

结对第二次—文献摘要热词统计及进阶需求
作业格式
课程名称:软件工程1916|W (福州大学)
作业要求:结对第二次—文献摘要热词统计及进阶需求
结对学号:221600415-傅德泉 & 221600416-黄海山
代码签入记录
作业正文
一、分工情况
- 221600415-傅德泉
- 1、前期需求分析设计以及规划实现
- 2、PSP表开发规划
- 3、类图、流程图讨论设计
- 4、博客文档主要撰写
- 5、目标项目的用例测试
- 221600416-黄海山
- 1、前期需求分析设计以及规划实现
- 2、类图、流程图讨论设计
- 3、代码撰写,算法设计与程序功能的实现
- 4、项目性能分析
- 5、项目性能优化改进
二、PSP表
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 30 | 40 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 150 | 200 |
| · Design Spec | · 生成设计文档 | 50 | 60 |
| · Design Review | · 设计复审 | 30 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 40 | 20 |
| · Design | · 具体设计 | 100 | 90 |
| · Coding | · 具体编码 | 360 | 400 |
| · Code Review | · 代码复审 | 100 | 150 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 200 | 260 |
| Reporting | 报告 | ||
| · Test Repor | · Test Repor | 60 | 70 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 90 | 95 |
| * | 合计 | 1240 | 1425 |
三、解题思路描述
- 需求分析:刚拿到此次作业题目的时候,第一感觉是有点压力的,不过在和队友认真阅读,按点分析后,我们从宏观角度得到大概的需求框架:基础需求大概是实现一个命令行程序,将文本输入进行解析,得到文本里的字符数单词数量,有效行数以及top10高频单词等。将基本功能封装后用于进阶需求,对论文列表和指定文件进行统计操作。通过编程实现方法,将原来的大问题拆解成各个功能点,分块解决逐个击破。
- 实现思路:主要是利用BufferedReader读出文件的内容,然后用readLine按行读出文件,按照特定的分隔字符利用split函数判断合法性,统计字符数。接着用string类型的List存储单词,最后用map按字典序存储。而在统计字符数功能中,直接调用BufferedReader的read函数,对读取的字符直接操作。
