AI系统论文:SmartMoE
2 Background and Motivation
MoE:Misture-of-Expertsn
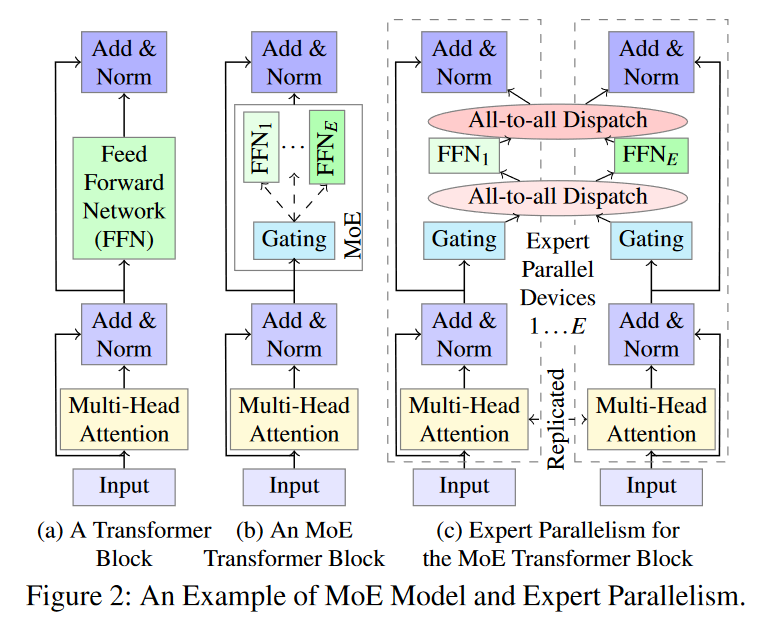
FFN为MoE模型中的专家,多个FFN和一个Gating组成了基本的MoE模型。
2.2 混合和自动并行化
训练密集型深度学习网络的常见的三种并行方式:
Data Parallelism(DP)
每个worker均存储一个完整的参数副本,分配给每个worker的训练样本都不同,并且前向传播和反向传播是在每个worker上独立完成的, then gradients on different workers will be aggregated before being used in the optimization of the model.
disadvantages: 由于参数需要在每个workder中同步和复制,因此会造成内存浪费和communication overhead.
Pipeline Model Parallelism(PP)
参见之前的DSP的文章,就用的PP这个思路:将训练过程分为多个阶段:Sampling,loading and training。
然后每个worker负责一个,会导致communication过程的时间花销变大。
Tensor Model Parallelism(TP)
张量模型并行(Tensor Model Parallelism,TP)是一种人工智能领域的技术。模型的单个运算符被分割成多个工作节点(workers)。每个工作节点存储运算符参数的一部分,并执行其中一部分的计算,例如矩阵的一个瓦片(tile)。不同运算符的TP需要由专家专门设计,分割方法对分布式训练性能至关重要。Megatron [35] 提供了在Transformer模型上使用TP的最佳实践。其他研究[36, 38]探讨了TP的统一表示和最高效分割的自动生成。
最后,总结了任何自动并行化训练系统的三个关键挑战:
- Space of Hybrid Parallelism(混合并行空间)
不同策略的混合使用可能会带来适应的问题
- Performance Modeling 性能建模
性能建模有助于有效探索巨大的混合并行空间。
- Searching Algorithm 搜索算法
因为搜索空间巨大,因此要找一个好的搜索算法。
