爬取艺龙网站部分酒店信息
一.主题式网络爬虫设计方案
1.主题式网络爬虫名称:爬取艺龙网站泉州酒店信息
2.主题式网络爬虫的内容与数据特征分析:爬取艺龙网站泉州酒店的名称,价格和评分
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点):
实现思路:本次设计方案主要使用request库爬取网页信息和beautifulSoup库来提取泉州酒店信息,将其存入Excel文件里,并对其进行数据清理,模型分析和数据可视化。
技术难度:对艺龙网站泉州酒店页面分析和信息采集以及数据可视化
二.主题页面的结构特征分析
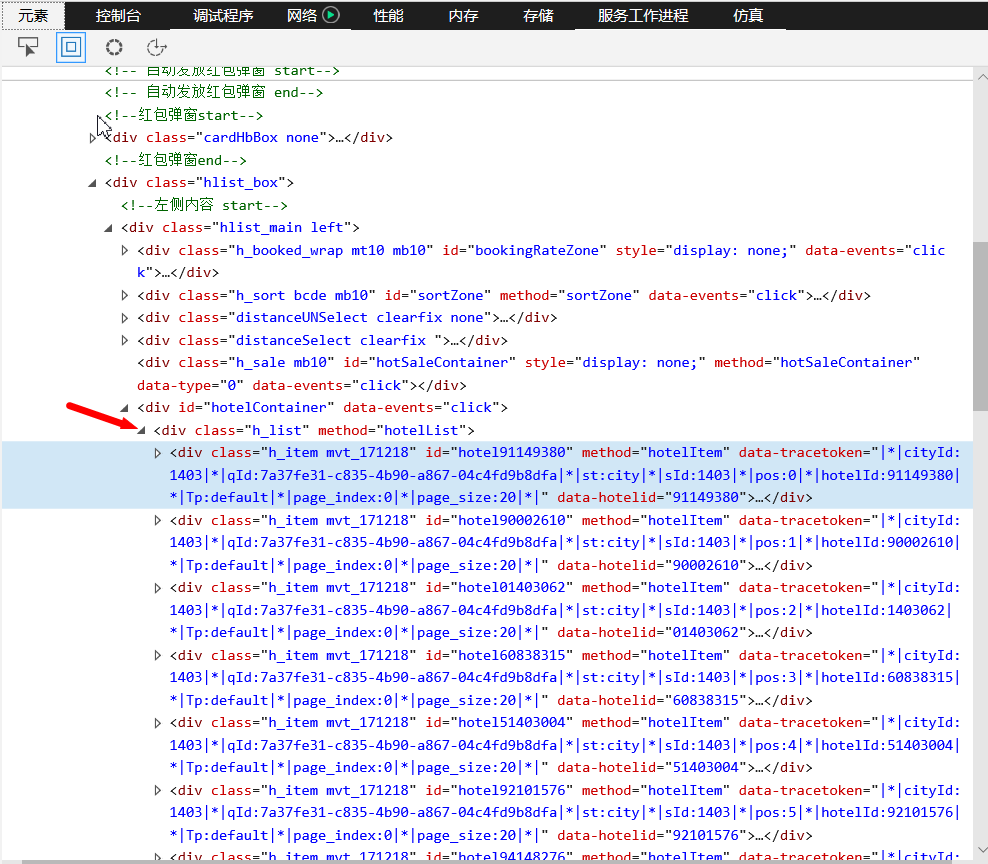
1.主题'页面的结构与特征分析:通过HTML页面的分析我们可以知道每个酒店的信息都在class="h_list"的子标签中,然后我们所要的信息都在于class="h_info_text"中,接着我们可以利用find_all逐一将需要的信息筛选出来。
2.HTML的页面解析