- 存在的问题:在实现进阶需求时,爬虫功能之前一直没有接触过,但是通过上网学习,结合过去文档树相关知识点的认知,很快得到使用。
四、设计实现过程
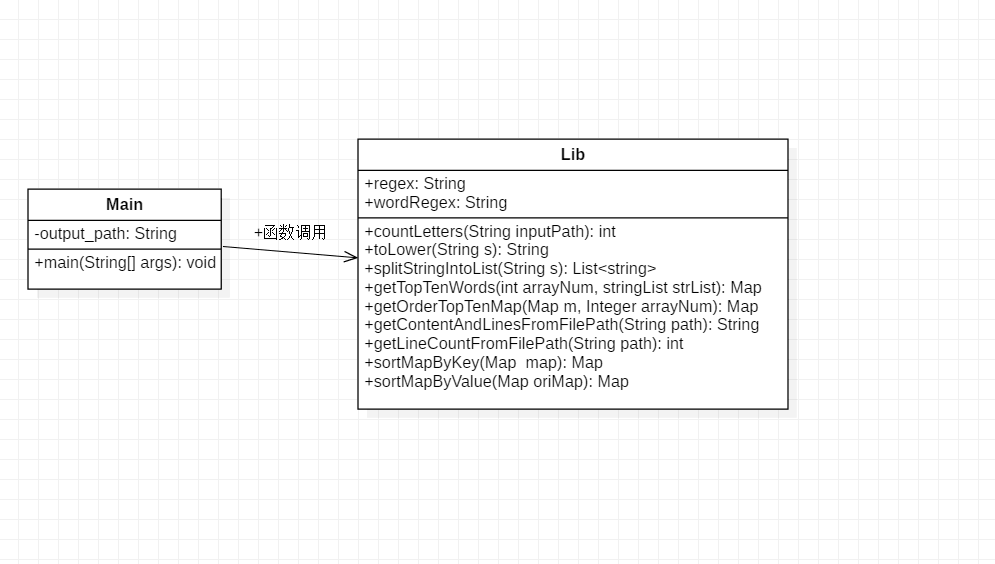
1、代码组织
- 基本需求
- 类的组织
|- src
|- Main.java(主程序,可以从命令行接收参数)
|- lib.java(包含多个其它自定义函数) - 函数组织
- countLetters 统计字符数
- splitStringIntoList 统计单词,调用转小写函数toLower
- getContentAndLinesFromFilePath 统计行数,获取文件内容成字符串,全转为小写
- getTopTenWords 统计前十字符,其中调用函数getOrderTopTenMap按频率和字典序排序,而在该函数中再次调用函数sortMapByKey和sortMapByValue,分别实现对Map按key和value进行排序
- 类的组织
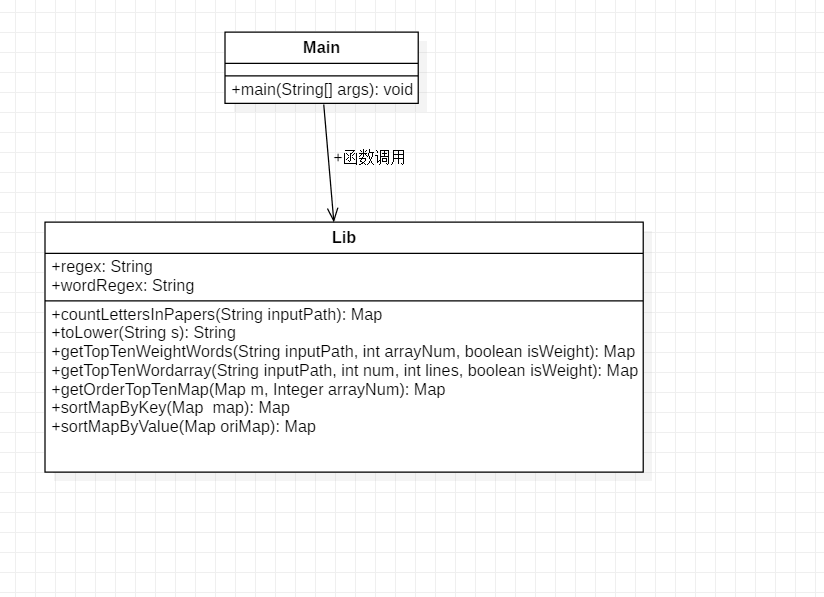
- 进阶需求
- 类的组织
|- cvpr(爬取论文列表,输出到result.txt)
|- src
|- Main.java(主程序,可以从命令行接收参数)
|- lib.java(包含多个其它自定义函数) - 函数组织
- countLettersInPapers 封装基础功能,在论文里统计字符数,行数,单词数。其中调用函数toLower 实现转小写包含数字的字符串
- getTopTenWeightWords 统计前十权重的单词,调用函数getOrderTopTenMap 使map按频率和字典序排序。该函数内部调用函数sortMapByKey和sortMapByValue,分别实现对Map按key和value进行排序
- getTopTenWordarray 统计前十的词组。函数调用同getTopTenWeightWords
- 类的组织
2、单元测试
- 测试思路:设定十种不同的临界输入,提前判断得出测试结果,通过对不同input文件进行算法运算获得输出,判断与预想结果是否一致
- 测试getTopTenWeightWords函数
- 测试countLettersInPapers函数
- 测试空白文件
- 测试文件不存在
- 测试单词数字开头的情况
- 测试大小写单词是否能识别
- 测试空白行是否识别
- 测试对\r\n的特殊输入进行
- 测试开头带有空格、tab的情形
- 测试带有空格,非字幕数字符号的分隔符
- 单元测试截图
3、代码组织与类图
- 基本需求
- 进阶需求
4、算法关键与关键实现部分流程图
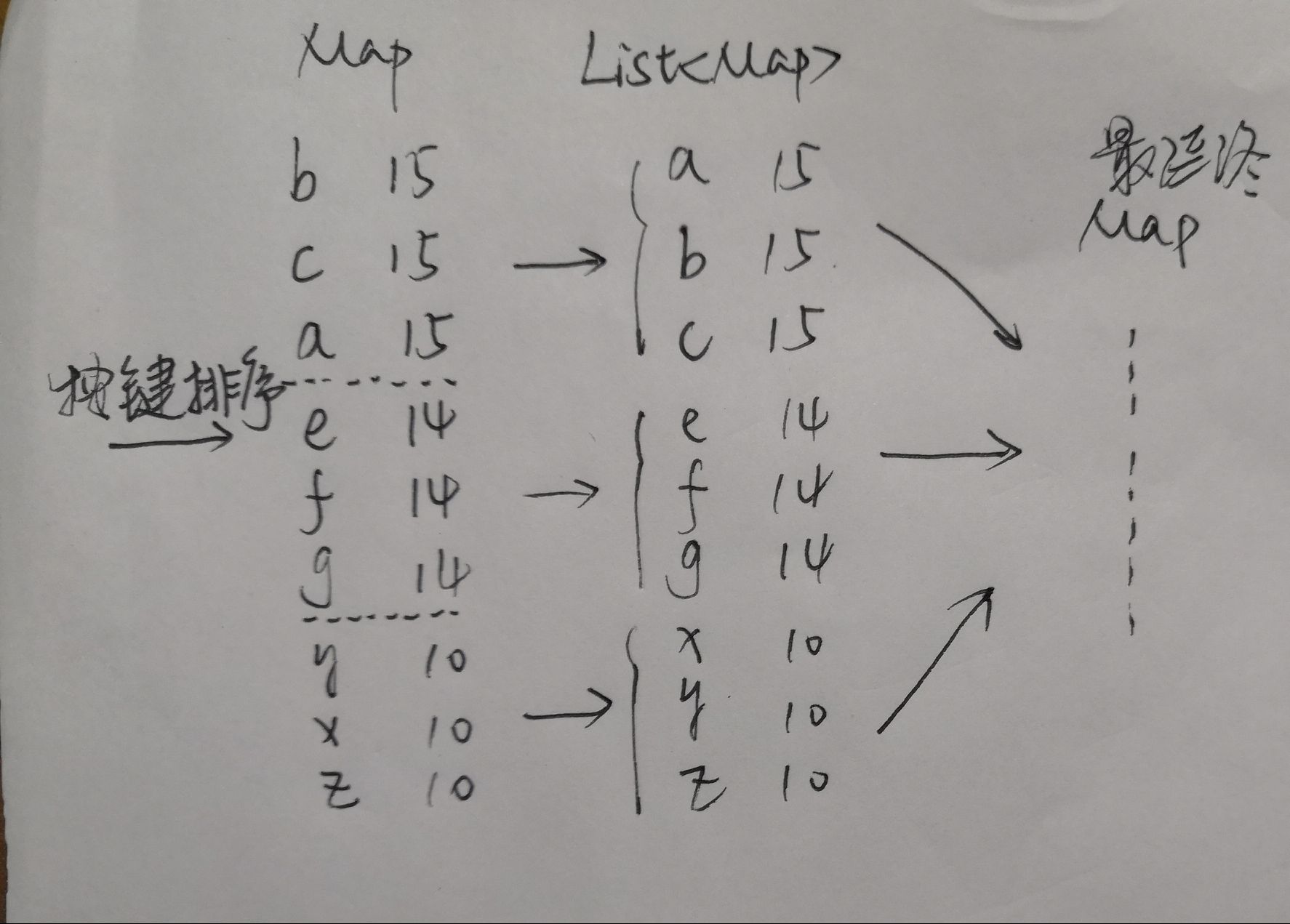
(算法的关键与关键实现部分流程图--map函数的函数设计)
- 关键函数:getOrderTopTenMap--按频率和字典序排序
- 实现原理:传入文本的单词数组,用map里的getOrDefaul函数统计所有单词的频率,然后将map数组按值排序,再把频率相同的map分别存到不同的子数组中,在对这些子数组里的map按key排序,在把每个子数组内的map合并到总map数组中。
