
上机实验4——列表与字典应用
目的 :熟练操作组合数据类型。
实验任务:
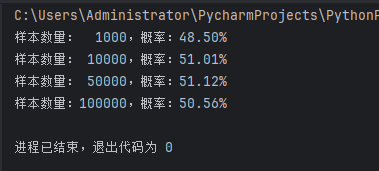
- 基础:生日悖论分析。如果一个房间有23 人或以上,那么至少有两个人的生日相同的概率大于50%。编写程序,输出在不同随机样本数量下,23 个人中至少两个人生日相同的概率。
- 进阶:统计《一句顶一万句》文本中前10 高频词,生成词云。
- 拓展:金庸、古龙等武侠小说写作风格分析。输出不少于3个金庸(古龙)作品的最常用10 个词语,找到其中的相关性,总结其风格。
1 基础
import random
def birthday_probability(sample_size, num_people=23):
"""计算在指定样本数量下,至少两个人生日相同的概率"""
success = 0
for _ in range(sample_size):
birthdays = set()
for _ in range(num_people):
day = random.randint(1, 365)
if day in birthdays:
success += 1
break
birthdays.add(day)
return success / sample_size
def main():
# 测试不同的样本数量
sample_sizes = [1000, 10000, 50000, 100000]
for size in sample_sizes:
prob = birthday_probability(size)
print(f"样本数量:{size:6},概率:{prob:.2%}")
if __name__ == "__main__":
main()
运行结果;
2 进阶
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from collections import Counter
import imageio
# 1. 读取文本文件
def read_text(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
# 2. 中文分词处理
def process_text(text):
stopwords = set()
with open('stopwords.txt', 'r', encoding='utf-8') as f:
for line in f:
stopwords.add(line.strip())
# 使用jieba分词
words = jieba.lcut(text)
# 过滤停用词和非中文字符
filtered = [
word for word in words
if len(word) > 1
and '\u4e00' <= word <= '\u9fff'
and word not in stopwords
]
return filtered
# 3. 统计高频词
def get_top_words(words, top_n=10):
word_counts = Counter(words)
return word_counts.most_common(top_n)
# 4. 生成词云
def generate_wordcloud(words):
wc = WordCloud(
font_path='msyh.ttc', # 中文字体文件
background_color='white',
max_words=200,
max_font_size=100
)
word_freq = dict(Counter(words))
wc.generate_from_frequencies(word_freq)
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()
# 主程序
if __name__ == "__main__":
text = read_text('yijudingyiwanju.txt')
words = process_text(text)
# 输出前10高频词
top_10 = get_top_words(words)
print("前10高频词:")
for word, count in top_10:
print(f"{word}: {count}次")
# 生成词云
generate_wordcloud(words)
运行结果:


3 拓展
import jieba
import os
from collections import Counter
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
# 配置部分
AUTHORS = {
"金庸": ["ldj", "tlbb", "sdyxz"],
"古龙": ["dqjkwqj", "qxlw", "lxfcq"]
}
STOPWORDS_PATH = "stopwords.txt"
CUSTOM_WORDS = ["说道", "一声", "只见", "心中"] # 需过滤的通用动词