三.网络爬虫程序设计
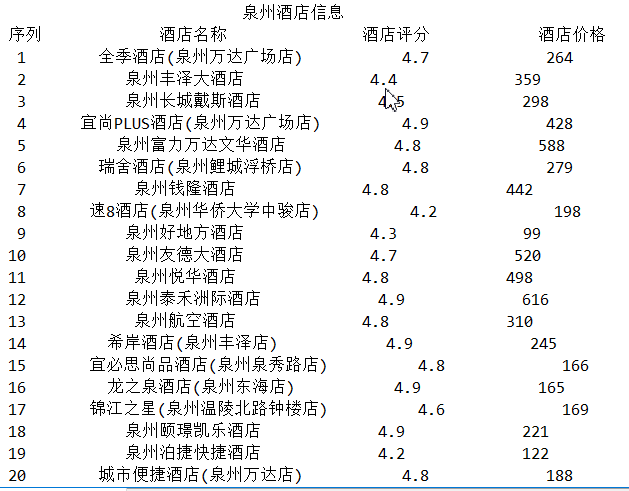
1.数据爬取与采集
1 import requests 2 import pandas as pd 3 from bs4 import BeautifulSoup 4 5 url='http://hotel.elong.com/quanzhou/' 6 header = {"User-Agent": "huang"} 7 r = requests.get(url, timeout=30, headers=header) 8 r.raise_for_status() # 产生异常信息 9 r.encoding = r.apparent_encoding # 修改编码 10 html = r.text 11 soup=BeautifulSoup(html,'html.parser') 12 #创建空列表 13 name=[] 14 level=[] 15 price=[] 16 hotellist=[] 17 18 #酒店名称 19 for span in soup.find_all("span","info_cn"): 20 name.append(span.string) 21 #酒店评分 22 for i in soup.find_all("i","t20 c37e"): 23 level.append(i.string) 24 #酒店价格 25 for span in soup.find_all("span","h_pri_num"): 26 price.append(span.string) 27 print("{:^60}".format("泉州酒店信息")) 28 print("{:^5}\t{:^20}\t{:^10}\t{:^10}".format("序列","酒店名称","酒店评分","酒店价格")) 29 #将数据进行整合 30 for i in range(20): 31 print("{:^5}\t{:^20}\t{:^10}\t{:^10}".format(i+1,name[i],level[i],price[i])) 32 hotellist.append([i+1,name[i],level[i],price[i]]) 33 #对数据进行保存 34 df = pd.DataFrame(hotellist,columns = ['序列','酒店名称','酒店评分','酒店价格']) 35 df.to_excel('艺龙网站泉州酒店信息.xlsx')

2.对数据进行清洗和处理
(1).删除酒店价格
1 df=pd.read_excel('艺龙网站泉州酒店信息.xlsx') 2 df.drop('酒店名称',axis=1,inplace=True) #删除酒店名称 3 df.head(20)

(2).重复值处理
1 df.duplicated() #重复值处理

(3).空值与缺失值处理
1 a=df['酒店价格'].isnull().value_counts() #检查是否有空值或缺失值 2 print(a)

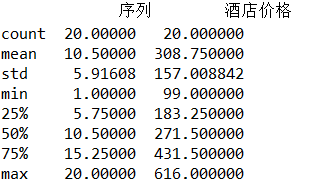
(4).异常值处理
1 df.describe() #检查是否有异常值
3.数据分析与可视化
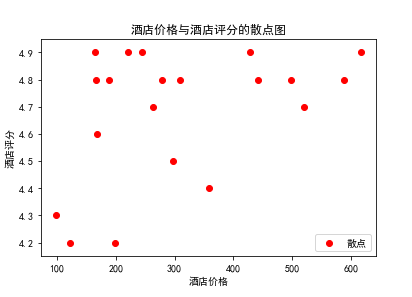
(1)散点图
1 #散点图 2 x = df.酒店价格 3 y = df.酒店评分 4 plt.xlabel("酒店价格") 5 plt.ylabel("酒店评分") 6 plt.scatter(x,y,color="red",label="散点") 7 plt.title("酒店价格与酒店评分的散点图") 8 plt.legend() 9 plt.show()
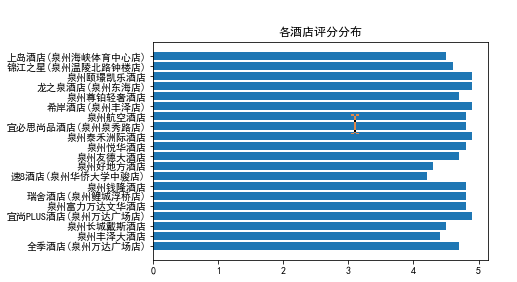
(2).柱状图(各酒店评分分布)
1 #柱形图 2 name_list = df.酒店名称 3 num_list = df.酒店评分 4 plt.barh(range(len(num_list)), num_list,tick_label = name_list) 5 plt.title("各酒店评分分布") 6 plt.show()
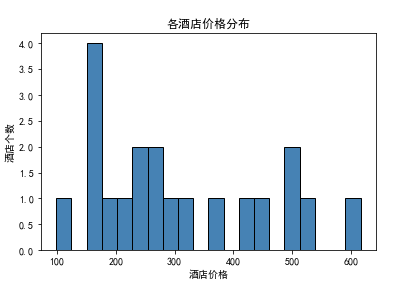
(3).直方图(各酒店价格分布)
1 #直方图 2 plt.hist(x = df.酒店价格, 3 bins = 20, 4 color = 'steelblue', 5 edgecolor = 'black' 6 ) 7 plt.xlabel('酒店价格') 8 plt.ylabel('酒店个数') 9 plt.title("各酒店价格分布") 10 plt.show()
4.数据之间的关系与相关系数
1 import numpy as np 2 import pandas as pd 3 import seaborn as sns 4 import sklearn 5 df=pd.read_excel('艺龙网站泉州酒店信息.xlsx') 6 df.head(20) 7 from sklearn.linear_model import LinearRegression 8 X=df.drop("酒店名称",axis=1) 9 predict_model=LinearRegression() 10 predict_model.fit(X,df['酒店价格']) 11 print("回归系数为:",predict_model.coef_) #判断相关性 12 sns.regplot(df.酒店价格,df.序列)