- 算法思维图

五、性能分析与改进
1、改进花费时间:95min
2、改进的思路:
- 由于一开始是在执行splitStringIntoList(用正则表达式匹配空白符和非字母数字,将整个文本内容字符串切割为一个个单词)过程中,顺便用map存储合法单词,由于题目要求是要三个独立的接口,因此在调用getTopTenWords函数时是先执行了一次splitStringIntoList函数。改进后splitStringIntoList函数只用于统计单词个数,getTopTenWords则是先自行遍历一次文件,查找合法单词后,进行后续操作。
- 此外,刚开始对文件内容的读取也存在一定功能冗余:统计字符函数、统计单词总数函数和统计有效行三个功能彼此独立,导致在计算过程中需要对输入读取三次,致使时间资源的浪费。后来通过将文件读取到内存中,只进行一次输入操作,从而节省代码开销。
3、性能分析图
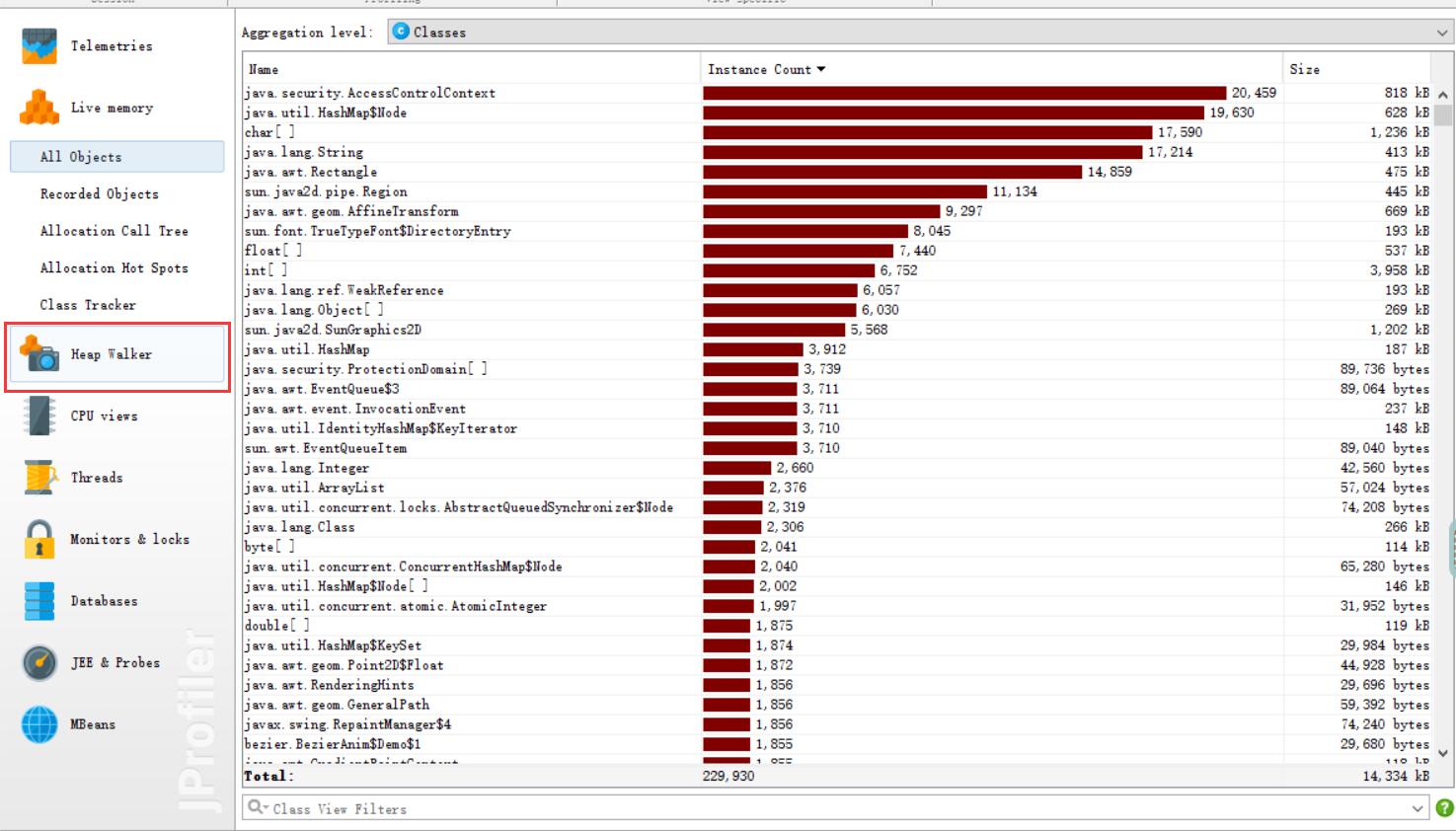

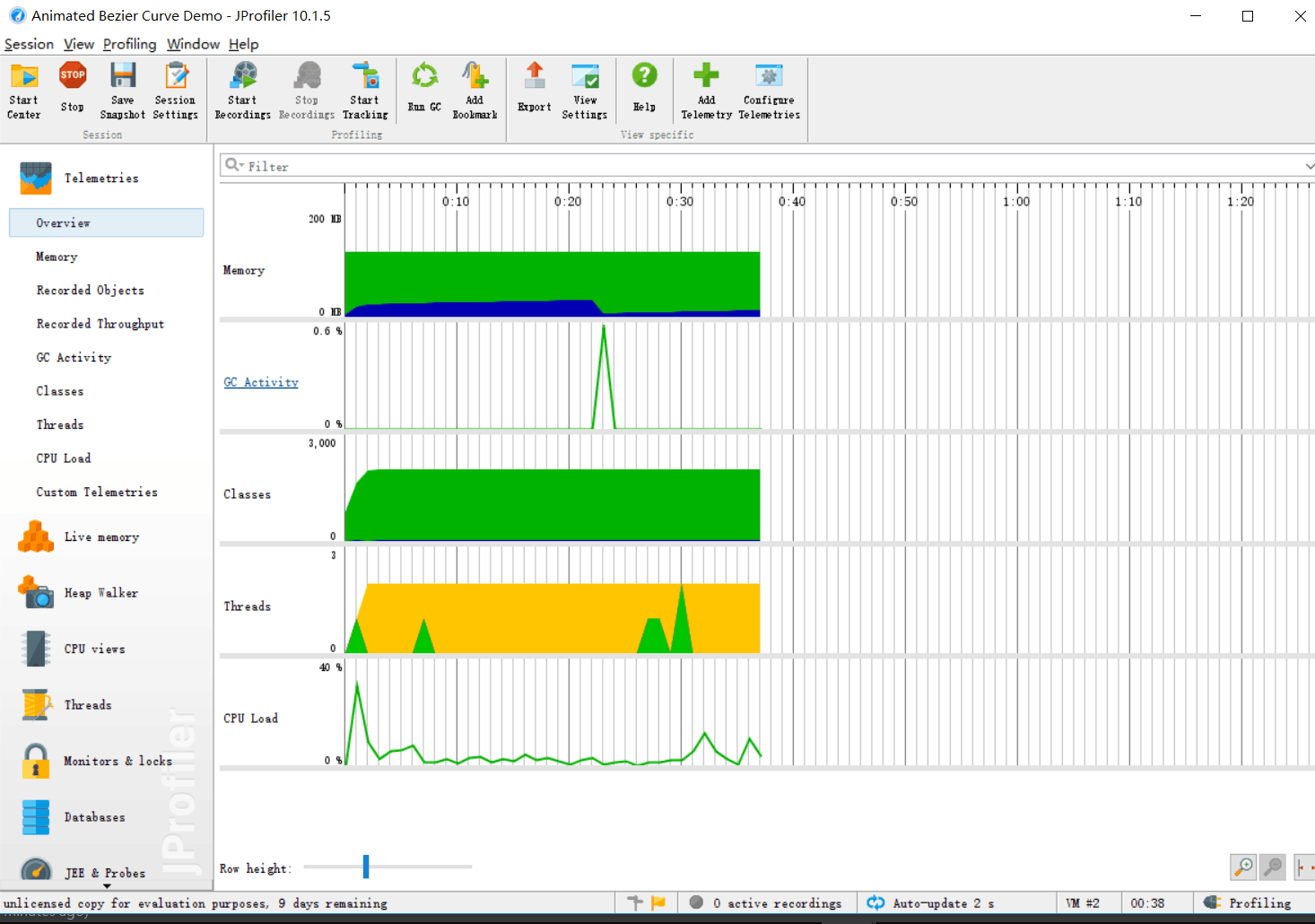
4、消耗最大的函数
- map按频率和字典序排序函数-- getOrderTopTenMap
六、关键代码
1、基础需求
- map按频率和字典序排序。传入文本的单词数组,用map里的getOrDefaul函数统计所有单词的频率,然后将map数组按值排序,再把频率相同的map分别存到不同的子数组中,在对这些子数组里的map按key排序,在把每个子数组内的map合并到总map数组中,从而实现题目需求。
public Map<String,Integer>getOrderTopTenMap(Map<String, Integer>m,Integer arrayNum){
Map<String, Integer> map=sortMapByValue(m);//通过Value排序;
int order=0;
int numInten=0;
for(Integer item:map.values()){
++order;
if(order==arrayNum){
numInten=item;
}
}
Iterator<Map.Entry<String, Integer>> it = map.entrySet().iterator();
while(it.hasNext()){
Map.Entry<String, Integer> entry = it.next();
if(entry.getValue()<numInten)
it.remove();//使用迭代器的remove()方法删除元素
}
Set<Integer> valueSet=new TreeSet<>();//有序
for(String key:map.keySet()){//看看有几种值结果
valueSet.add(map.get(key));