# 核心函数
def load_corpus(author):
"""加载指定作者所有作品文本"""
corpus = []
for book in AUTHORS[author]:
path = f"{author}作品集/{book}.txt"
with open(path, 'r', encoding='utf-8') as f:
corpus.append(f.read())
return " ".join(corpus)
def process_text(text):
"""文本处理流程"""
# 加载停用词
with open(STOPWORDS_PATH, 'r', encoding='utf-8') as f:
stopwords = set(f.read().splitlines())
stopwords.update(CUSTOM_WORDS)
# 精准分词+过滤
words = jieba.lcut(text)
return [
word for word in words
if len(word) > 1
and '\u4e00' <= word <= '\u9fff'
and word not in stopwords
]
def analyze_author(author):
"""分析单个作者词频"""
text = load_corpus(author)
words = process_text(text)
return Counter(words)
# 分析执行
if __name__ == "__main__":
# 词频统计
jinyong_counts = analyze_author("金庸")
gulong_counts = analyze_author("古龙")
# 获取前10高频词
top_jy = [item[0] for item in jinyong_counts.most_common(10)]
top_gl = [item[0] for item in gulong_counts.most_common(10)]
# 相关性分析
common_words = set(top_jy) & set(top_gl)
jy_unique = set(top_jy) - common_words
gl_unique = set(top_gl) - common_words
# 配置中文字体(关键修改部分)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 确保负号正常显示
# 可视化
plt.figure(figsize=(12, 6))
# 金庸词频分布
plt.subplot(121)
jy_words, jy_freq = zip(*jinyong_counts.most_common(10))
plt.barh(range(10), jy_freq, color='#FF6F61')
plt.yticks(range(10), jy_words)
plt.title("金庸作品高频词")
# 古龙词频分布
plt.subplot(122)
gl_words, gl_freq = zip(*gulong_counts.most_common(10))
plt.barh(range(10), gl_freq, color='#6B5B95')
plt.yticks(range(10), gl_words)
plt.title("古龙作品高频词")
plt.tight_layout()
plt.show()
# ======== 风格分析报告 ========
print("共性特征:", "、".join(common_words))
print("金庸特色:", "、".join(jy_unique))
print("古龙特色:", "、".join(gl_unique))
运行结果:
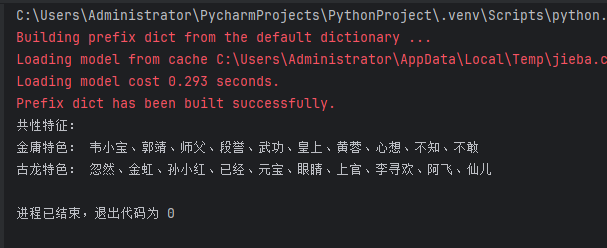
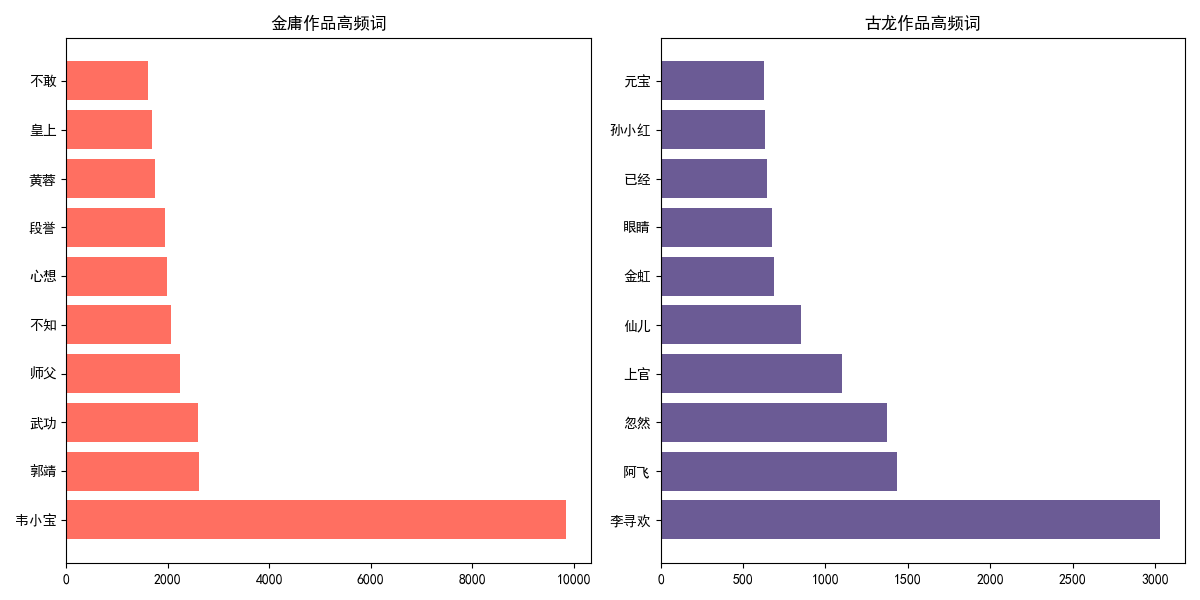
结果说明:
- 金庸小说风格:高频词如“黄蓉”“段誉”“郭靖”“韦小宝”等体现出其作品注重人物群像塑造,角色性格鲜明且具有代表性;“武功”一词突显对武侠世界中武功体系的细致刻画;“皇上”暗示故事常涉及江湖与宫廷的交织,情节宏大复杂,整体风格偏向于构建严谨、丰富的武侠世界,人物命运与江湖、家国紧密相连。
- 古龙小说风格:高频词如“李寻欢”“阿飞”“上官”等人物名字,展现出其对个性独特的江湖人物的着重刻画;“忽然”体现情节多意外转折,充满悬念;“眼睛”等词暗示对人物神态、情感的细腻捕捉。整体风格上更强调人物内心世界与情感纠葛,情节奇诡多变,语言简洁而富有张力,营造出独特的江湖氛围与情感冲突。
综上,通过高频词可看出:金庸笔下的江湖宏大规整,人物与家国、江湖规则紧密相连;古龙笔下的江湖则更具个人化、情感化与奇诡性,突出人物个性与情节的跌宕。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号