
数据采集与融合技术实践2
数据采集与融合技术实践2
任务一
代码和图片
任务要求在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。根据浏览网址观察可发现,每个城市的数据保存在http://www.weather.com.cn/weather/{城市代码}.shtml 之中。于是我选定了北京,上海,广州,深圳这四个城市并查阅了城市代码,依次访问其url进行爬虫.

根据中国天气网的页面结构,7 日天气预报的数据都集中在一个 ul 标签中,其 class 为 "t clearfix"。解析时先定位到该 ul,再遍历其中的每个 li 元素。每个 li 都包含一条完整的天气信息:通过 li.find("h1") 获取日期;通过 li.find("p", class_="wea") 获取天气现象;通过 li.find("p", class_="tem") 获取温度信息,其中最高温位于 span 标签,最低温位于 i 标签。若页面中某一项缺失,则用空字符串代替,最后将高低温拼接成 "{high}/{low}" 的形式并去掉多余的斜杠。整个步骤的核心在于利用固定的 CSS 选择器配合简单的容错机制,只要网页结构不发生变化,就能稳定、准确地提取所需的天气数据。
这部分的代码为:
soup = BeautifulSoup(text, "lxml")
ul = soup.find("ul", class_="t clearfix")
lis = ul.find_all("li", recursive=False)
for li in lis:
try:
date_tag = li.find("h1")
date = date_tag.get_text(strip=True) if date_tag else ""
wea_tag = li.find("p", class_="wea")
weather = wea_tag.get_text(strip=True) if wea_tag else ""
tem_p = li.find("p", class_="tem")
hi = ""
lo = ""
if tem_p:
span_hi = tem_p.find("span")
i_lo = tem_p.find("i")
hi = span_hi.get_text(strip=True) if span_hi else ""
lo = i_lo.get_text(strip=True) if i_lo else ""
temp = (hi + "/" + lo).strip("/")
if date and weather and temp:
print(city, date, weather, temp)
save_row(cur, conn, city, date, weather, temp)
except Exception as e:
continue
提取结果:
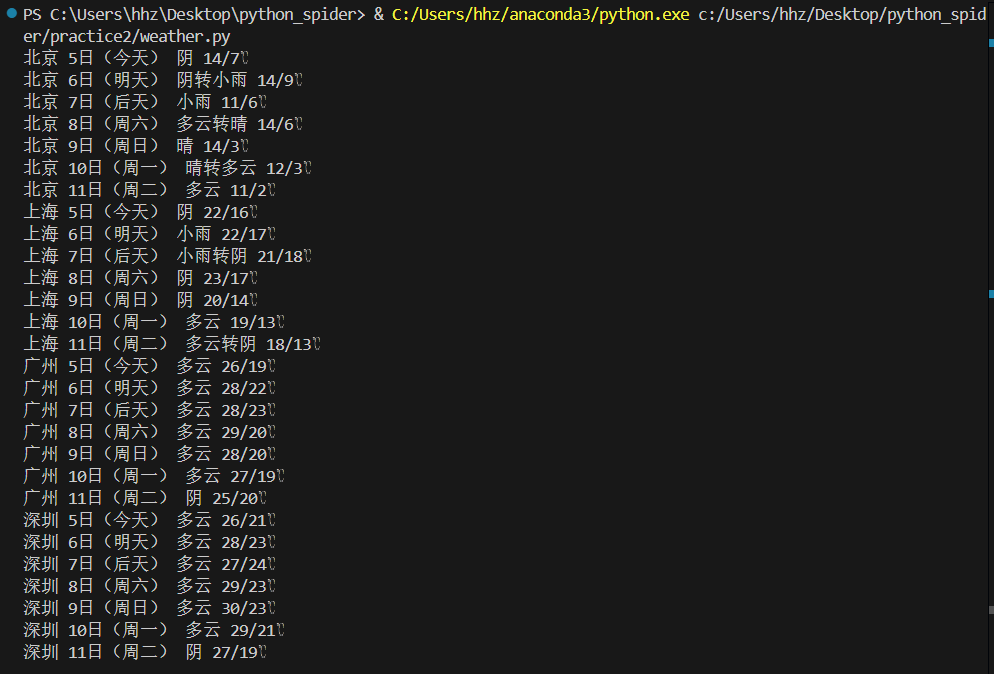
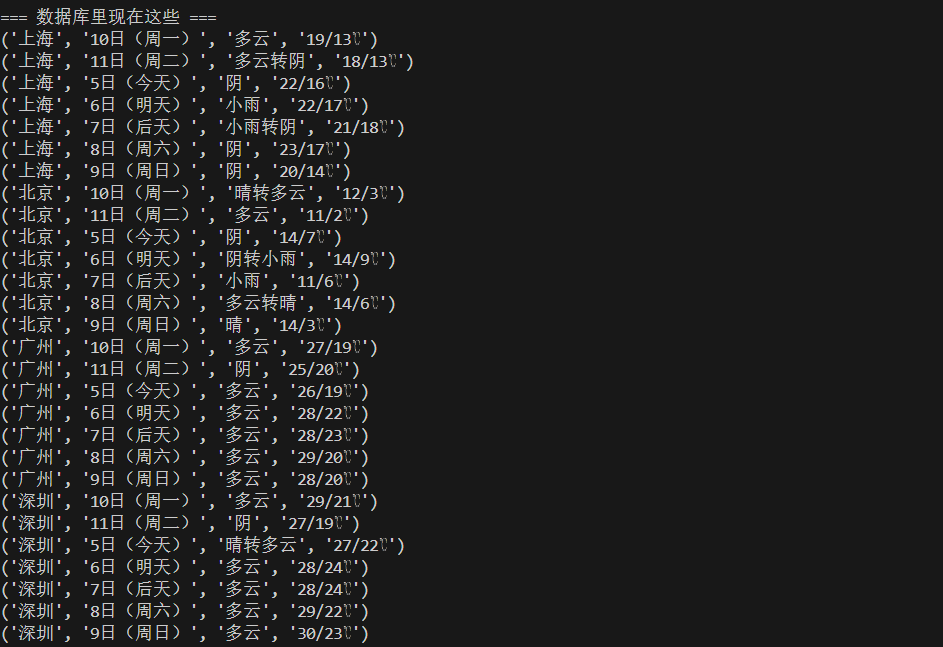
提取出数据后,用sqlit3保存在数据库里面里面
作业心得
这次的天气爬虫作业让我对爬虫的基本流程有了更直观的理解。通过使用 urllib.request 获取网页源码、用 BeautifulSoup 解析 HTML 结构并提取需要的信息,再利用 sqlite3 将数据保存到本地数据库,我体会到了爬虫的整个过程。同时在调试过程中也发现网页结构变化、编码问题等都会导致爬取失败,因此编写爬虫时要注意容错和延时。总体来说,这次实验帮助我掌握了网页数据抓取与持久化存储的基本方法。
任务二
代码和图片
任务要求用requests和json解析方法定向爬取股票相关信息,并存储在数据库中。我选择了东方财富(https://www.eastmoney.com/)作为爬取网站,首先,我找到了其中存取数据的请求指向的网址