2.3 Challenges of Automatic Parallelization for MoE Models
用下图解释自动并行MoE模型的挑战性:
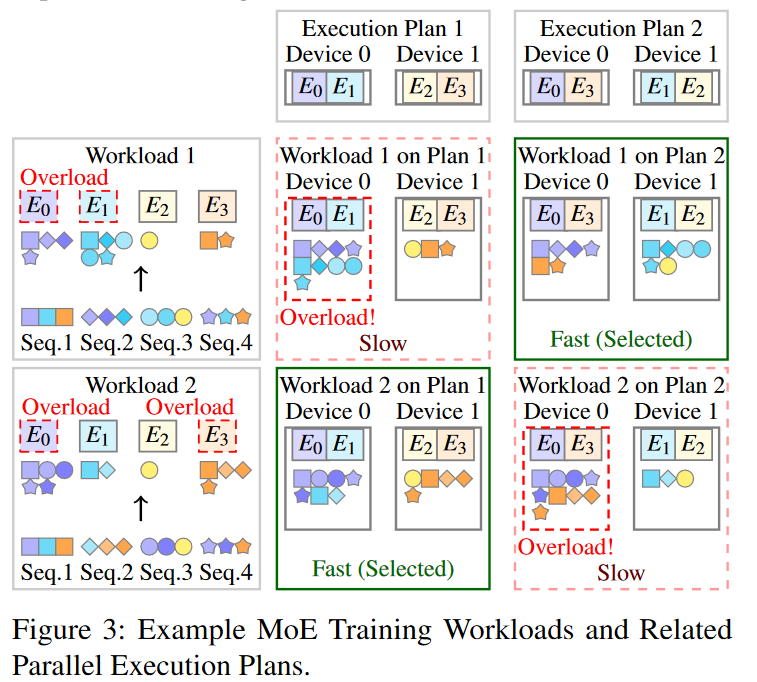
- 更大的混合并行空间。
因为模型要额外考虑不同expert之间的组合差异,如E0与E1组合还是E0与E3组合。(一个MoE layer 有四个expert)
- 工作负载感知性能建模
传统的性能建模方式仅使用模型结构和硬件信息来估计性能,缺乏对工作负载的考虑。因为在上图中,上下两个工作负载使得同一个方案出现了效率上的差异。
- 自适应动态并行化
由于MoE训练过程会出现不同工作负载,因此我们需要自适应自动并行化,该方法采用运行时执行方案搜索和切换来保持训练过程高效率。训练系统可以在每次迭代时更新执行计划,以实现最终的高性能。
3 Overview——SmartMoE
以往的自动并行系统仅在训练前搜索最佳执行计划。SmartMoE则采用两阶段方法:
他们使用了更大的混合并行空间来搜索最优执行计划,并且把自动并行过程分为了两阶段:offline and online,具体见图4:
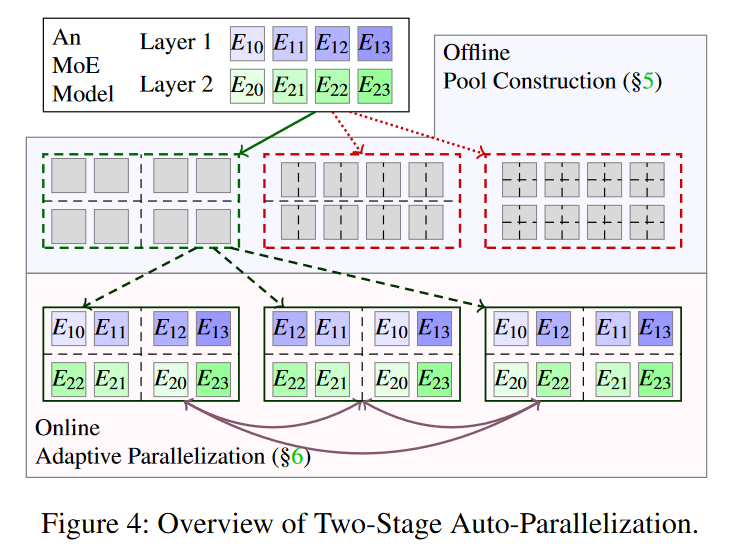
阶段1:offline pool construction
SmartMoE将一些执行计划划分为一个聚类,作为一个pool(一共就构建这一个),他们彼此之间进行切换的代价适中。该模型会在训练之前构建一个较好的pool,并使其保持在线适应能力。
怎么构建?设计了一个数据敏感的性能模型,利用模型规范来估计工作负载,然后再借助传统的搜索算法在运行前就划分出良好的pool。
此处为为池子选择合适的并行策略组合。
阶段2:online adaptive parallelization
阶段1使得在SmartMoE模型进行训练之前就找到一个良好的pool,但这个pool往往很大,在具体训练时候我们需要再极短的时间内在pool中选择出合适的execution plan(执行方案)。因此作者开发了轻量级算法来完成这个任务。
此处为:pool中给定的并行策略组合,expert placement有多种方案,在在线阶段,依据工作负载的不同,切换合适的expert placement。
4
SmartMoE支持混合并行:支持任意的 数据和张量,管道和expert并行,此外还支持expert placement(专家分布)
