07 Spark RDD编程 综合实例 英文词频统计
1. 用Pyspark自主实现词频统计过程。
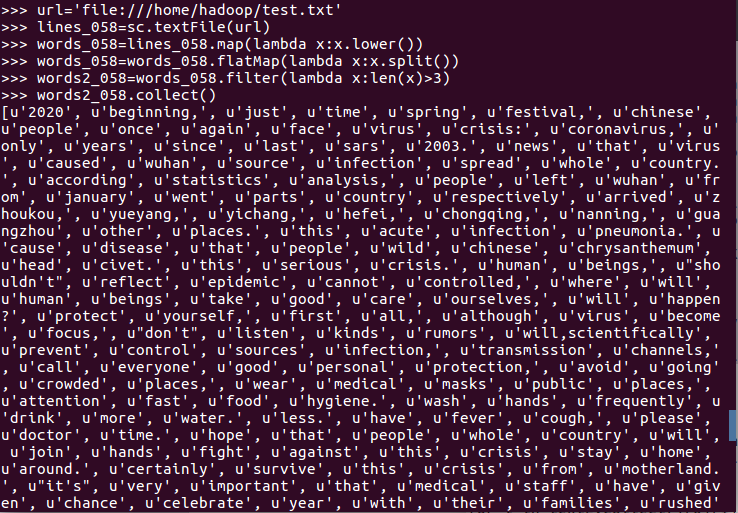
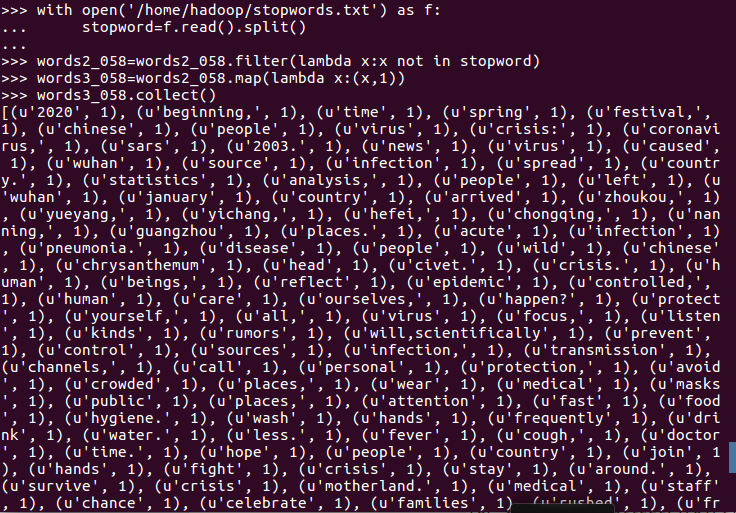
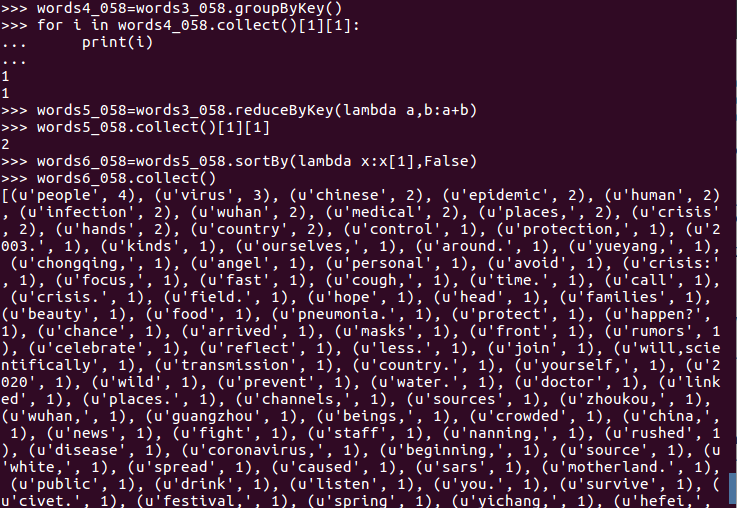
2. 并比较不同计算框架下编程的优缺点、适用的场景。
–Python
–MapReduce
–Hive
–Spark
1.python
Python 特点:面向对象
Python 既支持面向过程编程,也支持面向对象编程。在“面向过程”的语言中(如 C 语言),程序仅仅是由可重用代码的函数构建起来的;而在“面向对象”的语言(如 C++)中,程序是由数据和功能组合而成的对象构建起来的。
与其他编程语言(如 C++ 和 Java)相比,Python 是以一种非常强大,而又简单的方式实现的面向对象编程。
Python 特点:强大的功能
Python 强大的功能也许才是很多用户支持 Python 的最重要的原因,从字符串处理到复杂的 3D 图形编程,Python 借助扩展模块都可以轻松完成。
实际上,Python 的核心模块已经提供了足够强大的功能,使用 Python 精心设计的内置对象可以完成许多功能强大的操作。
2.Mapreduce
写Mapreduce进行数据处理,需要利用java、python等语言进行开发调试,没有可视化操作界面来的那么方便,在性能优化方面,常见的有在做小表跟大表关联的时候,可以先把小表放到缓存中(通过调用Mapreduce的api),另外可以通过重写Combine跟Partition的接口实现,压缩从Map到reduce中间数据处理量达到提高数据处理性能。
3.Hive
在没有出现下面要说的Spark之前,Hive可谓独占鳌头,涉及离线数据的处理基本都是基于Hive来做的,早期的阿里的云梯1就是充分利用Hive的特性来进行数据处理Hive采用sql的方式底层基于Hadoop的Mapreduce计算框架进行数据处理,所以他的优化方案很多,常见的场景比如数据倾斜,当多表关联其中一个表比较小,可以采用mapjoin,或者设置set hive.groupby.skewindata=true等,当碰到数据量比较大的时候,可以考虑利用分桶,分区(分为静态分区,动态分区)进行数据重新组织存储,这样在利用数据的时候就不需要整表去扫描,比如淘宝常常对一个业务场景利用不同算法进行营销活动,每个算法的营销活动可以存放到不同的分桶中,这样统计数据的时候就会提高效率。对于hive的性能优化我后面会有一个专题进行介绍,这里只简单提一下常用的场景。
4.Spark
Spark基于内存计算的准Mapreduce,在离线数据处理中,一般使用Spark sql进行数据清洗,目标文件一般是放在hdf或者nfs上,在书写sql的时候,尽量少用distinct,group by reducebykey 等之类的算子,要防止数据倾斜。在优化方面主要涉及配置每台集群每台机器运行task的进程个数,内存使用大小,cpu使用个数等。从我个人的角度来看,我觉得spark sql跟上面所说的hive sql差不多,只不过spark sql更加倾向于内存处理。但是他不具有较强的模板话,如果修改里面逻辑要重新编译调试运行,比较适合改动比较小的业务场景,比如数据仓库模型中ods,dwd层的数据处理。因为这两层都是宽表级别的粗处理,目的很简单旨在数据最优存储支撑上层ads层报表开发。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号