}
Map<Integer,Integer> sameMap=new HashMap<>();//每种结果有多少个
for(Integer value:valueSet){
for(String key:map.keySet()){
if(map.get(key)==value){
sameMap.put(value,sameMap.getOrDefault(value,0)+1);
}
}
}
//相同频率拆段
List<Map<String,Integer> > mapList=new ArrayList<>();
for(Integer item:valueSet){
Map<String,Integer> mapItem=new HashMap<>();
for(String s:map.keySet()){
if(map.get(s)==item){
mapItem.put(s,map.get(s));
}
}
mapList.add(mapItem);
}
List<Map<String,Integer> > mapList2=new ArrayList<>();
//频率相同排序
for(int i=mapList.size()-1;i>=0;--i){//set升序,频率最高的段在后面
mapList2.add(sortMapByKey(mapList.get(i)));
}
Map<String,Integer>result=new LinkedHashMap<>();
int num=0;
for(int i=0;i<mapList2.size();++i){
for(String key: mapList2.get(i).keySet()){
++num;
if(num<=arrayNum)
result.put(key,mapList2.get(i).get(key));
else
break;
}
}
return result;
}
2、进阶需求
- 爬取论文信息主函数,通过对网页DOM树的操作,获取页面信息节点
public static void main(String args[]) throws IOException {
Document doc=Jsoup.connect(URL).maxBodySize(0).get();
Elements elements=doc.getElementsByClass("ptitle").select("a");
BufferedWriter bw=new BufferedWriter(new OutputStreamWriter(new FileOutputStream(new File(STORE_NAME))));
int index=0;
System.out.println("start");
for(Element e : elements){
String href=e.attr("href");
System.out.println(index+":"+href);