5.将代码汇总,附上完整代码
1 import requests 2 import pandas as pd 3 from bs4 import BeautifulSoup 4 5 url='http://hotel.elong.com/quanzhou/' 6 header = {"User-Agent": "huang"} 7 r = requests.get(url, timeout=30, headers=header) 8 r.raise_for_status() # 产生异常信息 9 r.encoding = r.apparent_encoding # 修改编码 10 html = r.text 11 soup=BeautifulSoup(html,'html.parser') 12 #创建空列表 13 name=[] 14 level=[] 15 price=[] 16 hotellist=[] 17 18 #酒店名称 19 for span in soup.find_all("span","info_cn"): 20 name.append(span.string) 21 #酒店评分 22 for i in soup.find_all("i","t20 c37e"): 23 level.append(i.string) 24 #酒店价格 25 for span in soup.find_all("span","h_pri_num"): 26 price.append(span.string) 27 print("{:^60}".format("泉州酒店信息")) 28 print("{:^5}\t{:^20}\t{:^10}\t{:^10}".format("序列","酒店名称","酒店评分","酒店价格")) 29 #将数据进行整合 30 for i in range(20): 31 print("{:^5}\t{:^20}\t{:^10}\t{:^10}".format(i+1,name[i],level[i],price[i])) 32 hotellist.append([i+1,name[i],level[i],price[i]]) 33 #对数据进行保存 34 df = pd.DataFrame(hotellist,columns = ['序列','酒店名称','酒店评分','酒店价格']) 35 df.to_excel('艺龙网站泉州酒店信息.xlsx') 36 #对数据进行读取 37 import pandas as pd 38 df=pd.read_excel('艺龙网站泉州酒店信息.xlsx') 39 print(df) 40 #对数据进行清洗和处理 41 #删除酒店价格 42 df.drop('酒店名称',axis=1,inplace=True) 43 df.head(20) 44 #检查是否有重复值 45 df.duplicated() 46 #检查是否有空值或缺失值 47 a=df['酒店价格'].isnull().value_counts() 48 print(a) 49 #检查是否有异常值 50 df.describe() 51 52 #对数据分析与可视化 53 import pandas as pd 54 import numpy as np 55 import matplotlib.pyplot as plt 56 import seaborn as sns 57 df = pd.DataFrame(pd.read_excel('艺龙网站泉州酒店信息.xlsx')) 58 #散点图 59 x = df.酒店价格 60 y = df.酒店评分 61 plt.xlabel("酒店价格") 62 plt.ylabel("酒店评分") 63 plt.scatter(x,y,color="red",label="散点") 64 plt.title("酒店价格与酒店评分的散点图") 65 plt.legend() 66 plt.show() 67 #柱形图 68 name_list = df.酒店名称 69 num_list = df.酒店评分 70 plt.barh(range(len(num_list)), num_list,tick_label = name_list) 71 plt.title("各酒店评分分布") 72 plt.show() 73 #直方图 74 plt.hist(x = df.酒店价格, 75 bins = 20, 76 color = 'steelblue', 77 edgecolor = 'black' 78 ) 79 plt.xlabel('酒店价格') 80 plt.ylabel('酒店个数') 81 plt.title("各酒店价格分布") 82 plt.show() 83 84 #数据之间的关系与相关系数 85 import numpy as np 86 import pandas as pd 87 import seaborn as sns 88 import sklearn 89 df=pd.read_excel('艺龙网站泉州酒店信息.xlsx') 90 df.head(20) 91 from sklearn.linear_model import LinearRegression 92 X=df.drop("酒店名称",axis=1) 93 predict_model=LinearRegression() 94 predict_model.fit(X,df['酒店价格']) 95 print("回归系数为:",predict_model.coef_) #判断相关性 96 sns.regplot(df.酒店价格,df.序列)
四.结论
1.经过对主题数据的分析与可视化,我发现酒店的价格跟酒店的评分不相关。
2.通过这次的练习让我懂得了不少知识,也对自己的不足之处更加了解。对于本次的编程对象方面由于没有充足了解,导致其数据可视化方面较少,其相关性不明显,总的方面做的还是有些不足。虽说有些不完美,但还是收获了不少,对Python越来越感兴趣,希望今后能学到更多方面的知识提升自己的不足。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号