expert placement:通常指的是将具有不同领域知识和技能的专家(此处专家通常指具有特定领域知识或技能的实体,可以是机器学习模型、算法、软件程序,较少指人类专家等)或者算法分配到合适的任务或者问题上,以最大程度地发挥其潜力和效率。
SmartMoE使用“expert slot”概念来支持现有并行性的任意组合。专家槽为worker上存储专家子网络参数的基本单元。
"Expert slot"是一种在自然语言处理中使用的概念。它是指一个特定的语言模型中,专门用于识别特定类型的实体或信息的插槽。例如,一个旅游应用程序可能会使用一个专家插槽来识别用户输入中的日期、地点、酒店名称等信息。这些插槽可以帮助应用程序更好地理解用户的意图,并提供更准确的响应。
此处使用三个属性来表示专家槽的配置:
- 每个槽位的容量(Capacity):一个0到1的分数,表示存储了专家子网络的多少
- 每个worker上专家槽的数量(Slots):应该为正数。
- 每个worker上MoE层的数量(Layers)。
举例:假设有一个模型,有\(L\)层MoE层,每层MoE层有\(E\)个专家,训练在一个有\(N\)个worker的集群上,\(D、T、P\)分别代表数据,张量和管道并行方式,则表1展示了如何为不同的并行策略设置属性:
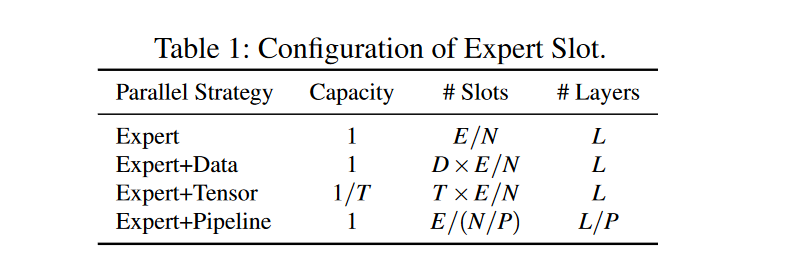
具体实例:\((L, E, N) = (2, 4, 4)\) ,两个MoE层,每层有4个专家,在有4个worker的集群上训练。
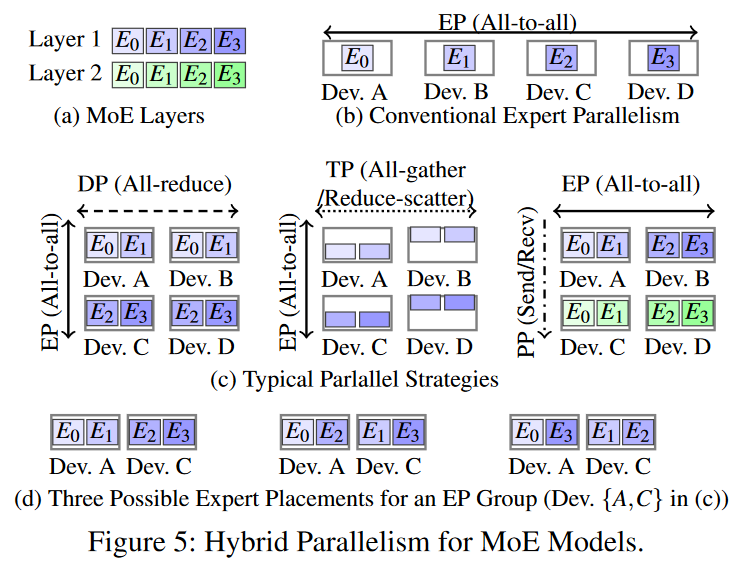
- EP:expert parallelism:专家并行:同时运行多个专家或者算法,每个专家或算法都负责处理任务的一部分,并在某种程度上独立工作。比如:在分布式计算中,多个计算节点(worker)可以并行地运行不同的任务,每个节点都具有一定的专业知识或者算法来处理特定类型的数据或问题。
- TP:task parallelism任务并行:任务并行是将一个大任务分解成多个较小的子任务,然后并行执行这些子任务的策略。每个子任务可以在不同的处理器核心、线程或计算节点上执行。这种并行策略特别适用于处理大规模数据集或执行多步骤的计算任务。此处应该指上文的Tensor Model parallelism
- DP:data parallelism数据并行:数据并行是将相同的操作应用于多个数据元素的并行策略。通常,多个处理单元会同时处理不同的数据元素,以加速数据处理过程。这种策略常见于并行计算中,如图像处理、矩阵运算等领域。