String title=e.text();
String text=Jsoup.connect(URL_PRE+href).get().getElementById("abstract").text();
bw.write(String.valueOf(index));
bw.write("\r\n");
bw.write("Title: "+title+"\r\n");
bw.write("Abstract: "+text+"\r\n\r\n");
++index;
}
bw.flush();
bw.close();
System.out.println("end");
}
- 统计前十权重单词,传入boolean类型的isWeight参数判断是否需要对单词进行权重统计,之后按照基础篇对单词进行排序的思想处理输入。
public Map<String,Integer> getTopTenWeightWords(String inputPath,int arrayNum,boolean isWeight)throws Exception{
Map<String,Integer> map=new HashMap<>();
FileInputStream fileInputStream=new FileInputStream(new File(inputPath));
InputStreamReader inputStreamReader=new InputStreamReader(fileInputStream);
BufferedReader br = new BufferedReader(inputStreamReader);
String itemStr;
while((itemStr=br.readLine())!=null){
if(itemStr.startsWith("Title:")||itemStr.startsWith("Abstract:")){
String[] strList=itemStr.split(regex);
int weight=1;
if(strList[0].equals("Title")){
if(isWeight){
weight=10;
}
}
else if(strList[0].equals("Abstract"))
weight=1;
for(int i=1;i<strList.length;++i){
String key=strList[i];
if(key.matches(wordRegex)){//是一个单词
key=toLower(key);
map.put(key,map.getOrDefault(key,0)+weight);
}
}
}
}
br.close();
return getOrderTopTenMap(map,arrayNum);
}
- 统计前十的数组。将数组里的元素拼接为一个字符串,之后按照基础篇中对单词进行排序的思路排序数组。
