
走进 Akka.NET
官方文档:https://getakka.net/index.html
一、Akka.NET 是什么?
Akka 是一个构建高并发、分布式和弹性消息驱动的工具包。Akka.NET 是 Akka 的一个 .NET 的移植库。
Akka.NET 内部都是 Actor 构成的,Actor 是一个状态、行为、邮箱、子节点和监视者策略构成的容器。
二、Akka.NET 的一些基础模块
Akka - 核心 Actor 库
Akka.Remote - 跨节点 Actor 部署/通信
Akka.Cluster - 弹性 Actor 网络(HA)
Akka.Persistence - 事件源, 持久化 Actor 状态 & 恢复
Akka.Streams - 流式工作流
Akka.Cluster.Tools - 集群单例, 分布式发布/订阅
Akka.Cluster.Sharding - 持久化状态分区
Akka.DData - 最终一直的数据复制
三、Akka.NET 的架构
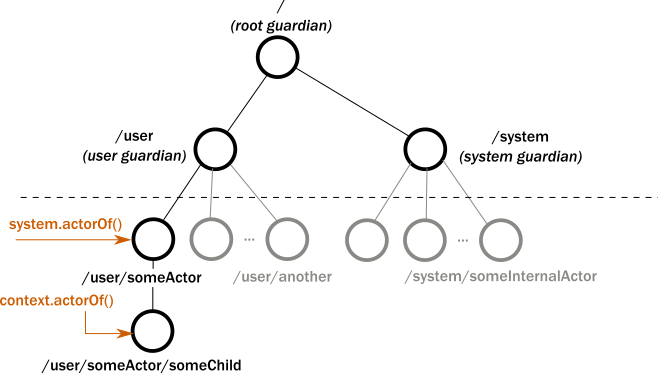
如图所示,一个 akka 系统有一个跟节点 root,然后 root 有2个子节点,user 和 system ,你定义的 actor 都在 user 下,system 下都是系统定义的
四、Akka.NET 发送消息的规则
-
最多一次交付
-
每个配对的发送者、接收者对消息保持排序。
五、基础 Actor 类型
- ReceiverActor:如果使用这个类型的 Actor 为基类,使用 Receive<T>(msg=>{}); 来接收消息
- UntypedActor:如果使用这个类型的 Actor 为基类,需要重写 OnReceive(object message) 方法,然后区分 message 类型
六、使用 Akka.NET
- 普通模式
因为 Helloworld 的例子太多了,官网也有,这里直接略过。
代码在这里
代码里有些特殊情况的处理没写,这里简单说一下
比如 sender 发送给了 receiver 一个消息,但是 receiver 还有些事情没有准备好,比如发送来一个消息,但是可能需要先登录,那就先缓存下来,等办完事再处理
流程是:先 Stash 消息,开启 Scheduler ,发送 GetToken 消息,token 获取成功返回 GetTokenSuccess 消息,取消 Scheduler ,变成 Redy 状态,正常处理消息
public ReceiveActor() { private ICancelable _cancel; public ReceiveActor() { Receive<TestMsg>(msg => { Stash.Stash(); }); Receive<GetToken>(msg => { GetTokenProcess(); } Receive<GetTokenSuccess>(msg => { _cancel?.Cancel(); _cancel = null; Become(Ready); }); if (_cancel == null) { _cancel = Context.System.Scheduler.ScheduleTellRepeatedlyCancelable(TimeSpan.Zero, TimeSpan.FromSeconds(10), Self, new GetToken(), Self); } } private void Ready() { Receive<TestMsg>(msg => { //Todo }); Stash.UnstashAll(); } private void GetTokenProcess() { var tokenActor = Context.ActorOf(Props.Create(() => new TokenActor("url"))); tokenActor.Ask<GetTokenSuccess>(new GetToken { Token = "", }).ContinueWith(tr => { if (tr.IsCanceled || tr.IsFaulted) { return new GetTokenSuccess(); } return tr.Result; }).PipeTo(Self); } public class GetToken { public string Token { get; set; } } }