- PP:pipeline parallelism管道并行:管道并行是将一个任务分成多个阶段,每个阶段由不同的处理单元并行执行。每个处理单元完成其特定阶段的任务,然后将结果传递给下一个处理单元。这种策略通常用于流式数据处理,如编译器优化、音频处理和图像处理。
expert placement plan 指的是从专家子网络到专家槽的一个映射,如图5中的(d),专家槽中指明了设备A,C和则个紫色专家,图则说明了他们的3中不同分布方法。
5 offline pool constrution
5.1 design principle of a pool
- pool产生于训练之前,借助性能模型来完成pool的划分
- pool在整个训练过程中保持不变,在训练时在这个pool中切换执行计划
在SmartMoE中,作者将pool定义为一组执行计划,其中expert placement(这本质上是一种expert到设备dev的映射,即哪些专家放在哪些设备上)是唯一可变的并行策略。
SmartMoE在离线池构建阶段,寻找典型并行策略的优秀组合,在线阶段,再进行组合内部专家分布计划的切换。
优点
1: 灵活性高
2: 切换执行方案时候开销小。因为不同方案仅体现为expert placement的不同,他们具有相同的expert slot,切换时无需内存的变动,而仅需worker之间进行参数交换。
5.2 工作负载感知的性能模型 Workload-Aware Performance Modeling
性能模型使得在训练之前就能评估不同pool的性能,但动态工作负载使得我们在实际运行之前无法得知。
为此,建造了一个数据敏感型的性能模型。
因此要估计训练工作量:在训练之前估计专家选择的输出,具体来说,是估计门控(gating)网络(见下图2)的输出。
方法:我们得到门控网络具体算法后,能算出任何专家的最大工作量,我们就用每个专家的最大工作量,作为其实际工作量,然后来预测我们创建的pool的性能。
然后我们将该性能模型应用于候选池,并在开始分布式训练之前枚举搜索空间。
目前最先进的门控网络(gating networks)分为两类:
- load-balanced gating networks 负载均衡门控网络
保证expert的负载是均衡的。
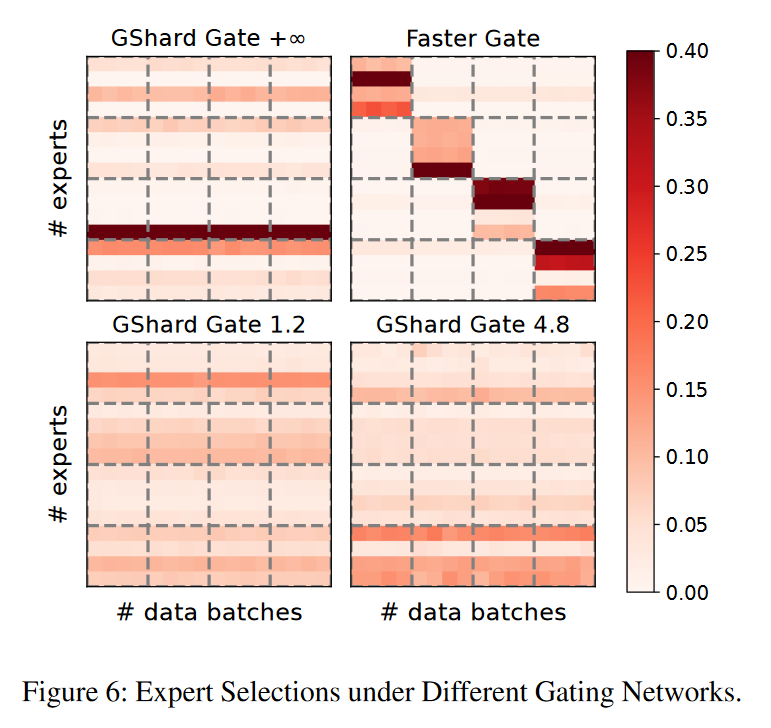