public Map<String,Integer> getTopTenWordarray(String inputPath,int num,int lines,boolean isWeight)throws Exception{
Map<String,Integer> map=new HashMap<>();
FileInputStream fileInputStream=new FileInputStream(new File(inputPath));
InputStreamReader inputStreamReader=new InputStreamReader(fileInputStream);
BufferedReader br = new BufferedReader(inputStreamReader);
String itemStr;
while((itemStr=br.readLine())!=null){
if(itemStr.startsWith("Title:")||itemStr.startsWith("Abstract:")){
String[] strList=itemStr.split(regex);
int weight=1;
if(strList[0].equals("Title")){
if(isWeight){
weight=10;
}
for(int i=1;i<strList.length;++i){
boolean isArray=true;
StringBuilder sb=new StringBuilder();
int j;
for(j=i;j<i+num&&j<strList.length;++j){
String key=strList[j];
key=toLower(key);
if(!key.matches(wordRegex)){//遇到无效单词
i=j;
isArray=false;
break;
}
else{
if(sb.length()>0){
sb.append(" "+key);
}
else{
sb.append(key);
}
}
}
if(isArray&&j==num+i) {
map.put(sb.toString(), map.getOrDefault(sb.toString(), 0) + weight);
}
}
}
else if(strList[0].equals("Abstract")){
weight=1;
for(int i=1;i<strList.length;++i){
boolean isArray=true;
StringBuilder sb=new StringBuilder();
int j;
for(j=i;j<num+i&&j<strList.length;++j){
String key=strList[j];
key=toLower(key);
if(!key.matches(wordRegex)){//遇到无效单词
i=j;
isArray=false;
break;
