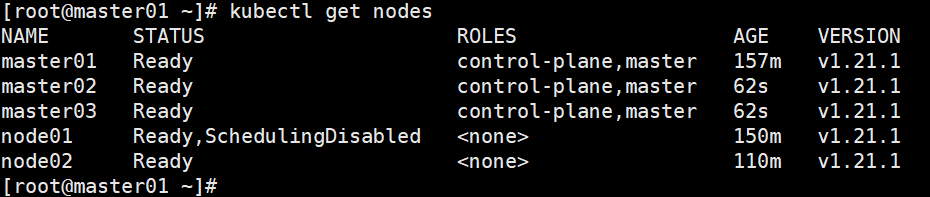
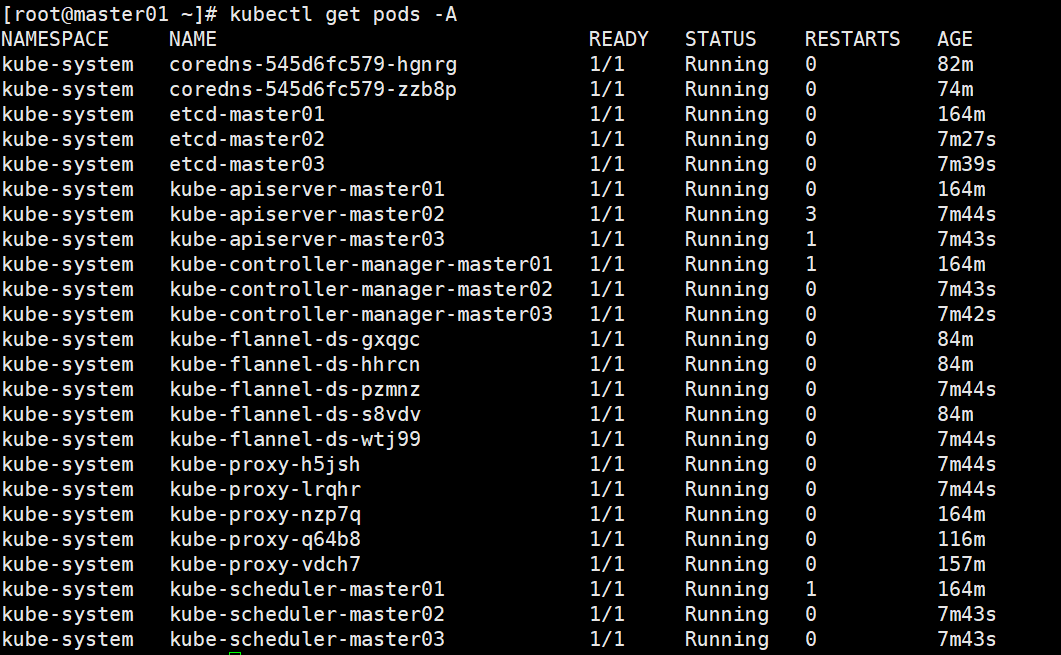
至此,集群搭建结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号