由此我可以预览到数据

我使用固定的请求头模拟浏览器访问,循环分页请求接口,每页抓取一定数量的股票数据。接口返回后解析 JSON,从图片中我们可以看到,每一只股票相关的数据有很多,我们没必要每个数据都存下来,于是我从中提取了股票代码、名称、最新价、涨跌幅、涨跌额、成交量和成交额,构造成数据行写入数据库
相关代码为:
fields = "f12,f14,f2,f3,f4,f5,f6"
fs = (
"m%3A0%2Bt%3A6%2Bf%3A!2%2C"
"m%3A0%2Bt%3A80%2Bf%3A!2%2C"
"m%3A1%2Bt%3A2%2Bf%3A!2%2C"
"m%3A1%2Bt%3A23%2Bf%3A!2%2C"
"m%3A0%2Bt%3A81%2Bs%3A262144%2Bf%3A!2"
)
page_size = 20
base_url = (
"https://push2delay.eastmoney.com/api/qt/clist/get?"
"np=1&fltt=1&invt=2&"
"fs=m%3A0%2Bt%3A6%2Bf%3A!2%2Cm%3A0%2Bt%3A80%2Bf%3A!2%2Cm%3A1%2Bt%3A2%2Bf%3A!2%2C"
"m%3A1%2Bt%3A23%2Bf%3A!2%2Cm%3A0%2Bt%3A81%2Bs%3A262144%2Bf%3A!2&"
f"fields={fields}&fid=f3&pn={{pn}}&pz={{pz}}&po=1&dect=1&"
"ut=fa5fd1943c7b386f172d6893dbfba10b&wbp2u=%7C0%7C0%7C0%7Cweb"
)
pn = 1
while True:
url = base_url.format(pn=pn, pz=page_size)
r = requests.get(url, headers=headers)
data = r.json().get("data", {})
diff = data.get("diff", [])
if not diff:
break
rows = []
for item in diff:
row = (
item.get("f12"),# 代码
item.get("f14"),# 名称
item.get("f2"),# 最新价
item.get("f3"),# 涨跌幅
item.get("f4"),# 涨跌额
item.get("f5"),# 成交量
item.get("f6"),# 成交额
)
rows.append(row)
查询结果为:

