


大数据学习之Spark的缓存机制及CheakPoint 47
1、RDD的缓存机制
RDD通过persist方法或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。

通过查看源码发现cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StorageLevel中定义的。

缓存有可能丢失,或者存储存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
l Demo示例:

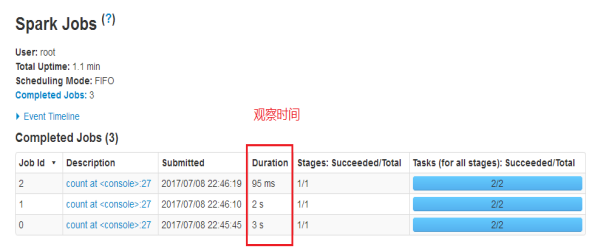
l 通过UI进行监控:
2、RDD的Checkpoint(检查点)机制:容错机制
检查点(本质是通过将RDD写入Disk做检查点)是为了通过lineage(血统)做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。
设置checkpoint的目录,可以是本地的文件夹、也可以是HDFS。一般是在具有容错能力,高可靠的文件系统上(比如HDFS, S3等)设置一个检查点路径,用于保存检查点数据。
分别举例说明:
l 本地目录
注意:这种模式,需要将spark-shell运行在本地模式上
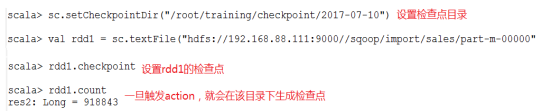
l HDFS的目录
注意:这种模式,需要将spark-shell运行在集群模式上

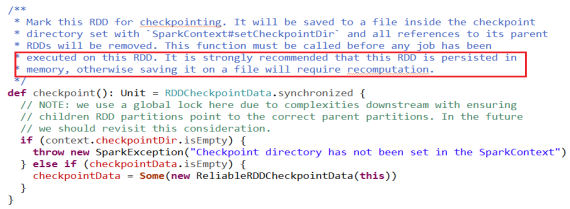
l 源码中的一段话

 浙公网安备 33010602011771号
浙公网安备 33010602011771号