图6表示这种类型中典型的门控网络GShard的专家选择过程。
GShard门设计的关键是容量因子(capacity factor),它限制了分配给专家的训练样本比例。
如图6,容量因子分别设为\(+\infty\),1.2, 4.8,不同的容量因子会导致专家上不同的样本分配比例,我们因此可以算出任何专家的工作负载上限,然后把这个作为训练过程的瓶颈,来预测pool的性能。
- topology-aware gating networks 拓扑感知的门控网络。
其限制了all to all调度阶段跨节点通信的大小。
如图6右上角,faster Gate的可视化:这个例子聚类有16个设备,分布在4个节点上,为了避免跨节点的地带宽,它更喜欢将训练样本分配给同一节点内的专家,如图:大多数专家选择都是在对角线的4*4块中。
这第二种网络也没看懂
当我们获得完专家选择也就是门控网络的输出后,我们就可以利用现有的性能模型来估计执行计划的性能,并用估计的工作负载作为其输入(我觉得应该是每个专家都达到最大的工作负载)。并且由于训练开始前的时间较为充裕,因此我们可以采用多花一点时间来寻找具有作家估计性能的pool。
6 online adaptive Parallelization 在线自适应并行化
6.1 light-wight searching 轻量级搜索
贪心算法
首先,简化 expert placement problems:
假设有\(E\)个专家,\(N\)个设备,第\(i\)个专家被gating network分到了\(C_i\)个训练样本,我们就需要决定这些专家在对应设备上的分布,其中,用\(P_i\)表示第\(i\)个专家的位置,优化目标是最小化式:
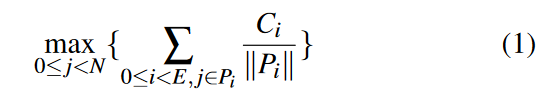
\(P_i\)是一个集合,里面只有一个元素,就是第i个专家分布在的设备的编号上。\(||P_i||\) 应该表示该集合中元素的个数,此处恒为1
\(\frac{C_i}{||P_i||}\)表示没看懂,先看算法,该算法1按照每个专家的计算量\(C_i\) .的降序来决定其位置,同时,为了避免增加某些设备上的内存开销,一台设备中放置的专家数量限制为\(\frac{E}{N}\) ,即不超过平均值。算法1的时间复杂度为\(O(NE)\)

总结:把工作量最大的expert尽可能分到目前总工作量最小的设备上。
6.2 Efficient adaptive training