}
else{
if(sb.length()>0){
sb.append(" "+key);
}
else{
sb.append(key);
}
}
}
if(isArray&&j==num+i){
map.put(sb.toString(), map.getOrDefault(sb.toString(), 0) + weight);
}
}
}
}
}
br.close();
return getOrderTopTenMap(map,lines);
}
七、单元测试
- 测试程序实例
@Test
public void test1(){
String input_path="src\\input1.txt";
try{
//基本需求
Lib lib=new Lib();
String contentStr=lib.getContentAndLinesFromFilePath(input_path);
List<String> wordList=lib.splitStringIntoList(contentStr);
Integer lines=lib.getLineCountFromFilePath(input_path); //有效行数
Integer characters=lib.countLetters(input_path); //字符数
Integer words=wordList.size(); //单词总数
Map<String,Integer> map=lib.getTopTenWords(wordList,10);
String topWords ;//频率最高单词
for(String key:map.keySet()){
topWords="<"+key+">: "+map.get(key)+"\r\n";
}
String testChar="characters: 102";
String testWords="words: 2";
String testLines="lines: 2";
String testTopWords="<abcdefghijklmnopqrstuvwxyz>: 2";
assertEquals(testChar,characters);
assertEquals(testWords,words);
assertEquals(testLines,lines);
assertEquals(testTopWords,topWords);
}
catch (Exception e){
e.printStackTrace();
}
}
- 部分测试数据
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~
\t\n
测试结果:
characters: 102
words: 2
lines: 2
<abcdefghijklmnopqrstuvwxyz>: 2
abcdefghijklmnopqrstuvwxyz
1234567890