作业心得
这次股票行情爬取作业让我进一步掌握了如何通过网络接口获取结构化数据并进行本地化存储。相比以往的网页爬虫,这次直接调用了东方财富网的行情 API,通过分析 URL 参数和字段编号,实现了批量抓取沪深股市实时数据。并且也学会了json的相关知识,掌握了变更api参数返回数据的能力
任务三
代码和图片
作业要求爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,首先我先对页面进行调试分析,过程如下:

由此,我找到了存储数据的url,接着先用 urllib.request 下载整段 JS 文本;接着用正则分别匹配 IIFE 的形参 function(a,b,...) 与末尾调用处的实参 (...)),然后再次用正则从 JS 中抓出 univData:[...] 这一整段数组文本,并把对象键后面出现的“变量名值”(形如 : varName)替换为前面映射到的字面量,完成替换后,用一个简单的正则把数组里每个学校对象({...})切分出来,再分别用小正则提取字段,比如学校名,排名,省份啥的。最后存到数据库
关键代码:
m_params = re.search(r"\(function\((.*?)\)", js, re.S)
m_args = re.search(r"\)\((.*)\)\);\s*$", js, re.S)
if not (m_params and m_args):
print("没找到 IIFE 结构,直接退出")
sys.exit(1)
param_names = [x.strip() for x in m_params.group(1).split(",") if x.strip() and x.strip() != "..."]
# 简单分割实参(逗号拆分,字符串里带逗号会有问题,这里就不考虑了)
raw_args = [x.strip() for x in m_args.group(1).split(",")]
def to_lit(s):
s = s.strip()
if s.startswith(("'", '"')) and s.endswith(("'", '"')): # 字符串
return s
if re.fullmatch(r"-?\d+(?:\.\d+)?", s): # 数字
return s
if s in ("true", "false", "null"):
return s
return "null"
vals = [to_lit(v) for v in raw_args]
while len(vals) < len(param_names):
vals.append("null")
mapping = dict(zip(param_names, vals[:len(param_names)]))
m_arr = re.search(r"univData\s*:\s*(\[[\s\S]*?\])", js)
if not m_arr:
print("未找到 univData 数组")
sys.exit(1)
arr_text = m_arr.group(1)
def rep_var(m):
key = m.group(2)
return m.group(1) + mapping.get(key, "null")
arr_text = re.sub(r'(:\s*)([A-Za-z_$][A-Za-z0-9_$]*)\b', rep_var, arr_text)
objs = re.findall(r"\{[^{}]*\}", arr_text)

作业心得
这次作业让我进一步理解了如何从网页 JavaScript 文件中提取结构化数据。最初我以为只能直接爬网页的 HTML,但通过分析 payload.js 文件,我学到了如何利用正则表达式定位函数形参与实参、建立变量映射关系,并通过字符串替换的方式把动态变量变成可直接读取的字面量。随后再提取其中的 univData 数组,对象化地解析出学校名称、排名、省份、类别和总分等信息。其中,我还遇到了直接打开url查看会出现乱码的问题。虽然整个过程略显繁琐,但让我熟悉了文本匹配、模式搜索和简单的数据反解析思路。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号