我们通过启发式算法来调整这些参数:
Threshold of switching overhead 交换开销的阈值
针对不同的负载切换执行计划会带来通信开销。作者用一个阈值来筛选掉哪些对性能提升不大但会带来大的通信开销的方案。
Frequency of Online Searching 在线搜索的频率
由于神经网络参数变化在一定时间内不大,因此我们可以每隔几次迭代进行一次在线搜索。合适的频率通过实验来选择。
Frequency of History Collecting. 历史记录收集的频率
为了进行在线搜索,我们需要获得以往专家选择的历史。通过实验发现,仅在在线适应迭代之前的几次迭代中收集专家选择的历史记录即可。
7 评估
7.1 实验设置
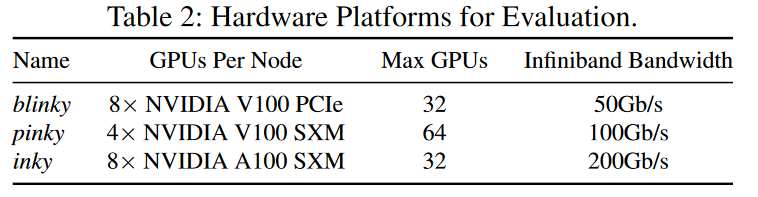
Clusters 实验在3个代表性集群上评估了SmartMoE,如下表:
Models 用于评估的模型如下表:
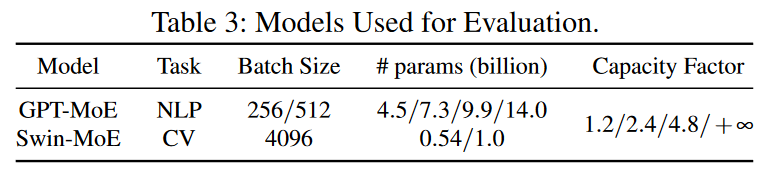
一个是用于NLP的GPT-MoE,一个是用于CV的Swin-MoE,门控网络用GShard(容量因子越小,工作负载越平衡)。应用具有不同容量因子的GShard门来评估我们的系统端优化。
Baseline SmartMoE与4个训练模型进行对比:DeepSpeed,Tutel,FasterMoE, Alpa。
Evaluation Metrics (评估指标)
7.2 End-to-end speedup
作者评估了两种模型在三个不同集群上端到端性能。\(X/Y\)表示对容量因子为Y的X台设备进行评估,结果如下:
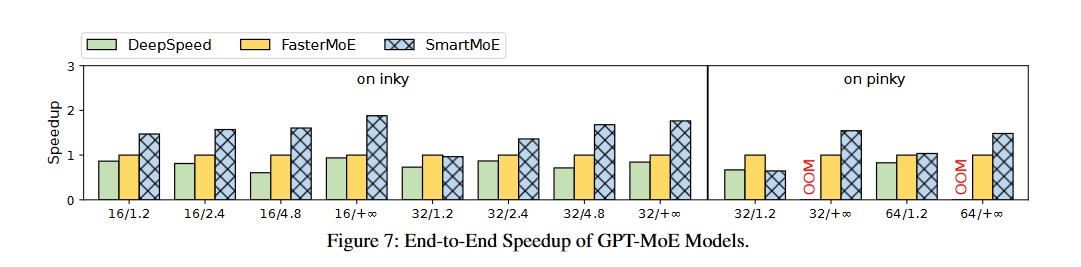
为什么inky上的效果更好呢?因为inky上节点间和节点内链路之间的带宽距更大,从而使得混合并行更加高效。而且inky在一个节点中有更多的Gpu,增加了可能得节点内并行策略。
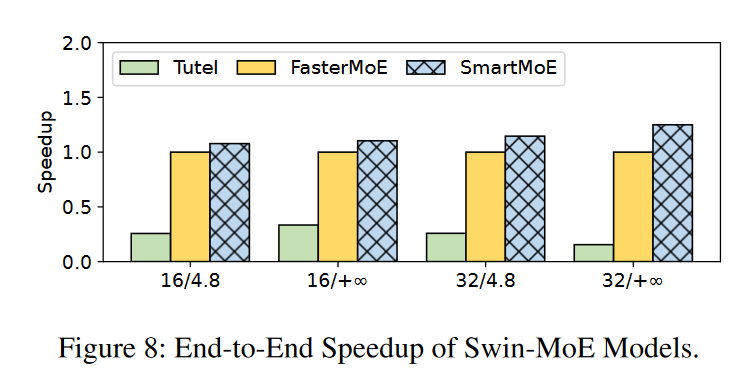
7.3 离线并行消融实验
Ablation Study(消融研究)是科学研究中的一种方法,通常用于评估系统或模型中各个组成部分的贡献或影响。这种方法在多个领域中都有应用,包括计算机科学、医学、地球科学等。
