


第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC

2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
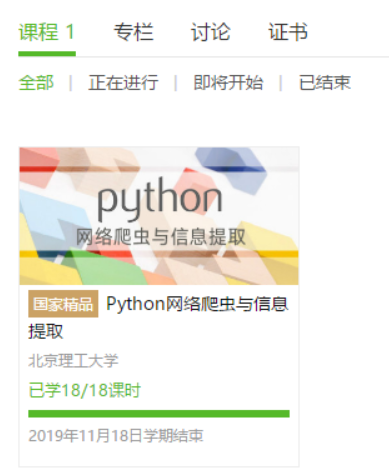
3.学习完成第0周至第4周的课程内容,并完成各周作业

4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
学习的体会和收获
第一次学习的是Python爬虫,网上有很多很多关于这一类东西的教程,我也仅仅是可以实现,并且停留在一知半解的程度,在代码过程中添加了很多对Python的新的理解,对编程这个大集合的更深层的理解。 在学习第0周的时候,老师主要介绍了Python网络爬虫也叫做网络机器人,可以代替人们自动地在互联网中进行数据信息的采集与整理。在大数据时代,信息的采集是一项重要的工作,如果单纯靠人力进行信息采集,不仅低效繁琐,搜集的成本也会提高。在很多领域都运用到这问技术,比如:百度搜索引擎的爬虫百度蜘蛛每天会在海量的互联网信息中进行爬取,爬取优质信息并收录,当用户在百度搜索引擎上检索对应关键词时,百度将对关键词进行分析处理,从收录的网页中找出相关网页,按照一定的排名规则进行排序并将结果展现给用户。还介绍了常用的Python IDE工具主要分为两大类文本工具类IDE和集成工具类IDE。讲述了接下要掌握定向网络数据爬取和页面解析的基本功能,本课程实例主要有京东商品页面的爬虫、亚马逊商品页面的爬虫、网络图片的爬取和存储等等。学习了这一周对网络爬虫有了初步的了解。在学习第一周,老师介绍了爬取网页的通用代码和HTTP协议及Requests库的主要知识,让我学习到了request库的7个主要方法,其中requests.head()方法、requests.request()方法和requests.get()方法是最常用与网络爬虫的方法,接下来还介绍了HTTP协议以及HTTP协议对资源的操作,主要功能是通过URL和命令管理资源,操作独立无状态,网络通道及服务器成为了黑匣子。最后是对Requests方法的参数进行一些列的分析和网络爬虫存在的风险及限制等。在这一周让我懂得request的方法对网络爬虫起到相关重要的作用但是也存在着一定的风险。在学习第二周,老师介绍了Beautiful Soup库的安装、Beautiful Soup库标签的分析、信息标记的三种形式、信息提取的方法和中国大学排名定向爬虫的实例介绍,主要介绍了bs4库的基本元素和bs4库的遍历功能。信息标记的形式可以分为XML、 JSON、 YAML。其中主要区别XML是在Internet上的信息交互与传递,JSON是移动应用云端和节点的信息通信,无注释,YAML是各类系统的配置文件,有注释易读。中国大学排名定向爬虫是采用requests-bs4路线实现了中国大学排名定向爬虫,对中英文混排输出问题进行优化。在学习第三周,老师介绍了正则表达式使用的优势即简洁,一行胜千言及一行就是特征的优势,在学习这个知识点之前我是完全不懂的,学完让我知道了什么是正则表达式以及它的用处。接下来是对两个实例进行分析,第一个是淘宝商品比价定向爬虫进行介绍主要是采用了requests-re路线实现的。第二个是对股票数据定向爬虫进行分析主要采用request-bs4-re路线实现股票信息爬取和存储,实现了展示爬取进程的动态滚动条。在学习第四周,老师介绍了Scrapy的框架、结构、命令行的使用以及与request的不同。Scrapy爬虫基本使用,更重要的是对股票数据sceapy爬虫实例的过程分析。经过这几周的学习,让我深刻的体会到了网络爬虫给我们带来便利的同时,在没有恰当使用的情况下也可以导致整个网络的崩溃,所以说不管是是什么东西我们都要把其优势发挥到最大,同时尽可能的减少不必要的麻烦。就是要在逐渐学习深入过程中,了解、理解、掌握正则表达式这是非常强大的东西,在很多语言中都会遇到这个东西,对提取想要的内容非常有帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号