- Router
Actor 内部其实是单线程的处理消息的,但是用了 Router 可以把消息分出去给多个节点处理,这里分为2种模式,group 和 pool
先来看 group 配置
akka {
actor{
provider = cluster
deployment {
/api/myClusterGroupRouter {
router = broadcast-group # routing strategy
routees.paths = ["/user/api"] # path of routee on each node
nr-of-instances = 3 # max number of total routees
cluster {
enabled = on
allow-local-routees = on
use-role = crawler
}
}
}
}
}
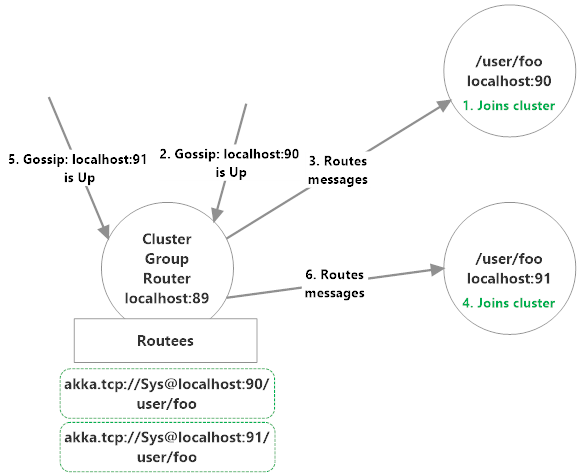
如图看到在 89节点上注册了 90 和 91 节点的 Routees
pool 模式
akka {
actor{
provider = cluster
deployment {
/api/myClusterPoolRouter {
router = round-robin-pool # routing strategy
nr-of-instances = 10 # max number of total routees
cluster {
enabled = on
allow-local-routees = on
use-role = crawler
max-nr-of-instances-per-node = 1
}
}
}
}
}
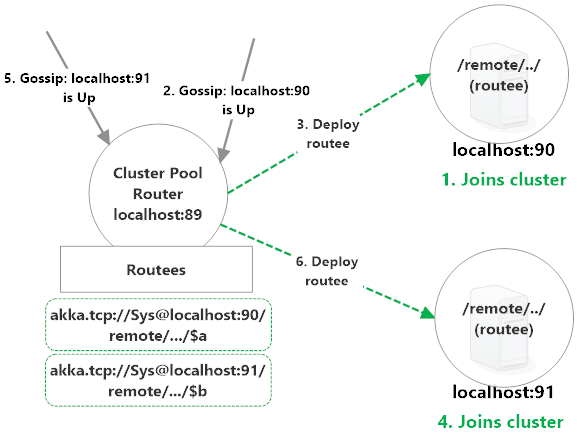
这种模式其实是在 90 和 91 的节点上分别注册了 89 的 routee,89上是akka.tcp://Sys@localhost:90/remote/akka/tcp/localhost:89/$a 和 akka.tcp://Sys@localhost:91/remote/akka/tcp/localhost:89/$a
具体代码在这里
- Shard
用逻辑 id 联系,不关心集群中的物理位置或管理他们的创建,可以 rebalance (消耗资源比较大,只有差异比较大的时候才会,默认 rebalance-threshold = 10,shard 数量设置为集群节点最大数量的10倍,shard 数量太大消耗大)
整个 ActorSystem 中只能有一个Codinator,在最老的节点上,因为最老的节点被认为是安全的。
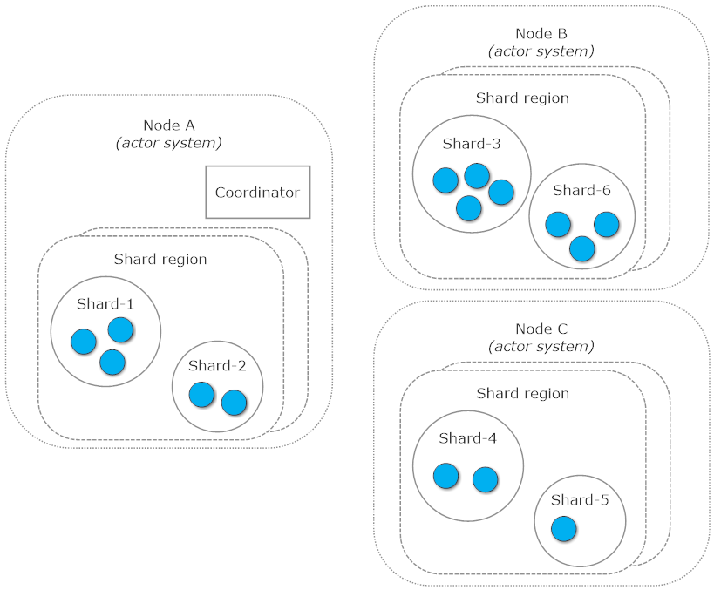
如图所示整个系统分为了 Coordinator ,Shard region(typeName), Shard,Entity 部分,节点的路径是 /user/sharding/<typeName>/<shardId>/<entityId> 和普通的路径 /user/<actorName> 不一样
这里使用了 Persistent ,每种数据库的配置完全不同,我是 Redis 的配置,建议使用即时更新的数据库,不更新的很可能是弃用的,比如 mysql。
具体代码在这里
这里需要注意的是:
- 只能有一个 Lighthourse —— 否在爆 ID 13 error
- 创建 ActorSystem 的时候后边加上 _config.WithFallback(ClusterClientReceptionist.DefaultConfig()).WithFallback(DistributedPubSub.DefaultConfig()); —— 否在爆 ID 9 error
- 区别
Shard 看着好像也能处理 Router 的问题,但这里又有些区别,此处摘自官方文档,用的自动翻译,请自行理解下:
在一致的散列场景中,整个密钥空间被拼接在我们在路由器配置中定义的参与者数量之间。这究竟意味着什么?单个参与者实例负责处理整个范围的密钥。例如:假设在一个一致的哈希路由器后面,我们有一个数字1-100的密钥空间,在5个参与者之间平均共享。这意味着,第一个参与者将负责处理ID为1-20、第二个参与者21-40、第三个参与者41-60等的所有消息。如果您的目标是每个标识符有一个唯一的参与者,那么对于您的情况来说,这不是一个有效的场景。在集群分片场景的另一边,每个实体(这就是我们如何引用分片参与者)由对(ShardId,EntityId)标识。它是1-1关系,因此用同一对标识的消息保证总是路由到相同的单个实体。 另一个区别是灵活性。一致的哈希路由器几乎是静态的,在您想要调整集群大小的情况下,它们不能很好地工作。你记得以前提到过的拼接键空间的概念吗?想象一下,一旦我们改变分配给它的参与者/节点的实际数量,它将如何工作。当然,这些关键范围也必须改变。因此,在集群大小调整之后,以前处理ID为1-20的消息的演员现在可以处理不同的范围(即,1-15)。这称为“分区切换”。当使用集群切分时,我们的参与者将能够随着集群大小的改变迁移到其他节点,即使在集群大小改变时,也能够保持消息id和分割实体之间的关系。
七、总结
除了 stream 没研究,其他的多少都看了一点,因为我没有使用 stream 的场景,其他发现 Helloworld 的入门真的没什么用,只是让你理解 Actor 的开发的思想和模式,实际使用需要多看文档,一点点研究,还有就是官网的博文,再就是一些大神写的例子,
这里放几个网址供大家学习
GitHub:
https://github.com/cgstevens/FileProcessor
https://github.com/Horusiath/AkkaDemos
https://github.com/petabridge/akkadotnet-code-samples
https://github.com/Lutando/Akkatecture
文档:
Streams:https://petabridge.com/blog/akkadotnet-11-cluster-streams/
Distributed Pub-Sub:https://petabridge.com/blog/distributed-pub-sub-intro-akkadotnet/
Shard:https://petabridge.com/blog/introduction-to-cluster-sharding-akkadotnet/
Shard:https://petabridge.com/blog/cluster-sharding-technical-overview-akkadotnet/
Petabridge.Cmd:https://petabridge.com/blog/petabridgecmd-release/
Moonitoring:https://github.com/petabridge/akka-monitoring
你是不是感觉很奇怪,没有 Dashboard 呢,其实是有,但是收费,在这里:https://phobos.petabridge.com/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号