在计算机科学和机器学习领域,Ablation Study通常用于评估机器学习模型的性能,特别是在深度学习和神经网络中。它的基本思想是通过逐个去除或"消融"模型中的某些组件或特征,然后观察这些组件的去除对模型性能的影响。这有助于研究人员理解模型中不同组件的相对重要性,从而有助于改进模型的设计和性能。
例如,如果研究人员想要了解一个深度神经网络中不同层对最终分类性能的贡献,他们可以进行Ablation Study,逐层禁用或移除某些层,然后比较性能差异。这有助于确定哪些层对性能起关键作用,哪些层可以被简化或省略。
研究离线并行化算法的有效性
又做了一个实验,基线为FasterMoE,并且禁用了所有系统的在线优化,结果如下。
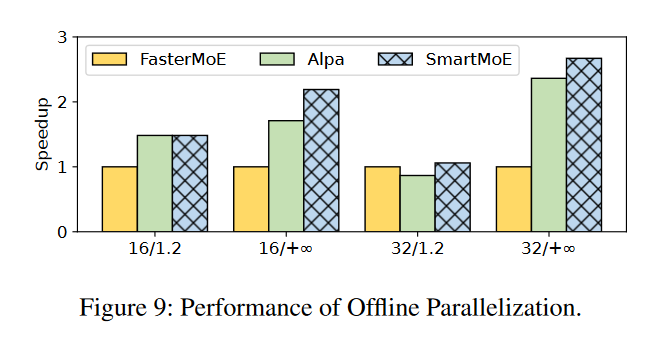
结果说明该模型可以找出效果优良的pool
然后图10表明了数据敏感性能模型的准确性:
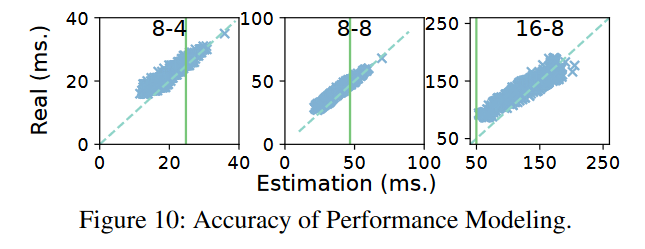
图中\(X-Y\)表示在本地批量大小为Y的X个设备上的评估。横坐标表示性能模型评估的结果,纵坐标表示真实的性能结果,可以发现点总是集中在\(y = x\)这条线上,结果较为准确。
7.4 在线并行消融研究
评估SmartMoE中自适应并行化方法的性能改进,
条件:MoE模型有16层;在pinky集群上研究。
执行计划的更改为每训练10轮更新一次。
下图显示了所有16个MoE层的加速比:
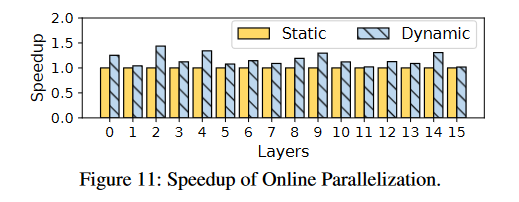
结论:MoE每层能实现1.16倍加速比,相比于不进行自适应并行化方法;第二层能有1.43倍的加速比。
另一个实验
下图显示了一个MoE层从迭代1-1500次的延迟。
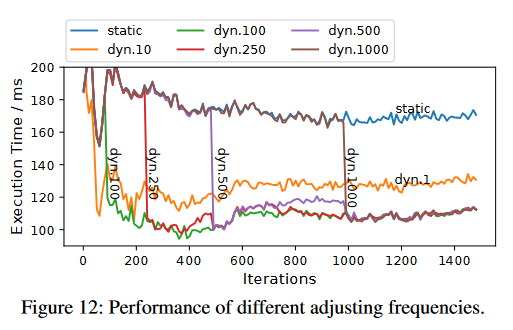
不同频率使用动态执行策略或者静态执行策略,并用曲线显示每轮执行时间。
图中\(dyn.X\) 表示每X次迭代切换执行计划。
结论:每当切换执行策略时候,训练用时会明显减少,切换频率并不是越高越好。
没解决的问题:如何设置适当的动态并行化频率。
7.5 细粒度的性能分解
结果在图13中:
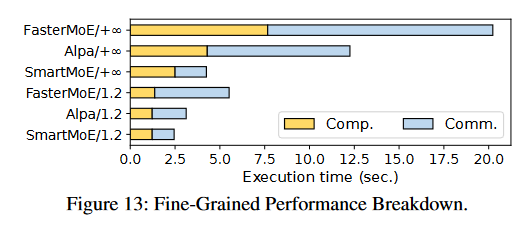
容量因子:
此术语通常用于GShard中,它是一种扩展巨型模型的技术,使用了条件计算和自动分片。容量因子是指MoE中每个专家的容量,也就是每个专家的参数量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号