,./;'[]\<>?:"{}|`-=~!@#$%^&*()_+
测试结果:
characters: 76
words: 1
lines: 3
<abcdefghijklmnopqrstuvwxyz>: 1
- 测试思路:设定不同的临界输入,如:空白文件、文件不存在、以单词数字开头等情况,提前判断得出测试结果,通过对不同input文件进行算法运算获得输出,判断与预想结果是否一致。具体测试内容回见“四-2”。
八、困难与解决方法
- 在最初的需求分析上花费了较长的时间,一些需求没有分析到位导致后来在实现过程中出现遗漏,再补充起来就需要对已实现的代码进行修改。下次在动手前还是需要和队员更加深入的进行讨论。
- 一些以前没接触过的知识在此次编程中需要及时学习,如爬虫的使用和算法的性能分析。在及时上网,交流掌握技能的同学,渐渐学到新的实用技能。
九、项目小结
1、队友评价
- 221600416-黄海山
在和德泉队友合作的过程中,我觉得我的队友是一个性格温和,擅于沟通交流的人,不管是阅读文档还是沟通理解的能力都是极强,最让我感动的是,我的队友责任心极强,在自己还有许多学生工作要完成的同时,还能够熬夜写文档,及时并且高质量地完成作业任务,这实在是一种难能可贵的品质。总的来说,这是一次愉快的合作经历。
- 221600415- 傅德泉
我的队友黄海山,编程能力极强,完成了此次作业主要程序的撰写。在需求分析阶段,能较好的相互交流,尊重彼此的看法,使得后边的工作进展顺利。最后在文档撰写环节,也能认真交流算法的实现过程,为后期测试打好基础,总而言之合作过程十分顺利。
2、个人心得
- 221600416-黄海山
在这次作业开始之前,我曾被这次作业如此多的需求和所要完成的巨大工作量所困惑,但是困难摆在眼前,我顾不得去抱怨什么,更加不能因为有困难而轻易放弃,于是我不得不开始认真思考如何着眼去解决这个问题,经过对作业需求认真地阅读和分析后,我发现这次的作业看似繁多的需求其实是由一个个小问题组成的,而有一部分问题的解答是有重复的,比如作业中对单词频率的统计,单词权重的统计,数组频率的统计,数组权重的统计都可以归类为一个map排序的问题,而其他诸如单词,字符的统计等都是熟悉的文件读写问题,经过如此分析后,就大大减少了原来的工作量。经过一天多的认真编程后,我和队友完成了对作业需求的实现和初步测试,又经过一段时间的修改和测试,认真比对作业需求,终于完成了这次作业。在编写这次作业的过程中,我最大的收获就是加强了阅读文档的能力,拆分复杂问题的能力。当然,在和队友的讨论过程中,也加强了沟通交流的能力。
- 221600415-傅德泉
此次作业需求量大,锻炼到了自身需求分析的能力。在于队友的沟通交流中,发现自己对于代码的理解能力也有所提升,同时还接触了代码测试的较专业的方式。此外,回顾了类图和流程图的绘制方法,更加深入的掌握了该项能力。在撰写文档的过程中,体会到了一个程序的全面性,应该从多个地方进行考评。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号