BatchNorm
原理——
BatchNorm就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布;
若对神经网络每一层做归一化,会使每一层输出为标准正太分布,会使神经网络完全学习不到特征;
[
说明——(适用于从整体分布看)
图片28*28,通道3,批次10,BatchNorm就是在归一化10个批次中的所有图像的第1(或者另外的)个通道;
]
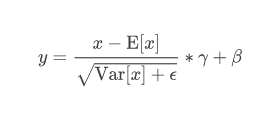

算法过程_
沿着通道计算每个batch的均值u
沿着通道计算每个batch的方差σ^2
对x做归一化,x’=(x-u)/开根号(σ^2+ε)
加入缩放和平移变量γ和β ,归一化后的值,y=γx’+β
注意——
1.缩放和平移变量R和β是神经网络学习到的;
2.为什么要加这两个参数?
保证每一次数据经过归一化后还保留原有学习来的特征,同时又能完成归一化操作,加速训练,增加非线性拟合能力(通过两个参数位置变换);
优点——
1.调参过程变简单,对于初始化要求没那么高,数据被压缩,可以使用大的学习率;
2.缓解过拟合,Batchnorm可以代替其他正则方式如dropout、L2、L1等;
3.降低了数据之间的绝对差异,因此在分类任务上具有更好的效果;
4.有效避免梯度消失或者爆炸(将数据拉到均值为0方差为1的正太分布),使梯度处于较大的位置,损失收敛快;
5.可以把训练数据集打乱;(文献说这个可以提高1%的精度)
缺点——由于每次计算均值和方差是在一个batch上,如果batchsize太小,,则计算的均值、方差不足以代表整个数据分布;
参数及其作用——
num_features: 输出通道维度
eps: 防止公式分母为0,默认为1e-5。
momentum: 动态均值和动态方差所使用的动量,控制梯度的下降幅度,默认为0.1。
affine: 默认true,给该层添加可学习的仿射变换参数。
track_running_stats:默认true,记录训练过程中的均值和方差;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号